Hive on Spark 配置
目录
- 1 Hive 引擎简介
- 2 Hive on Spark 配置
- 2.1 在 Hive 所在节点部署 Spark
- 2.2 在hive中创建spark配置文件
- 2.3 向 HDFS上传Spark纯净版 jar 包
- 2.4 修改hive-site.xml文件
- 2.5 Hive on Spark测试
- 2.6 报错
1 Hive 引擎简介
Hive引擎包括:MR(默认)、tez、spark。
Hive on Spark:Hive既作为存储元数据又负责 SQL 的解析优化,语法是 HQL 语法,执行引擎变成了 Spark,Spark 负责采用 RDD 执行。
Spark on Hive:Hive 只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用 RDD 执行。
2 Hive on Spark 配置
注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。

2.1 在 Hive 所在节点部署 Spark
(1)Spark官网下载 jar 包地址:http://spark.apache.org/downloads.html
(2)上传并解压解压spark-3.0.0-bin-hadoop3.2.tgz
[huwei@hadoop101 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[huwei@hadoop101 software]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
(3)配置 SPARK_HOME 环境变量
[huwei@hadoop101 module]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
使环境变量生效
[huwei@hadoop101 module]$ source /etc/profile.d/my_env.sh
2.2 在hive中创建spark配置文件
[huwei@hadoop101 software]$ cd /opt/module/hive-3.1.2/conf/
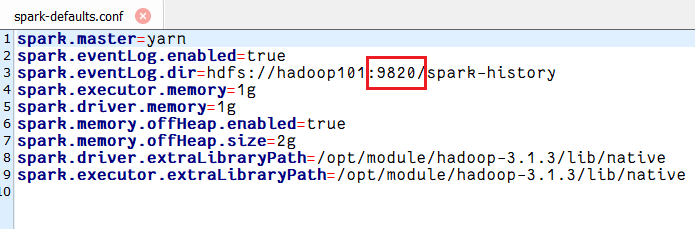
[huwei@hadoop101 conf]$ vim spark-defaults.conf
添加如下内容
spark.master=yarn
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://hadoop101:9820/spark-history
spark.executor.memory=1g
spark.driver.memory=1g
spark.memory.offHeap.enabled=true
spark.memory.offHeap.size=2g
spark.driver.extraLibraryPath=/opt/module/hadoop-3.1.3/lib/native
spark.executor.extraLibraryPath=/opt/module/hadoop-3.1.3/lib/native
在HDFS创建如下路径,用于存储历史日志
[huwei@hadoop101 conf]$ hadoop fs -mkdir /spark-history
2.3 向 HDFS上传Spark纯净版 jar 包
由于Spark3.0.0非纯净版默认支持的是 hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
(1)上传并解压spark-3.0.0-bin-without-hadoop.tgz
[huwei@hadoop101 conf]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz -C /opt/module/
(2)上传Spark纯净版jar包到HDFS
[huwei@hadoop101 conf]$ hadoop fs -mkdir /spark-jars
[huwei@hadoop101 conf]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
2.4 修改hive-site.xml文件
[huwei@hadoop101 conf]$ vim /opt/module/hive-3.1.2/conf/hive-site.xml
添加如下内容
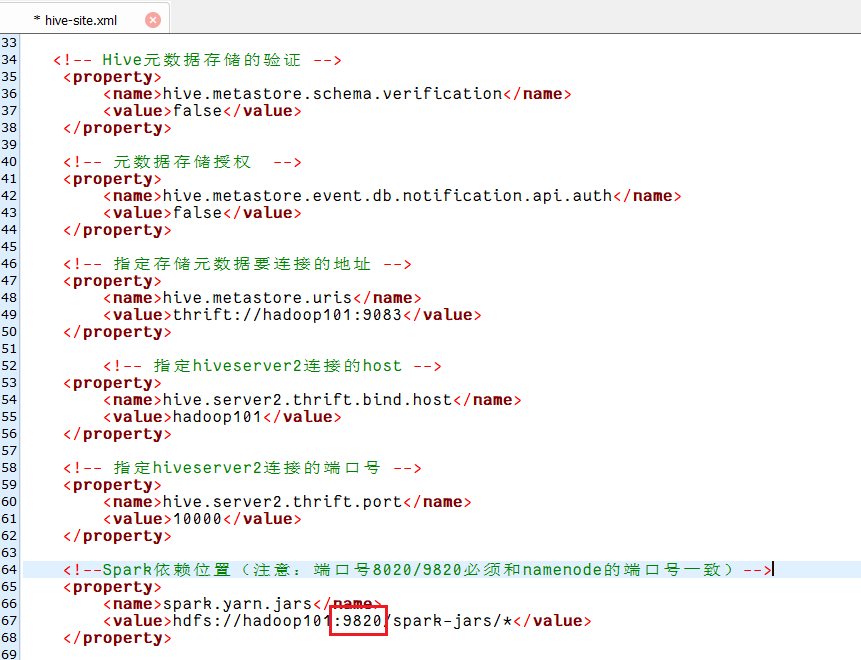
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property><name>spark.yarn.jars</name><value>hdfs://hadoop101:9820/spark-jars/*</value>
</property><!--Hive执行引擎-->
<property><name>hive.execution.engine</name><value>spark</value>
</property><!--Hive和Spark连接超时时间-->
<property><name>hive.spark.client.connect.timeout</name><value>10000ms</value>
</property>
2.5 Hive on Spark测试
(1)启动 spark
[huwei@hadoop101 ~]$ cd /opt/module/
[huwei@hadoop101 module]$ cd spark
[huwei@hadoop101 spark]$ sbin/start-all.sh(2)启动hive客户端
[huwei@hadoop101 conf]$ hive
(3)创建一张测试表
hive (default)> create table student(id int, name string);
(4)通过insert测试效果
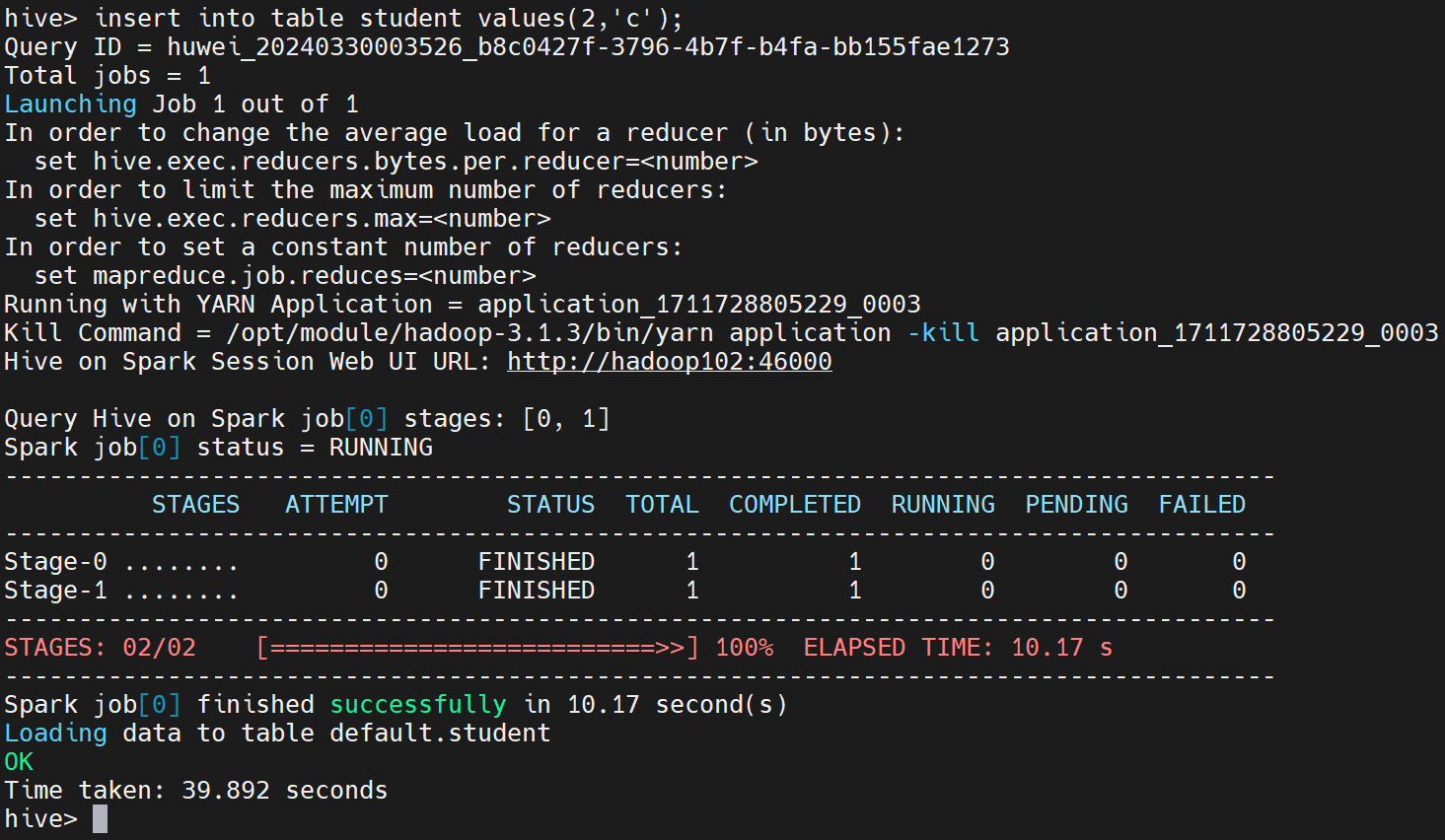
hive (default)> insert into table student values(1,'abc');
若结果如下,则说明配置成功
2.6 报错
在最后插入数据测试Hive on Spark的时候总是报错,也不是版本问题,也不是内存问题,困扰了一天了,最后发现跟着教程走的namenode端口号写成了8020,而我使用的是hadoop3版本,在安装hadoop时,将namenode端口号设的是9820
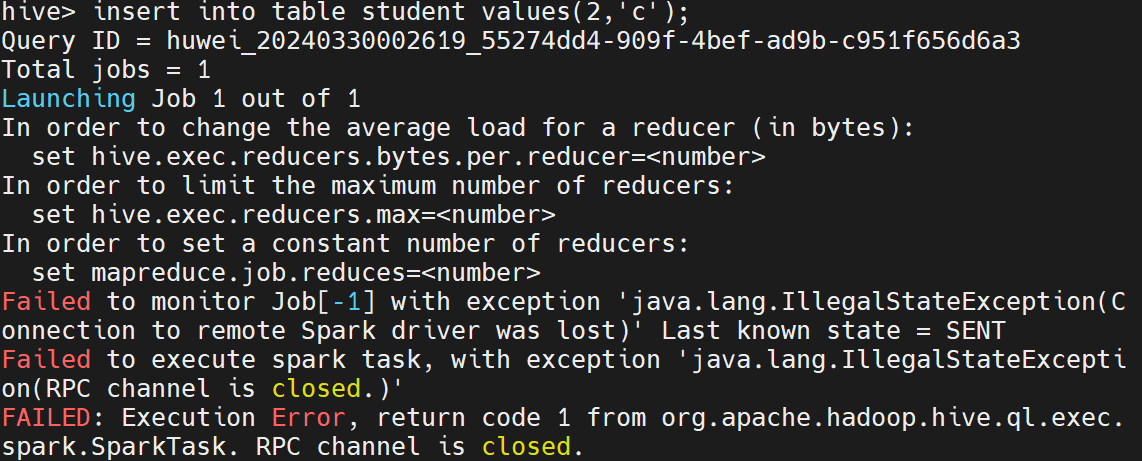
后来,我将以下两个配置文件namenode的端口号改成9820,最终才解决。