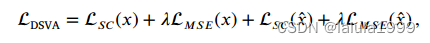(ISPRS,2023)深度语义-视觉对齐用于zero-shot遥感图像场景分类
文章目录
- 相关论文
- 摘要
- 引言
- 类别嵌入局限性——问题1
- 普通ZSL模型局限性——问题2
- 自动属性注释过程——对应问题1
- 深度语义-视觉对齐(DSVA)模型——对应问题2
- 基于遥感多模态相似性的自动属性标注
- 属性词汇表构造
- 使用CLIP模型自动标注属性
- 对CLIP模型进行训练和微调
- 用于zero-shot学习的深度语义-视觉对齐模型
- 问题定义
- Vision transformer
- Visual-attribute mapping module视觉属性映射模块
- Attention concentrating (AC) module注意力聚焦模块
- 训练损失
相关论文
(ISPRS,2023)深度语义-视觉对齐用于zero-shot遥感图像场景分类
(CVPR,2022)ZegFormer:基于解耦的zero-shot语义分割
(CVPR,2023)PADing:通用zero-shot分割的基元生成与语义对齐
(CVPR,2023)ZegCLIP: 使用CLIP进行单阶段零样本语义分割
(NeurIPS,2019)【代码复现】Zero-Shot Semantic Segmentation零样本语义分割
摘要
深度神经网络在遥感图像分类方面取得了令人期待的进展,其中训练过程需要大量的每个类别样本。然而,考虑到遥感目标数据库的动态增长,为每个遥感类别注释标签是耗时且不切实际的。零样本学习(ZSL)允许识别在训练过程中未见过的新类别,为上述问题提供了有希望的解决方案。
然而,先前的ZSL模型主要依赖于手动标注的属性或从语言模型中提取的词嵌入来将知识从已见类别转移到新类别。这些类别嵌入可能在视觉上不可检测,而且标注过程耗时且劳动密集。此外,先驱性的ZSL模型使用在ImageNet上预训练的卷积神经网络,这些网络主要关注图像中出现的主要对象,忽视了在遥感场景分类中也很重要的背景上下文。
为了解决上述问题,我们提出了自动收集可视检测属性的方法。我们通过描述属性与图像之间的语义-视觉相似性来为每个类别预测属性。通过这种方式,属性注释过程由机器自动完成,而不是像其他方法中那样由人工完成。此外,我们提出了一种深度语义-视觉对齐(DSVA)模型,利用Transformer中的自注意机制将局部图像区域关联起来,整合背景上下文信息进行预测。DSVA模型进一步利用属性注意力图来关注在ZSL中进行知识转移所必需的信息丰富的图像区域,并将视觉图像映射到属性空间进行ZSL分类。
通过大量实验证明,我们的模型在一个具有挑战性的大规模遥感场景分类基准测试中明显优于其他最先进的模型。此外,我们定性验证了由我们的网络注释的属性既具有类别区分性又具有语义相关性,这有利于零样本知识转移。
引言
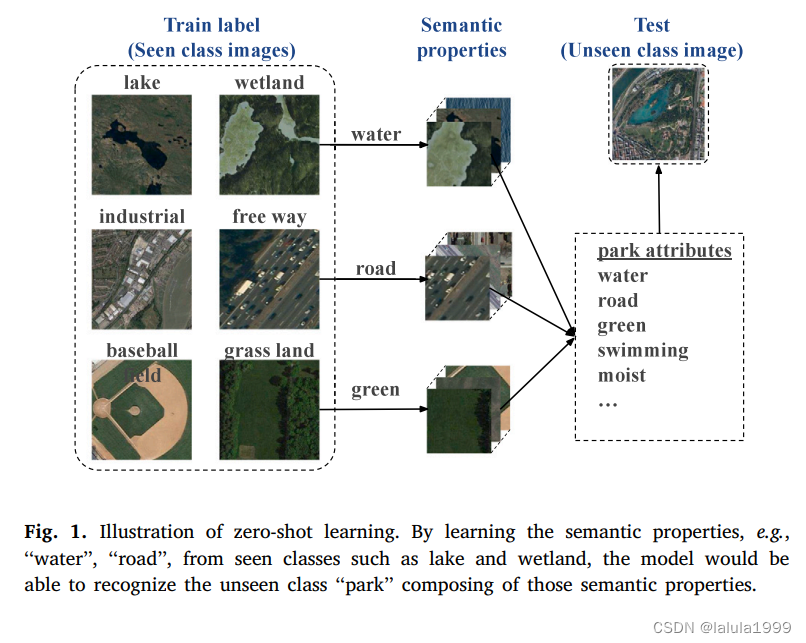
通过学习每个已见类别的语义知识所展示的视觉属性(例如,“水”,“道路”和“绿色”),该模型能够识别由该语义知识组成的未见类别,例如公园。样本学习的两个关键因素是类别嵌入和ZSL模型。
类别嵌入局限性——问题1
以往改进类别嵌入的尝试有两个方面,手动标注的属性和来自预训练语言模型的语义嵌入。属性是物体的特征属性,既可人类解释,又能在不同类别之间进行区分。因此,描述每个类别特征的属性嵌入已成为ZSL中最常用和最强大的类别嵌入。手动标注属性通常是一个两步过程,耗时且劳动密集。
一些先驱者通过用从预训练语言模型(例如word2vec、glove和BERT)中提取的语义类别嵌入或为RS场景构建的知识图中提取的语义嵌入替换属性来解决这个问题。然而,这些嵌入的每个维度都不包含具体的语义属性,也不能被视觉检测到,因此导致ZSL性能较差。
普通ZSL模型局限性——问题2
普通ZSL模型在RS场景分类任务中的泛化能力有限,这是由于RS场景具有以下特点:
- 与通常关注局部对象的普通光学图像不同,全局上下文和局部对象之间的交互信息都很重要。
- RS图像具有高的类间差异和类内相似性,因此要求ZSL模型集中于类内区分特征和类间共享特征。
- CNN网络天然具有较小的感受野,其设计侧重于局部对象特征,无法充分相关全局和局部信息以用于大规模RS场景。
自动属性注释过程——对应问题1
使用CLIP模型预测遥感多模态属性(RSMM-Attributes)用于遥感场景分类。
我们首先构建一个包含具有丰富语义和视觉信息的属性的属性词汇,用于RS场景分类。为了确保每个类别的属性嵌入在视觉上可检测,属性标注过程通过计算属性和示例图像之间的语义-视觉相似性来完成。CLIP模型是使用包含图像和相应文本描述的大规模RS数据集进行预训练的,因此能够将语义文本和视觉RS图像关联在一个共同的空间中。通过这种方式,用于标注的劳动密集型过程被自动模型取代,大大减少了时间消耗。
深度语义-视觉对齐(DSVA)模型——对应问题2
使用RSMM-Attributes在已见和未见类别之间转移知识,并在考虑图像的局部细节和全局上下文的情况下执行ZSL。我们采用了一个视觉Transformer,它使用局部图像区域之间的长程交互来提取图像表示。
为了将语义属性与视觉特征关联起来,我们学习编码每个属性的视觉特性的属性原型。同时,通过计算原型与视觉图像特征之间的相似性,生成属性注意力图,并通过计算图像-属性相似性准确地将图像映射到属性空间。我们进一步提出了一个注意力集中模块,以关注信息丰富的属性区域。
基于遥感多模态相似性的自动属性标注
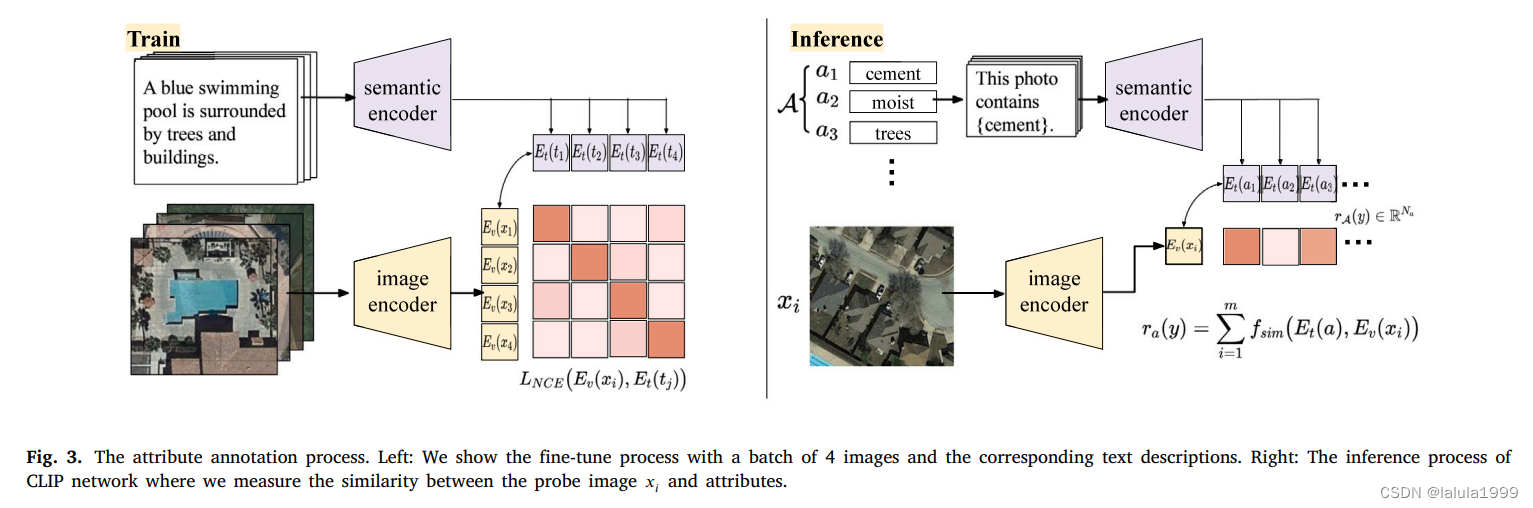
我们提出采用CLIP模型来将语义和视觉空间联系起来,为每个遥感场景类别注释遥感多模态属性(RSMM-Attribute)。
给定一个遥感场景类别 y y y和一个属性 a ∈ A a∈A a∈A ,我们的目标是为该类别注释属性值,表示属性𝑎在类别 y y y中出现的可能性,即 r a ( y ) ∈ R r_a(y) ∈ ℝ ra(y)∈R。利用CLIP模型,我们可以衡量属性 a a a和类别 y y y之间的关联强度 r a ( y ) r_a(y) ra(y)。最终,我们将获得一个包含每个类别的所有属性值的类别嵌入,表示为 r A ( y ) ∈ R N a r_A(y)∈ ℝ^{N_a} rA(y)∈RNa,其中 N a N_a Na是属性词汇表的大小。
属性词汇表构造
为了发现具有丰富语义和视觉信息的属性,我们考虑了以下六类属性:

- "颜色"组包括场景中出现的颜色(例如绿色、棕色)。
- "物体存在"组列出了可能出现的物体(例如树木、土壤)。
- "材料"组描述构成场景的材料(例如水泥、金属)。
- "纹理"组描述每个类别的纹理和图案(例如对称、平坦)。
- "形状"组指示每个场景中显示的主要形状(例如圆形、矩形)。
- "功能"组指示每个类别的社会经济功能(例如工业、农业)。
然后,我们遍历与遥感场景相关的所有属性和对象,以填充每个组,并最终获得一个带有二进制的 a a a属性的属性词汇表 N a N_a Na。
使用CLIP模型自动标注属性
如图3(右侧)所示,我们采用的CLIP模型由语义编码器 E t ( ⋅ ) E_t(⋅) Et(⋅)和视觉编码器 E v ( ⋅ ) E_v(⋅) Ev(⋅)组成,将属性名称和探测图像映射到一个共享的语义-视觉空间中。然后,通过相似度度量函数 f s i m f_{sim} fsim计算实值置信度 r a ( y ) r_a(y) ra(y),如下所示:
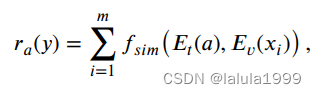
属性值 r a ( y ) r_a(y) ra(y)表示属性 a a a在类别 y y y中出现的可能性。按照CLIP的方法,我们将单个属性名称(例如,“狭窄道路”)转化为包含属性的句子(例如,“这张照片包含狭窄道路”),作为 E t ( ⋅ ) E_t(⋅) Et(⋅)的输入。相似度度量采用点积进行计算:
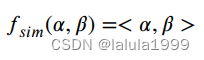
通过这种方式,我们可以很容易地代替人工将每个属性和相应的类别关联起来,并预测每个类的类语义属性为 r A ( y ) ∈ R N a r_A(y)∈ ℝ^{N_a} rA(y)∈RNa。我们将CLIP模型标注的属性表示为遥感多模态属性(RSMM-Attribute)。
对CLIP模型进行训练和微调
CLIP采用对比学习的范式,优化正样本图像-文本对(即 x i x_i xi和 t i t_i ti,其中𝑖 ∈ {1, 2, …, 𝐵})之间的余弦相似度为1,而负样本图像-文本对(即 x i x_i xi和 t j t_j tj,其中𝑖 ≠ 𝑗)之间的相似度优化为接近0。

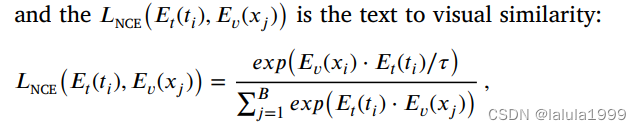
我们使用RSICD数据集中的遥感场景图像和相应描述对CLIP模型进行微调。微调过程如图3(左侧)所示,其中一批图像和相应的文本描述使用视觉编码器 E v ( ⋅ ) E_v(⋅) Ev(⋅)和语义编码器 E t ( ⋅ ) E_t(⋅) Et(⋅)编码到一个共同的空间中。然后,通过优化两个InfoNCE损失函数 L N C E L_{NCE} LNCE的和来训练编码器。
用于zero-shot学习的深度语义-视觉对齐模型
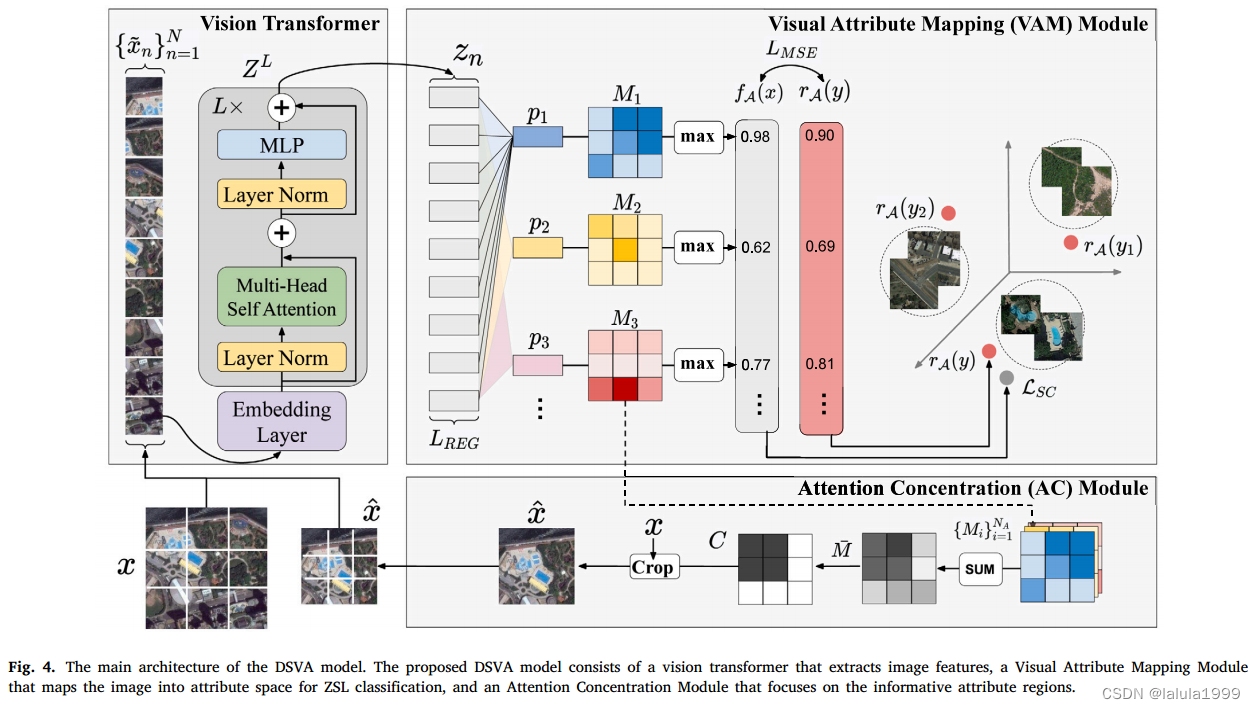
如图4所示,DSVA模型利用一种带有自注意力层的Transformer来提取图像表示,然后使用Visual-Attribute Mapping (VAM)模块将表示映射到属性空间,并根据属性相似性为每个图像预测类别标签。此外,我们提出了Attention Concentration (AC)模块,通过属性相关的注意力来集中关注信息丰富的图像区域。
问题定义
训练集 S = { x , y , r A ( y ) ∣ x ∈ X , y ∈ Y s } S=\{x,y,r_A(y)|x \in X,y \in Y^s\} S={x,y,rA(y)∣x∈X,y∈Ys}
- x x x:来自RGB图像空间 X X X的遥感图像
- y y y:来自可见类别 Y s Y^s Ys的标签
- r A ( y ) r_A(y) rA(y):上一步获得的属性嵌入向量 r A ( y ) ∈ R N a r_A(y)∈ ℝ^{N_a} rA(y)∈RNa
未见类别标签用 Y u Y^u Yu表示,未见类别的属性嵌入向量 { r A ( y ) ∣ y ∈ Y u } \{r_A(y)|y\in Y^u\} {rA(y)∣y∈Yu}也是已知的。
zero-shot学习任务旨在预测来自未见类别的图像的标签,即 X → Y u X\rightarrow Y^u X→Yu。
广义zero-shot学习(GZSL)旨在对来自可见和未见类别的图像进行分类,即 X → Y u ∪ Y s X\rightarrow Y^u \cup Y^s X→Yu∪Ys。
Vision transformer
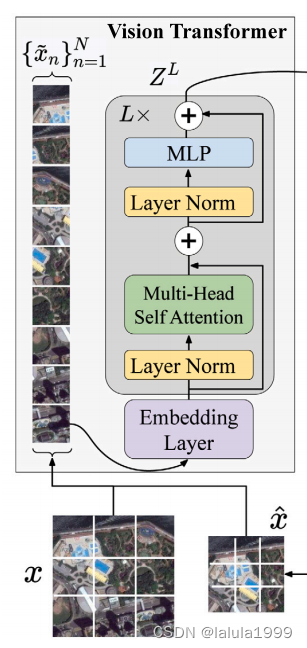
输入图像 x ∈ R H × W × C x ∈ℝ^{H×W×C} x∈RH×W×C,其中 H , W , C H,W,C H,W,C分别表示高度、宽度和通道数,被重塑为图像块的序列 { x ~ n } n = 1 N \{\tilde{x}_n\}^N_{n=1} {x~n}n=1N,且 x ~ n ∈ R H k × W k × C \tilde{x}_n\in ℝ^{\frac{H}{k}×\frac{W}{k}×C} x~n∈RkH×kW×C。 k k k是图像块的行数(或列数), N = k × k N=k×k N=k×k。
为了提取图像表示,我们首先学习一个线性嵌入层 f 0 ( ⋅ ) f_0(⋅) f0(⋅),将图像块映射到𝐷维度的块嵌入 Z 0 ∈ R N × D Z^0 ∈ℝ^{N×D} Z0∈RN×D:
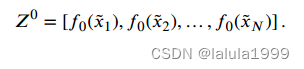
然后,图像块嵌入将被传递到Transformer编码器,它由 L L L层的多头自注意力(MHSA)子网络和多层感知器(MLP)子网络组成:
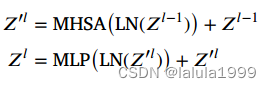
其中, l = 1 , 2 , . . . , L l=1,2,...,L l=1,2,...,L表示层的索引,每个潜在嵌入 Z 0 , Z 1 , . . . , Z L Z^0,Z^1,...,Z^L Z0,Z1,...,ZL的形状为 R N × D ℝ^{N×D} RN×D。其中,第一个输入向量 Z 0 Z^0 Z0来自以下公式。
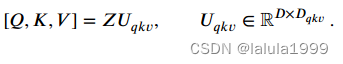
对于每个子网络,我们采用残差连接并进行层归一化(LN)操作。
在每个多头自注意力模块中,对于归一化的输入向量 L N ( Z l − 1 ) ∈ R N × D LN(Z^{l-1})\inℝ^{N×D} LN(Zl−1)∈RN×D(为简单起见,我们使用 Z Z Z表示),我们计算输入序列中每个元素的加权和,其中权重基于序列中两个元素之间的相似度。输入序列 Z ∈ R N × D Z\in ℝ^{N×D} Z∈RN×D通过线性层映射为三个张量,即查询(Q)、键(K)和值(V)。随后计算自注意力:
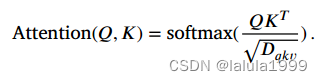

输出多头注意力:
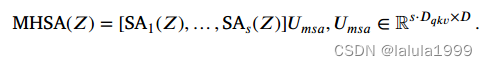
Visual-attribute mapping module视觉属性映射模块
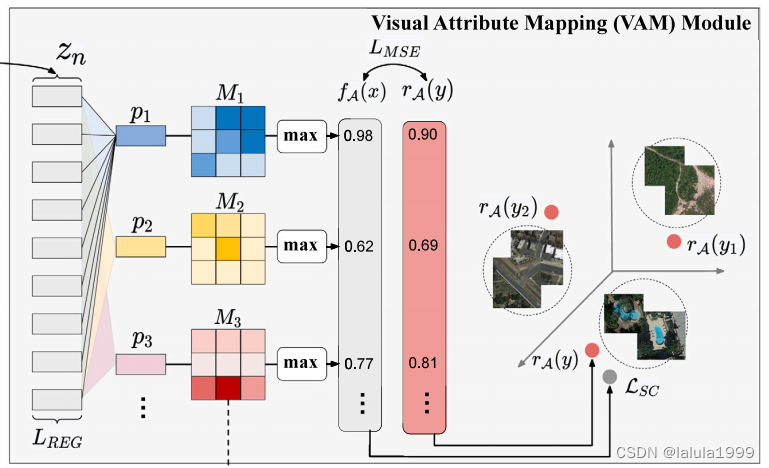
我们构建了一个视觉属性映射层,用于学习 N a N_a Na个原型向量 p 1 , p 2 , . . . P N a p_1,p_2,...P_{N_a} p1,p2,...PNa。第 i i i个原型向量 p i ∈ R D p_i\in ℝ^{D} pi∈RD编码了第 i i i个属性 a a a的视觉线索。需要注意的是,原型向量是可训练的向量。
由于原型向量应该编码每个属性的视觉特性,我们使用点积作为属性原型向量 p i p_i pi和每个局部图像嵌入 z n z_n zn之间的相似度,其中 z n z_n zn表示图像区域 x ~ n \tilde{x}_n x~n包含特定属性的可能性:
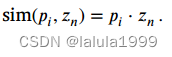
我们将第 i i i个属性与 N = k × k N=k×k N=k×k个局部图像嵌入之间的相似性值重新整形,形成一个注意力图 M i ∈ R k × k M_i\in ℝ^{k×k} Mi∈Rk×k,表示属性 a i a_i ai在图像 x x x中出现的可能性:
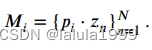
然后,我们通过最大化每个图像patch与属性原型之间的相似性来预测属性值得分:
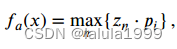
其中 f a ( x ) ∈ R f_a(x) ∈ℝ fa(x)∈R是预测的属性值。总体而言,图像 x x x的预测属性嵌入是 f A ( x ) f_A(x) fA(x)。为了将图像分配到特定的类别,我们计算预测属性嵌入与所有训练类别中的真实属性嵌入之间的兼容性得分,如下所示:
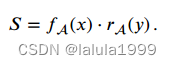
Attention concentrating (AC) module注意力聚焦模块

注意力图 M i M_i Mi指示与属性原型具有相似特性的图像区域,因此利用这些注意力图有助于模型定位属性信息并在类别之间传递属性知识。为此,我们提出了一个注意力聚焦模块,用于裁剪和突出属性信息丰富的图像区域,并再次使用裁剪后的图 x ^ \hat{x} x^来训练DSVA网络。
给定从VAM模块生成的 N a N_a Na个属性注意力图 { M i } i = 1 N a \{M_i\}^{N_a}_{i=1} {Mi}i=1Na,目标是集中关注与属性相关的图像区域并裁剪原始图像 x x x。我们首先对注意力图求和,以得到平均注意力:

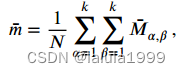
α \alpha α和 β \beta β为平均注意力的空间坐标。生成一个浓度掩模,其大小为 k × k k×k k×k,以突出显示信息图像区域:
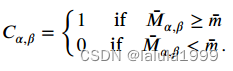
其中,属性注意力高于平均 m ˉ \bar{m} mˉ的区域被标记为1,属性注意力低 m ˉ \bar{m} mˉ的区域被标记为0。然后我们使用最小的边界框来包含 C C C中所有非零值,将原始图像 x x x裁剪成裁剪图 x ^ \hat{x} x^,并将裁剪后的图像再次输入到视觉转换器和VAM模块中。我们在每个批次中迭代运行VAM模块和AC模块,其中AC模块将帮助网络聚焦于指出不同类别之间区分性细节的有信息属性区域。
训练损失
- 语义兼容性损失
使用交叉熵损失,鼓励图像与其对应的属性标签具有较高的兼容性得分,如下所示:
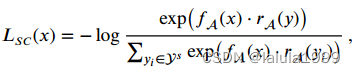
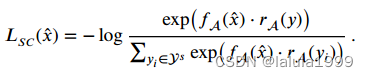
- 语义回归损失
为了促进视觉-语义映射模块的训练,我们进一步将属性预测视为回归问题,并最小化预测属性与真实属性嵌入之间的均方误差(Mean Square Error,MSE),如下所示:
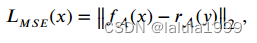
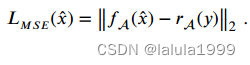
总损失如下: