数据结构——lesson12排序之归并排序
💞💞 前言
hello hello~ ,这里是大耳朵土土垚~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹
💥个人主页:大耳朵土土垚的博客
💥 所属专栏:数据结构学习笔记 、排序算法合集
💥对于数据结构顺序表、链表、堆以及排序有疑问的都可以在上面数据结构专栏和排序合集专栏进行学习哦~ 有问题可以写在评论区或者私信我哦~

前面我们学习过六种排序——直接插入排序、希尔排序、直接选择排序、堆排序、冒泡排序和快速排序,今天我们就来学习归并排序🥳🎉🎉🎉
1.归并排序
基本思想: 归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide andConquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并排序核心步骤:
归并排序的步骤类似于二叉树的后序遍历,先一直分解到不能再分,然后对两个子序列合并排序,最终得到全部排序好的序列;
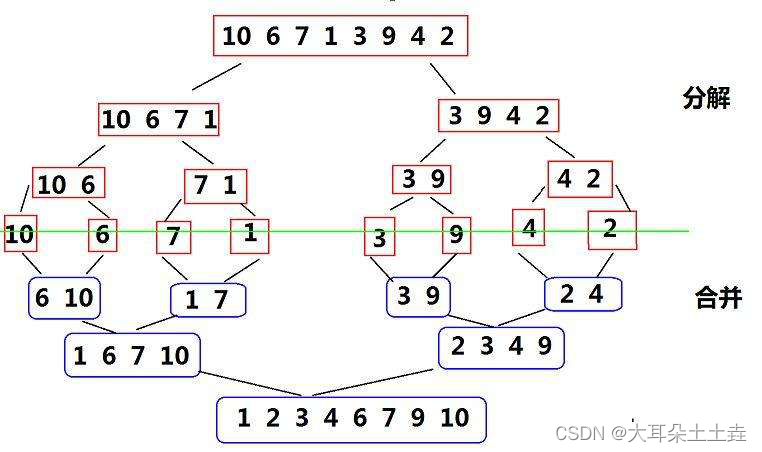

1.1归并排序(递归版)
在上图中我们看到它把序列拿下来排好后再放回原序列,归并排序需要在内存中重新开辟一个数组来存放排好的子序列,然后再拷贝回原数组,这样可以防止在原数组中操作困难以及很多错误的发生;
步骤:
①使用malloc函数开辟一个大小为原数组的空间存放在tmp中;
②重新构造递归函数(因为如果在原来的函数中递归,那么每次都会malloc开辟一个数组,不合适)_mergesort();
③分解数列,进行递归,创建mid遍量,从中间开始分割;
④当只有一个数时就不再分割(也就是begin>=end时);
⑤对子序列进行归并排序;
void _mergesort(int* a,int begin,int end, int* tmp)
{//递归结束条件if (begin >= end)return;//分左右区间int mid = (begin + end) / 2;_mergesort(a, begin, mid,tmp);_mergesort(a, mid+1, end,tmp);//归并排序int begin1 = begin;int end1 = mid;int begin2 = mid + 1;int end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[i++] = a[begin1];begin1++;}else{tmp[i++] = a[begin2];begin2++;}}//如果最后begin1的序列有剩余while (begin1 <= end1){tmp[i++] = a[begin1++];}//如果最后begin2的序列有剩余while (begin2 <= end2){tmp[i++] = a[begin2++];}//最后再拷贝回原数组memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));}// 归并排序递归实现
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int)*n);_mergesort(a,0,n-1,tmp);free(tmp);//释放内存空间
}
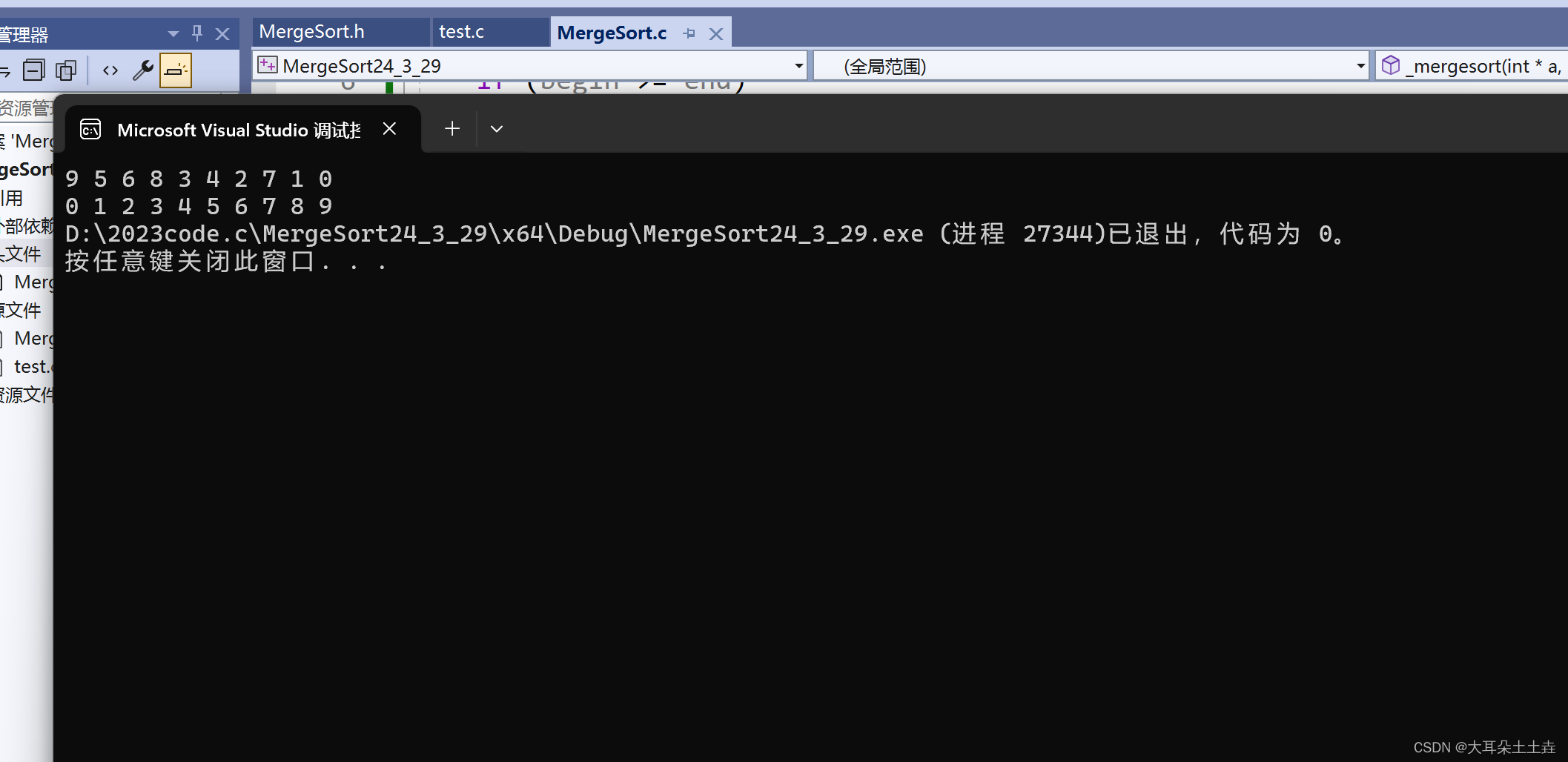
结果如下:
上面一排是排序前,下面一排是用归并排序排完序后
1.2归并排序(非递归版)
归并排序非递归版主要是通过循环来实现两两归并;
步骤如下:
①使用malloc开辟tmp数组来存放归并好的数;
②创建gap来设定每次归并的序列的范围;
③利用while循环来实现整个序列的多次归并;
④while循环内部与递归的归并对子序列排序类似,不同的是需要嵌套for循环来实现多个gap范围的序列归并(因为此时已经将整个序列分成每gap个为一组,所以需要for循环来控制,使得这些序列全部都两两归并);
⑤归并完了后要使用memcpy函数将数据拷贝回原数组;
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);//开辟数组来归并if (tmp == NULL){perror("malloc fail");return;}int gap = 1;//定义每次归并范围while (gap < n)//gap不能==n,因为此时?{int j = 0;//记录tmp数组下标//每次距离为gap的两组归并for (int i = 0; i < n; i+=2*gap){int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;if (end1 >= n || begin2 >= n){end1 = n - 1;break;}if (end2 >= n){end2 = n - 1;}//归并while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1];begin1++;}else{tmp[j++] = a[begin2];begin2++;}}//如果最后begin1的序列有剩余while (begin1 <= end1){tmp[j++] = a[begin1++];}//如果最后begin2的序列有剩余while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, sizeof(int)*(end2 - i + 1));}gap *= 2;}free(tmp);
}结果如下:
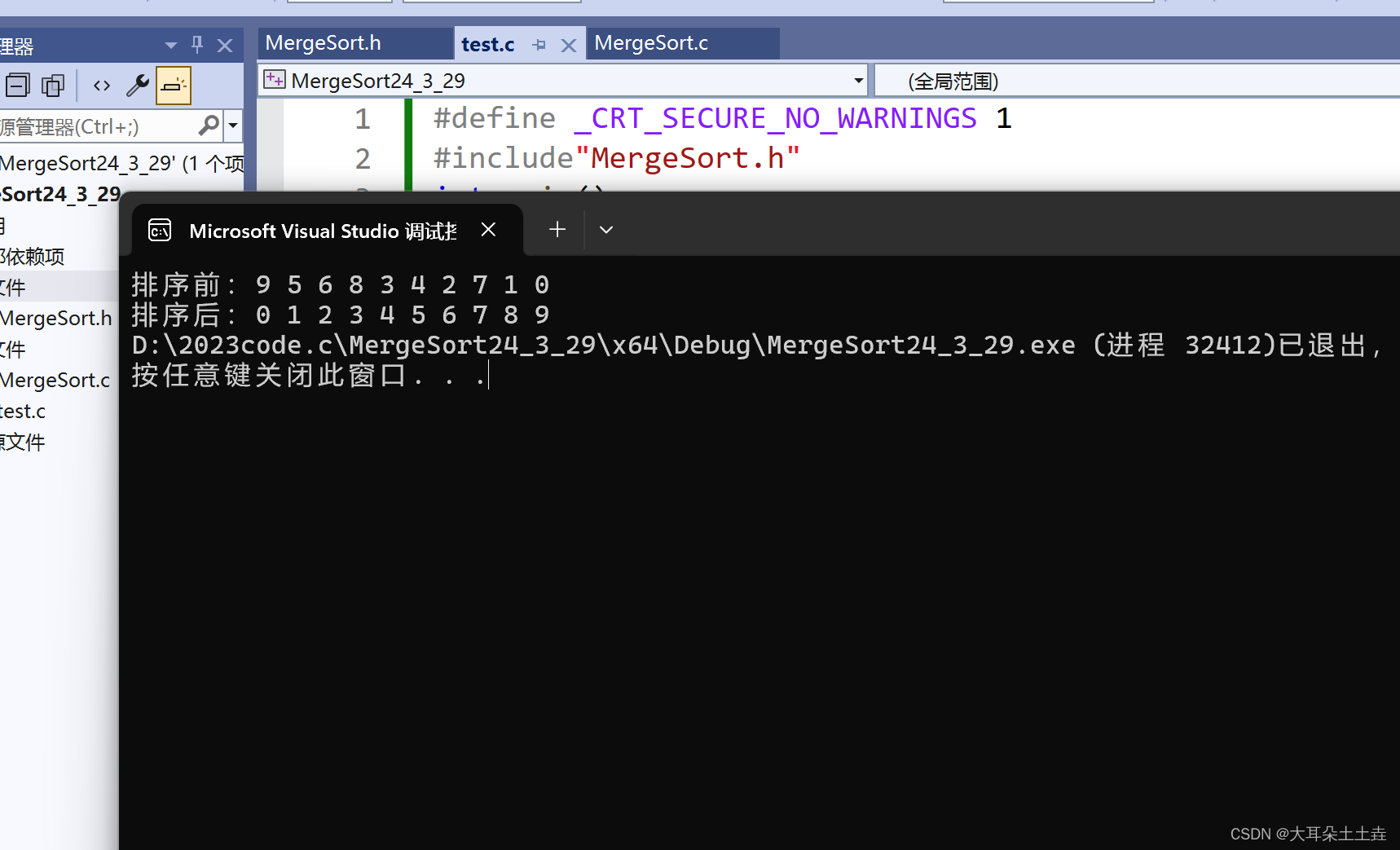
✨✨这里要注意两点:
🥳🥳(1)将数组每gap为一组分完后进行两两归并时,可能出现三种情况:
💥 ①到最后可能第一个序列存在,下一个序列不存在也就是begin2>=n的情况;
💥②还可能出现第一个序列只有一部分也就是end1>=n的情况;
💥 ③第二个序列只有一部分存在也就是end2>=n的情况;
出现①②两种情况说明最后一组只有一组或半组,这时不需要再归并,将end2 = n -1,并break跳出循环即可;
情况③有两组可以归并,但是第二组不完整,所以此时需要将end2 = n-1,不跳出循环继续归并即可;
🥳🥳(2)memcpy将tmp中归并的数拷贝回原数组时;
💥①可以考虑在for循环内部每次归并完两个序列后拷贝回去(上述代码就是使用这种)此时:
memcpy(a + i, tmp + i, sizeof(int)*(end2 - begin1 + 1))
要注意拷贝的位置要+i,并且拷贝的个数也应该是归并的两个序列的长度,(但是不能使用2*gap因为会出现上面的(1)问题,有可能序列不存在或部分存在)所以序列长度应该是end2 - i;
💥②可以在每次完整归并完距离为gap的序列后再进行拷贝,此时:
memcpy(a, tmp, sizeof(int) * n);
如下图所示:
此时不需要考虑拷贝的位置,直接全部拷贝即可;
??真的以为这么简单吗???不可能,绝对不可能😭😭
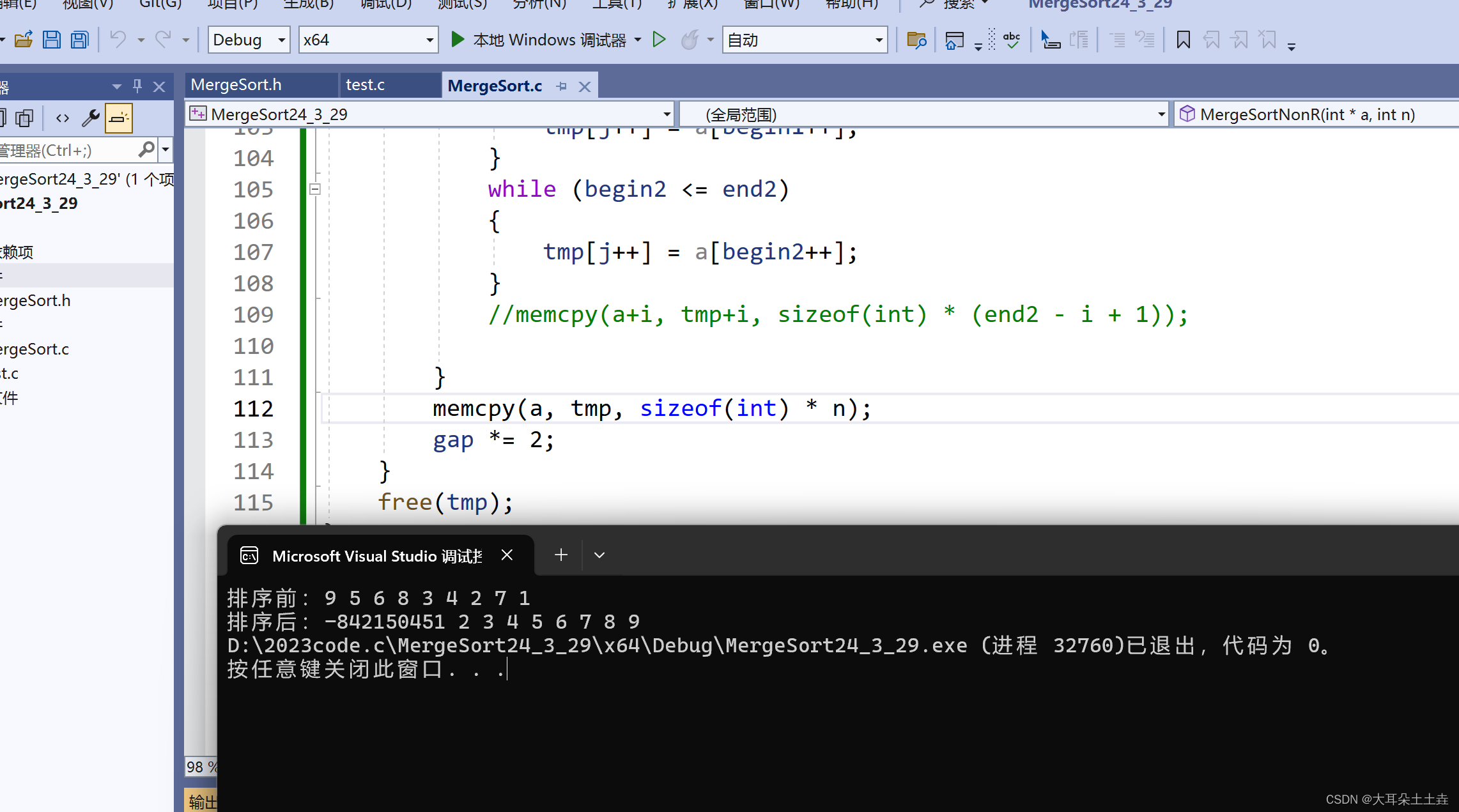
刚刚将十个数据0,1,2,3,4,5,6,7,8,9改成九个数据1,2,3,4,5,6,7,8,9结果如下:
可恶又错了,得重新捋一遍:
现在我们是要等for循环一遍将间距为gap的组两两归并,直到全部归并完再进行拷贝,之前是for循环内部每两组归并完就拷贝,那为什么全部归并完再拷贝会出错呢???
捋一遍发现:
if (end1 >= n || begin2 >= n) { end1 = n - 1; break; }
这里有问题,在只有一个序列或半个序列时,我们直接跳出了循环,也就是此时原数组后面的数根本没有输入到tmp数组里面,此时tmp后面的数是不知道是什么的,然后你再全部一拷贝回原数组,这样不仅不能排序,还会将原数组的数给覆盖掉,所以如果要使用:memcpy(a, tmp, sizeof(int) * n);
我们不能再次使用上面的if语句,需要改一改:
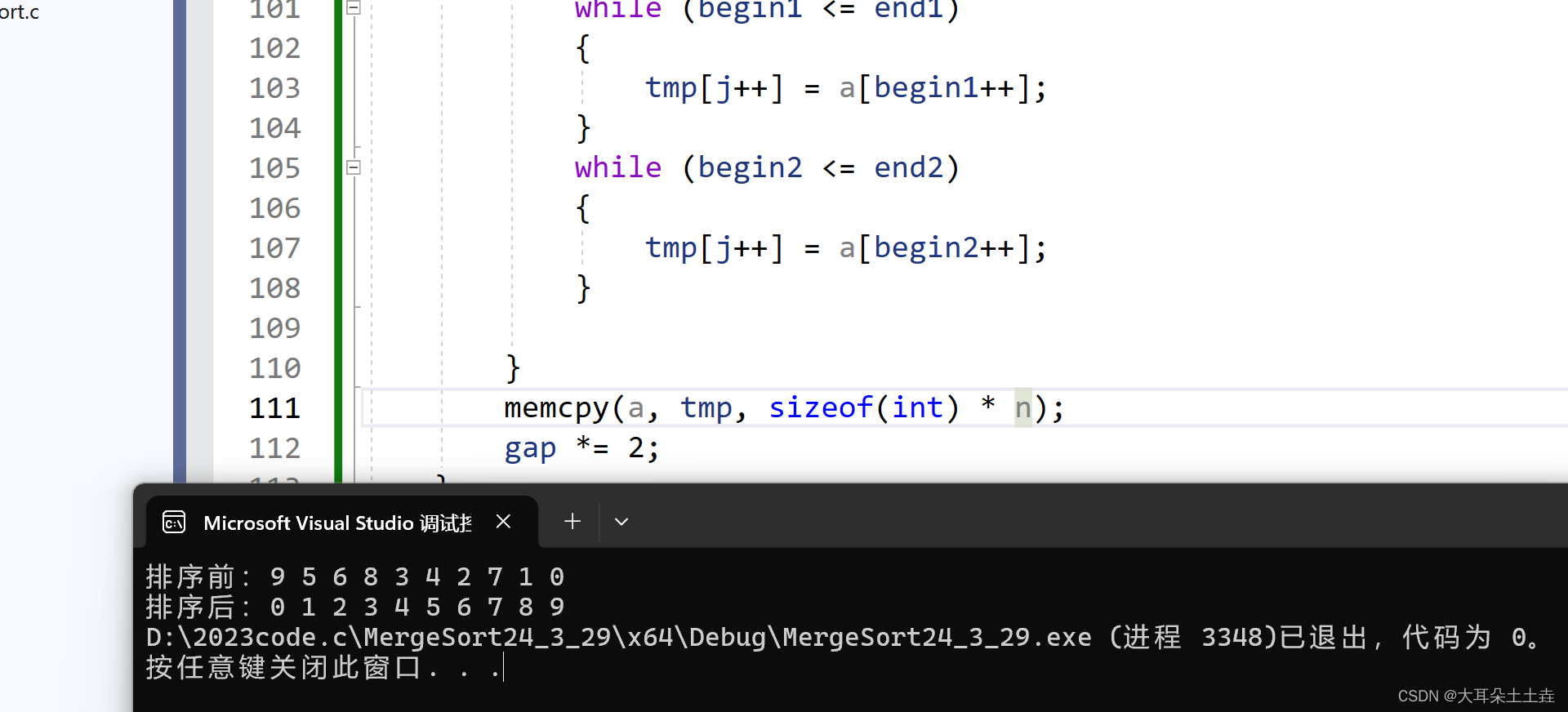
if (end1 >= n || begin2 >= n)
{end1 = n - 1;//break//不能跳出循环,需要将序列1的数录入到tmp数组中,所以只要设置序列2不存在即可//要是序列2不存在,只需begin2 > end2 即可begin2 = i + 1;end2 = i;
}
结果如下:
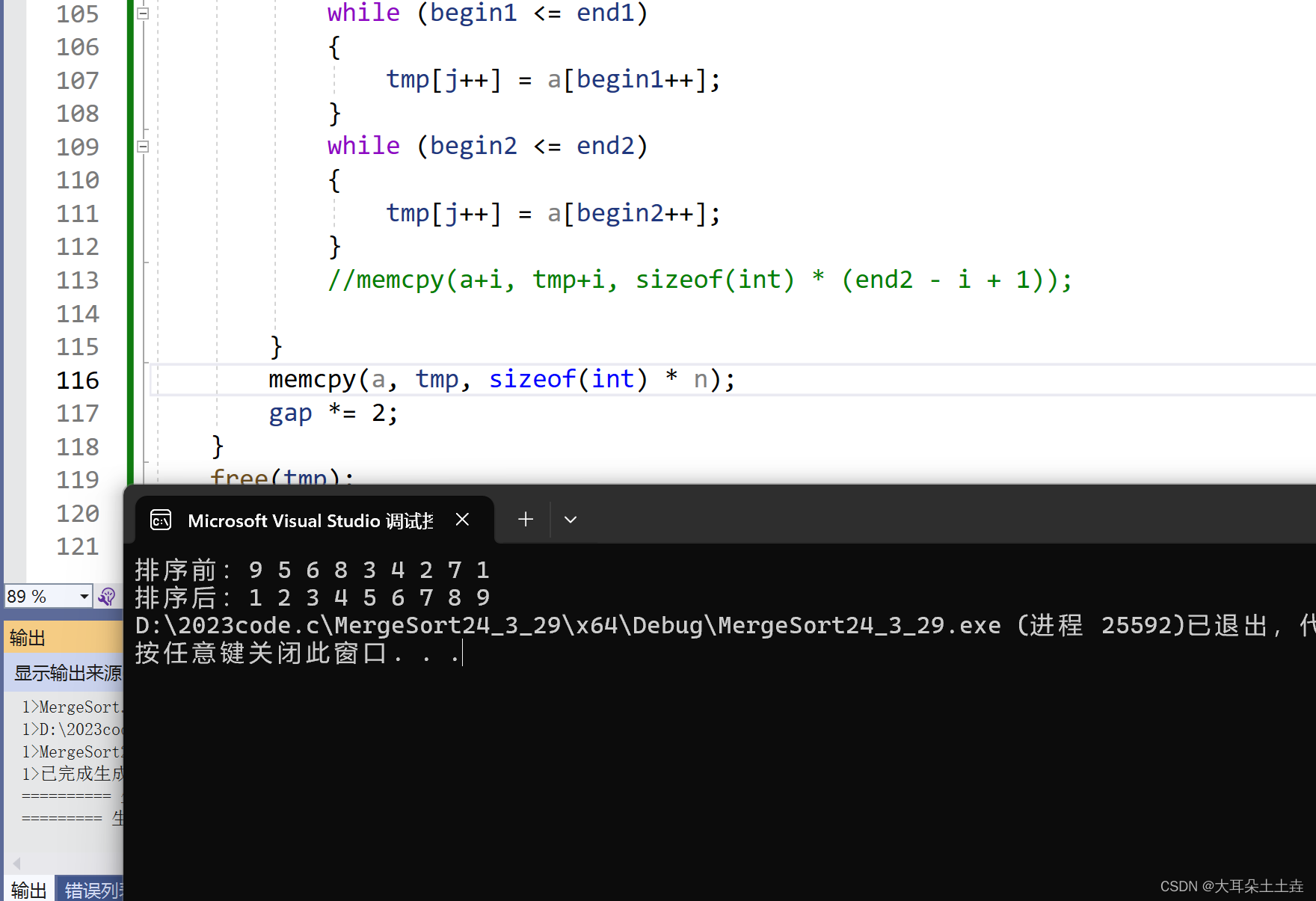
此时就可以使用 memcpy(a, tmp, sizeof(int) * n);啦🥳🥳🥳
注意不可以在跳出break循环后再进行拷贝哦~因为这样没办法知道之前归并好的数据是什么,所以没办法进行归并排序💫💫
2.归并排序复杂度分析
2.1空间复杂度
无论递归还是非递归,我们都使用malloc函数开辟了tmp数组,大小是n,所以它的空间复杂度是O(n);🥳🥳🥳
2.2时间复杂度
我们可以利用非递归的来看归并排序的时间复杂度:
①首先,无论gap是什么,都需要借助for循环来遍历一遍数组进行归并排序每一遍都是n;
②所以只需要确定while循环多少次即可,有因为while循环条件是gap < n,每次gap*=2;
③所以while循环log(n)次所以归并排序非递归的时间复杂度是O(nlogn);
而非递归是利用while循环对递归的另一种表现形式,它们的原理逻辑都是一样的,所以递归版的时间复杂度也应该是O(nlogn);🥳🥳🥳
3.结语
我们学习了归并排序的两种实现——递归与非递归版;并分析了归并排序的时间和空间复杂度,以上就是归并排序的所有内容啦~ 完结撒花~🥳🎉🎉🎉