【class14】创建自己的OCR系统
【class14】
上节回顾
在上节课中,我们主要了解了OCR的实现原理。
简单来说,OCR技术就是提取文档/图像中的文字。
接下来我们将进入实战,搭建属于自己的OCR系统~
为了更高效地学习,我们分为以下几步完成:
1. 读取图像文件
2. 接入百度智云文字识别服务
3. 调用通用文字识别
4. 提取文字识别信息
5. 写入文本文件
1. 读取图像文件
如图,我们随机选择一张试题图像,保存路径为"/Users/ocr/test.png"。

接着,直接打开并读取刚刚保存的这张图像。使用 with...as 配合open函数以rb 方式,打开路径为filePath的图像。
调用 read() 函数,读取图像中的内容。
# 将照片路径'/Users/ocr/test.png'赋值给变量filePath
filePath = '/Users/ocr/test.png'
# 使用with...as以rb方式,打开路径为filePath的图片并赋值给f
with open(filePath, 'rb') as f:
# 使用read()读取f,赋值给变量image
image = f.read()
# 使用print()输出变量image
print(image)
关于read的一点拓展
在 Python 中,read(), readline(), 和 readlines() 是用于读取文件内容的三种不同的方法。
- read():
- read() 方法用于从文件中读取指定数量的字节。如果未指定字节数量,则默认读取整个文件内容。
- 返回一个包含文件内容的字符串。
- readline():
- readline() 方法用于从文件中读取一行内容,并返回一个字符串。每次调用该方法时,它会读取文件中的下一行。
- 当读取到文件末尾时,readline() 方法会返回一个空字符串。
- readlines():
- readlines() 方法用于从文件中读取所有行,并将其存储在一个列表中。每个列表元素对应文件中的一行。
- 返回一个包含文件内容的列表,每个元素是文件的一行内容。
下面是这三种方法的简单示例用法:
# 假设有一个名为 "example.txt" 的文本文件,内容如下:
# Hello, World!
# This is a test file.
# Python is awesome.
# 使用 read() 方法读取整个文件内容
with open("example.txt", "r") as file:
content = file.read()
print(content)
# 使用 readline() 方法逐行读取文件内容
with open("example.txt", "r") as file:
line = file.readline()
while line != "":
print(line.strip()) # 删除行尾的换行符
line = file.readline()
# 使用 readlines() 方法读取所有行,并存储在列表中
with open("example.txt", "r") as file:
lines = file.readlines()
for line in lines:
print(line.strip()) # 删除行尾的换行符
2. 接入百度智云文字识别服务
读取完图像内容,在识别文字之前,我们需要先找到一个智能识别文字的方式:
接入百度智能云文字识别服务,然后调用这个服务进行识别。与图像识别一样,百度智能云也为文字识别提供了很多接口。
这些接口都能实现文字识别的功能。

在这里,我们「接入百度智云文字识别服务」同样只需3步:
a. 创建文字识别应用
b. 获取AppID、API Key和Secret Key
c. 创建文字识别客户端
a. 创建文字识别应用
登录已创建的百度账号。
进入【文字识别】页面以后,我们需要通过【创建应用】功能,创建一个属于我们自己的文字识别应用。

在【创建应用】页面:
1. 为你的应用设定名称;
2. 领取接口的免费额度;
3. 对应用进行简短的描述;
4. 填写完毕后,选择【立即创建】完成操作。

b. 获取AppID、API Key和Secret Key
创建完成后,点击「查看应用详情」就可以看到AppID、API Key和Secret Key。
我们需要使用这三个ID来调用对应的API。

c. 创建文字识别客户端
在之前的项目中,我们已经安装好了 Python SDK。
现在直接导入和新建AipOcr即可创建文字识别客户端。
创建文字识别客户端
代码的作用
AipOcr是OCR的Python SDK客户端,为使用OCR的开发人员提供了一系列的交互方法。
在使用之前,我们需要先创建它。
# 从aip中导入AipOcr
from aip import AipOcr
# 将AppID"10252021"赋值给变量APP_ID
APP_ID = '10252021'
# 将API Key"ZHe7788sh11GEjIAdEKeY"赋值给变量API_KEY
API_KEY = 'ZHe7788sh11GEjIAdEKeY'
# 将Secret Key"JMMzHe7788BUSH1ZhEnM1YUEhh"赋值给变量SECRET_KEY
SECRET_KEY = 'JMMzHe7788BUSH1ZhEnM1YUEhh'
# 新建一个AipOcr,并赋值给变量client
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
3.调用通用文字识别
接下来,我们就可以调用接口来实现文字识别啦~
为了更准确、通用,这里选择「通用文字识别(高精度版)」这个接口来搭建OCR系统。
「通用文字识别(高精度版)」能更高精度地识别图片中的文字信息。
即对输入的一张图片,识别出所有的文字。

调用通用文字识别
代码的作用
这几行高亮的代码,利用「通用文字识别(高精度版)」接口,对一张输入图片,识别出所有文字。
代码:
# 3. 调用通用文字识别
# 如果有可选参数
# 创建字典options,并将可选参数detect_direction的值设置为"true"
options = {"detect_direction":"true"}
# 调用通用文字识别接口并把结果赋值给result
result = client.basicAccurate(image, options)
# 输出result
print(result)
设置可选参数
在调用接口时,规定了可选参数需要以字典的形式传入函数中,所以创建了字典options。
这里提供的可选参数有2个:
detect_direction和probability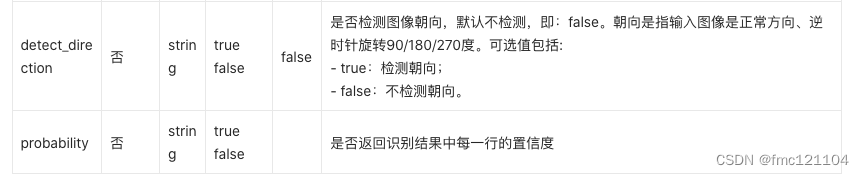
示例中添加了参数detect_direction,将其设置为"true",就能检测图像的朝向。
待识别的图像
必选参数image,图像数据,支持jpg/png/bmp格式
要求大小不超过4M,最短边至少15px,最长边最大4096px,否则会识别失败。
调用通用文字识别
对刚刚新建的AipOcr对象--client,使用basicAccurate( )函数。
将待识别的图像必选参数image和可选参数options传入到该函数中即可。

这么多的参数当然不是每一个都需要。
我们需要的文字识别信息都存储在'words_result'中。
其他参数对我们暂时没有使用价值。

4. 提取返回结果
调用接口返回的是一个复杂的字典结构,我们将它赋值给了result。
想要从字典result中取出参数'words_result'的值,得到文字信息,可以用result['words_result']。

# 4. 提取返回结果
# 从返回结果中提取出参数words_result的值并赋值给变量ending
ending = result['words_result']
# 使用print()输出变量ending
print(ending)
参数'words_result'的值是一个列表结构,我们将它赋值给了ending。
取出列表ending的每一个元素,我们用for循环来实现。
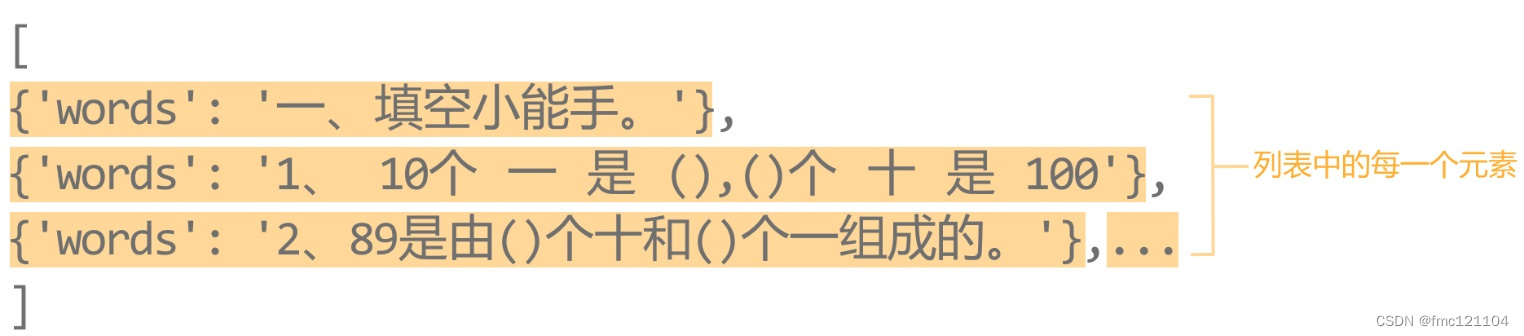
# 4. 提取返回结果
# 从返回结果中提取出参数words_result的值并赋值给变量ending
ending = result['words_result']
# 使用for循环遍历列表ending中的每一个元素
for word in ending:
# 使用print()输出word
prnt(word)
我们发现,列表中的每一个元素都包含参数'words'。
这是因为文字识别是按照单元行(从上到下)进行的,每一行的内容都与识别结果一一对应。
它们分别存储在独立的'words'中,共同组成一个列表。
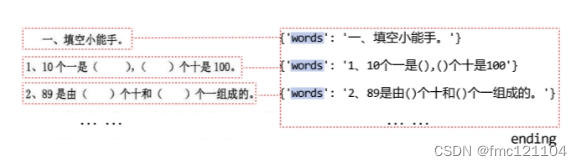
列表中的每一个元素又是一个字典,我们想要获得'words'参数中的文字信息就需要指定键'words'。

# 提取参数'words'中的文字信息
text = word['words']
# 使用print()输出text
print(text)
如图所示,最终我们获得了所有'words'参数中的文字信息。
这样,整个识别过程也就完成了。
5. 写入文件
最后,为了保存记录,我们试着将刚刚获得的所有文字信息写入最简单的文本文件,方便查看。
写入文件
代码的作用
写入文件和读取文件类似,同样需要先打开文件再写入。
这几行代码使用 with...as 语句配合 open() 函数以a方式,打开了路径为test.txt的文件,并使用write()函数写入内容"这是个测试!"。
代码:
# 使用with...as以a方式,打开路径为test.txt的文件
# 并赋值给fp
with open("test.txt","a") as fp:
# 使用write()将"这是个测试!"写入fp
fp.write("这是个测试!")
a方式
文件的打开方式用特定的字符串表示。
这里的" a " 表示写入文件时,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾。
write()函数
对文件进行写入操作,传入的参数常为字符串格式。
这里,使用write()函数在文本中写入内容"这是个测试!"。
# 5. 写入文件
# 使用with...as以a方式,打开路径为test.txt的文件并赋值给fp
with open("test.txt","a") as fp:
# 使用write()将文字信息text写入fp
fp.write(text)
# 使用print()输出"写入完成"
print("写入完成")
写入完成,我们打开test.txt文件发现:
所有的文字信息都连成一片,密密麻麻没有间隔。
这样既不利于我们查找也不方便阅读。
因此,我们可以在字符串后面添加换行符'\n' ,按行写入文字信息。
修改代码为:
# 使用write()将文字信息text换行写入fp
fp.write(text+ '\n')
这样,当我们再次打开test.txt文件就可以看到:文字信息是按照识别行的顺序依次写入的啦~当然你也可以按照自己的风格,用其他符号来分隔写入的文字信息😆