Python零基础一天丝滑入门教程(非常详细)
目录
第1章 初识python
第1节 python介绍
1.为什么要学习Python?
2.python排名
3.python起源
4.python 的设计目标
第2节 软件安装
第2章 快速上手:基础知识
第1节 Python3 基础语法
Python 变量
字面量
数据类型转换
Python3 注释
数据类型
Python3 运算符
第2节 Python3 数字(Number)
Python 数字类型转换
数学函数
随机数函数
三角函数
数学常量
第3节 Python3 字符串
Python 访问字符串中的值
Python 转义字符
Python 字符串运算符
Python 的字符串内建函数
第4节 Python3 集合(数组)
Python3 列表
访问列表中的值
更新列表
删除列表元素
Python列表脚本操作符
Python 列表截取与拼接
列表比较
Python列表函数&方法
Python3 元组
访问元组
修改元组
删除元组
元组运算符
元组索引,截取
元组内置函数
注意:
Python3 字典
访问字典里的值
修改字典
删除字典元素
添加新的键值对
字典键的特性
字典内置函数&方法
Python3 集合
集合的基本操作
集合内置方法完整列表
第5节 Python3 条件与循环
Python3 条件控制
if 语句
match...case
Python3 循环语句
while 循环
for 语句
range() 函数
break 和 continue 语句及循环中的 else 子句
pass 语句
第6节 Python3 推导式
第7节 Python3 迭代器与生成器
第8节 Python3 函数和lambda(匿名函数)
Python3 函数
Python3 lambda(匿名函数)
第9节 Python3 装饰器
为何要用装饰器
什么是装饰器
用类来实现装饰器
使用 wrapt 模块编写更扁平的装饰器
常见错误
“装饰器”并不是“装饰器模式”
记得用 functools.wraps() 装饰内层函数
修改外层变量时记得使用 nonlocal
nonlocal和global到底有什么区别?
第10节 Python3 数据结构
第11节 Python3 输入和输出
第12节 Python3 错误和异常
基本结构
常见的Python异常
抛出异常
定义自定义异常
assert(断言)
基本语法
断言的作用
注意事项
断言的高级用法
with 关键字
基本语法
工作原理
示例:文件操作
上下文管理器
优点
第13节 Python3 面向对象
面向对象编程的核心概念
Python中的类定义
继承(Inheritance)
封装(Encapsulation)
多态(Polymorphism)
第14节 Python3 正则表达式
正则表达式基础
Python re模块常用功能
编译正则表达式
正则表达式的高级用法
第1章 初识python
第1节 python介绍
1.为什么要学习Python?
Python是一个非常适合初学者的编程语言,它具有许多优点,让它成为了当今最受欢迎的编程语言之一。
- 简单易学:Python的语法设计简洁清晰,容易理解和学习。它的语法结构几乎可以与自然语言媲美,因此即使是没有编程经验的人也能够相对轻松地上手。
- 丰富的库支持:Python拥有丰富的第三方库,涵盖了几乎所有领域的需求,无论是数据分析、网络编程、图形图像处理、机器学习还是人工智能等,都有成熟的库可供使用,大大提高了开发效率。
- 社区活跃:Python拥有一个庞大而活跃的社区,这意味着你在学习过程中可以轻松获取帮助、交流经验,并且有大量的开源项目可供参考学习。
- 广泛应用:Python不仅在软件开发领域应用广泛,还被广泛应用于科学计算、数据分析、人工智能、自动化测试、网络安全等领域。因此掌握Python编程技能可以让你在不同领域都有发展机会。
总的来说,学习Python不仅能够为个人技能增长打下良好基础,还可以为未来的职业发展提供更多可能性。
2.python排名
TIOBE 排行榜中 C 和 Java 一直占据着前两位,近 20 年来没有哪个语言可以撼动它们两的地位,直到这几年 Python 发展越来越快,市场占有率一直在提升,在2021年时排名第一。
3.python起源
Python的起源可以追溯到1989年,当时Guido van Rossum在圣诞节期间开始编写这门语言,他的初衷是设计一种易于阅读和使用的编程语言,以替代一些他认为不够优雅的语言。第一个公开发行版于1991年发布。
Guido van Rossum因其在Python语言设计和发展过程中的重要贡献而成为Python社区的知名人物,被尊称为“Python之父”。他在Python社区被认为是“仁慈的独裁者”,这意味着他在Python语言的发展中发挥着至关重要的领导作用,并且在必要时做出决定。他曾在Google工作,并且把大部分时间用来维护和推动Python的发展。
2020年11月,Guido van Rossum加入了微软,这进一步彰显了他在计算机科学领域的重要地位和影响力。
4.python 的设计目标
Python的设计目标包括了使编程变得简单直观,使得任何人都可以轻松学习和使用它。
吉多·范罗苏姆在1999年向DARPA提交的“Computer Programming for Everybody”计划中概述了他对Python的目标,其中包括:
- 简单直观的语言:Python被设计成一种易于理解和学习的语言,其语法结构清晰简洁,让初学者能够迅速上手,并且也为有经验的开发者提供了强大的工具。
- 开源:Python是开源的,这意味着任何人都可以查看其源代码、修改并进行贡献。这种开放性促进了Python社区的发展和壮大,也使得Python逐渐成为一门被广泛采用的编程语言。
- 易读性:Python的设计追求代码像纯英语一样易于理解,这使得代码的维护和协作变得更加容易。清晰的语法结构和丰富的标准库使得Python代码更加易读、易维护。
- 适用于日常任务:Python被设计用于处理各种类型的任务,从简单的脚本编写到大型应用程序开发,都可以在Python中实现。其灵活性和高效性使得Python成为许多开发者首选的语言之一。
这些设计目标的实现使得Python成为了一门流行的编程语言,被广泛应用于各种领域,包括Web开发、数据科学、人工智能、自动化测试等。
第2节 软件安装
pycharm专业版安装方法及环境配置(资源里有相关破解专业版的方法)
提取码: 6ag5
至于环境配置教程,自行搜索便可,这里就不浪费时间了!!!!
第2章 快速上手:基础知识
第1节 Python3 基础语法
Python 变量
变量:在程序运行时,能储存计算结果或能表示值的抽象概念。
简单的说,变量就是在程序运行时,记录数据用的。
变量,从名字中可以看出,表示“量”是可变的。所以,变量的特征就是,变量存储的数据,是可以发生改变的。
注意:变量分全局变量和局部变量!!!
全局变量:在函数外部创建的变量称为全局变量。全局变量可以被函数内部和外部的每个人使用。
示例
x = "awesome"def myfunc():x = "fantastic"print("Python is " + x)myfunc()print("Python is " + x)
这时候有同学就要问了,能不能在函数内部创建全局变量?答案是必须可以的。
在Python中,global 关键字用于在函数内部声明一个全局变量。当我们在函数内部需要修改全局变量的值时,我们需要使用 global 关键字来告诉解释器该变量是全局的,而不是局部的。
下面是一个简单的例子来说明 global 关键字的使用:
def change_global():global x1 # 声明 x1 是全局变量x1 = 20 # 修改全局变量 x1 的值change_global()
print(x1) # 输出 20
字面量
Python中常用的有6种值(数据)的类型
| 类型 | 描述 | 说明 |
| 数字(Number) | 支持 • 整数(int) • 浮点数(float) • 复数(complex) • 布尔(bool) | 整数(int),如:10、-10 |
| 浮点数(float),如:13.14、-13.14 | ||
| 复数(complex),如:4+3j,以j结尾表示复数 | ||
| 布尔(bool)表达现实生活中的逻辑,即真和假,True表示真,False表示假。 True本质上是一个数字记作1,False记作0 | ||
| 字符串(String) | 描述文本的一种数据类型 | 字符串(string)由任意数量的字符组成 |
| 列表(List) | 有序的可变序列 | Python中使用最频繁的数据类型,可有序记录一堆数据 |
| 元组(Tuple) | 有序的不可变序列 | 可有序记录一堆不可变的Python数据集合 |
| 集合(Set) | 无序不重复集合 | 可无序记录一堆不重复的Python数据集合 |
| 字典(Dictionary) | 无序Key-Value集合 | 可无序记录一堆Key-Value型的Python数据集合 |
数据类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,一般情况下只需要将数据类型作为函数名即可。
Python 数据类型转换可以分为两种:
1、隐式类型转换:在一些操作中,Python 会自动进行类型转换以保证操作的正确性。比如在整数和浮点数之间的运算中,Python 会将整数隐式地转换为浮点数进行计算。这种转换是自动完成的,不需要我们显式地调用函数。
2、显式类型转换:有时候我们需要明确地将一个数据类型转换为另一个数据类型。这时候我们可以使用内置的类型转换函数。
常见的类型转换函数有:
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
例子:
# 隐式类型转换
result = 5 + 2.0 # 整数 5 隐式转换为浮点数
print(result) # 输出 7.0# 显式类型转换
num_str = "10"
num_int = int(num_str) # 将字符串转换为整数
print(num_int) # 输出 10# 类型转换函数也可以用于转换数据类型
num_float = float(num_int) # 将整数转换为浮点数
print(num_float) # 输出 10.0
Python3 注释
在Python中,注释是用来在代码中添加说明、解释或者提醒的文本。Python支持两种类型的注释:
1、单行注释:使用 # 符号。在 # 符号后的内容会被解释器忽略,不会被执行。
# 这是一个单行注释
print("Hello, world!") # 这是另一个单行注释
2、多行注释:使用三个单引号 ''' 或者三个双引号 """ 将注释括起来。多行注释通常用于注释函数、类或者模块的功能或者说明。
'''
这是一个多行注释
可以写很多内容在这里
'''
print("Hello, world!")
数据类型
在学习字面量的时候,我们了解到:数据是有类型的。
目前在入门阶段,我们主要接触如下三类数据类型:
| 类型 | 描述 | 说明 |
| string | 字符串类型 | 用引号引起来的数据都是字符串 |
| int | 整型(有符号) | 数字类型,存放整数 如 -1,10, 0 等 |
| float | 浮点型(有符号) | 数字类型,存放小数 如 -3.14, 6.66 |
string、int、float这三个英文单词,就是类型的标准名称。
为了验证数据的类型,我们可以通过type()语句来得到数据的类型,type() 是一个内置函数,用于获取对象的类型。它返回一个表示对象类型的类型对象。在 Python 中,一切皆为对象,包括数字、字符串、列表、函数等等。
语法:
type(object)
例如:
x = 5
print(type(x)) # 输出 <class 'int'>y = "Hello, world!"
print(type(y)) # 输出 <class 'str'>z = [1, 2, 3]
print(type(z)) # 输出 <class 'list'>
type() 函数返回的是对象的类型,可以用于动态地检查变量的类型,以便在程序运行时进行相应的处理。
Python3 运算符
算术运算符
- +:加法
- -:减法
- *:乘法
- /:除法
- %:取模(取余)
- //:整除(地板除)
- **:指数(幂)
比较(关系)运算符
- ==:等于
- !=:不等于
- >:大于
- <:小于
- >=:大于等于
- <=:小于等于
赋值运算符
- =:简单赋值
- +=:加法赋值
- -=:减法赋值
- *=:乘法赋值
- /=:除法赋值
- %=:取模赋值
- //=:整除赋值
- **=:指数赋值
逻辑运算符
- and:逻辑与
- or:逻辑或
- not:逻辑非
位运算符
- &:按位与
- |:按位或
- ^:按位异或
- ~:按位取反
- <<:左移
- >>:右移
成员运算符
- in:如果在指定的序列中找到值返回 True,否则返回 False
- not in:如果在指定的序列中没有找到值返回 True,否则返回 False
身份运算符
- is:判断两个标识符是否引用自一个对象
- is not:判断两个标识符是否引用自不同对象
运算符优先级
以下表格列出了从最高到最低优先级的所有运算符, 相同单元格内的运算符具有相同优先级。 运算符均指二元运算,除非特别指出。 相同单元格内的运算符从左至右分组(除了幂运算是从右至左分组):
| 运算符 | 描述 |
|---|---|
|
| 圆括号的表达式 |
|
| 读取,切片,调用,属性引用 |
| await x | await 表达式 |
|
| 乘方(指数) |
|
| 正,负,按位非 NOT |
|
| 乘,矩阵乘,除,整除,取余 |
|
| 加和减 |
|
| 移位 |
|
| 按位与 AND |
|
| 按位异或 XOR |
|
| 按位或 OR |
|
| 比较运算,包括成员检测和标识号检测 |
|
| 逻辑非 NOT |
|
| 逻辑与 AND |
|
| 逻辑或 OR |
|
| 条件表达式 |
|
| lambda 表达式 |
|
| 赋值表达式 |
例子
# 算术运算符
a = 10
b = 3
print("a + b =", a + b) # 输出:a + b = 13
print("a - b =", a - b) # 输出:a - b = 7
print("a * b =", a * b) # 输出:a * b = 30
print("a / b =", a / b) # 输出:a / b = 3.3333333333333335
print("a % b =", a % b) # 输出:a % b = 1
print("a // b =", a // b) # 输出:a // b = 3
print("a ** b =", a ** b) # 输出:a ** b = 1000# 比较(关系)运算符
x = 5
y = 10
print("x == y:", x == y) # 输出:x == y: False
print("x != y:", x != y) # 输出:x != y: True
print("x > y:", x > y) # 输出:x > y: False
print("x < y:", x < y) # 输出:x < y: True
print("x >= y:", x >= y) # 输出:x >= y: False
print("x <= y:", x <= y) # 输出:x <= y: True# 赋值运算符
x = 5
print("x =", x) # 输出:x = 5
x += 2
print("x += 2 -> x =", x) # 输出:x += 2 -> x = 7
x **= 3
print("x **= 3 -> x =", x) # 输出:x **= 3 -> x = 343# 逻辑运算符
p = True
q = False
print("p and q:", p and q) # 输出:p and q: False
print("p or q:", p or q) # 输出:p or q: True
print("not p:", not p) # 输出:not p: False# 位运算符
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
print("a & b:", a & b) # 输出:a & b: 12
print("a | b:", a | b) # 输出:a | b: 61
print("a ^ b:", a ^ b) # 输出:a ^ b: 49
print("~a:", ~a) # 输出:~a: -61
print("a << 2:", a << 2) # 输出:a << 2: 240
print("a >> 2:", a >> 2) # 输出:a >> 2: 15# 成员运算符
list1 = [1, 2, 3, 4, 5]
print("2 in list1:", 2 in list1) # 输出:2 in list1: True
print("6 not in list1:", 6 not in list1) # 输出:6 not in list1: True# 身份运算符
x = 5
y = 5
print("x is y:", x is y) # 输出:x is y: True
print("x is not y:", x is not y) # 输出:x is not y: False
第2节 Python3 数字(Number)
Python 中有三种主要的数值类型,它们分别是整型(int)、浮点型(float)和复数(complex)。这些类型分别用于处理不同的数值数据。
1、整型 (int):代表整数,可以是正数或负数,不带小数点。在 Python 3 中,整型没有限制大小,可以根据需要存储很大的整数值。例如:
x = 10
2、浮点型 (float):代表带有小数点的数字。它由整数部分和小数部分组成,也可以用科学计数法表示。例如:
y = 3.14
3、复数 (complex):由实数部分和虚数部分组成。可以用形如 a + bj 或 complex(a, b) 表示,其中 a 和 b 都是浮点型数值。例如:
z = 2 + 3j
布尔型 (bool) 被视为整型的子类型,它只有两个值,True 和 False,在计算中被当作整型处理。例如:
is_true = True
is_false = False
Python 数字类型转换
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,我们只需要将数据类型作为函数名即可。
- int(x):将 x 转换为整数。如果 x 是浮点数,会将其向下取整;如果 x 是字符串,会尝试将其解析为整数形式。
- float(x):将 x 转换为浮点数。如果 x 是整数,会将其转换为对应的浮点数;如果 x 是字符串,会尝试将其解析为浮点数形式。
- complex(x):将 x 转换为一个复数,实部为 x,虚部为 0。
- complex(x, y):将 x 和 y 转换为一个复数,实部为 x,虚部为 y。
例子
x = 5.7
y = "10"
print(int(x)) # 输出: 5
print(int(y)) # 输出: 10print(float(x))# 输出: 5.7
print(float(y))# 输出: 10.0
print(complex(x))# 输出: (5.7+0j)
x = 2
y = 3
print(complex(x, y))# 输出: (2+3j)
数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 以浮点数形式返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| round(x [,n]) | 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。 其实准确的说是保留值将保留到离上一位更近的一端。 |
| sqrt(x) | 返回数字x的平方根。 |
随机数函数
Python 的 random 模块提供了许多用于生成随机数的函数。下面是其中一些常用的函数:
- choice(seq):从序列的元素中随机挑选一个元素。
- randrange([start,] stop [,step]):从指定范围内按指定基数递增的集合中获取一个随机数。默认的基数是1。
- random():随机生成下一个实数,它在[0, 1)范围内。
- seed([x]):改变随机数生成器的种子。如果不设置种子,Python 会使用系统时间作为默认种子。
- shuffle(lst):将序列的所有元素随机排序。
- uniform(x, y):随机生成下一个实数,它在[x, y]范围内。
例子
import random# 生成一个随机整数
random_integer = random.randrange(1, 100)
print("随机整数:", random_integer)# 生成一个随机实数
random_float = random.uniform(1.0, 10.0)
print("随机实数:", random_float)# 从列表中随机选择一个元素
seq = ["apple", "banana", "cherry"]
random_element = random.choice(seq)
print("随机选择的元素:", random_element)# 将列表元素随机打乱
random.shuffle(seq)
print("打乱后的列表:", seq)
三角函数
Python 中常用的三角函数,它们位于 math 模块中。
下面是每个函数的简要描述:
- acos(x):返回 x 的反余弦弧度值,即余弦值为 x 的角度的弧度值。
- asin(x):返回 x 的反正弦弧度值,即正弦值为 x 的角度的弧度值。
- atan(x):返回 x 的反正切弧度值,即正切值为 x 的角度的弧度值。
- atan2(y, x):返回给定的 x 和 y 坐标值的反正切值,即 (y/x) 的反正切值。
- cos(x):返回 x 弧度的余弦值。
- hypot(x, y):返回欧几里德范数,即 sqrt(x^2 + y^2)。
- sin(x):返回 x 弧度的正弦值。
- tan(x):返回 x 弧度的正切值。
- degrees(x):将弧度转换为角度。
- radians(x):将角度转换为弧度。
这些函数在处理角度和弧度之间的转换以及三角函数计算时非常有用。要使用这些函数,你需要先导入 math 模块。
import math# 计算 sin(45°)
sin_value = math.sin(math.radians(45))
print("sin(45°) =", sin_value)# 计算 arctan(1)
atan_value = math.atan(1)
print("arctan(1) =", atan_value, "弧度")
print("arctan(1) =", math.degrees(atan_value), "°")
数学常量
Python 的 math 模块还提供了一些常用的数学常量,如下所示:
- pi:数学常量 pi,代表圆周率,通常以π表示。
- e:数学常量 e,即自然常数。
import math# 圆周率 pi
print("圆周率 pi =", math.pi)# 自然常数 e
print("自然常数 e =", math.e)
第3节 Python3 字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。
Python 访问字符串中的值
在 Python 中,你可以通过索引来访问字符串中的单个字符或子字符串。
1、访问单个字符
Python 中的字符串可以像其他语言一样,通过索引来访问单个字符。索引从 0 开始,即第一个字符的索引为 0,第二个字符的索引为 1,依此类推。同时,也可以使用负数索引,从末尾开始计数,例如 -1 表示最后一个字符,-2 表示倒数第二个字符,依此类推。
示例:
s = "Hello, World!"# 访问单个字符
print(s[0]) # 输出 'H'
print(s[7]) # 输出 'W'
print(s[-1]) # 输出 '!'
2、截取子字符串
Python 支持通过切片(slice)来截取子字符串,语法为 变量[头下标:尾下标]。截取的结果包括头下标的字符,但不包括尾下标的字符。如果不指定头下标或尾下标,则默认从字符串的开头或末尾开始截取。
s = "Hello, World!"# 截取子字符串
print(s[0:5]) # 输出 'Hello'
print(s[7:]) # 输出 'World!'
print(s[:5]) # 输出 'Hello'
print(s[-6:-1]) # 输出 'World'
在上面的示例中:
s[0:5] 截取从索引 0 到 4 的子字符串,结果为 'Hello'。
s[7:] 截取从索引 7 到末尾的子字符串,结果为 'World!'。
s[:5] 截取从开头到索引 4 的子字符串,结果为 'Hello'。
s[-6:-1] 截取从倒数第 6 个字符到倒数第 2 个字符的子字符串,结果为 'World'。
Python 转义字符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。如下表:
| 转义字符 | 描述 | 实例 |
|---|---|---|
| \(在行尾时) | 续行符 | >>> print("line1 \
... line2 \
... line3")
line1 line2 line3
>>> |
| \\ | 反斜杠符号 | >>> print("\\")
\ |
| \' | 单引号 | >>> print('\'')
' |
| \" | 双引号 | >>> print("\"")
" |
| \a | 响铃 | >>> print("\a") 执行后电脑有响声。 |
| \b | 退格(Backspace) | >>> print("Hello \b World!")
Hello World! |
| \000 | 空 | >>> print("\000")>>> |
| \n | 换行 | >>> print("\n")>>> |
| \v | 纵向制表符 | >>> print("Hello \v World!")
Hello World!
>>> |
| \t | 横向制表符 | >>> print("Hello \t World!")
Hello World!
>>> |
| \r | 回车,将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 | >>> print("Hello\rWorld!")
World!
>>> print('google runoob taobao\r123456')
123456 runoob taobao |
| \f | 换页 | >>> print("Hello \f World!")
Hello World!
>>> |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | >>> print("\110\145\154\154\157\40\127\157\162\154\144\41")
Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | >>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21")
Hello World! |
| \other | 其它的字符以普通格式输出 |
Python 字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python"。
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果: HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则 | a[1:4] 输出结果 ell |
| in | 成员运算符,如果字符串中包含给定的字符返回 True | 'H' in a 输出结果 True |
| not in | 成员运算符,如果字符串中不包含给定的字符返回 True | 'M' not in a 输出结果 True |
| r/R | 原始字符串,用于不转义特殊字符 | print(r'\n') 与 print(R'\n') 均输出 \n |
| % | 格式字符串(已过时,推荐使用 f-string(f-string 是 python3.6 之后版本添加的。f-string 是一种简洁、直观的方法。通过在字符串前加上 f 或 F,你可以在字符串中直接引用变量或表达式,并在花括号 {} 中插入它们。)) | name = "Alice"
age = 30# 直接引用变量
print(f"My name is {name} and I am {age} years old.") |
Python 的字符串内建函数
Python 的字符串常用内建函数如下:
| 序号 | 方法及描述 |
|---|---|
| 1 | capitalize() |
| 2 | center(width, fillchar) 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding="utf-8", errors="strict") Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding='UTF-8',errors='strict') 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| 6 | endswith(suffix, beg=0, end=len(string)) |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False.. |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | ljust(width[, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | replace(old, new [, max]) 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串末尾的空格或指定字符。 |
| 31 | split(str="", num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 | splitlines([keepends]) 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars]) 在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars="") 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
第4节 Python3 集合(数组)
Python 编程语言中有四种集合数据类型:
- 列表(List)是一种有序和可更改的集合。允许重复的成员。
- 元组(Tuple)是一种有序且不可更改的集合。允许重复的成员。
- 集合(Set)是一个无序和无索引的集合。没有重复的成员。
- 词典(Dictionary)是一个无序,可变和有索引的集合。没有重复的成员。
选择集合类型时,了解该类型的属性很有用。
为特定数据集选择正确的类型可能意味着保留含义,并且可能意味着提高效率或安全性。
Python3 列表
列表是 Python 中最常用的数据类型之一,它是一种有序、可变的集合,可以包含不同类型的数据项。列表可以进行多种操作,包括索引、切片、加法、乘法、成员检查等。此外,Python 已经内置了确定列表长度、找出最大和最小元素的方法。
列表的灵活性使得它在实际编程中应用广泛,可以用来存储和操作各种数据。由于列表的可变性,可以方便地对其进行增加、删除和修改操作,这使得列表成为处理动态数据的理想选择。
访问列表中的值
要访问列表中的值,可以使用索引来获取特定位置的元素。在Python中,列表的索引从0开始,因此第一个元素的索引是0,第二个元素的索引是1,依此类推。可以使用方括号和索引来访问列表中的值。
例如,如果有一个名为my_list的列表,可以通过以下方式访问列表中的值:
my_list = [10, 20, 30, 40, 50]
print(my_list[0]) # 访问第一个元素,输出 10
print(my_list[2]) # 访问第三个元素,输出 30
除了使用正向索引外,还可以使用负向索引来访问列表中的元素。负向索引表示从列表末尾开始计数,例如-1表示最后一个元素,-2表示倒数第二个元素,依此类推。
my_list = [10, 20, 30, 40, 50]
print(my_list[-1]) # 访问最后一个元素,输出 50
print(my_list[-3]) # 访问倒数第三个元素,输出 30更新列表
要更新列表中的值,可以直接通过索引来修改列表中特定位置的元素,也可以使用切片来替换多个元素,也可以使用 append() 方法来添加列表项。Python 中的列表是可变的,所以可以对其进行修改。
1、直接通过索引更新单个元素:
my_list = [10, 20, 30, 40, 50]
my_list[2] = 300 # 将第三个元素修改为300
print(my_list) # 输出 [10, 20, 300, 40, 50]
2、使用切片来替换多个元素:
my_list = [10, 20, 30, 40, 50]
my_list[1:4] = [200, 300, 400] # 将第二到第四个元素替换为新的值
print(my_list) # 输出 [10, 200, 300, 400, 50]
3、使用 append() 方法来添加列表项:
my_list = [10, 20, 30, 40, 50]
my_list.append(60)
print(my_list) # 输出 [10, 20, 30, 40, 50, 60]删除列表元素
要删除列表中的元素,可以使用 del 语句或者 remove() 方法。
1、使用 del 语句删除指定索引位置的元素:
my_list = [10, 20, 30, 40, 50]
del my_list[2] # 删除索引为2的元素,即第三个元素
print(my_list) # 输出 [10, 20, 40, 50]
2、使用 remove() 方法删除指定数值的元素:
my_list = [10, 20, 30, 30, 40, 50]
my_list.remove(30) # 删除数值为30的元素
print(my_list) # 输出 [10, 20, 30, 40, 50]
使用 del 语句可以根据索引位置删除元素,而 remove() 方法可以根据元素的数值进行删除。需要注意的是,如果有多个相同数值的元素,remove() 方法只会删除第一个匹配的元素。
Python列表脚本操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print(x, end=" ") | 1 2 3 | 迭代 |
Python 列表截取与拼接
在 Python 中,可以使用切片来截取列表,并且可以通过加法运算符来拼接列表。
列表截取(切片):
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 从第二个元素到第五个元素(不包括)
sublist = my_list[1:5]
print(sublist) # 输出 [2, 3, 4, 5]# 从第三个元素开始到末尾
sublist2 = my_list[2:]
print(sublist2) # 输出 [3, 4, 5, 6, 7, 8, 9, 10]# 从开头到第四个元素(不包括)
sublist3 = my_list[:4]
print(sublist3) # 输出 [1, 2, 3, 4]
列表拼接:
list1 = [1, 2, 3]
list2 = [4, 5, 6]
concatenated_list = list1 + list2
print(concatenated_list) # 输出 [1, 2, 3, 4, 5, 6]
通过切片可以获取列表中的子集,而通过加法运算符可以将两个列表连接起来。这些操作使得列表的处理非常灵活和方便。
列表比较
在 Python 中,可以使用 operator 模块中的 eq 方法来比较两个列表是否相等。operator 模块提供了一种以函数形式表示 Python 中的内置运算符的便捷方式。
以下是使用 operator 模块的 eq 方法进行列表比较的示例:
import operatorlist1 = [1, 2, 3]
list2 = [1, 2, 3]
print(operator.eq(list1, list2))# 输出TruePython列表函数&方法
Python 中的列表函数和方法非常丰富,它们提供了许多便捷的操作来处理列表数据。下面是一些常用的列表函数和方法:
列表函数:
- len(list):返回列表元素个数。
- max(list):返回列表中的最大值。
- min(list):返回列表中的最小值。
- list(seq):将一个序列(比如元组)转换为列表。
列表方法:
- list.append(obj):在列表末尾添加新的对象。
- list.count(obj):统计某个元素在列表中出现的次数。
- list.extend(seq):在列表末尾一次性追加另一个序列中的多个值,相当于用新列表扩展原来的列表。
- list.index(obj):从列表中找出某个值第一个匹配项的索引位置。
- list.insert(index, obj):将对象插入列表的指定位置。
- list.pop([index=-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
- list.remove(obj):移除列表中某个值的第一个匹配项。
- list.reverse():反向列表中元素的顺序。
- list.sort(key=None, reverse=False):对原列表进行排序。
- list.clear():清空列表中的所有元素。
- list.copy():复制列表。
Python3 元组
在 Python 中,元组(tuple)和列表(list)非常相似,但它们有一个重要的区别:元组的元素不能被修改,而列表的元素可以被修改。
可以使用小括号 () 来创建一个元组,并在其中添加元素,多个元素之间使用逗号 , 隔开。以下是一个简单的示例:
my_tuple = (1, 2, 3, 4, 5)
另外,当元组只有一个元素时,需要在元素后面加上逗号,以明确表示这是一个元组。例如:
single_element_tuple = (1,) # 只有一个元素的元组
需要注意的是,元组虽然不可修改,但是你仍然可以对元组进行索引、切片、遍历等操作。
访问元组
在 Python 中,可以使用索引来访问元组中的元素。元组的索引从 0 开始,也可以使用负数从末尾开始反向索引。
示例:
my_tuple = (1, 2, 3, 4, 5)# 访问单个元素
print(my_tuple[0]) # 输出:1
print(my_tuple[3]) # 输出:4# 使用负数索引反向访问
print(my_tuple[-1]) # 输出:5
print(my_tuple[-2]) # 输出:4# 切片操作
print(my_tuple[1:4]) # 输出:(2, 3, 4)
print(my_tuple[:3]) # 输出:(1, 2, 3)
print(my_tuple[2:]) # 输出:(3, 4, 5)
修改元组
在 Python 中,元组是不可变的,这意味着一旦创建了元组,就不能对其进行修改。这包括不能添加、删除或修改元组中的元素。
如果需要对元组中的元素进行修改,你可以考虑使用列表(list)来代替元组。列表是可变的,可以通过索引来修改其中的元素,也可以通过方法如 append、remove 等来添加和删除元素。
以下是一个示例,展示了如何将元组转换为列表,并对列表进行修改:
my_tuple = (1, 2, 3)
my_list = list(my_tuple) # 将元组转换为列表
my_list[0] = 10 # 修改列表中的元素
print(my_list) # 输出:[10, 2, 3]
如果只是暂时需要修改元组中的元素,可以考虑创建一个新的元组来代替原有的元组。例如:
original_tuple = (1, 2, 3)
modified_tuple = (4, original_tuple[1], original_tuple[2]) # 创建一个新的元组
print(modified_tuple) # 输出:(4, 2, 3)
删除元组
在 Python 中,由于元组是不可变的数据类型,所以并不能直接删除其中的元素。一旦创建了元组,其中的元素就不能被修改或删除。
如果需要删除整个元组,可以使用 del 关键字来删除整个元组对象,例如:
my_tuple = (1, 2, 3, 4, 5)
del my_tuple # 删除整个元组对象# print(my_tuple)在这个例子中,del my_tuple 语句将会删除整个元组对象,使得之后再访问 my_tuple 将会引发一个 NameError 错误。
需要注意的是,一旦删除了整个元组对象,其中的元素也将会被销毁,无法再次访问。
元组运算符
与字符串一样,元组之间可以使用 +、+=和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
len((1, 2, 3)) | 3 | 计算元素个数 |
>>> a = (1, 2, 3) >>> b = (4, 5, 6) >>> c = a+b >>> c (1, 2, 3, 4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接,c 就是一个新的元组,它包含了 a 和 b 中的所有元素。 |
>>> a = (1, 2, 3) >>> b = (4, 5, 6) >>> a += b >>> a (1, 2, 3, 4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接,a 就变成了一个新的元组,它包含了 a 和 b 中的所有元素。 |
('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
3 in (1, 2, 3) | True | 元素是否存在 |
for x in (1, 2, 3): print (x, end=" ") | 1 2 3 | 迭代 |
元组索引,截取
当需要访问元组中的特定元素或截取其中的一部分时,可以使用索引和切片操作。
1、元组索引:
使用索引来访问元组中的单个元素,索引从 0 开始。
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[0]) # 输出:1
print(my_tuple[3]) # 输出:4
2、元组切片:
使用切片操作来获取元组中的一部分元素。
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[1:4]) # 输出:(2, 3, 4)
print(my_tuple[:3]) # 输出:(1, 2, 3)
print(my_tuple[2:]) # 输出:(3, 4, 5)
3、负数索引和切片:
也可以使用负数索引来从末尾开始访问元组中的元素。
my_tuple = (1, 2, 3, 4, 5)
print(my_tuple[-1]) # 输出:5
print(my_tuple[-2:]) # 输出:(4, 5)
元组内置函数
1、len(tuple):计算元组元素个数。
tuple1 = ('Google', 'Runoob', 'Taobao')
print(len(tuple1)) # 输出:3
2、max(tuple):返回元组中元素的最大值。
tuple2 = (5, 4, 8)
print(max(tuple2)) # 输出:8
3、min(tuple):返回元组中元素的最小值。
tuple3 = (5, 4, 8)
print(min(tuple3)) # 输出:4
4、tuple(iterable):将可迭代系列转换为元组。
list1 = ['Google', 'Taobao', 'Runoob', 'Baidu']
tuple1 = tuple(list1)
print(tuple1) # 输出:('Google', 'Taobao', 'Runoob', 'Baidu')
注意:
在Python中,元组是不可变的,这意味着元组所指向的内存中的内容不可变。
具体来说,元组的不可变性包括以下几点:
- 元组中的元素不可变:一旦元组被创建,其包含的元素不能被修改、添加或删除。例如,你无法通过索引来修改元组中的元素。
- 元组的内存地址不可变:一旦元组被创建,在元组的生命周期内,其所指向的内存地址和包含的元素都不能被改变。
这种不可变性使得元组在某些场景下非常有用,例如作为字典的键、函数的参数等。与列表相比,元组的不可变性使得其具有更轻量级的特性,能够提供更好的性能。
总之,元组的不可变性是指元组本身和其中的元素都不能被改变,这是元组与列表等可变数据类型的重要区别之一。
Python3 字典
在 Python 中,字典是由一系列键值对组成的数据结构,每个键值对之间用逗号分隔,键和值之间使用冒号分隔,整个字典则包裹在花括号中。
注意:dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。键必须是唯一的,但值则不必。值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
# 创建一个字典
d = {'name': 'Alice', 'age': 25, 'city': 'New York'}
访问字典里的值
把相应的键放入到方括号中,如下实例:
# 创建一个字典
d = {'name': 'Alice', 'age': 25, 'city': 'New York'}# 访问字典中的元素
print(d['name']) # 输出 'Alice'
print(d['age']) # 输出 25
print(d['city']) # 输出 'New York'
修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
# 创建一个字典
d = {'name': 'Alice', 'age': 25, 'city': 'New York'}# 修改字典中的值
d['age'] = 26
print(d['age']) # 输出 26删除字典元素
能删单一的元素也能清空字典,清空只需一项操作。
显式删除一个字典用del命令,如下实例:
# 创建一个字典
d = {'name': 'Alice', 'age': 25, 'city': 'New York'}# 删除字典元素
del d['age']
del d['city']# 输出字典
print(d)添加新的键值对
如下实例:
# 创建一个字典
d = {'name': 'Alice', 'age': 25, 'city': 'New York'}# 添加新的键值对
d['gender'] = 'female'
print(d) # 输出 {'name': 'Alice', 'age': 26, 'city': 'New York', 'gender': 'female'}字典键的特性
在 Python 字典中,每个键必须是唯一的,如果同一个键被赋值两次,后一个值会覆盖前一个值。这保证了字典中每个键都对应一个唯一的值。
另外,由于字典的实现方式,键必须是不可变的。这意味着可以使用数字、字符串或元组作为字典的键,因为它们是不可变的数据类型。然而,不能使用列表作为字典的键,因为列表是可变的,当然也不能用其他的可变对象作为键。
如下实例:
# 创建一个字典
my_dict = {'name': 'Alice', 'age': 25, (1, 2): 'tuple_key'}# 尝试使用列表作为字典的键
# my_dict = {[1, 2]: 'list_key'} # 这行代码会导致 TypeError: unhashable type: 'list'# 尝试使用相同的键赋值两次
my_dict = {'name': 'Bob', 'name': 'Charlie'}# 输出字典
print(my_dict) # 输出 {'name': 'Charlie'}# 尝试使用可变对象作为键
# my_dict = {'name': 'Alice', ['a', 'b']: 'list_key'} # 这行代码会导致 TypeError: unhashable type: 'list'
字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | len(dict) 计算字典元素个数,即键的总数。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> len(tinydict)
3 |
| 2 | str(dict) 输出字典,可以打印的字符串表示。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> str(tinydict)
"{'Name': 'Runoob', 'Class': 'First', 'Age': 7}" |
| 3 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 | >>> tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
>>> type(tinydict)
<class 'dict'> |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | key in dict 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回一个视图对象 |
| 7 | dict.keys() 返回一个视图对象 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 返回一个视图对象 |
| 11 | pop(key[,default]) 删除字典 key(键)所对应的值,返回被删除的值。 |
| 12 | popitem() 返回并删除字典中的最后一对键和值。 |
Python3 集合
在Python 3中,集合(set)是一个无序、不重复元素的数据结构,它支持常见的集合操作,如并集、交集、差集等。
要创建一个集合,可以使用大括号 {},并在其中添加元素,确保元素之间用逗号分隔。例如:
my_set = {1, 2, 3, 4, 5}
另外,也可以使用 set() 函数创建集合,将一个可迭代对象(比如列表或元组)作为参数传递给 set() 函数。例如:
my_set = set([1, 2, 3, 4, 5])
创建了一个名为 my_set 的集合,并且它包含了元素 1 到 5。
集合提供了一系列的方法和操作符,可以进行集合运算,例如:
- 并集:| 或 union()
- 交集:& 或 intersection()
- 差集:- 或 difference()
- 对称差集:^ 或 symmetric_difference()
此外,集合还支持其他方法,如添加元素、移除元素、清空集合等。需要注意的是,集合是可变对象,因此它们是可以修改的。
集合的基本操作
1、添加元素
可以使用add()方法向集合中添加元素,
my_set = {1, 2, 3}
my_set.add(4)
print(my_set) # 输出:{1, 2, 3, 4}2、移除元素
使用remove()或discard()方法可以从集合中移除指定的元素,
my_set = {1, 2, 3, 4, 5}
my_set.remove(3) # 如果元素存在,则移除
my_set.discard(5) # 如果元素存在,则移除print(my_set)
3、计算集合元素个数
使用len()函数可以计算集合中元素的个数,
my_set = {1, 2, 3, 4}
count = len(my_set)
print(count)4、清空集合
可以使用clear()方法清空集合中的所有元素,
my_set = {1, 2, 3, 4}
my_set.clear()
print(my_set)5、判断元素是否在集合中存在
可以使用in关键字来判断元素是否在集合中存在,
my_set = {1, 2, 3, 4}
result = 3 in my_set # 结果为True
result1 = 5 in my_set # 结果为False
集合内置方法完整列表
- add():为集合添加元素
- clear():移除集合中的所有元素
- copy():拷贝一个集合
- difference():返回多个集合的差集
- difference_update():移除集合中的元素,该元素在指定的集合也存在。
- discard():删除集合中指定的元素
- intersection():返回集合的交集
- intersection_update():返回集合的交集。
- isdisjoint():判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
- issubset():判断指定集合是否为该方法参数集合的子集。
- issuperset():判断该方法的参数集合是否为指定集合的子集
- pop():随机移除元素
- remove():移除指定元素
- symmetric_difference():返回两个集合中不重复的元素集合。
- symmetric_difference_update():移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
- union():返回两个集合的并集
- update():给集合添加元素
- len():计算集合元素个数
第5节 Python3 条件与循环
Python3 条件控制
条件语句通常以 if 关键字开始,后面跟着一个条件表达式,即一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。如果条件表达式的结果为 True,则执行条件语句下面缩进的代码块;如果条件表达式的结果为 False,则跳过这个代码块,继续执行后面的代码。
if 语句
if语句是Python中用于执行条件判断的关键字之一,它的基本语法结构如下:
if <条件>:<条件成立时执行的代码块>
在这个语法结构中,<条件>是一个返回True或者False的表达式,如果<条件>为True,那么<条件成立时执行的代码块>就会被执行;如果<条件>为False,那么<条件成立时执行的代码块>就会被跳过。
例如:
x = 10
if x > 5:print("x大于5")
在这个例子中,当x的值大于5时,print("x大于5")这行代码就会被执行。
除了基本的if语句外,还可以使用elif和else来构建更复杂的条件判断逻辑。例如:
x = 10
if x > 5:print("x大于5")
elif x == 5:print("x等于5")
else:print("x小于5")
在这个例子中,根据x的值不同,会执行不同的代码块。
match...case
match...case是Python 3.10中引入的一种新的模式匹配语法,用于替代较为繁琐的if...elif...else结构,让代码更加清晰和易于阅读。下面是match...case语法的基本形式:
match <expression>:case <pattern1>:<action1>case <pattern2>:<action2>...case <patternN>:<actionN>
在这个语法中,<expression>是要进行匹配的表达式,<pattern1>、<pattern2> 等是不同的模式,<action1>、<action2>等是与模式匹配成功时执行的动作。
下面是一个简单的示例:
def check_number(x):if not isinstance(x, int):raise ValueError("输入必须为整数")# 使用match语句进行数值检查match x:case 1:print("这是数字1")case 2:print("这是数字2")case _:print("这是其他数字")
check_number(1)case _: 类似于 C 和 Java 中的 default:,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功。
Python3 循环语句
Python 中的循环语句有 for 和 while。
while 循环
while循环是一种在条件为真时重复执行代码块的控制结构。其基本语法结构如下:
while <条件>:<需要重复执行的代码块>
在这个语法结构中,<条件>是一个返回True或False的表达式。只要<条件>为True,循环内的代码块就会被重复执行;当<条件>为False时,循环将停止,程序将继续执行循环后面的代码。
以下是一个简单的示例,展示了如何使用while循环来计算并打印1到5的数字:
count = 1
while count <= 5:print(count)count += 1
在这个示例中,首先设置了一个计数器count的初始值为1,然后使用while循环不断地打印count的值,并递增count,直到count的值大于5时循环停止。
需要谨慎处理while循环,因为如果条件永远为真,循环将会无限地执行下去,造成程序的无响应。因此,在使用while循环时,需要确保循环的终止条件最终会变为False,以避免出现无限循环的情况。
for 语句
for语句是Python中用于遍历可迭代对象(如列表、元组、字典、集合等)的一种循环结构。其基本语法结构如下:
for <变量> in <可迭代对象>:<需要重复执行的代码块>
在这个语法结构中,<可迭代对象>是一个可以逐个返回元素的对象,例如列表、元组、字典的键、集合等。<变量>是用来依次接收<可迭代对象>中的元素值的变量,在每次循环迭代时都会被赋予不同的值。
以下是一个简单的示例,展示了如何使用for循环来遍历一个列表并打印其中的元素:
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:print(fruit)
在这个示例中,for循环依次将列表fruits中的每个元素赋值给变量fruit,然后执行print(fruit)语句来打印每个水果的名称。
需要注意的是,for循环通常用于遍历已知长度的可迭代对象,当需要对一个序列进行迭代操作时,for循环是一种非常方便和直观的方式。同时,for循环也可以与内置函数range()结合使用,用来生成一系列数字进行循环操作。
range() 函数
range()函数是Python中用来生成一个整数序列的函数,通常用在循环中,特别是与for循环结合使用。range()函数有几种不同的用法,下面是它最常见的三种形式:
- range(stop): 生成从0开始,到stop-1结束的整数序列。
- range(start, stop): 生成从start开始,到stop-1结束的整数序列。
- range(start, stop, step): 以指定的步长step生成从start开始,到stop-1结束的整数序列。
以下是示例,展示了range()函数的不同用法:
# 生成0到4的整数序列
for i in range(5):print(i)# 生成2到6的整数序列
for i in range(2, 7):print(i)# 以步长为2生成1到9的整数序列
for i in range(1, 10, 2):print(i)
在示例中,range()函数被用来生成不同范围和步长的整数序列,然后结合for循环对生成的序列进行遍历操作。需要注意的是,range()函数生成的整数序列不包含stop参数指定的值。
break 和 continue 语句及循环中的 else 子句
在Python中,break和continue是用于控制循环执行流程的关键字,而循环中的else子句则提供了一种在循环正常结束时执行特定代码的机制。
1、break语句:当break语句被执行时,会立即终止当前所在的循环(例如for或while循环),并跳出循环体,继续执行循环之后的代码。
for i in range(5):if i == 3:breakprint(i)
在这个例子中,当i的值等于3时,break语句会执行,导致循环立即终止,不再执行后续的循环体,因此在输出中只会看到0、1、2。
2、continue语句:当continue语句被执行时,会立即跳过当前循环中剩余的代码,直接进行下一轮循环的判断和执行。
for i in range(5):if i == 2:continueprint(i)
在这个例子中,当i的值等于2时,continue语句会执行,导致当前循环中剩余的代码不会执行,直接进行下一轮循环,因此在输出中不会看到2。
3、循环中的else子句:在Python中,循环也可以带有一个else子句,它会在循环正常结束时执行,但如果循环被break语句终止,则else子句不会被执行。
for i in range(5):if i == 6:break
else:print("循环正常结束")for i in range(5):if i == 3:break
else:print("循环正常结束1")
在第一个例子中,由于循环没有被break语句终止,因此else子句会被执行;而在第二个例子中,由于循环被break语句终止,else子句不会被执行。
pass 语句
pass语句是Python中的一个特殊语句,它不执行任何操作,只是作为占位符或空操作使用。在Python中,有时候需要定义一个代码块,但又没有实际的代码需要执行,这时可以使用pass语句来占位,以保持语法完整性。
以下是pass语句的一些常见用法:
1、在函数或类的定义中,当暂时不想编写函数体或类体时,可以使用pass语句进行占位。
def my_function():pass # 暂时不写任何代码class MyClass:def __init__(self):pass # 暂时不实现初始化方法
2、在条件语句、循环或其他控制结构中,有时需要保持语法完整性,但又不需要执行任何操作,可以使用pass语句作为占位符。
if condition:# 待实现的代码
else:pass # 暂时不做任何操作for item in my_list:pass # 暂时不对列表中的元素进行处理
pass语句的作用是让代码保持完整性,在以后需要添加具体的实现时,可以在pass语句的位置上编写实际的代码。它在逻辑上不执行任何操作,但可以使代码结构更加清晰和完整。
第6节 Python3 推导式
Python 推导式是一种非常方便的语法,可以用来快速构建新的数据序列。
Python 支持各种数据结构的推导式:
1、列表(list)推导式
列表推导式格式为:
[表达式 for 变量 in 列表]
[out_exp_res for out_exp in input_list]或者 [表达式 for 变量 in 列表 if 条件]
[out_exp_res for out_exp in input_list if condition]- out_exp_res:列表生成元素表达式,可以是有返回值的函数。
- for out_exp in input_list:迭代 input_list 将 out_exp 传入到 out_exp_res 表达式中。
- if condition:条件语句,可以过滤列表中不符合条件的值。
例子
# 从一个列表构建另一个新的列表,例如将原列表中的每个元素加倍
original_list = [1, 2, 3, 4, 5]
doubled_list = [x * 2 for x in original_list if x % 2 == 0]
print(doubled_list) # 输出: [4, 8]
2、字典(dict)推导式
字典推导基本格式:
{ key_expr: value_expr for value in collection }或{ key_expr: value_expr for value in collection if condition }例子
# 从一个字典构建另一个新的字典,例如将原字典中的值加倍
original_dict = {'a': 1, 'b': 2, 'c': 3}
doubled_dict = {k: v * 2 for k, v in original_dict.items() if v % 2 == 0}
print(doubled_dict) # 输出: {'b': 4}3、集合(set)推导式
集合推导式基本格式:
{ expression for item in Sequence }
或
{ expression for item in Sequence if conditional }例子
# 从一个集合构建另一个新的集合,例如将原集合中的元素加倍
original_set = {1, 2, 3, 4, 5}
doubled_set = {x * 2 for x in original_set if x % 2 == 0}
print(doubled_set) # 输出: {8, 4}4、元组(tuple)推导式
元组推导式可以利用 range 区间、元组、列表、字典和集合等数据类型,快速生成一个满足指定需求的元组。
元组推导式基本格式:
(expression for item in Sequence )
或
(expression for item in Sequence if conditional )例子
# 元组推导式实际上并不存在,因为推导式生成的是列表、字典或集合,而不是元组
# 但是可以使用生成器表达式来生成一个元组
original_tuple = (1, 2, 3, 4, 5)
doubled_tuple = tuple(x * 2 for x in original_tuple if x % 2 == 0)
print(doubled_tuple) # 输出: (4, 8)第7节 Python3 迭代器与生成器
在 Python 3 中,迭代器(iterator)是一个对象,用于实现迭代器协议(iterator protocol),它可以通过 next() 函数来逐个返回集合中的元素,直到所有元素被访问完毕。迭代器可以用于遍历任何可迭代对象,比如列表、元组、字典、集合等。
在 Python 中,可以使用以下方式创建迭代器:
1、手动创建迭代器:可以通过编写一个包含 __iter__() 和 __next__() 方法的类来手动创建迭代器。__iter__() 方法返回迭代器对象自身,而 __next__() 方法返回下一个值,并在没有更多值可供返回时引发 StopIteration 异常。
class MyIterator:def __init__(self, max_num):self.max_num = max_numself.current = 0def __iter__(self):return selfdef __next__(self):if self.current < self.max_num:result = self.currentself.current += 1return resultelse:raise StopIterationmy_iter = MyIterator(5)
for item in my_iter:print(item)
使用生成器(generator)创建迭代器:生成器是一种特殊的函数,它可以使用 yield 关键字来暂停和恢复函数的执行,从而生成一个迭代器。
2、使用生成器(generator)创建迭代器:生成器是一种特殊的函数,它可以使用 yield 关键字来暂停和恢复函数的执行,从而生成一个迭代器。
def my_generator(max_num):current = 0while current < max_num:yield currentcurrent += 1gen = my_generator(5)
for item in gen:print(item)
Python 中的迭代器为数据处理提供了灵活而高效的方式,使得代码更具可读性和可维护性。同时,Python 也提供了许多内置函数和模块,如 iter()、next()、functools 等,用于迭代器的处理和操作。
第8节 Python3 函数和lambda(匿名函数)
Python3 函数
在 Python 3 中,函数是一种可重复使用的代码块,用于执行特定的任务或操作。函数可以接受输入参数,并返回一个值或执行一些操作。以下是创建和使用函数的基本语法:
def function_name(parameters):# 函数体# 可以包含一系列操作return result # 可选的返回值
在这个语法中:
- def 关键字用于定义函数;
- function_name 是函数的名称,根据命名规范应该使用小写字母并用下划线分隔单词;
- parameters 是函数的参数列表,可以为空或包含多个参数;
- 冒号 : 用于标识函数头的结束;
- 函数体是函数的实际代码,可以包含一系列操作;
- return 语句可选,用于从函数中返回值。
以下是一个简单的示例函数:
def greet(name):message = "Hello, " + name + "!"return messageresult = greet("Alice")
print(result) # 输出: Hello, Alice!
Python 中的函数有以下特点:
- 函数可以接受任意数量的参数,包括位置参数、默认参数、可变参数和关键字参数;
- 函数可以返回任意数量的返回值,包括单个值、元组、字典等;
- 函数可以嵌套定义,即在一个函数内部定义另一个函数;
- 函数也是一种对象,可以作为参数传递给其他函数,也可以作为返回值返回。
Python3 lambda(匿名函数)
在 Python 3 中,lambda 函数是一种匿名函数,也被称为“一次性函数”或“即用即弃函数”。与普通函数不同,lambda 函数不需要通过 def 关键字定义,而是使用 lambda 关键字创建。lambda 函数通常用于编写简单的、单行的函数,它可以接受任意数量的参数,但只能包含一个表达式,并且返回表达式的结果。
lambda 函数的基本语法如下:
lambda arguments: expression
在这个语法中:
- lambda 关键字用于声明 lambda 函数;
- arguments 是参数列表,可以包含零个或多个参数;
- 冒号 : 用于分隔参数列表和表达式;
- expression 是一个表达式,用于计算并返回结果。
以下是一个简单的示例,演示了如何使用 lambda 函数计算两个数的和:
add = lambda x, y: x + y
result = add(3, 5)
print(result) # 输出: 8
lambda 函数通常用于函数式编程中,特别是在需要传递函数作为参数的场景下,例如在 map()、filter()、sorted() 等函数中。它们可以让代码更加简洁和易读。
需要注意的是,虽然 lambda 函数非常灵活和便捷,但由于其只能包含单个表达式,因此适合编写简单的、较为复杂的逻辑应当使用普通函数来实现,以保持代码的可读性和可维护性。
第9节 Python3 装饰器
为何要用装饰器
使用装饰器的主要原因有以下几点:
- 代码复用:装饰器可以将通用的功能抽象成一个装饰器函数,然后可以在多个函数或类中重复使用这个功能,避免了代码重复。
- 分离关注点:使用装饰器可以将不同功能的代码分离开来,使得代码更加清晰可读。例如,可以将日志记录、性能检测、权限验证等功能与业务逻辑分离开来,提高代码的可维护性。
- 动态添加功能:装饰器可以在运行时动态地给函数或类添加新的功能,而无需修改其源代码,这样可以更灵活地扩展现有的功能。
什么是装饰器
装饰器是 Python 中一种特殊的函数,用于动态地给函数或类添加额外的功能,同时又不修改其源代码和调用方式。装饰器的作用就是为被装饰对象添加新的功能,例如插入日志、性能测试、事务处理、缓存、权限校验等。
装饰器可以应用于函数、方法和类,它使用了 Python 中的闭包和函数对象的特性来实现。在装饰器的实现过程中,通常会涉及到名称空间、函数嵌套、闭包等知识。
Python 使用 @ 符号来定义装饰器,将装饰器函数放在被装饰函数之前,并使用 @ 符号进行修饰。这样,在调用被装饰函数时,实际上是在调用经过装饰器修饰后的函数。
用类来实现装饰器
在Python中,装饰器是一种设计模式,用于在不修改原始函数代码的情况下增加函数的功能。通常,装饰器是通过使用函数和闭包来实现的,Python允许使用任何可调用对象作为装饰器,这包括类。
要使用类来实现装饰器,我们可以定义一个类,该类接受一个函数作为参数,并在内部存储这个函数。然后,我们可以定义一个__call__方法,当类的实例被调用时,这个方法会被执行。__call__方法可以执行一些额外的操作,然后调用存储的函数。
以下是一个使用类来实现装饰器的简单示例:
class MyDecorator:def __init__(self, func):self.func = funcdef __call__(self, *args, **kwargs):print("在调用函数之前发生了一些事情。")result = self.func(*args, **kwargs)print("调用函数后发生了一些事情。")return result@MyDecorator
def say_hello(name):print(f"Hello {name}!")say_hello("Alice")在这个例子中,MyDecorator类是一个装饰器类。它接受一个函数func作为参数,并将其存储为实例变量。__call__方法允许类的实例表现得像一个函数,它在调用原始函数之前和之后打印一些文本。
当我们使用@MyDecorator语法来装饰say_hello函数时,实际上是将say_hello函数传递给MyDecorator类的构造函数,并创建了一个装饰器实例。当你调用say_hello("Alice")时,实际上是在调用这个装饰器实例,它执行__call__方法,打印额外的文本,并调用原始的say_hello函数。
这种方法提供了一种灵活的方式来实现装饰器,允许我们在装饰器中使用更多的功能,例如状态管理、错误处理等。
使用 wrapt 模块编写更扁平的装饰器
wrapt是一个强大的Python库,它提供了一个装饰器工厂,可以用来创建装饰器,这些装饰器可以包装任何可调用对象,包括函数、方法、类等。使用wrapt可以编写出更扁平、更灵活的装饰器,它允许我们访问原始的函数、方法或类,并且可以传递额外的参数。
以下是如何使用wrapt模块来编写一个简单的装饰器的示例:
import wraptdef my_decorator(wrapped, instance, args, kwargs):print("在调用函数之前发生了一些事情。")result = wrapped(*args, **kwargs)print("调用函数后发生了一些事情。")return result@wrapt.decorator
def my_decorator_with_wrapt(wrapped, instance, args, kwargs):# 这里可以添加装饰器逻辑return my_decorator(wrapped, instance, args, kwargs)@my_decorator_with_wrapt
def say_hello(name):print(f"Hello {name}!")say_hello("Alice")在这个例子中,wrapt.decorator是一个工厂函数,它返回一个装饰器。这个装饰器接受原始的函数wrapped,以及可选的instance(如果函数是作为方法被调用的话),以及args和kwargs,它们分别代表位置参数和关键字参数。
通过使用wrapt,我们可以保持装饰器的逻辑和装饰器本身的声明分离,这使得代码更加清晰和易于维护。此外,wrapt还提供了许多其他功能,比如处理异常、返回值、以及装饰器的缓存等。
wrapt模块的另一个好处是它对Python的元编程特性提供了很好的支持,使得编写复杂的装饰器变得更加容易。这使得wrapt成为许多高级Python开发者的首选工具之一。
常见错误
“装饰器”并不是“装饰器模式”
装饰器"(Decorator)在Python中是一种语法结构,它允许程序员在不修改函数内容的情况下动态地添加功能。而"装饰器模式"(Decorator Pattern)是一种设计模式,它是一种面向对象编程中用来动态地给一个对象添加额外职责的设计模式。
在Python中,装饰器通常是一个函数,它接受一个函数作为参数并返回一个新的函数。这个新的函数可以增强原函数的功能,比如添加日志、缓存结果等。Python装饰器的语法糖使得代码更加简洁和可读。而装饰器模式则通常涉及到类和对象的组合,它允许通过创建包含目标对象的类来动态地添加功能。在装饰器模式中,通常有一个抽象组件类,一个或多个具体组件类,以及一个或多个装饰类。装饰类通常持有一个组件类的引用,并提供与组件类相同的接口,同时添加额外的功能。
Python中的装饰器和装饰器模式虽然名字相同,但它们的概念和实现方式是不同的。Python的装饰器更侧重于函数级别的增强,而装饰器模式则是一种更通用的设计模式,可以应用于类和对象。
Hint: 在 Python 官网上有一个 实现了装饰器模式的例子。
记得用 functools.wraps() 装饰内层函数
functools.wraps() 是一个专门用于装饰器的装饰器(是的,有点绕口),它用于保留被装饰函数的元数据,如函数名、文档字符串等。当我们使用装饰器时,如果不使用functools.wraps,被装饰的函数将失去其原有的一些属性,这可能会导致一些意料之外的问题,尤其是在调试和使用某些工具时。
functools.wraps的用法如下:
import functoolsdef my_decorator(func):@functools.wraps(func)def wrapper(*args, **kwargs):# 在函数执行前可以执行一些操作print(f"调用函数: {func.__name__}")# 调用原始函数result = func(*args, **kwargs)# 在函数执行后可以执行一些操作print(f"作用 :{func.__name__} 返回 {result}")return resultreturn wrapper@my_decorator
def say_hello(name):return f"Hello, {name}!"# 测试函数
print(say_hello("World"))
在这个例子中,my_decorator是一个装饰器,它接受一个函数func作为参数,并定义了一个内层函数wrapper。wrapper函数使用functools.wraps(func)来装饰,这样wrapper就会继承func的元信息。
当调用speak_hello("World")时,会看到输出中包含了函数的名称,这是因为我们使用了functools.wraps。如果没有这个装饰器,wrapper函数的__name__属性将会是'wrapper',而不是原始的'say_hello'。
记住使用functools.wraps是一个很好的习惯,这样可以保持代码的清晰性和可维护性,特别是在涉及函数反射或者调试的时候。
修改外层变量时记得使用 nonlocal
在Python中,当我们想在嵌套函数中修改外层函数的变量时,我们需要使用nonlocal关键字来声明这个变量。这样做是为了告诉Python解释器,这个变量不是局部变量,也不是全局变量,而是外层函数的局部变量。
下面是一个使用nonlocal的例子:
def outer_function():outer_var = "我在外面"def inner_function():nonlocal outer_varouter_var = "我在里面"print(outer_var)inner_function()print(outer_var)outer_function()
在这个例子中,inner_function内部使用了nonlocal关键字来声明outer_var。这样,当inner_function修改outer_var时,它实际上修改的是outer_function作用域内的outer_var,而不是创建一个新的局部变量。
如果我们不使用nonlocal,Python会默认outer_var是一个局部变量,这会导致一个UnboundLocalError错误,因为我们在尝试修改一个尚未绑定的局部变量。
请注意,nonlocal关键字只适用于嵌套函数的情况。如果我们尝试在一个函数中修改一个全局变量,我们不需要使用nonlocal,但如果我们确实想修改全局变量,我们可能需要使用global关键字来声明它。
nonlocal和global到底有什么区别?
nonlocal和global是Python中的两个关键字,它们用于在不同的作用域内声明变量。这两个关键字的主要区别在于它们影响的作用域不同。
global关键字:
- global用于在函数或其他局部作用域内声明一个全局变量。
- 当我们在函数内部使用global关键字时,我们是在告诉Python解释器,我们想要引用的是全局作用域中的变量,而不是在函数内部创建一个新的局部变量。
- 如果我们在函数内部没有使用global关键字而试图修改一个全局变量,Python会认为我们是在创建一个新的局部变量,而不是修改全局变量。
nonlocal关键字:
- nonlocal用于在嵌套函数中声明一个外层函数的变量。
- 当我们在内层函数中使用nonlocal关键字时,我们是在告诉Python解释器,我们想要引用的是外层函数作用域中的变量,而不是在当前函数内部创建一个新的局部变量。
- 如果我们在内层函数内部没有使用nonlocal关键字而试图修改一个外层函数的变量,Python会认为我们是在创建一个新的局部变量,而不是修改外层函数的变量。
总结一下,global用于在函数内部引用或修改全局变量,而nonlocal用于在嵌套函数中引用或修改外层函数的局部变量。
例子:
# 全局变量
global_var = "我是一个全局变量"def outer_function():# 外层函数的局部变量outer_var = "我在外面"def inner_function():# 使用 nonlocal 声明外层函数的局部变量nonlocal outer_varouter_var = "我已经从内部改变了"print(outer_var)# 使用 global 声明全局变量global global_varglobal_var = "我已从外部功能更改"inner_function()print(outer_var)outer_function()
print(global_var)
在这个例子中,我们有一个全局变量global_var和一个名为outer_function的函数,它包含一个名为inner_function的嵌套函数。
在inner_function中,我们使用nonlocal关键字来声明outer_var,这样我们就可以修改outer_function作用域内的outer_var。
在outer_function中,我们使用global关键字来声明global_var,这样我们就可以修改全局作用域内的global_var。
当我们调用outer_function()时,会先打印出修改后的outer_var,然后是修改后的global_var。
第10节 Python3 数据结构
Python数据结构与算法分析_第2版.pdf
提取码: 8di1
第11节 Python3 输入和输出
1、输入(Input): Python 3中,输入通常使用input()函数来实现。当调用input()函数时,程序会暂停,等待用户输入一些文本,并按回车键。用户输入的文本将被作为字符串返回。
2、输出(Output): Python 3中,输出通常使用print()函数来实现。print()函数将传递给它的参数打印到控制台(终端或命令行界面)。如果我们想在输出中使用更复杂的格式化,我们可以使用字符串的.format()方法或Python 3.6引入的f-string。
# 使用 .format() 方法格式化输出
print("姓名:{},年龄:{}".format(name, age))# 使用 f-string 格式化输出
print(f"姓名:{name},年龄:{age}")
3、读和写文件:
open() 将会返回一个 file 对象,基本语法格式如下:
open(filename, mode)
- filename:包含了你要访问的文件名称的字符串值。
- mode:决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
不同模式打开文件的完全列表:
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:
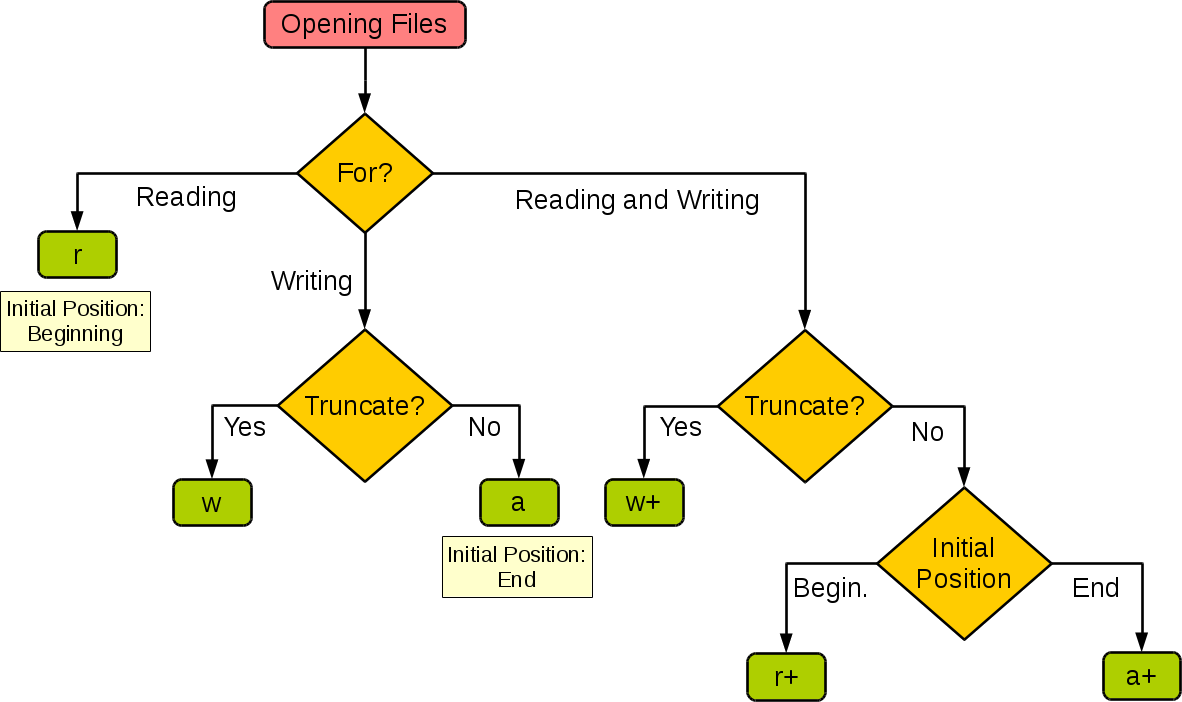
| 模式 | r | r+ | w | w+ | a | a+ |
|---|---|---|---|---|---|---|
| 读 | + | + | + | + | ||
| 写 | + | + | + | + | + | |
| 创建 | + | + | + | + | ||
| 覆盖 | + | + | ||||
| 指针在开始 | + | + | + | + | ||
| 指针在结尾 | + | + |
4、文件对象的方法
文件对象在Python中提供了多种方法来操作文件,以下是一些常见的文件对象方法:
- read(size): 读取文件内容,size 是可选参数,表示要读取的字符数。如果未指定 size,则读取整个文件。
- readline(): 读取文件的一行。
- readlines(): 读取文件的所有行,返回一个包含每行作为元素的列表。
- write(string): 将字符串写入文件。如果文件以追加模式打开,则写入文件末尾;如果以写入模式打开,则覆盖原有内容。
- writelines(sequence): 将序列(如列表)中的每个字符串写入文件。
- seek(offset, whence): 移动文件指针到指定位置。offset 是要移动的字节数,whence 指定从哪里开始移动(0 表示文件开头,1 表示当前位置,2 表示文件末尾)。
- tell(): 返回当前文件指针的位置。
- close(): 关闭文件,释放系统资源。使用 with 语句时,文件会在代码块结束时自动关闭。
- flush(): 清除输出缓冲区,确保所有内容都写入到文件中。
- truncate([size]): 截断文件,size 是可选参数,表示截断到文件的哪个位置。如果未指定 size,则截断到当前文件指针的位置。
- isatty(): 检查文件是否连接到一个终端设备。
- fileno(): 返回文件的文件描述符。
示例:
# 打开文件进行读写
with open('example.txt', 'r+') as file:# 读取文件内容content = file.read()print(content)# 写入内容到文件file.write('这是一条新线路.\n')# 定位到文件开头file.seek(0)# 读取文件的所有行lines = file.readlines()print(lines)# 关闭文件# 注意:使用 with 语句时,文件会在代码块执行完毕后自动关闭
第12节 Python3 错误和异常
Python中的异常处理是程序中一个非常重要的部分,它允许程序在遇到错误时继续运行而不是立即崩溃。Python使用try-except语句来处理异常。
基本结构
try:# 尝试执行的代码块pass
except SomeException as e:# 如果try块中的代码引发SomeException异常,则执行这里的代码print("An error occurred:", e)
finally:# 不管是否发生异常,都会执行的代码块print("This will always execute.")常见的Python异常
- SyntaxError: 语法错误,代码中有语法错误时抛出。
- NameError: 尝试访问一个未定义的变量时抛出。
- TypeError: 操作或函数应用到错误类型的对象时抛出。
- ValueError: 传递给函数的参数具有正确的类型,但内容不正确时抛出。
- IndexError: 索引超出序列的范围时抛出。
- KeyError: 尝试访问字典中不存在的键时抛出。
- IOError: 输入/输出操作失败时抛出(在Python 3中,这个异常被合并到OSError中)。
抛出异常
使用raise关键字可以主动抛出异常。
raise ValueError("无效的值")
定义自定义异常
我们可以定义自己的异常类,这些类应该继承自Exception类或其子类。
class MyCustomError(Exception):pass# 使用自定义异常
try:raise MyCustomError("Something went wrong!")
except MyCustomError as e:print(e)assert(断言)
在Python中,assert是一个关键字,用于调试程序。它允许我们测试一个条件,如果该条件为False,则程序将抛出AssertionError异常。assert通常用于确保程序在某个特定点上满足特定的条件。
基本语法
assert condition, "Error message"如果condition为True,程序继续执行。如果condition为False,则程序抛出AssertionError,并显示指定的"Error message"。
示例
# 断言一个条件
assert 1 + 1 == 2, "The universe is broken!"# 如果条件不满足,将抛出异常
assert 1 + 1 == 3, "Math is wrong!"在第二个例子中,因为1 + 1不等于3,所以程序将抛出AssertionError,并显示错误信息"Math is wrong!"。
断言的作用
- 调试: 在开发过程中,断言可以用来快速检查代码中的潜在问题。
- 文档: 断言可以作为文档的一部分,说明函数的预期行为。
- 测试: 在单元测试中,断言可以用来验证测试用例的结果是否符合预期。
注意事项
- 在Python中,可以通过-O(优化)选项运行程序,这将禁用assert语句,以提高程序的运行效率。
- 断言不适用于捕获运行时错误,因为它们可以被禁用。对于需要在生产环境中处理的错误,应该使用异常处理。
断言的高级用法
我们还可以结合使用断言和异常来提供更详细的错误信息:
def divide(x, y):try:result = x / yexcept ZeroDivisionError:assert False, "Cannot divide by zero"else:return result# 使用断言函数
assert divide(10, 2) == 5, "Division should work correctly"在这个例子中,如果y为0,将抛出ZeroDivisionError,然后assert将捕获这个异常并提供一个更具体的错误消息。
with 关键字
Python中的with关键字是用于异常处理的一种语法结构,它允许我们以一种非常干净和高效的方式来处理资源。with语句通常与那些需要管理资源,比如文件操作、网络连接、数据库连接等场景中的上下文管理器一起使用。
基本语法
with expression as variable:# 代码块# 这里可以访问变量,并且当退出with语句时,资源会被自动释放工作原理
with语句创建了一个临时的执行环境,在这个环境中,你可以执行一组代码。当代码块执行完毕后,无论是否发生异常,都会自动执行一些清理工作。
示例:文件操作
with open('example.txt', 'r') as file:data = file.read()# 文件会在with语句块执行完毕后自动关闭
print(data)在这个例子中,open()函数返回一个文件对象,该对象支持上下文管理协议。with语句确保了文件在代码块执行完毕后,无论是否发生异常,都会被正确关闭。
上下文管理器
上下文管理器是实现了__enter__()和__exit__()这两个魔术方法的对象。with语句就是通过调用这两个方法来管理资源的。
class MyResource:def __enter__(self):# 进入上下文时执行的操作return selfdef __exit__(self, exc_type, exc_val, exc_tb):# 退出上下文时执行的操作,包括异常处理if exc_type:print(f"An exception occurred: {exc_val}")# 返回False则异常会向上抛出,返回True则异常会被抑制return Falsewith MyResource() as resource:print("使用资源")优点
- 自动资源管理:无需手动释放资源,with语句会自动调用资源的清理代码。
- 异常安全:即使在代码块中发生异常,退出时的清理代码依然会被执行。
- 可读性:代码更加清晰,易于理解资源何时被获取和释放。
- 一致性:with语句提供了一种统一的方式来管理资源,使得代码风格一致。
with语句是Python中处理需要资源管理的场景的一种优雅方式,它简化了代码,提高了代码的可读性和健壮性。
第13节 Python3 面向对象
Python从设计之初就已经是一门面向对象(OOP)的语言,这意味着我们可以使用类和对象来组织代码。面向对象编程是一种编程范式,它使用“对象”来设计软件,其中每个对象都是数据和代码的组合。
面向对象编程的核心概念
- 类(Class):类是对象的蓝图或模板。它定义了一组具有相同属性和方法的对象的结构。
- 对象(Object):对象是类的实例。每个对象都拥有类定义的属性和方法。
- 属性(Attribute):属性是对象的状态,通常在类的初始化方法中设置。
- 方法(Method):方法是对象的行为,它们是与对象相关联的函数。
- 继承(Inheritance):继承允许新创建的类(子类)继承现有类(父类)的属性和方法。
- 封装(Encapsulation):封装是将对象的数据(属性)和行为(方法)组合在一起的过程,同时隐藏内部细节。
- 多态(Polymorphism):多态允许同一个接口接受不同的数据类型。
Python中的类定义
类是创建对象的蓝图。它定义了对象的属性和方法。
class MyClass:# 类的属性attribute = "some value"# 类的方法def method(self, arg):return arg# 初始化方法def __init__(self, name):self.name = name # 实例属性# 创建类的实例
my_object = MyClass("python")# 访问类的属性和方法
print(my_object.attribute)
print(my_object.method("Hello, World!"))
print(my_object.name)继承(Inheritance)
继承允许我们定义一个类(子类)来继承另一个类(父类)的属性和方法。
class ParentClass:def parent_method(self):print("父方法")class ChildClass(ParentClass):def child_method(self):print("子方法")# 子类继承了父类的方法
child_object = ChildClass()
child_object.parent_method() # 调用父类方法
child_object.child_method() # 调用子类方法封装(Encapsulation)
封装意味着隐藏对象的内部状态和实现细节,只暴露一个可以被外界访问和使用的接口。
class Person:def __init__(self, name, age):self._name = name # 私有属性self.__age = age # 私有属性,更强的封装def get_name(self): # 公开接口return self._namedef set_name(self, name):self._name = namedef get_age(self): # 公开接口return self.__agedef set_age(self, age):self._age = age# 访问私有属性需要通过公开的方法
person = Person("Alice", 30)
print(person.get_name())
person.set_name("Bob")
print(person.get_name())
print(person.get_age())
person.set_age(40)
print(person.get_age())多态(Polymorphism)
多态允许子类重写父类的方法,使得同一个接口可以有不同的实现。
class Animal:def speak(self):raise NotImplementedError("Subclasses must implement this method")class Dog(Animal):def speak(self):return "Woof!"class Cat(Animal):def speak(self):return "Meow!"# 多态的使用
animals = [Dog(), Cat()]
for animal in animals:print(animal.speak()) # 根据对象的实际类型调用相应的方法第14节 Python3 正则表达式
Python的正则表达式功能由re模块提供,它是一个强大的工具,用于处理字符串中的搜索、替换、分割和匹配等操作。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
正则表达式基础
- 字符匹配:
.匹配任意单个字符(除了换行符)。 - 字符类:
[abc]匹配方括号内的任意一个字符。 - 预定义字符类:
\d匹配任意数字,等同于[0-9]。 - 量词:
*匹配前面的元素零次或多次。+匹配前面的元素一次或多次。?匹配前面的元素零次或一次。{n}匹配确定的 n 次数。{n,}至少匹配 n 次。{n,m}匹配 n 到 m 次。
- 分组:
()将多个表达式组合成一个单元,也可以用于捕获匹配的文本。 - 选择:
|表示逻辑或,匹配两种模式中的任意一种。 - 锚点:
^匹配字符串的开始。$匹配字符串的结束。
Python re模块常用功能
匹配:
re.match():从字符串的开始位置匹配一个正则表达式。re.search():扫描整个字符串,寻找正则表达式的第一次出现。
查找:
re.findall():返回一个列表,包含字符串中所有匹配的非重叠子串。re.finditer():返回一个迭代器,产生每个匹配的Match对象。
替换:
re.sub():替换字符串中的匹配项。
分割:
re.split():根据匹配的正则表达式来分割字符串。
示例代码
import re# 匹配一个简单的正则表达式
result = re.match(r'Hello \w+', 'Hello World')
if result:print("找到匹配项:", result.group())# 查找所有匹配项
matches = re.findall(r'\d+', 'The years 1999 and 2021 were good.')
print("找到的数字:", matches)# 替换字符串中的匹配项
new_string = re.sub(r'\b[^\s]+\b', 'python', 'Hello World, welcome to the world of AI.')
print("新建字符串:", new_string)# 分割字符串
parts = re.split(r'\s+', 'One two\tthree\nfour')
print("拆分部件:", parts)编译正则表达式
对于复杂的正则表达式,可以使用re.compile()来编译正则表达式,这样可以提高效率,特别是当需要多次使用同一个表达式时。
import repattern = re.compile(r'\d+')
result = pattern.findall('123 abc 456')
print("找到的号码:", result)正则表达式的高级用法
- 贪婪与非贪婪:默认情况下,量词是贪婪的,尽可能多地匹配字符。使用
?可以使量词变为非贪婪,尽可能少地匹配字符。 - 特殊序列:
\b表示单词边界,\w匹配字母、数字及下划线。 - 断言:
(?=...)正向前瞻断言,(?!...)负向前瞻断言;(?<=...)正向后瞻断言,(?<!...)负向后瞻断言。