AI大模型探索之路-实战篇4:DB-GPT数据应用开发框架调研实践
目录
- 前言
- 一、DB-GPT总体概述
- 二、DB-GPT关键特性
- 1、私域问答&数据处理&RAG
- 2、多数据源&GBI
- 3、多模型管理
- 4、自动化微调
- 5、Data-Driven Multi-Agents&Plugins
- 6、隐私安全
- 三、服务器资源准备
- 1、创建实例
- 2、打开jupyterLab
- 四、DB-GPT启动
- 1、激活 conda 环境
- 2、切换到 DB-GPT 目录
- 3、导入 SQLite 样例数据
- 五、DB-GPT运行
- 1、使用命令行工具启动
- 2、访问 DB-GPT 页面
- 六、DB-GPT数据对话
- 1、安装数据库
- 2、添加数据源
- 3、绑定数据库
- 4、对话体验
- 1)选择数据对话
- 2)开始数据对话
- 3)错误处理
- 4)数据对话1
- 5)数据对话2
- 总结
前言
在当今的人工智能时代,大模型技术的迅猛发展为各行各业带来了前所未有的变革。这些大模型,以其强大的语言理解和生成能力,正在逐步成为智能化应用的核心。然而,如何高效地利用这些大模型,构建出满足各种需求的应用,仍然是一个具有挑战性的问题。DB-GPT,作为一个开源的AI原生数据应用开发框架,应运而生,旨在简化大模型应用的开发过程,让构建智能化应用变得触手可及。本文将深入介绍DB-GPT的核心功能、关键特性,并通过实战操作,展示如何利用DB-GPT进行数据应用开发。
一、DB-GPT总体概述

DB-GPT是一个开源的AI原生数据应用开发框架。目的是构建大模型领域的基础设施,通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单,更方便。

核心能力主要有以下几个部分:
RAG(Retrieval Augmented Generation),RAG是当下落地实践最多,也是最迫切的领域,DB-GPT目前已经实现了一套基于RAG的框架,用户可以基于DB-GPT的RAG能力构建知识类应用。
- GBI:生成式BI是DB-GPT项目的核心能力之一,为构建企业报表分析、业务洞察提供基础的数智化技术保障。
- 微调框架: 模型微调是任何一个企业在垂直、细分领域落地不可或缺的能力,DB-GPT提供了完整的微调框架,实现与DB-GPT项目的无缝打通,在最近的微调中,基于spider的准确率已经做到了82.5%
- 数据驱动的Multi-Agents框架: DB-GPT提供了数据驱动的自进化Multi-Agents框架,目标是可以持续基于数据做决策与执行。
- 数据工厂: 数据工厂主要是在大模型时代,做可信知识、数据的清洗加工。
- 数据源: 对接各类数据源,实现生产业务数据无缝对接到DB-GPT核心能力。
二、DB-GPT关键特性
1、私域问答&数据处理&RAG
DB-GPT支持通过内置、多文件格式上传、插件自抓取等方式自定义构建知识库,能够对海量结构化和非结构化数据进行统一向量存储与检索,实现高效的知识管理。此外,DB-GPT还实现了基于RAG的框架,用户可以基于DB-GPT的RAG能力构建知识类应用,为用户提供更加智能的问答体验。
2、多数据源&GBI
DB-GPT支持与多种数据源进行交互,包括但不限于Excel、各类数据库和数仓,同时支持生成分析报告,为用户提供深入的业务洞察。GBI,即生成式BI,是DB-GPT项目的核心能力之一,可以为构建企业报表分析、业务洞察提供基础的数智化技术保障。
3、多模型管理
DB-GPT支持海量模型,包括多种开源和API代理的大语言模型,如LLaMA/LLaMA2、Baichuan、ChatGLM、文心、通义、智谱、星火等。用户可以根据需求选择合适的模型进行应用开发,极大地提高了开发的灵活性和便捷性。
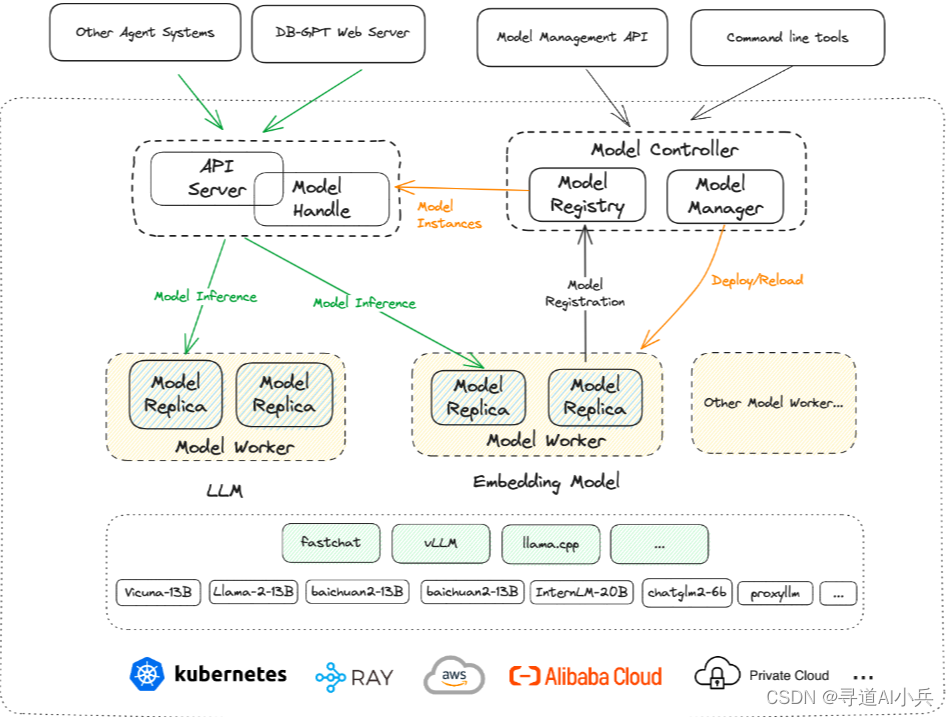
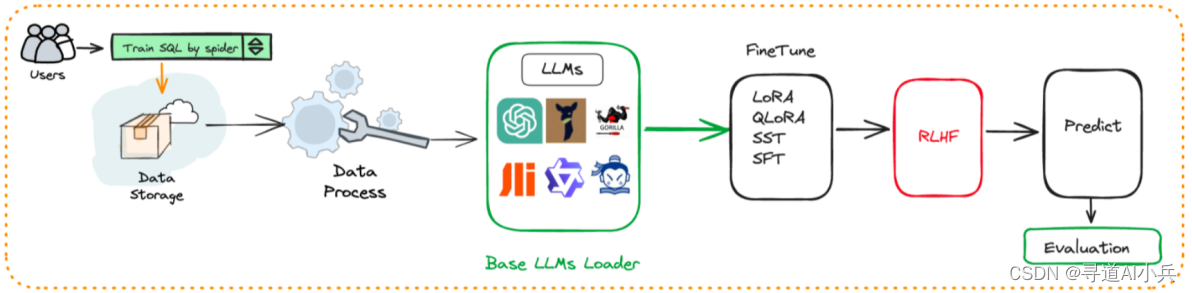
4、自动化微调
围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让TextSQL微调像流水线一样方便。
5、Data-Driven Multi-Agents&Plugins
DB-GPT支持自定义插件执行任务,并且原生支持Auto-GPT插件模型,通过Agents协议采用Agent Protocol标准,实现智能体之间的协作和任务的高效执行。这种数据驱动的自进化Multi-Agents框架,可以持续基于数据做决策与执行,大大提高了应用的智能化水平。
6、隐私安全
DB-GPT注重数据隐私和安全,通过私有化大模型、代理脱敏等多种技术保障数据的隐私安全。这一点在当今这个数据安全日益受到重视的时代,显得尤为重要。

三、服务器资源准备
DB-GPT刚好有支持AutoDL的镜像,因此直接在AutoDL 云平台时进行实践操作;在AutoDL云平台上,选择一台4090 GPU24G的服务器,为DB-GPT的运行提供必要的计算资源。打开jupyterLab,选择“终端”启动项,打开终端页面,后续所有操作都基于终端进行操作。
1、创建实例
选择一台4090 GPU24G的服务器,进行创建实例。

2、打开jupyterLab
选择”终端“启动项,打开终端页面,后续所有操作都基于终端进行操作。
四、DB-GPT启动
1、激活 conda 环境
conda activate dbgpt
2、切换到 DB-GPT 目录
cd /root/DB-GPT/
3、导入 SQLite 样例数据
bash ./scripts/examples/load_examples.sh

五、DB-GPT运行
1、使用命令行工具启动
dbgpt start webserver --port 6006
dbgpt 是 DB-GPT 项目的命令行工具,这里利用命令行工具来启动(当然,你也可以使用命令 python dbgpt/app/dbgpt_server.py --port 6006 来启动)。
这里使用 6006 端口来启动服务,这个端口方便在 AutoDL 中开启公网访问。
镜像中默认准备好了 Qwen-1_8B-Chat 和 text2vec-large-chinese 模型文件。

2、访问 DB-GPT 页面
在服务器示例列表中,找到自定义服务,点击。

点击 “访问” 后自动打开的页面如下:

六、DB-GPT数据对话
数据对话能力是通过自然语言与数据进行对话,主要是结构化与半结构化数据的对话,可以辅助做数据分析与洞察。在开始数据对话之前,我们首先需要添加数据源
1、安装数据库
步骤1:安装MySQL数据库
sudo apt-get update
sudo apt-get install mysql-server
sudo service mysql start
安装启动mysql完成之后,登录mysql(默认无密码)
mysql -u root -p

步骤2:创建数据库用户
CREATE USER 'gpt'@'localhost' IDENTIFIED BY 'gpt';
步骤3:给数据库用户赋权限
GRANT ALL PRIVILEGES ON *.* TO 'gpt'@'localhost';
FLUSH PRIVILEGES;
2、添加数据源
1)数据准备
目前DB-GPT支持多种数据库类型。 选择对应的数据库类型添加即可。这里我们选择的是MySQL作为演示,演示的测试数据:case_1_student_manager_mysql.sql
create database case_1_student_manager character set utf8;
use case_1_student_manager;CREATE TABLE students (student_id INT PRIMARY KEY,student_name VARCHAR(100) COMMENT '学生姓名',major VARCHAR(100) COMMENT '专业',year_of_enrollment INT COMMENT '入学年份',student_age INT COMMENT '学生年龄'
) COMMENT '学生信息表';CREATE TABLE courses (course_id INT PRIMARY KEY,course_name VARCHAR(100) COMMENT '课程名称',credit FLOAT COMMENT '学分'
) COMMENT '课程信息表';CREATE TABLE scores (student_id INT,course_id INT,score INT COMMENT '得分',semester VARCHAR(50) COMMENT '学期',PRIMARY KEY (student_id, course_id),FOREIGN KEY (student_id) REFERENCES students(student_id),FOREIGN KEY (course_id) REFERENCES courses(course_id)
) COMMENT '学生成绩表';INSERT INTO students (student_id, student_name, major, year_of_enrollment, student_age) VALUES
(1, '张三', '计算机科学', 2020, 20),
(2, '李四', '计算机科学', 2021, 19),
(3, '王五', '物理学', 2020, 21),
(4, '赵六', '数学', 2021, 19),
(5, '周七', '计算机科学', 2022, 18),
(6, '吴八', '物理学', 2020, 21),
(7, '郑九', '数学', 2021, 19),
(8, '孙十', '计算机科学', 2022, 18),
(9, '刘十一', '物理学', 2020, 21),
(10, '陈十二', '数学', 2021, 19);INSERT INTO courses (course_id, course_name, credit) VALUES
(1, '计算机基础', 3),
(2, '数据结构', 4),
(3, '高等物理', 3),
(4, '线性代数', 4),
(5, '微积分', 5),
(6, '编程语言', 4),
(7, '量子力学', 3),
(8, '概率论', 4),
(9, '数据库系统', 4),
(10, '计算机网络', 4);INSERT INTO scores (student_id, course_id, score, semester) VALUES
(1, 1, 90, '2020年秋季'),
(1, 2, 85, '2021年春季'),
(2, 1, 88, '2021年秋季'),
(2, 2, 90, '2022年春季'),
(3, 3, 92, '2020年秋季'),
(3, 4, 85, '2021年春季'),
(4, 3, 88, '2021年秋季'),
(4, 4, 86, '2022年春季'),
(5, 1, 90, '2022年秋季'),
(5, 2, 87, '2023年春季');
执行SQL,创建数据库,创建数据表、添加数据

2)数据检查
查看SQL之后,数据是否正常入库

3、绑定数据库
将我们创建的MySQL数据库设置为数据源

配置好数据库连接信息

4、对话体验
用户可以通过自然语言提问,DB-GPT会根据问题的语义理解,生成相应的SQL查询语句,并将查询结果以图表、表格或数据的形式返回给用户。这样的交互方式极大地简化了数据分析的复杂性,使得非技术用户也能够轻松地进行数据查询和分析。
1)选择数据对话
2)开始数据对话
此时界面上数据库已经默认设置为我们前面绑定的数据库了,也可以手动选择
3)错误处理
在数据对话的过程中,可能会遇到一些问题,比如缺少必要的Python库或者模型对某些查询的处理不够准确。例如,如果在提问咨询时遇到“RuntimeError: ‘cryptography’ package is required for sha256_password or caching_sha2_password auth methods”的错误,就需要安装相应的Python库来解决问题。通过pip install cryptography命令安装缺少的库后,需要重新启动DB-GPT以使更改生效。
pip install cryptography

安装后重新启动DB-GPT
4)数据对话1
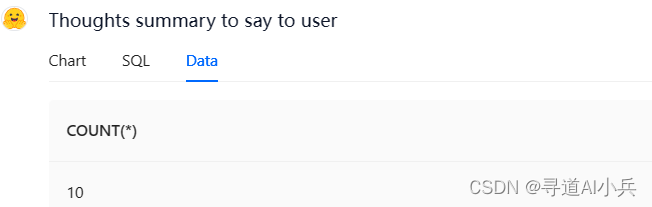
问题:请帮我查询总共有多少学生?
可以看到数据查询成功,而且还分3中方式返回Chart、SQL、Data

返回SQL语句,可以检查相关的SQL是否正确

Data页签返回执行结果
SQL执行
还可以点击上面的Editor按钮,复制SQL,直接在页面上执行,查看结果

5)数据对话2
后门连接问了两次稍微比第一次复杂一点的请求,就搞不定了。

数据对话的体验展示了DB-GPT在处理结构化和半结构化数据方面的能力,它能够理解用户的自然语言查询,并准确地转换成SQL语句,执行查询并返回结果。用户可以通过简单的问答形式,获取到他们需要的数据洞察,这对于数据分析和业务决策来说是非常有价值的。
总结
经过实战测试,DB-GPT展现了其强大的功能、对多种模型的支持以及良好的界面体验。但是在交互体验和复杂任务处理方面存在一定的不足,如果模型的稳定性和任务拆解能力的进一步提升,DB-GPT有望成为大模型应用开发领域的优秀工具。
DB-GPT的开发团队持续在优化其功能和性能,用户社区的反馈和贡献也是推动其进步的重要力量。随着大模型技术的成熟和应用的普及,我们可以期待DB-GPT在未来能够提供更加完善和强大的服务,帮助开发者轻松构建出智能、高效的应用,推动人工智能技术在各行各业的应用和发展。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!