OpenAI Sora:浅析文生视频模型Sora以及技术原理简介
一、Sora是什么?
Sora官方链接:https://openai.com/sora
视频模型领头羊Runway Gen 2、Pika等AI视频工具,都还在突破几秒内的连贯性,而OpenAI,已经达到了史诗级的纪录。
OpenAI,永远快别人一步!!!!
像ChatGPT成功抢了Claude的头条一样,这一次,谷歌核弹级大杀器Gemini 1.5才推出没几个小时,全世界的目光就被OpenAI的Sora抢了去。
100万token的上下文,仅靠一本语法书就学会了一门全新的语言,如此震撼的技术进步,在Sora的荣光下被衬得暗淡无光,着实令人唏嘘。
三个词总结 “60s超长长度”、“单视频多角度镜头”,“世界模型”
60s超长长度: pika和runway(视频模型领头羊)还只能生成4s视频,这60s直接拉开了差距。而且动作连续,还有一定的艺术性,没有生硬的感觉。
单视频多角度镜头: 在60s的视频内,可以在保持主角色不变的高度一致性的同时,还生成多个不同角度的分镜。Sora能在同一视频中设计出多个镜头,同时保持角色和视觉风格的一致性。
要知道,以前的AI视频,都单镜头生成的。。
世界模型: Sora有时能够模拟对世界状态产生简单影响的行为。例如,画家可以在画布上持续添加新的笔触,或者一个人吃汉堡时留下咬痕。这个就厉害了,基于虚幻引擎5(Unreal-Engine-5)的Sora它是能理解物理世界的。
二、为什么这一次Sora得到全世界这么多关注?
1. 技术上遥遥领先
跟之前的runway和pika可以说不属于一个种群了(类似于猿猴与人类),Sora是跟ChatGPT一样是有理解能力的,它可以感知真实的物理世界和自然语言。
OpenAI究竟是怎么做到的?根据官网介绍,「通过一次性为模型提供多帧的预测,我们解决了一个具有挑战性的问题。」
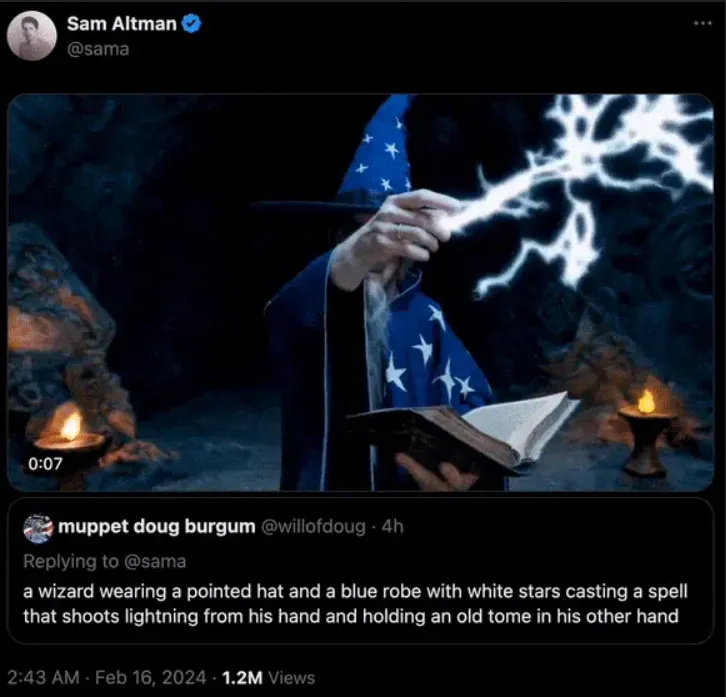
显然,这个王炸级技术有着革命般的意义,连Sam Altman都沉迷到不能自拔!
他不仅疯狂发推安利,而且还亲自下场为网友生成视频:你们随意来prompt
,我一一输出。
2. 大幅度降低了短视频制作的成本
只需一个简单的提示词,就能生成一段制作精良的60秒视频。时间之长,画面之不失违和,简直令人震惊。
支持使用图片或视频片段进行扩展,生成全新的视频。同时也支持将两个视频合并整合成一个新的视频。
原先汽车广告视频要花费大量的人力物力,是不是可以AI生成了?电影宣传片是不是也可以?短视频和短片本身就短那就更没问题了吧?(有人甚至认为tiktok都会被取代了)
但是需要创意和价值观的电影一时半会还不能被替代。因为需要好的估时剧本,好的导演,好的演员,大家配合才能演绎出一个经典的电影。
3. 生成4K图片
Sora 还能够生成图像,分辨率高达 2048×2048。除了Midjourney和Dall-E又有了个新的选择。
Sora一出,马斯克直接大呼:人类彻底完蛋了!

马斯克为什么这么说?
OpenAI科学家Tim Brooks表示,没通过人类预先设定,Sora就自己通过观察大量数据,自然而然学会了关于3D几何形状和一致性的知识。
三、Sora技术原理简介介绍
1. Sora的训练受到了大语言模型(Large Language Model)的启发。

这些模型通过在互联网规模的数据上进行训练,从而获得了广泛的能力。
Sora是一种扩散模型,它能够通过从一开始看似静态噪声的视频出发,经过多步骤的噪声去除过程,逐渐生成视频。
Sora不仅能够一次性生成完整的视频,还能延长已生成的视频。通过让模型能够预见多帧内容,团队成功克服了确保视频中的主体即便暂时消失也能保持一致性的难题。
与GPT模型类似,Sora采用了Transformer架构,从而实现了卓越的性能扩展。
OpenAI把视频和图像分解为较小的数据单元——「patches」,每个「patches」相当于GPT中的一个「token」。这种统一的数据表示方法能够在更广泛的视觉数据上训练扩散Transformer,覆盖了不同的持续时间、分辨率和纵横比。
2. Sora的独特方法如何改变视频生成
以往,生成模型的方法包括GAN、自回归、扩散模型。它们都有各自的优势和局限性。
但是!!!Sora引入的,是一种全新的范式转变——新的建模技术和灵活性,可以处理各种时间、纵横比和分辨率。
Sora所做的,是把Diffusion和Transformer架构结合在一起,创建了diffusion transformer模型。
于是,以下功能应运而生——
文字转视频:将文字内容变成视频
图片转视频:赋予静止图像动态生命
视频风格转换:改变原有视频的风格
视频时间延展:可以将视频向前或向后延长
创造无缝循环视频:制作出看起来永无止境的循环视频
生成单帧图像视频:将静态图像转化为最高2048 x 2048分辨率的单帧视频
生成各种格式的视频:支持从1920 x 1080到1080 x 1920之间各种分辨率格式
模拟虚拟世界:创造出类似于Minecraft等游戏的虚拟世界
创作短视频:制作最长达一分钟的视频,包含多个短片
3. Sora秘密成分的核心:时空patch
这种方法使Sora能够有效地处理各种视觉数据,而无需调整大小或填充等预处理步骤。
这种灵活性确保了每条数据都有助于模型的理解,就像厨师可以使用各种食材,来增强菜肴的风味特征一样。
时空patch对视频数据详细而灵活的处理,为精确的物理模拟和3D一致性等复杂功能奠定了基础。
从此,我们可以创建看起来逼真且符合世界物理规则的视频,人类也得以一窥AI创建复杂、动态视觉内容的巨大潜力。
4. 多样化数据在训练中的作用
训练数据的质量和多样性,对于模型的性能至关重要。
传统的视频模型,是在限制性更强的数据集、更短的长度和更窄的目标上进行训练的。
而Sora利用了庞大而多样的数据集,包括不同持续时间、分辨率和纵横比的视频和图像。
它能够重新创建像Minecraft这样的数字世界,以及来自Unreal或Unity等系统的模拟世界镜头,以捕捉视频内容的所有角度和各种风格。
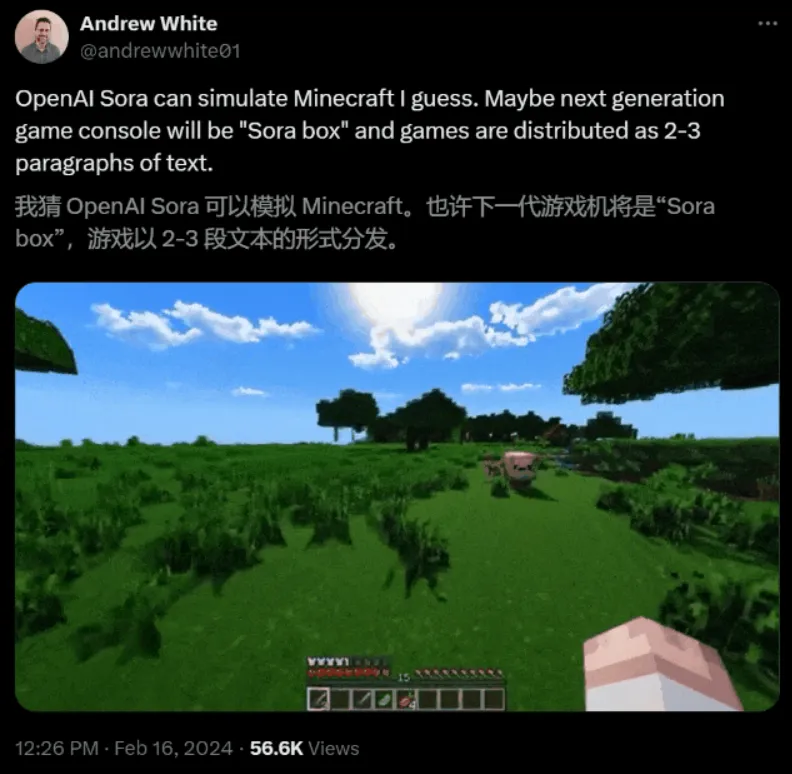
这样,Sora就成了一个「通才」模型,就像GPT-4对于文本一样。
四、Sora 怎么使用
目前 openai 官方还未开放 sora 灰度,不过根据文生图模型 DALL·E 案例,一定是先给 ChatGPT Plus 付费用户使用,需要升级 GPT Plus 可以看这个教程 : 升级 ChatGPT Plus ,一分钟完成升级
一位OpenAI员工发推表示,现在Sora只会在有限的范围内试用(刚方面的专业用户评判其伦理性),现在放出的demo主要是为了获得社会大众对它能力的反应
现在,标榜要开发负责任AGI的OpenAI,应该不会冒着风险给大众抛出一个潘多拉魔盒。
笔者认为使用Sora前我们需要有一些准备工作
在开始之前,确保您已经拥有了OpenAI账目,并获得了Sora的访问权限。准备好您想要转化成视频的文本描述,记住越详细越好。
1. Sora使用步骤一:文本描述
登录您的OpenAI账户,找到Sora的使用界面。在指定区域输入您的文本描述,可以是一个故事概述、场景描述或是具体的动作指令。
2. Sora使用步骤二:生成视频
完成文本描述和自定义设置后,点击“生成视频”按钮。Sora将开始处理您的请求,这可能需要几分钟时间。完成后,您可以预览生成的视频。
需要注意的是,截止2024年2月18日,OpenAI只向部分专业用户开放了Sora的访问权限。普通用户只能观看其发布的演示视频。
openai sora如何使用的常见问答Q&A
1.问题:Sora是什么?
Sora是由OpenAI开发的AI视频生成模型。
Sora可以根据用户提供的描述性文字生成长达60秒的高质量视频。
Sora的视频包含精细复杂的场景、生动的角色表情和复杂的镜头运动。
2.问题:Sora怎么使用?
登录OpenAI账户并找到Sora的使用界面。
在指定区域输入您的文本描述,可以是一个故事概述、场景描述或是具体的动作指令。
点击生成按钮,OpenAI Sora会根据您的文本描述生成视频。
3.问题:Sora的优势有哪些?
Sora具有极强的扩展性,基于Transformer架构,可以应用于各种场景。
Sora能够生成高质量、高清的视频,展现复杂场景的光影关系、物体的物理遮挡和碰撞关系。
Sora可以创造出包含多个角色、特定动作类型以及与主题和背景相符的详细场景。
4.问题:Sora的训练原理是什么?
Sora的训练分为两个阶段。首先,使用一个标注模型为训练集中的视频生成详细描述。
标注模型生成的描述能够更好地指导Sora生成视频。
Sora利用稳定扩散(Stable Diffusion)技术将静态噪声转换为连贯图像。
Sora模型采用初步的扩散模型生成视频长度,并逐步消除噪声完成视频。