Redis缓存设计与性能优化【缓存穿透、缓存击穿、缓存雪崩】
Redis缓存设计与性能优化
- 多级缓存架构
- 缓存设计
- 缓存穿透(空数据)
- 造成缓存穿透的基本原因有两个:
- 第一, 自身业务代码或者数据出现问题。
- 第二, 一些恶意攻击、 爬虫等造成大量空命中。
- 缓存穿透问题解决方案:
- 1、缓存空对象
- 2、布隆过滤器
- 缓存失效(击穿)(原因:同一时间失效 解决:设置随机失效时间)
- 缓存雪崩
- 原因:缓存层不能提供服务(如大量并发缓存层支撑不住)
- 预防和解决缓存雪崩问题, 可以从以下三个方面进行着手。
- 1) 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster。
- 2) 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。
- 3) 提前演练。
多级缓存架构
缓存设计
缓存穿透(空数据)
缓存穿透是指查询一个根本不存在的数据, 缓存层和存储层都不会命中, 通常出于容错的考虑,== 如果从存储层查不到数据则不写入缓存层==。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。
造成缓存穿透的基本原因有两个:
第一, 自身业务代码或者数据出现问题。
第二, 一些恶意攻击、 爬虫等造成大量空命中。
缓存穿透问题解决方案:
1、缓存空对象
String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空, 需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}
}
2、布隆过滤器
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
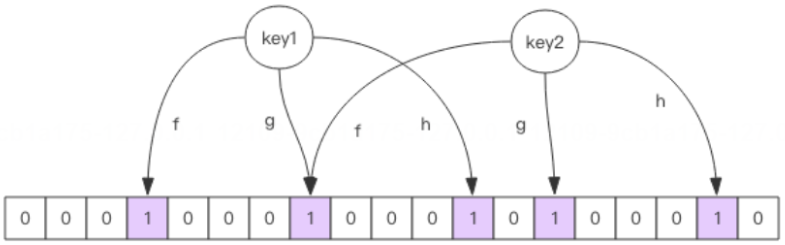
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组长度比较大,存在概率就会很大,如果这个位数组长度比较小,存在概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
可以用redisson实现布隆过滤器,引入依赖:
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId><version>3.6.5</version>
</dependency>
示例伪代码:
package com.redisson;import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;public class RedissonBloomFilter {public static void main(String[] args) {Config config = new Config();config.useSingleServer().setAddress("redis://localhost:6379");//构造RedissonRedissonClient redisson = Redisson.create(config);RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小bloomFilter.tryInit(100000000L,0.03);//将zhuge插入到布隆过滤器中bloomFilter.add("zhuge");//判断下面号码是否在布隆过滤器中System.out.println(bloomFilter.contains("guojia"));//falseSystem.out.println(bloomFilter.contains("baiqi"));//falseSystem.out.println(bloomFilter.contains("zhuge"));//true}
}
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,布隆过滤器缓存过滤伪代码:
//初始化布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);//把所有数据存入布隆过滤器
void init(){for (String key: keys) {bloomFilter.put(key);}
}String get(String key) {// 从布隆过滤器这一级缓存判断下key是否存在Boolean exist = bloomFilter.contains(key);if(!exist){return "";}// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);// 如果存储数据为空, 需要设置一个过期时间(300秒)if (storageValue == null) {cache.expire(key, 60 * 5);}return storageValue;} else {// 缓存非空return cacheValue;}
}
注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据。
缓存失效(击穿)(原因:同一时间失效 解决:设置随机失效时间)
由于大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大甚至挂掉,对于这种情况我们在批量增加缓存时最好将这一批数据的缓存过期时间设置为一个时间段内的不同时间。
String get(String key) {// 从缓存中获取数据String cacheValue = cache.get(key);// 缓存为空if (StringUtils.isBlank(cacheValue)) {// 从存储中获取String storageValue = storage.get(key);cache.set(key, storageValue);//设置一个过期时间(300到600之间的一个随机数)int expireTime = new Random().nextInt(300) + 300;if (storageValue == null) {cache.expire(key, expireTime);}return storageValue;} else {// 缓存非空return cacheValue;}
}
缓存雪崩
原因:缓存层不能提供服务(如大量并发缓存层支撑不住)
缓存雪崩指的是缓存层支撑不住或宕掉后, 流量会像奔逃的野牛一样, 打向后端存储层。
由于缓存层承载着大量请求, 有效地保护了存储层, 但是如果缓存层由于某些原因不能提供服务(比如超大并发过来,缓存层支撑不住,或者由于缓存设计不好,类似大量请求访问bigkey,导致缓存能支撑的并发急剧下降), 于是大量请求都会打到存储层, 存储层的调用量会暴增, 造成存储层也会级联宕机的情况。
预防和解决缓存雪崩问题, 可以从以下三个方面进行着手。
1) 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster。
2) 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。
比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
3) 提前演练。
在项目上线前, 演练缓存层宕掉后, 应用以及后端的负载情况以及可能出现的问题, 在此基础上做一些预案设定。