如何确保大模型 RAG 生成的信息是基于可靠的数据源?
在不断发展的人工智能 (AI) 领域中,检索增强生成 (RAG) 已成为一种强大的技术。
RAG 弥合了大型语言模型 (LLM) 与外部知识源之间的差距,使 AI 系统能够提供更全面和信息丰富的响应。然而,一个关键因素有时会缺失——透明性。
我们如何能够确定 RAG 系统呈现的信息是基于可靠来源的?
本文介绍了一种引人注目的解决方案:使用结构化生成的带源突出显示的 RAG。这种创新的方法不仅利用了 RAG 检索相关信息的能力,还突出了支持生成答案的具体来源。喜欢本文记得收藏、点赞、关注,希望大模型技术交流的文末加入我们。
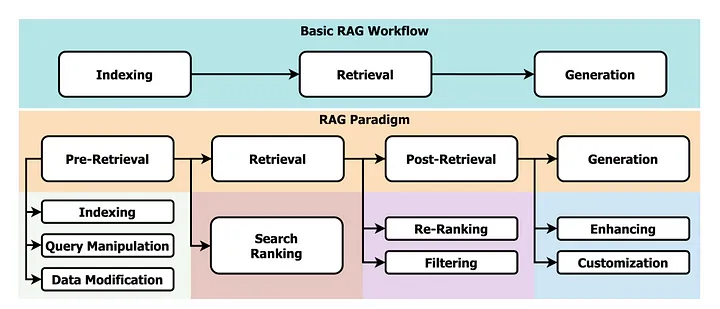
理解基础构件
在深入探讨之前,让我们先建立核心概念的基础:
结构化生成:这种技术引导大型语言模型 (LLM) 的输出遵循预定义的结构。可以将其想象为为 LLM 提供一张路线图,确保生成的文本符合特定格式。
带源突出显示的 RAG 的优势
RAG 和结构化生成的整合提供了诸多优点:
- 增强信任和透明性:突出显示的来源使用户能够评估所呈现信息的可信度。这有助于培养对系统的信任,并使用户能够深入了解支持证据。
- 改善可解释性:通过明确指出答案背后的来源,系统变得更加透明。用户能够深入了解推理过程,便于调试和进一步探索知识库。
- 更广泛的适用性:这种方法适用于用户不仅需要答案,还需要理由和清晰的审计记录的场景。它在教育、研究和法律领域尤为有价值。

代码实现
让我们深入了解使用结构化生成的带源突出显示的 RAG。
步骤 I:安装库
!pip install pandas json huggingface_hub pydantic outlines accelerate -q
步骤 II:导入库
import pandas as pd
import json
from huggingface_hub import InferenceClientpd.set_option("display.max_colwidth", None)repo_id = "meta-llama/Meta-Llama-3-8B-Instruct"llm_client = InferenceClient(model=repo_id, timeout=120)
步骤 III:提示模型
RELEVANT_CONTEXT = """
Document:The weather is really nice in Paris today.
To define a stop sequence in Transformers, you should pass the stop_sequence argument in your pipeline or model.
"""RAG_PROMPT_TEMPLATE_JSON = """
Answer the user query based on the source documents.Here are the source documents: {context}You should provide your answer as a JSON blob, and also provide all relevant short source snippets from the documents on which you directly based your answer, and a confidence score as a float between 0 and 1.
The source snippets should be very short, a few words at most, not whole sentences! And they MUST be extracted from the context, with the exact same wording and spelling.Your answer should be built as follows, it must contain the "Answer:" and "End of answer." sequences.Answer:
{{"answer": your_answer,"confidence_score": your_confidence_score,"source_snippets": ["snippet_1", "snippet_2", ...]
}}
End of answer.Now begin!
Here is the user question: {user_query}.
Answer:
"""USER_QUERY = "How can I define a stop sequence in Transformers?" prompt = RAG_PROMPT_TEMPLATE_JSON.format(context=RELEVANT_CONTEXT, user_query=USER_QUERY)print(prompt)
输出:
Answer the user query based on the source documents.Here are the source documents:
Document:The weather is really nice in Paris today.
To define a stop sequence in Transformers, you should pass the stop_sequence argument in your pipeline or model.You should provide your answer as a JSON blob, and also provide all relevant short source snippets from the documents on which you directly based your answer, and a confidence score as a float between 0 and 1.
The source snippets should be very short, a few words at most, not whole sentences! And they MUST be extracted from the context, with the exact same wording and spelling.Your answer should be built as follows, it must contain the "Answer:" and "End of answer." sequences.Answer:
{"answer": your_answer,"confidence_score": your_confidence_score,"source_snippets": ["snippet_1", "snippet_2", ...]
}
End of answer.Now begin!
Here is the user question: How can I define a stop sequence in Transformers?.
Answer:
继续代码:
answer = llm_client.text_generation(prompt,max_new_tokens=1000,
)answer = answer.split("End of answer.")[0]
print(answer)
输出:
{"answer": "You should pass the stop_sequence argument in your pipeline or model.","confidence_score": 0.9,"source_snippets": ["stop_sequence", "pipeline or model"]
}
步骤 IV:受限解码
from pydantic import BaseModel, confloat, StringConstraints
from typing import List, Annotatedclass AnswerWithSnippets(BaseModel):answer: Annotated[str, StringConstraints(min_length=10, max_length=100)]confidence: Annotated[float, confloat(ge=0.0, le=1.0)]source_snippets: List[Annotated[str, StringConstraints(max_length=30)]]# Using text_generation
answer = llm_client.text_generation(prompt,grammar={"type": "json", "value": AnswerWithSnippets.schema()},max_new_tokens=250,temperature=1.6,return_full_text=False,
)
print(answer)# Using post
data = {"inputs": prompt,"parameters": {"temperature": 1.6,"return_full_text": False,"grammar": {"type": "json", "value": AnswerWithSnippets.schema()},"max_new_tokens": 250,},
}
answer = json.loads(llm_client.post(json=data))[0]["generated_text"]
print(answer)
输出:
{"answer": "You should pass the stop_sequence argument in your modemÏallerbate hassceneable measles updatedAt原因","confidence": 0.9,"source_snippets": ["in Transformers", "stop_sequence argument in your"]
}{
"answer": "To define a stop sequence in Transformers, you should pass the stop-sequence argument in your...giÃ",
"confidence": 1,
"source_snippets": ["seq이야","stration nhiên thị ji是什么hpeldo"]
}
结论
使用结构化生成的带源突出显示的 RAG 代表了 AI 驱动的信息检索领域的重要进步。
通过为用户提供透明且有据可查的答案,这种技术培养了信任,促进了可解释性,并扩大了 RAG 系统在各个领域的适用性。
随着 AI 的不断发展,这种创新方法为用户能够自信地依赖 AI 生成的信息奠定了基础,使他们理解背后的推理和证据。
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法