(机器学习-深度学习快速入门)第一章第一节:Python环境和数据分析
文章目录
- 一:Python简介和运行环境
- (1)Python介绍
- (2)运行环境
- (3)Pycharm使用
- 二:数据分析常用库介绍
- (1)Numpy
- A:基本介绍
- B:索引和切片操作
- (2)Pandas
- A:基本介绍
- B:索引操作
一:Python简介和运行环境
(1)Python介绍
Python是一门面向对象的解释型语言,由于非常灵活且具有丰强大的库,所以在机器学习、深度学习等领域有着广泛应用。Python这门语言内容也是比较多的,但是如果你只想要用作人工智能领域,那么目前只学习其基础部分是完全够用的,所有有关Python的一些基础部分知识请移步下面的专栏
- Python基础教程
(2)运行环境
本专栏所有理论和实践的学习都离不开以下三个东西
- Python解释器(点击跳转至官网):主要作用是用于翻译、解释你所编写的Python代码
- Python Package(点击跳转至官网):是指Python的扩展包,涉及科学计算,绘图、图像处理等等;推荐安装Numpy、Scipy、Mataplotlib、Scikit-Learn、TensorFlow、pyTorch、OpenCV;安装格式为
pip install <Package Name> - 选择一款IDE(本专栏选择Pycharm):主要作用是用于翻译、解释你所编写的Python代码
注意:安装Python包时,如果包太大或者速度太慢的话可以更改镜像源,这里推荐清华镜像源,如下
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/
(3)Pycharm使用
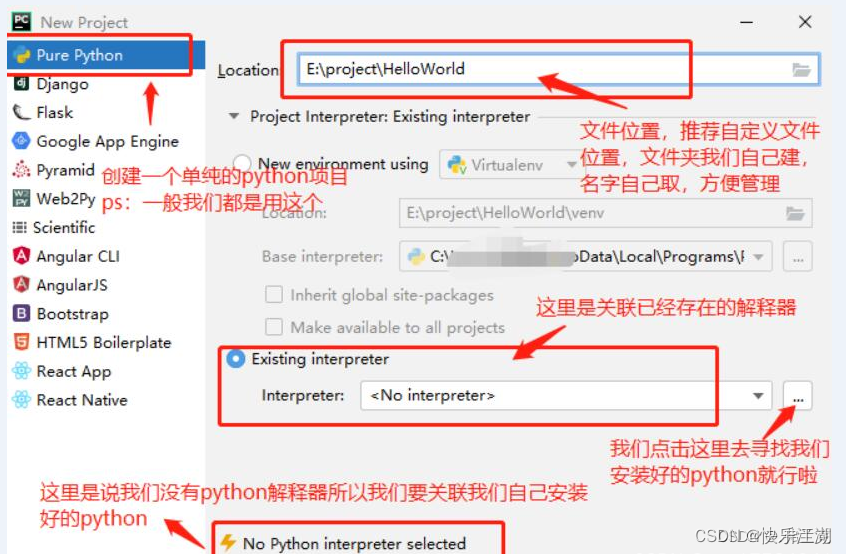
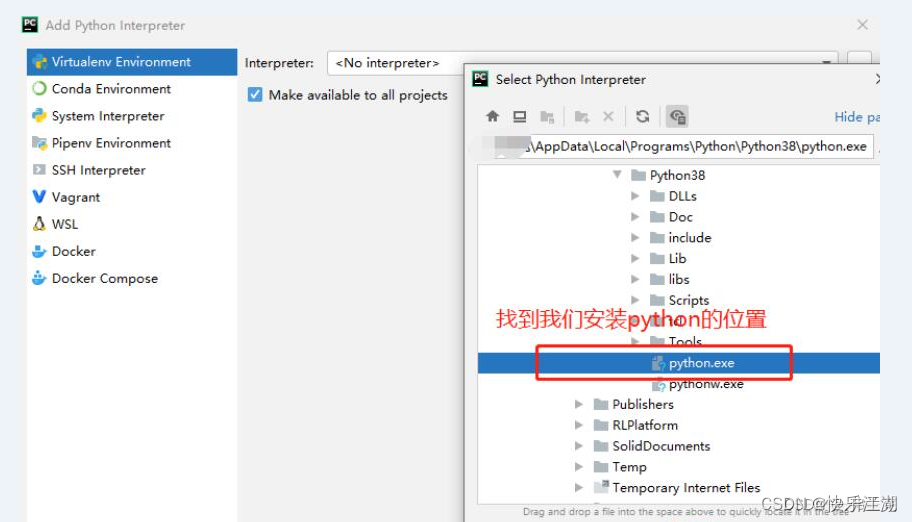
二:数据分析常用库介绍
注意
- 数据分析相关Python库是非常多,而且每一个库都很复杂,所以要想彻底学完整、学好是不太可能的,而且最关键的一点是我们经常使用到的可能只有你学到的那20%,所以这里我们只介绍相关库的最核心的用法,剩余的知识,在应用时如果不会了可以去查
- 相关库的详细介绍,可以移步此专栏:Python数据分析三板斧
(1)Numpy
Numpy:Numpy是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,它提供了许多高效的数值编程工具
import numpy as np
A:基本介绍
①:Numpy中的所有操作都围绕一个Ndarrary对象展开,其本质是一个N维数组。当然,在Python中也有一种常用的数据类型list可以表示数组,比如下面是一个二维数组
array = [[1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4], [1, 2, 3, 4]]
但list有不便于对列表内的单个对象操作(相对而言)
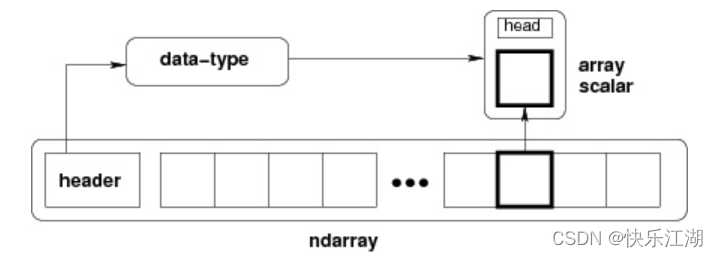
NumPy 中的N 维数组对象 ndarray是一系列同类型数据元素的集合,每个元素都有索引,从0开始。换句话说,ndarray对象是一个存放了同类型元素的多维数组,ndarray中每个元素在内存中都有相同存储大小的区域,由以下内容组成
-
一个指向数据(内存或内存映射文件中的一块数据)的指针(在Python中就是一个变量)
-
数据类型或
dtype:描述在数组中的每个元素所占大小 -
一个表示数组形状(
shape)的元组:表示各维度大小 -
一个跨度元组(
stride):其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数
这里,你可以调用array()函数创建一个简单的ndarray对象
- 为了便于演示,采用直接传入列表的方式创建
a = np.array([1, 2, 3, 4])
可以直接打印查看

②:Numpy数组(N-addary)和Python中List不是一个东西
- Python中List是可以追加任何数据类型的
a = np.linspace(0, 1, 11) # 等差数列
l = [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1]
print(type(a))
print(type(l))

③:Numpy底层使用C/C++实现,只是接口做得和Python一样。所以在使用时会存在一些细节问题,例如Python中的某些数值如果设置的不合理放在Numpy中就会溢出
import numpy as np
a = np.arange(0, 10)
print(a)
a[2] = 10000000000

所以这里要特别注意Numpy的dtype(数据类型)

a = np.arange(0, 10)
print(a.dtype)
a = a.astype(np.int64) # 数据类型转换
print(a.dtype)

④: 由于底层使用C/C++实现,所以Numpy数组进行扩容是及其不方便的,通常我么使用“堆叠”数组这种方式完成间接扩容
a = np.arange(5)
b = np.arange(100, 107)
c = np.concatenate((a, b))
print(a)
print(b)
print(c)

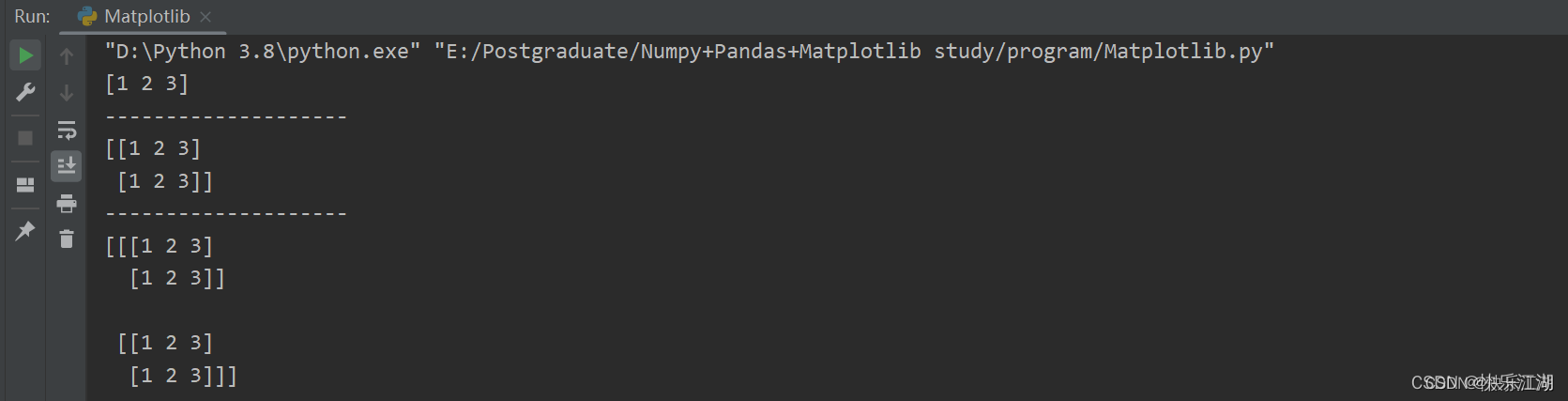
⑤: 初次接触Numpy的同学,可能对其维度比较迷惑(尤其是后面的索引和切片操作)。当然这个问题日后会细说。这里有一个很简单的方法去判断数组的维度:第一个元素前面有几个左中括号[它就是几维的,例如
a = np.array([1, 2, 3]) # 一维
b = np.array([[1, 2, 3], [1, 2, 3]]) # 二维
c = np.array([[[1, 2, 3], [1, 2, 3]], [[1, 2, 3], [1, 2, 3]]]) # 三维
print(a)
print("-"*20)
print(b)
print("-"*20)
print(c)
B:索引和切片操作
①:基本索引切片方式如下,针对一维数组进行
- 高维数组的索引和切片可能稍显复杂,大家可以查看上面的专栏
a = np.arange(5)
b = np.arange(100, 107)
c = np.concatenate((a, b))
print(c)
print(c[3])
print(c[3:6]) # 区间为左闭右开
print(c[3:]) # 从索引为3的位置开始一直截取到末尾
print(c[:6]) # 从开始位置开始,一直截取到索引为6的位置之前
print(c[4:-3]) # 从索引为4的位置开始截取到索引为-3的位置之前
print(c[::2]) # 步长为2正向截取
print(c[-5::-1]) # 反向截取
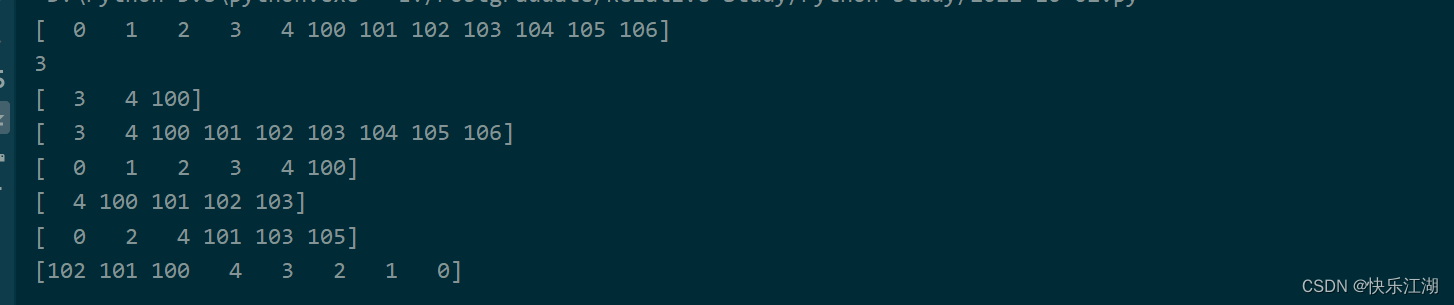
②:索引和切片也可以进行运算
a = np.arange(5)
b = np.arange(100, 107)
c = np.concatenate((a, b))
print(c)
print(c[:-1])
print(c[1:])
print(c[:-1] - c[1:])

(2)Pandas
A:基本介绍
Pandas:Pandas是2008年WesMcKinney开发出的库,是一个专门用于数据挖掘的开源Python库,它以Numpy为基础,借力Numpy模块在计算方面性能高的优势,又基于Matplotlib,可以简便的画图,而且还拥有自己独特的数据结构
-
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据
-
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征
-
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域
import pandas as pd
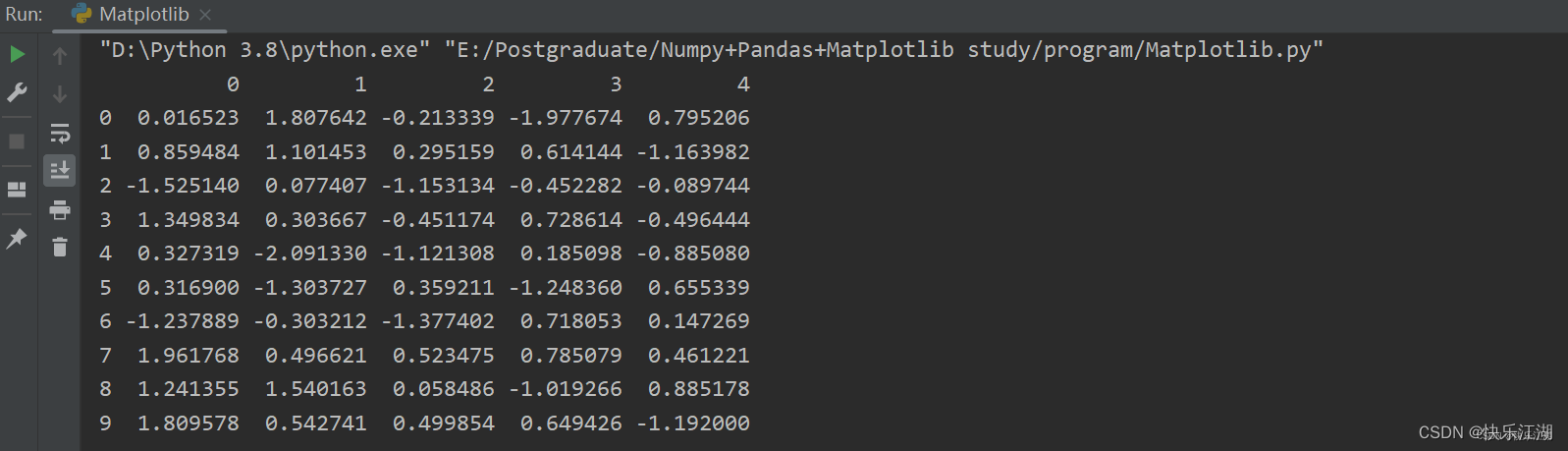
①:Pandas核心数据类型为DataFrame。Numpy注重运算,所以对于数据意义的表达没有那么清楚,比如下面用Numpy生成了一个符号正态分布的10支股票5天的涨幅情况
- 这样的数据表现形式让人有点难受,因为完全不知道它在表达什么
stock_change = np.random.normal(0, 1, (10, 5))
print(stock_change)
[[ 0.22129238 1.72192263 0.49808165 -0.70501369 -0.57315298]
[-0.05685967 -1.59493883 0.20770355 2.03934052 -0.91647225]
[-0.64659703 -1.7586049 -0.53091496 -0.95453855 0.84446516]
[ 0.02877987 1.53110344 -0.90623823 1.41938924 -1.24248129]
[-0.36990152 -0.17153907 0.24179436 0.82450977 1.1865927 ]
[-0.14524005 -0.57297533 -0.08680693 0.07105316 -0.12050658]
[ 0.50399736 1.56385492 -0.38175291 0.52144963 0.51322901]
[ 0.71534998 -0.61644881 0.15437358 0.00324533 -0.830954 ]
[-0.65036464 -1.71639338 -1.18670887 0.34092581 -0.8870423 ]
[-0.89061683 -0.93671895 -0.19911303 0.49350255 2.02240886]]
因此,我们的DataFrame就是为了让数据更有意义的显示。这里可以直接调用pd.DataFrame(),然后将numpy数组传入进去
stock_change = np.random.normal(0, 1, (10, 5))
a = pd.DataFrame(stock_change)
print(a)
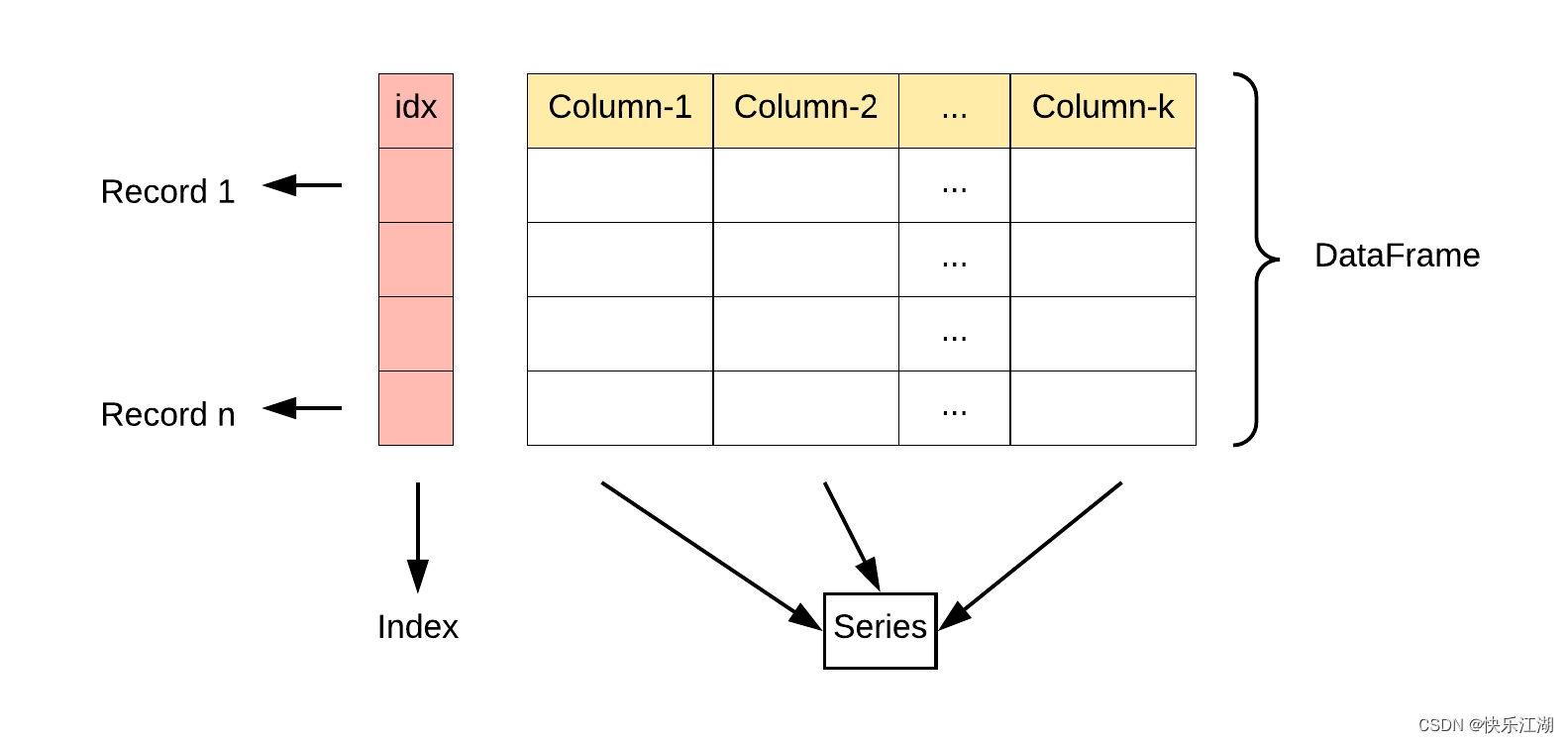
②:DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
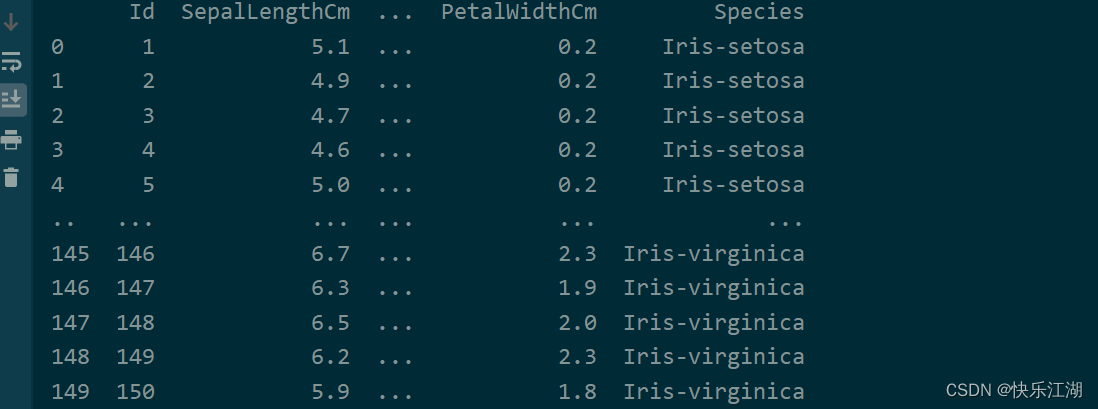
③:Pandas导入数据有很多种方式,这里以最常用的csv数据为例,导入鸢尾花数据集
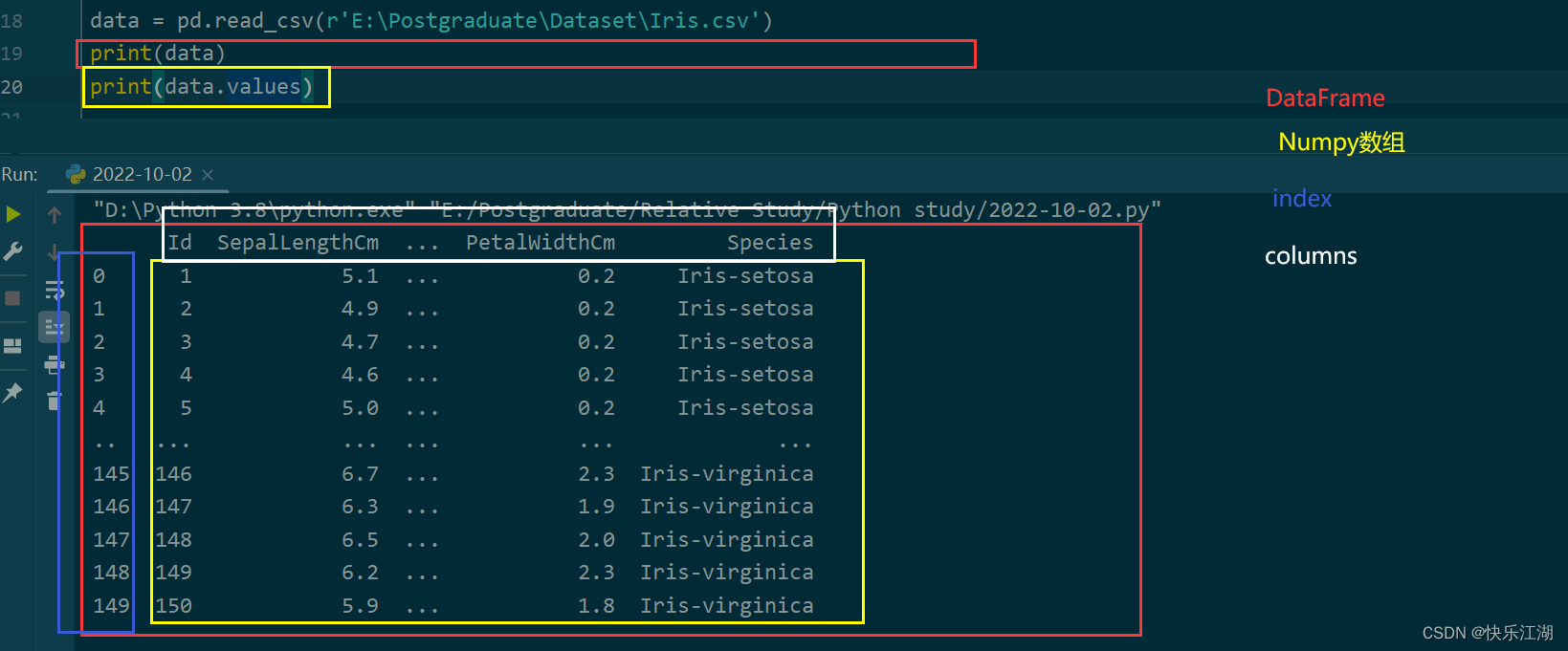
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
print(data)
其中Pandas与Numpy数组对应关系如下
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
print(data)
print(data.values)
print(data.columns)
print(data.index)
B:索引操作
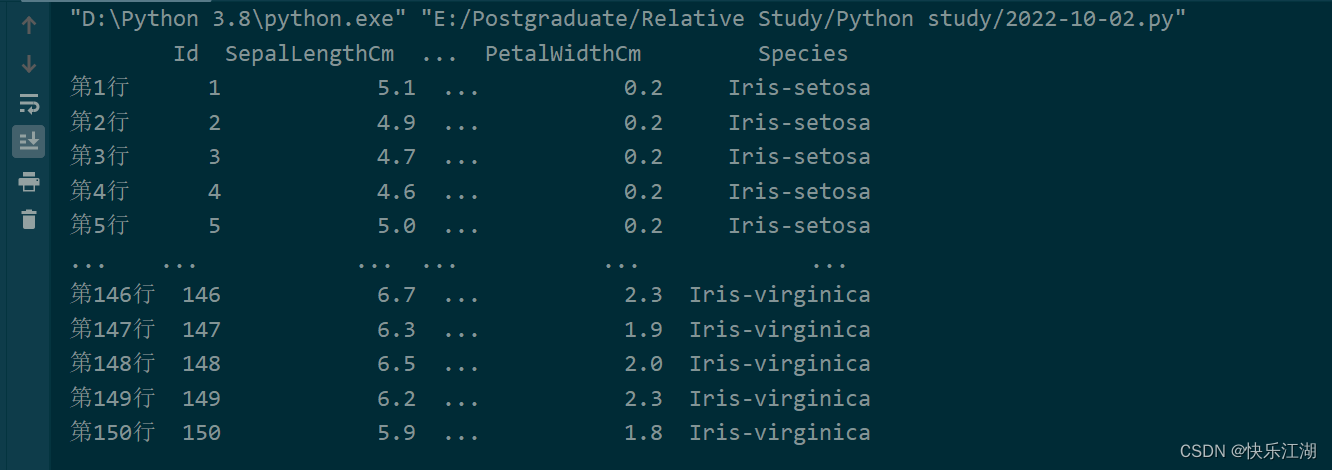
①:Pandas中index默认给出的是一个列表生成器,可以自定义索引,如下
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
new_index = []
for i in data.index:
new_index.append('第' + str(i+1) + '行')
data.index = new_index
print(data)
还有其他写法
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
new_index = []
for i in data.index:
new_index.append('第%03d行' % (i+1))
data.index = new_index
print(data)

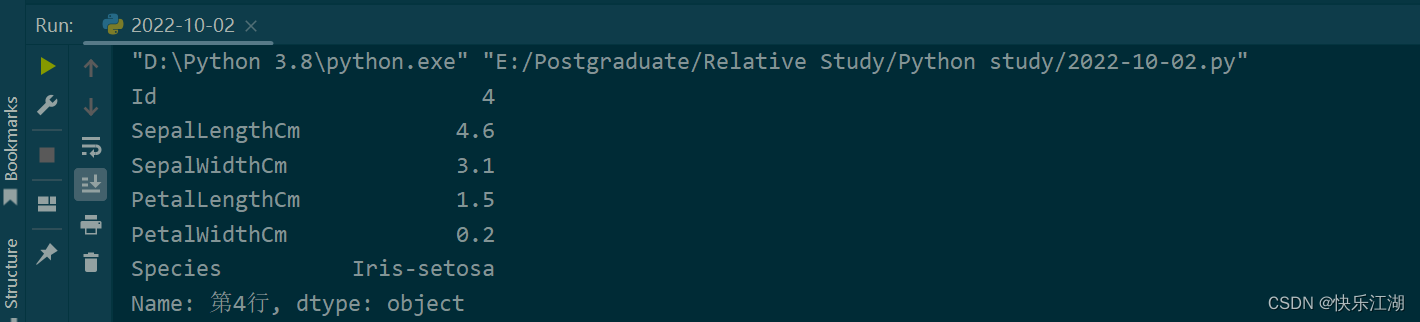
②:Pandas默认是对列进行索引而不是行。要索引行应该这样做
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
new_index = []
for i in data.index:
new_index.append("第"+str(i+1)+"行")
data.index = new_index
print(data.loc['第4行'])
进行列索引时,而Numpy索引基本一致(注意多列索引时必须加入中括号[])
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
new_index = []
for i in data.index:
new_index.append("第"+str(i+1)+"行")
data.index = new_index
print(data[['Id', 'Species']])

③:Pandas可以直接对列进行运算,例如
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
test = data['SepalLengthCm'] # 拿出seriese
print(test > 5) # 返回大于5的数据,如果大于3则显示true

data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
test = data['SepalLengthCm'] # 拿出seriese
nums = pd.value_counts((test > 5)) # 统计大于5的个数
print(nums)

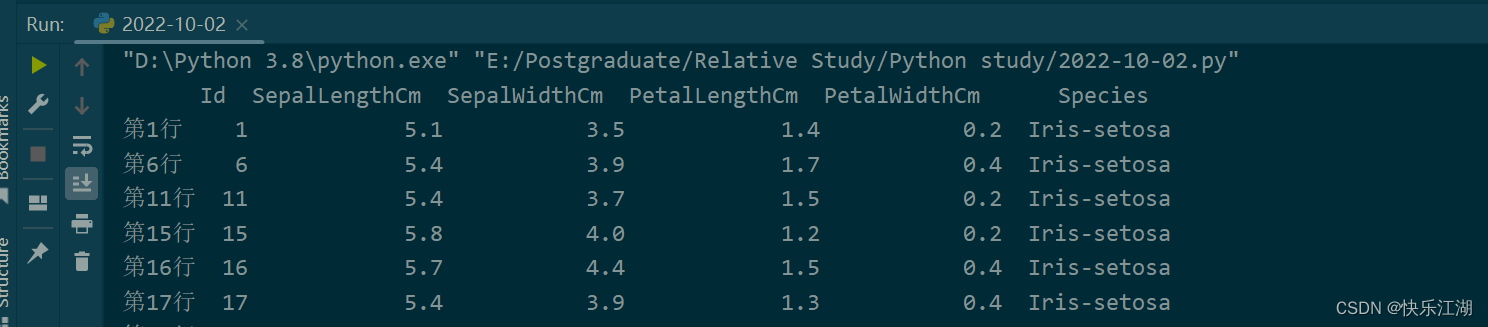
④:类似于SQL,很多时候我们需要对行列同时进行索引,所以可以这样做
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
new_index = []
for i in data.index:
new_index.append('第'+str(i+1)+'行')
data.index = new_index
select1 = data['Species'] == 'Iris-setosa' # 选择类别为Iris-setosa
select2 = data['SepalLengthCm'] > 5 # 选择SepalLengthCm>5
select = select1 & select2 # 同时满足select1和select2
ret = data.loc[select]
print(ret)
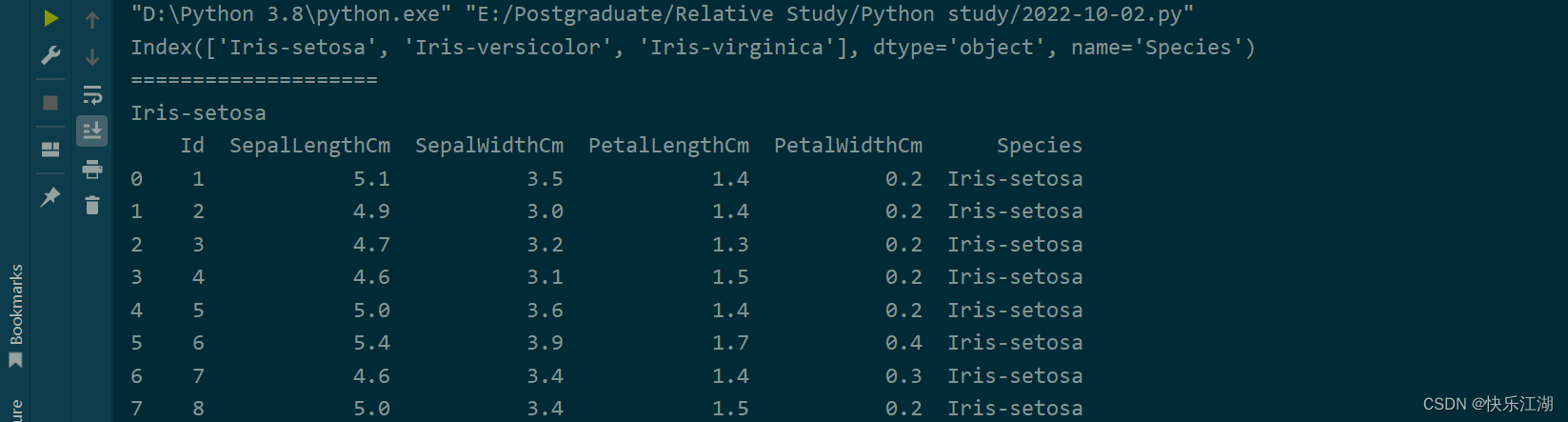
⑤:Pandas也可以对数据进行分组(groupBy),操作如下
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
data_g = data.groupby(by='Species') # 以Species对原数据进行分组,分为3组
data_g_size = data_g.size()
print(data_g_size.index)
for flower_type in data_g_size.index:
print("=" * 20)
print(flower_type)
flower_type_data = data_g.get_group(flower_type) # 通过index获取该组的数据
print(flower_type_data)
print("="*20)
⑥:如果数据量很大,那么Pandas在读入时花费的时间也会成倍增长,这不利于代码的编写。所以在实际应用中,我们常编写以下代码,首次读入后就将该数据读入缓存,下次就能直接读入了
if os.path.exists('Iris.chache'):
data = pd.read_pickle('Iris.chache')
else:
data = pd.read_csv(r'E:\Postgraduate\Dataset\Iris.csv')
data.to_pickle('Iris.chache')