简单说说我对集成学习算法的一点理解
概要
集成学习(Ensemble Learning)是一种机器学习技术框架,它通过构建并结合多个学习器(也称为个体学习器或基学习器)来完成学习任务。
- 集成学习旨在通过组合多个基学习器的预测结果来提高整体模型的性能。
- 每个基学习器都可以是一个简单的机器学习模型,如决策树、逻辑回归等。
- 基学习器可以是同质的(即所有基学习器都使用相同的算法),也可以是异质的(即基学习器使用不同的算法)。
工作原理
生成基学习器:首先,使用某种算法从训练数据中产生多个基学习器。这些基学习器通常会在训练数据的不同子集或不同特征子集上进行训练,以实现多样性。
结合策略:然后,使用一种结合策略将基学习器的预测结果结合起来,以产生最终的预测结果。常见的结合策略包括平均法(如简单平均、加权平均)、投票法(如硬投票、软投票)和学习法(如Stacking)。
代表性方法
Bagging:一种基于数据随机重抽样的集成学习方法。它通过从原始数据集中有放回地抽取样本来训练多个基学习器,并对所有基学习器的预测结果进行平均或投票来产生最终的预测结果。
Boosting:一族可将弱学习器提升为强学习器的算法。它主要是通过对样本集的操作获得样本子集,然后用弱分类算法在样本子集上训练生成一系列的基分类器,并通过加权投票等方式将基分类器的预测结果结合起来。
随机森林:Bagging的一个扩展变体,它以决策树为基学习器构建Bagging集成,并在决策树的训练过程中引入了随机属性选择。
优势和目的
集成学习的主要优势在于,通过结合多个基学习器的预测结果,可以减小模型的方差、偏差或改进预测性能。
集成学习的目的通常是为了提高模型的泛化能力,降低模型选择不当的可能性,以及提高模型的稳定性和鲁棒性。
总结
集成学习是一种通过构建并结合多个学习器来提高模型性能的技术框架。
它通过生成多个基学习器并使用一种结合策略将它们的预测结果结合起来,以实现更好的预测效果。
集成学习在机器学习和数据科学领域中被广泛应用,是提升模型性能的重要工具之一。
详细介绍
在机器学习算法(分类算法)中,将算法分为2类:
弱分类器:逻辑回归(Lr)分类算法、决策树(DT)分类算法
强分类器:
相当于弱分类器算法而言进行称呼,往往是多个弱分类器算法组成的,变成强分类器
即:三个臭皮匠,顶个诸葛亮
集成学习算法常见的有两类:
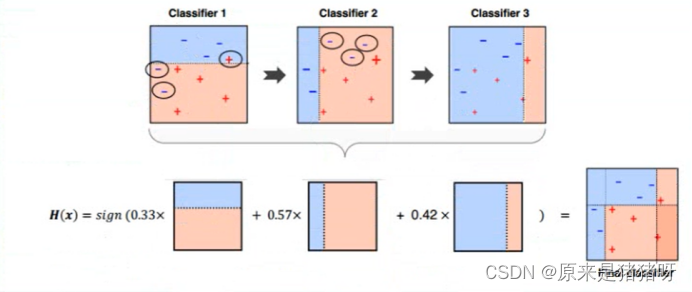
Boosting算法
直译为提升算法
选择某个弱分类器算法,逐步优化算法模型,逐步提升Boosting,最终获取最佳算法模型
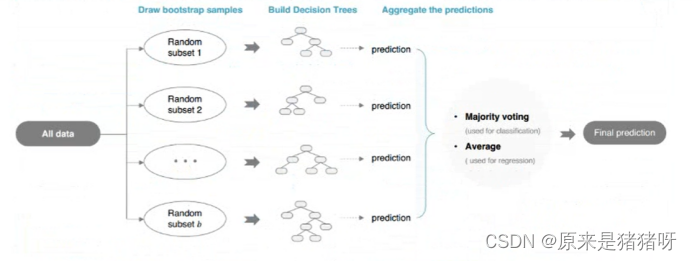
Bagging算法
直译为袋子算法
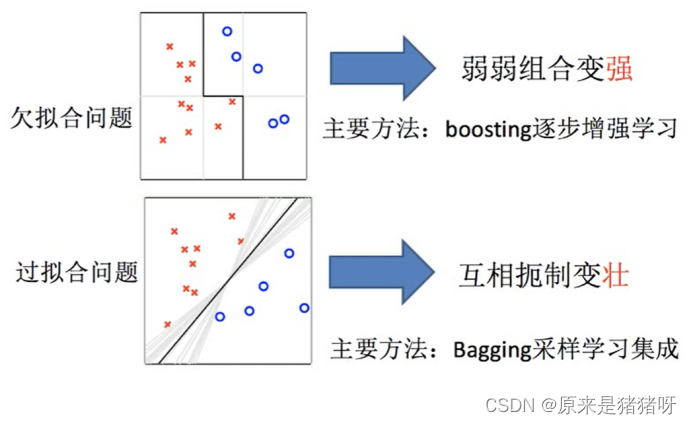
所面临的问题 :
欠拟合以及过拟合
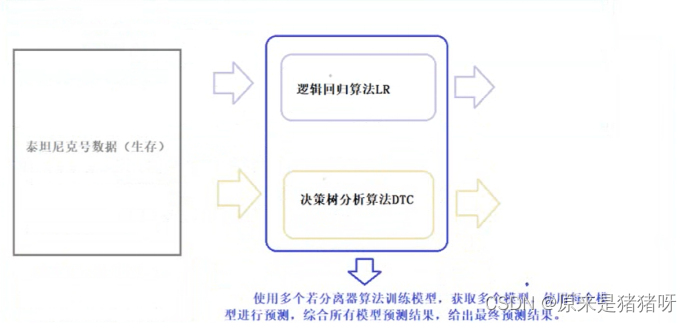
集成学习概念
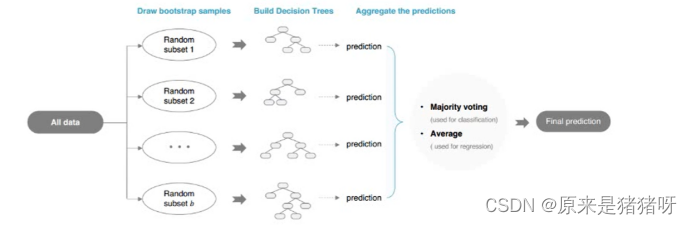
如下图所示:使用不同算法(LR、DT等)构建不同模型,最终合并模型(取其优秀),进行预测分类。
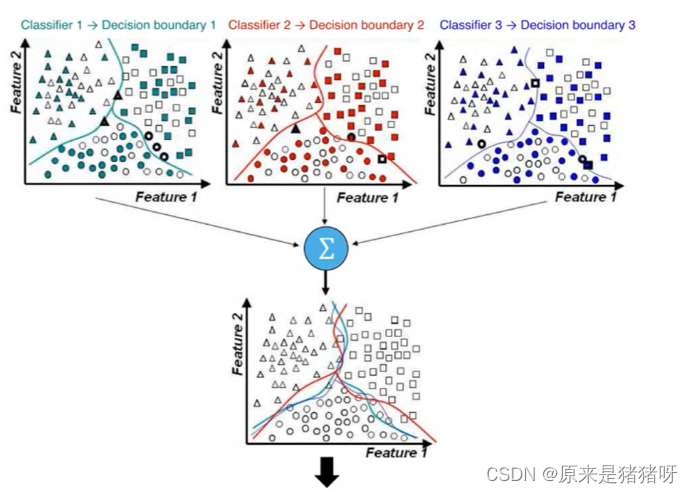
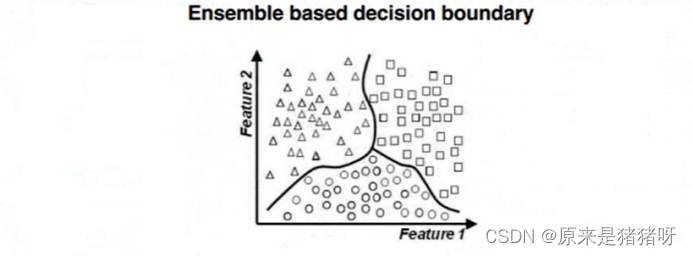 集成学习算法
集成学习算法
Bagging
袋子,有很多模型(每个模型不一样),预测时:让每个模型进行预测
如果是分类:使用投票vote机制,决定预测结果(类别最多)
如果是回归:使用平均avg机制,决定预测结果(对每个模型预测值求其平均值)
最典型算法:随机森林
森林中有很多决策树模型DTM
Boosting
提升,有很多模型,但是模型之间依赖关系(后续的模型“修正”前面模型不足的地方),最终合并所有模型优秀的地方,构建出一个模型进行预测。
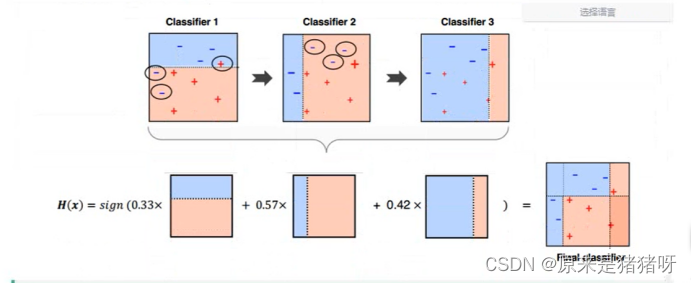
Ensemble集成学习算法/融合学习算法
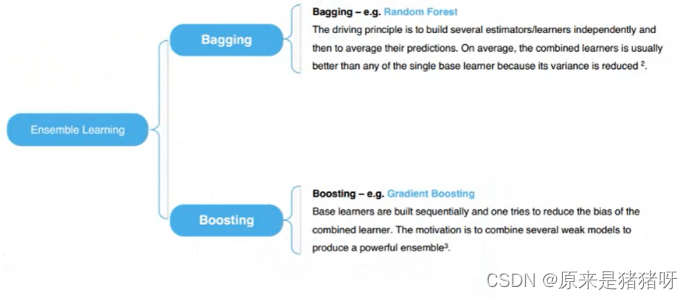
Bagging算法详细介绍
RandomForest-随机森林
随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
Random Forest = Bagging + CART decision Tree
先来分析一下什么是随机森林算法:
随机森林算法由三个词分别组成:随机、森林、算法,其中随机和森林是关键,我们单独拿出来进行解释
森林Forest:其中会有多棵树,每一棵树都是决策树。
我们还记得决策树有什么特点,因为一棵树的数据集固定,特征选择也固定,会导致:无论决策树执行多少次,结果都是不变的——出身就决定答案。
随机Random:而机器学习需要的不是一成不变的东西,所以随机Random就帮我们解决了这个问题
它会使数据集不一样——从源数据集有放回的去抽样数据
他会使特征选择不一样——假设数据集有20哥特征,每次抽取获取15个特征
由于决策树分类模型属于【概率分类模型】,所以要求标签label值从0开始计算。
Bagging官方样例
import org.apache.spark.ml.classification.{RandomForestClassificationModel, RandomForestClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.sql.DataFrame
import org.apache.spark.storage.StorageLevel/*** Spark ML官方案例,基于随机森林分类算法* http://spark.apache.org/docs/2.2.0/ml-classification-regression.html#random-forest-classifier*/
object ExampleRfClassification {def main(args: Array[String]): Unit = {// 构建SparkSession实例对象,通过建造者模式创建import org.apache.spark.sql.SparkSessionval spark: SparkSession = {SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[3]").config("spark.sql.shuffle.partitions", "3").getOrCreate()}// 导入隐式转换和函数库import spark.implicits._import org.apache.spark.sql.functions._// TODO: 1. 加载数据、数据过滤与基本转换val datasDF: DataFrame = spark.read.format("libsvm").load("datas/mllib/sample_libsvm_data.txt")// TODO: 2. 数据准备:特征工程(提取、转换与选择)// 将标签数据转换为从0开始下标索引val labelIndexer: StringIndexerModel = new StringIndexer().setInputCol("label").setOutputCol("label_index").fit(datasDF)val indexerDF = labelIndexer.transform(datasDF)// 自动识别特征数据中属于类别特征的字段,进行索引转换,决策树中使用类别特征更加好val featureIndexer: VectorIndexerModel = new VectorIndexer().setInputCol("features").setOutputCol("index_features").setMaxCategories(4).fit(indexerDF)val dataframe = featureIndexer.transform(indexerDF)// 划分数据集:训练数据集和测试数据集val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2))trainingDF.persist(StorageLevel.MEMORY_AND_DISK).count()// TODO: 3. 使用算法和数据构建模型:算法参数val rf: RandomForestClassifier = new RandomForestClassifier().setLabelCol("label_index").setFeaturesCol("index_features")// 超参数.setNumTrees(20) // 设置树的数目// 抽样获取数据量.setSubsamplingRate(1.0)// 获取特征的个数.setFeatureSubsetStrategy("auto")// 决策树参数.setImpurity("gini").setMaxDepth(5).setMaxBins(32)val rfModel: RandomForestClassificationModel = rf.fit(trainingDF)//println(rfModel.featureImportances) // 每个特征的重要性// TODO: 4. 模型评估val predictionDF: DataFrame = rfModel.transform(testingDF)predictionDF.select("prediction", "label_index").show(50, truncate = false)val evaluator = new MulticlassClassificationEvaluator().setLabelCol("label_index").setPredictionCol("prediction").setMetricName("accuracy")val accuracy = evaluator.evaluate(predictionDF)println("Test Error = " + (1.0 - accuracy))// 应用结束,关闭资源spark.stop()}}Boosting算法详细介绍
梯度提升树(GBT Gradient Boosting Tree)是一种迭代的决策树算法,该算法由多颗决策树组成,所有树的结论累加起来做最终答案。他在被提出之初就被认为是泛化能力(generalization)较强的算法。
GBDT = 梯度提升 + Boosting + 决策树

Boosting官方样例代码
import org.apache.spark.ml.classification.{GBTClassificationModel, GBTClassifier}
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{StringIndexer, StringIndexerModel, VectorIndexer, VectorIndexerModel}
import org.apache.spark.sql.DataFrame
import org.apache.spark.storage.StorageLevel/*** Spark ML官方案例,基于梯度提升树分类算法* http://spark.apache.org/docs/2.2.0/ml-classification-regression.html#gradient-boosted-tree-classifier*/
object ExampleGbtClassification {def main(args: Array[String]): Unit = {// 构建SparkSession实例对象,通过建造者模式创建import org.apache.spark.sql.SparkSessionval spark: SparkSession = {SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[3]").config("spark.sql.shuffle.partitions", "3").getOrCreate()}// 导入隐式转换和函数库import spark.implicits._import org.apache.spark.sql.functions._// TODO: 1. 加载数据、数据过滤与基本转换val datasDF: DataFrame = spark.read.format("libsvm").load("datas/mllib/sample_libsvm_data.txt")// TODO: 2. 数据准备:特征工程(提取、转换与选择)// 将标签数据转换为从0开始下标索引val labelIndexer: StringIndexerModel = new StringIndexer().setInputCol("label").setOutputCol("label_index").fit(datasDF)val indexerDF = labelIndexer.transform(datasDF)// 自动识别特征数据中属于类别特征的字段,进行索引转换,决策树中使用类别特征更加好val featureIndexer: VectorIndexerModel = new VectorIndexer().setInputCol("features").setOutputCol("index_features").setMaxCategories(4).fit(indexerDF)val dataframe = featureIndexer.transform(indexerDF)// 划分数据集:训练数据集和测试数据集val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2))trainingDF.persist(StorageLevel.MEMORY_AND_DISK).count()// TODO: 3. 使用算法和数据构建模型:算法参数val gbt: GBTClassifier = new GBTClassifier().setLabelCol("label_index").setFeaturesCol("index_features")// 设置超参数.setMaxIter(10).setStepSize(0.1) // 学习率,(0, 1]之间,默认值为1.setSubsamplingRate(1.0) // 每次训练决策树数据集占比,默认为1.0//.setImpurity("variance")//.setLossType("logistic")// 树的参数.setImpurity("gini").setMaxDepth(5).setMaxBins(32)val gbtModel: GBTClassificationModel = gbt.fit(trainingDF)// TODO: 4. 模型评估与参数调优val predictionDF: DataFrame = gbtModel.transform(testingDF)predictionDF.select("prediction", "label_index").show(50, truncate = false)val evaluator = new MulticlassClassificationEvaluator().setLabelCol("label_index").setPredictionCol("prediction").setMetricName("accuracy")val accuracy = evaluator.evaluate(predictionDF)println("Test Error = " + (1.0 - accuracy))Thread.sleep(10000000)// 应用结束,关闭资源spark.stop()}}Bagging与Boosting的区别

以决策树为基础分类器:
Bagging
多棵树,每棵树是独立存在的,没有任何联系 -> 多棵树
训练时的数据:“随机” -> 数据集(重复)、特征部分
训练时可以并行训练模型,多棵树可以同时构建,效率高
预测时
分类:vote投票;回归:avg平均
Boosting
多棵树,每棵树是关联的 -> 一棵树
使用全局的数据(不重复)、全部特征
训练时只能串行,一棵一棵的构建,彼此之间相互关联
预测时
是什么就是什么
(叠甲:大部分资料来源于黑马程序员,这里只是做一些自己的认识、思路和理解,主要是为了分享经验,如果大家有不理解的部分可以私信我,也可以移步【黑马程序员_大数据实战之用户画像企业级项目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿喷)