索引 ---- mysql
目录
1. 索引
1.1 概念
1.2 作用
1.3 使用场景
1.4 使用
1.4.1查看索引
1.4.2 创建索引
1.4.3 删除索引
1.5 注意事项
1.6 索引底层的数据结构 (面试经典问题)
1. 索引
1.1 概念
1.2 作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。
1.3 使用场景
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
1.4 使用
1.4.1查看索引
show index from 表名;
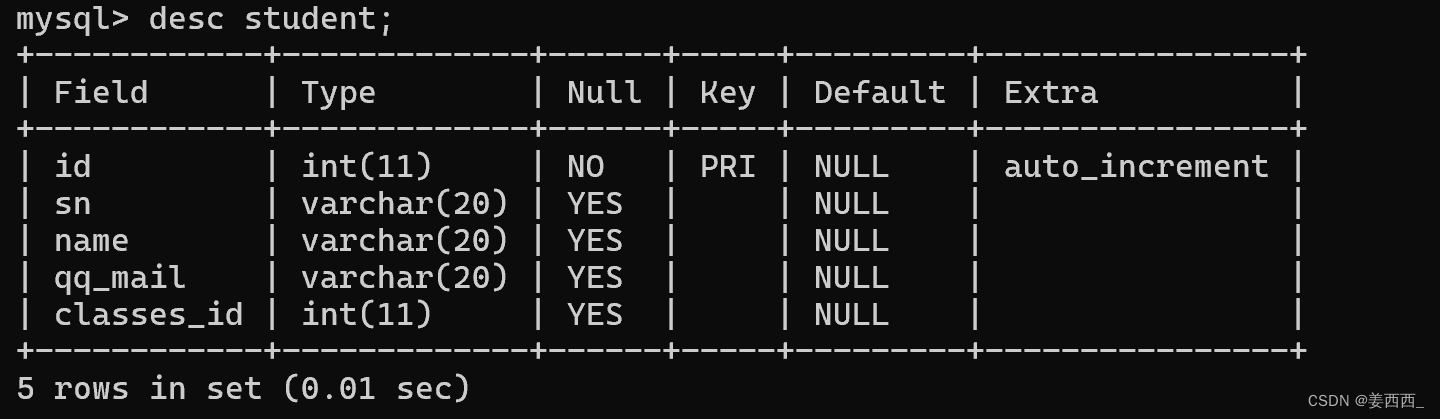
上述student表中, id是主键, 所以会自动创建一个索引, 所以我们可以查看索引
关于出现的一些属性,我们后续介绍
1.4.2 创建索引
create index 索引名 on 表名(列名);

1.4.3 删除索引
drop index 索引名 on 表名;

1.5 注意事项
如果针对空的表, 或者表中的数据不多, 此时创建索引无所谓
如果表本身很大, 此时创建索引操作, 就会引起大量的CPU/硬盘IO的消耗, 数据库可能会挂掉
- 为什么会如此呢?
- 如何解决呢?
- 但是我们没办法知道未来这张表会不会变大, 如果眼下有一张很大的表,并且针对这一列没有创建索引, 我们还要频繁查询该怎么办呢?
- 另外搞一台机器, 也搭建好一样的数据库服务器
- 创建表, 建立索引(此时是空表)
- 把旧的数据库的数据, 导入到新的数据库中(非常耗时)
- 数据导好后, 把应用程序的请求切换到新的服务器上即可
此时, 就可以顺利加上索引, 并且数据库可不会挂掉
这种方式还有一个非常大的好处, 一旦新的服务器出现问题, 随时都可以切换回旧的服务器, 避免问题扩大化
其实, 开发中的一些"高风险操作" , 都可以通过类似的方式来完成
1.6 索引底层的数据结构 (面试经典问题)
索引, 其实就是引入了一些数据结构, 来加快查询的速度
默认情况下, 进行条件查询操作, 就是遍历表, 一条一条数据带入条件
引入索引, 就是通过其他的数据结构, 来加快查询的速度, 减少遍历表的可能
对于应用于数据库的数据结构, 我们要求即能准确查找, 又能范围查找才行
思考我们学过的能够查找的数据结构:
1)哈希表
谈到哈希表的时间复杂度, 往往不谈最坏的, 就认为是O(1)
为什么不能说哈希表的复杂度是O(N)呢?
N表示哈希表中, 所有的数据加起来是N, 那么链表的长度肯定不是N, 除非是所有数据出现在一根链表上的极端情况, 假设最多可以设链表最大长度为M,那么复杂度为O(M), 但是在使用hash表时, 是会对hash表进行扩容的, 控制链表的长度不会很长, 所以时间复杂度近似认为是O(1)
哈希表是无序的, 只能查询key相等的情况, 不能进行范围查询, 所以不能应用于数据库
2) 二叉搜索树
一个普通的二叉搜索树, 时间复杂度为O(N), 这时最坏的情况, 但是如果是较为平衡的二叉搜索树, 时间复杂度就是O(logN)
AVL树, 是一个平衡的二叉树, 时间复杂度就是O(logN)
说个题外话
为什么TreeMap/TreeSet 不适用AVL树呢? 而是使用红黑树?
红黑树本质上是一个不那么平衡的二叉搜索树(要求较宽松)
而AVL树, 是一个非常严格的平衡二叉搜索树(要求很严格)
那么当要求较为严格的时候, 随便进行一些增删改的操作, 都可能会破坏要求, 从而触发旋转, 每次旋转都是有开销的, 那么红黑树触发旋转的概率就远远低于AVL树, 虽然红黑树没有那么平衡, 但是查询的时候速度是没差多少的
- 原因一:按道理, 红黑树中的元素是有序的, 可以进行范围查询, 但是看一个例子:
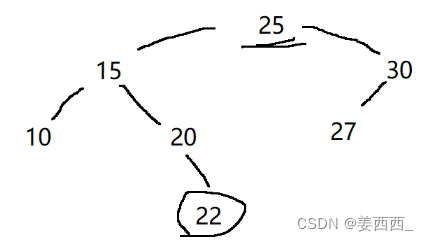
- 原因二: 当元素非常多时, 就会使树变得比较高, 树越高, 查询的效率就越低, 而数据库的数据/索引都是保存在硬盘上的, 每一次比较, 都需要进行一次硬盘I/O操作
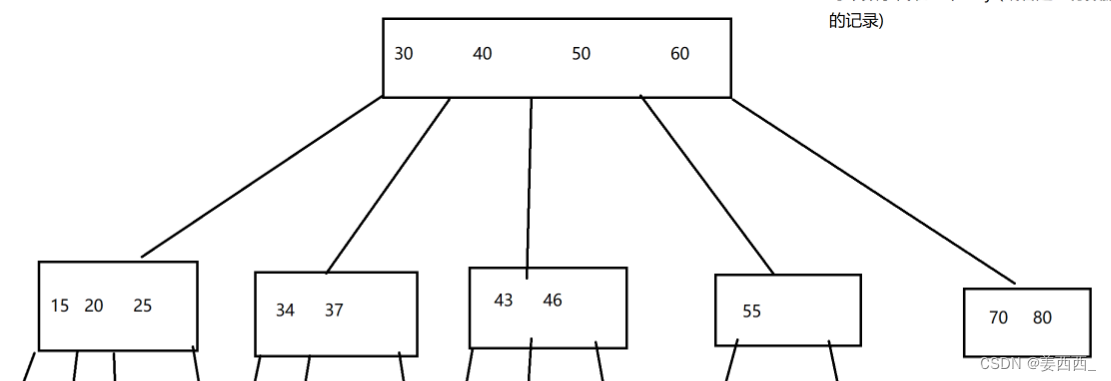
- 每个节点上的这些key都是有序排列的, 比较时可以用二分查找, 比较高效
- B树也会控制, 某个节点上保存的key不会太多, 如果插入更多的元素, 使key变多了, 就会使结点分裂出更多的子树
- 多个数据, 都是放在一块连续的存储空间上, 进行比较的时候,一次硬盘IO就能读出整个结点, 硬盘IO读取很慢, 所以减少硬盘IO的访问次数, 可以提高效率
4)B+树
其实数据库的最终形态是B+树, 相当于是B树的升级版
- N叉搜索树
- 每个父节点中的元素都会在子节点中以最大值的方式存在
- 叶子结点着一层通过链表连上
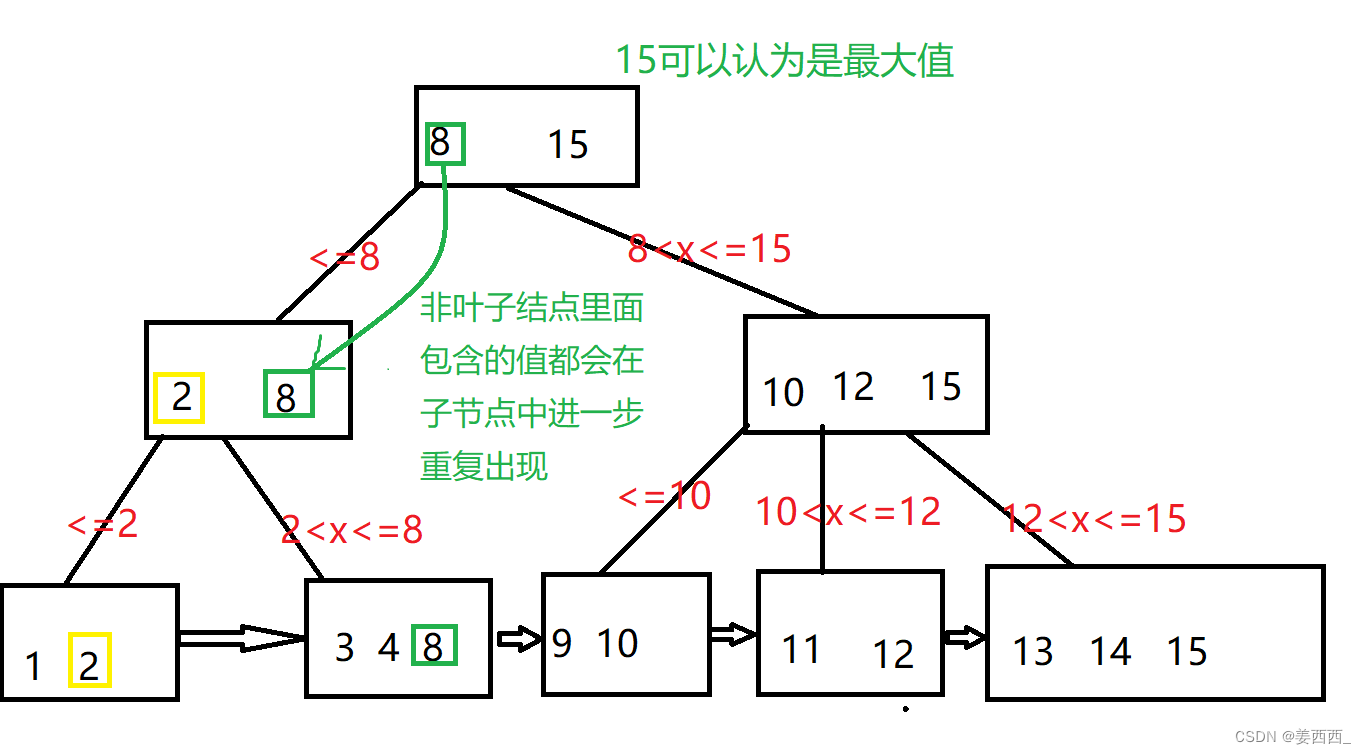
- 非常方便进行遍历和范围查询
- 当前任何一次查询操作, 最终都是要落到叶子结点完成的, 查询任何数据, 经过硬盘IO的次数都是一样的, 查询所消耗的时间是稳定的(稳定其实是个优点!)
- 由于叶子结点是数据的全集, 非叶子结点中, 都是重复出现的数据, 就可以把表中的每一行数据, 最终都关联到叶子结点这一层, 而非叶子结点值保存一个单纯的key值即可
例如上面的数据, 假设代表的是学生表, 那么这些数据是学生id, 但是在叶子结点中, 存储的就是表中每一行的数据, 不单单是id
我们所看到的表格, 只是逻辑上的结构, 实际上的底层结构, 就是B+树, 就会按照主键的索引的这个B+树的叶子结点来保存每一行数据
这样组织之后, 非叶子结点占用的空间就比较小(只保存id), 此时就可以将非叶子结点缓存到内存中(当然这份数据在硬盘也保存着, 只是为了提高效率, 就把这部分结构放在内存中了), 这样查询速度就又提高了(内存的读取速度很快)
如果你的表创建了主键, 那么自然是通过你创建的主键的索引的B+树来组织的
如果你没创建主键, mysql其实生成了一个隐藏主键, 按照隐藏主键在构造B+树
- 如果我们没有给出主键, 那么mysql会自动生成一个隐藏主键(假设是id), 此时就会产生索引和B+树
- 如果我们给出主键是id, 同样也会生成索引和B+树
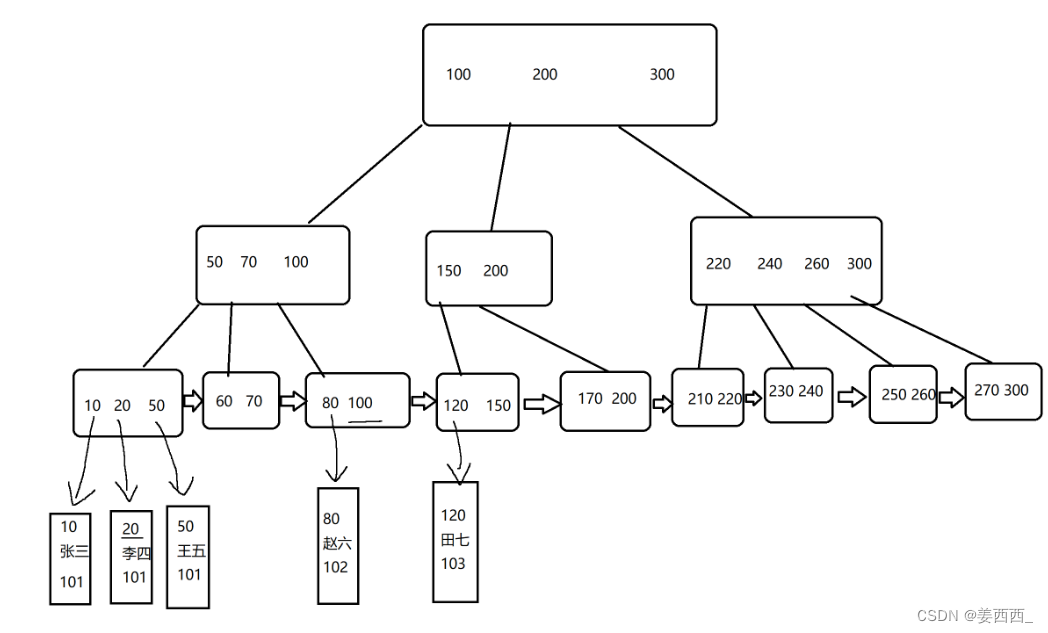
针对上述表查询情况有两种:
1) 走索引的情况
select * from student where id = 20;
select * from student where id>20 and id < 100;
此时就会根据上述B+树进行查询
2) 不走索引的情况(不根据id进行查询)
select * from student where classId = 20;
此时直接通过上述叶子结点的链表进行遍历, 一个一个的与条件进行比较 - 如果我们再根据name这一列创建索引
此时就会构造出另一个以name为关键字的B+树, 是和上面的主键B+树独自存在的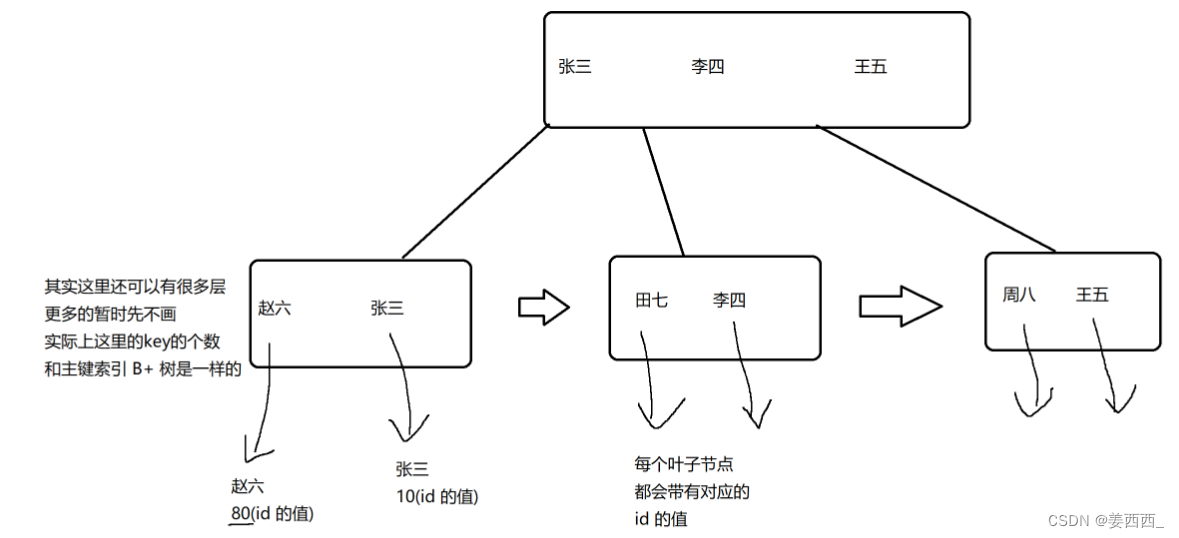
非主键的B+树, 叶子结点存放的是非主键的字段和对应的主键
此时, 按照名字查询时, 先在nameB+树上查询相应的name对应的id值, 再去主键idB+树查询数据(此过程叫做"回表")
其实B+树存在的前提, 是使用了innodb这个存储引擎
mysql支持多种存储引擎, 不同的存储引擎所用的索引数据结构是不同的
innodb是最常用的, 也是面试常考的(后续介绍)