实时瞳孔分割算法-RITnet论文复现
源代码在这里RITnet-Github
这个模型比较小众,我们实验室使用了官方提供的模型进行瞳孔中心位置提取,以实现视线追踪,效果很好
一、数据集准备
RITnet也是那一届openEDS数据集挑战赛的冠军模型,openEDS数据集可以从Kaggle上下载,一共9G,大家不用去找openEDS论文里提供的数据集下载地址,那个需要Facebook账户去进行申请,很麻烦
从Kaggle上下载下来的数据集长这样:
只需要openEDS,它包括了以下内容:
可以看到有很多文件夹,但代码中只用到了train、test文件夹中的文件,所以其它的先不用管
看看瞳孔图像的样子:
展示了上述内容后,相信大家对数据集这块有足够的了解了!最重要的一点:只需要把Semantic_Segmentation_Dataset拷贝进代码项目中(不拷贝也行,重定义一下路径就好了),文件摆放格式什么的都不用改,妥妥的保姆级
二、环境配置
我所用的 IDE 是 Pycharm 。从 Github 上下载下来的项目文件中包含2个对项目所需环境的描述文件:requirements.txt、environment.yml,前者只是记录了项目所用的包的名字,并没有各个包的具体版本信息;后者是一种便捷的环境打包文件,记录的就是原作者运行代码时的全部环境,但我在浅浅尝试之后就放弃了这种方法,因为我不会而且也用不好
所以我自己新创建了一个 conda 虚拟环境,对新手更友好,条理也非常清晰!
1.创建 python = 3.8 的 Anaconda 虚拟环境
没有经验的同学可以参考这篇帖子:从零开始创建conda环境及pycharm配置项目环境
打开 Anaconda Prompt,使用下面这条指令就能创建新的虚拟环境了
# Success 是自定义的环境名,python=3.8也是自定义的python版本
conda create -n Success python=3.8
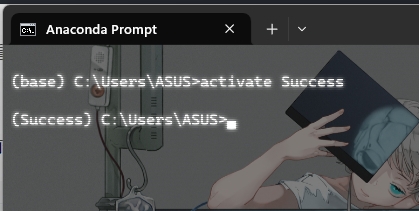
再使用下面这条指令看看环境有没有创建好,出现下图就是好消息
activate Success
这个环境的具体位置在你之前下载的 Anaconda 文件夹下,看看我的:
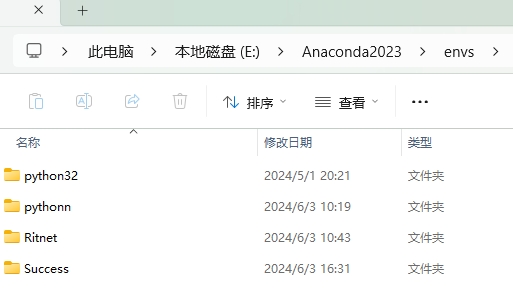
Anaconda2023 是我当时在安装 Anaconda 时新建的文件夹名,而 envs 中就存放着我们建立过的所有虚拟环境啦
创建好之后,把这个环境配置进 Pycharm 里。步骤为:
左上角 -> 设置
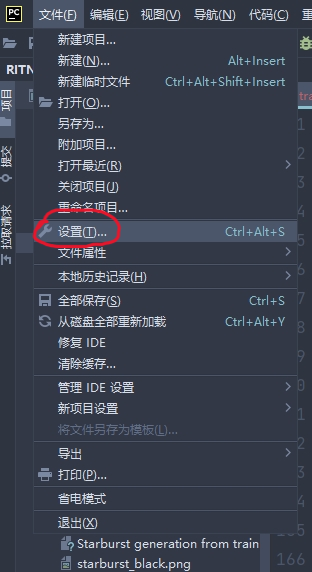
项目:RITNet -> Python解释器 -> 添加解释器 -> 添加本地解释器
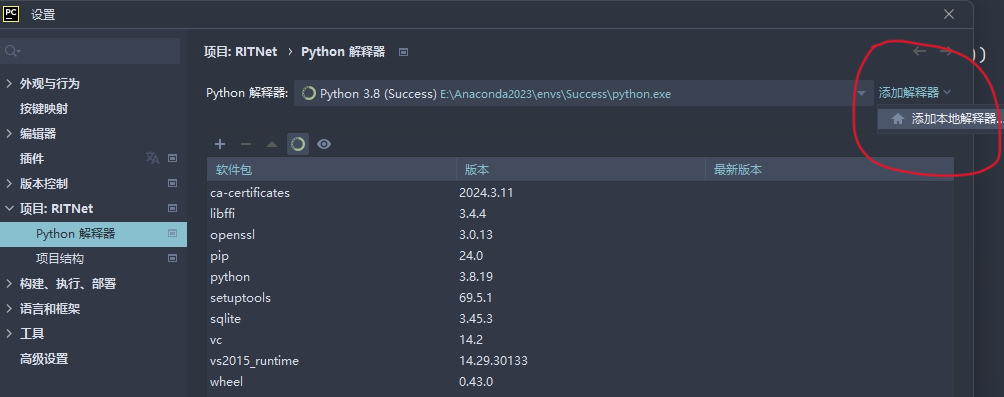
Virtualenv环境 -> 上面提到的 Anaconda 所处位置 -> envs -> 虚拟环境文件夹 -> python.exe(目标文件),选定 python.exe 点“确定”就好了
右下角变成这样就大功告成了

2.在当前虚拟环境中安装所需包
这块是最复杂最关键的部分,所用篇幅较长
a.Pytorch-GPU 安装
在 RITnet 项目中用到了 GPU 来加速模型训练,需要安装 GPU 版本的 Pytorch,这里有很多坑,但经过我长时间的摸索已经总结出一套必杀技:
大家应该经常在网上看到这2条指令 nvcc -V 、nvidia-smi 它们都是用来查看自己电脑上所安装的CUDA版本的,区别在于 nvidia-smi 所查看是自己电脑本身的 CUDA 版本,而 nvcc -V 指令只有你的电脑上有 Pytorch 时才能运行成功(不论GPU版本还是CPU版本),这2条语句的差别很大,而我们只需使用 nvidia-smi 来查看自己电脑的 CUDA 信息即可,如:
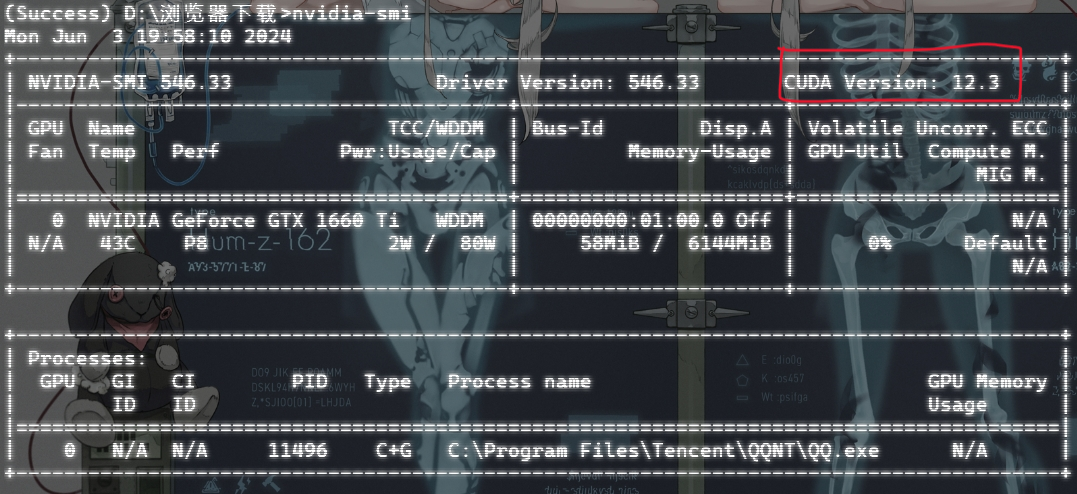
我电脑的 CUDA 版本是 12.3,我们需要根据它来安装 CUDA ,进而安装对应版本的 Pytorch-GPU.
CUDA 安装总体可以参考这篇帖子:全网最详细的安装pytorch GPU方法全网最详细之如何安装gpu版的pytorch,但别完全参考,有小坑!
而在安装 CUDA 时我遇到了 “NVIDIA 安装程序失败的问题”,很棘手,但解决了,解决方式如下:
在选择组件(自定义安装)的时候,将 CUDA 中的 Nsight VSE 和 Visual Studio Integration 取消勾选,后选择下一步,即可安装成功。此招式来自NVIDIA安装CUDA在安装阶段提示NVIDIA安装程序失败超级有用(给磕了)
安装好 CUDA 后,不要使用 pip install 指令直接从 Pytorch 官网下载 GPU 版本的 Pytorch,我下了超多次,结果下下来的都是 CPU 版本的,参考这个全网最详细之如何安装gpu版的pytorch
我将安装的 CUDA 和 torch 等包的对应关系放进下方的表格里,完全按照这个来就行
| CUDA | 12.0.0 |
| torch | 2.0.0 |
| torchvision | 0.15.1 |
| torchaudio | 2.0.1 |
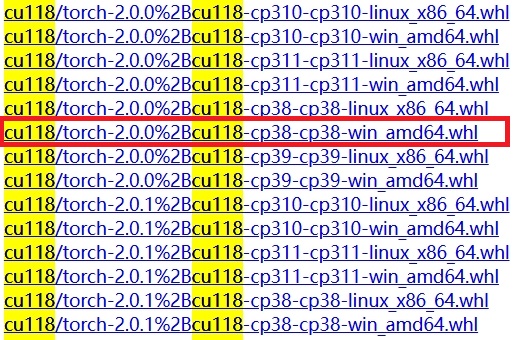
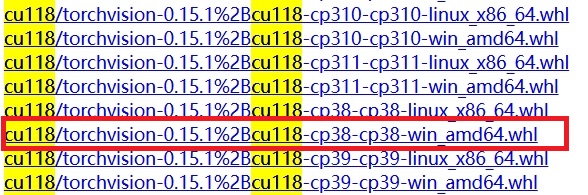
点击进入下载地址,我们需要根据上述表格下载以下3个文件(需要VPN,不然超慢)
torch 下载
torchvision 下载
torchaudio 下载
将上述3个文件都下载好后,进入文件所在目录(切记),在上面的搜索栏里输入 cmd,然后回车即可进入 dos。
在 dos 里激活刚刚创建好的虚拟环境后,使用下面这3行指令将上述3个文件都安装进我们的虚拟环境
pip install "torch-2.0.0+cu118-cp38-cp38-win_amd64.whl"pip install "torchvision-0.15.1+cu118-cp38-cp38-win_amd64.whl"pip install "torchaudio-2.0.1+cu118-cp38-cp38-win_amd64.whl"结束了,一切都结束了!最终用下面这段测试代码美美验证一下 Pytorch-GPU 到底装好没有!
import torch # 测试是否安装完成torch模块
import torchvision # 测试是否安装完成torchvision模块
import osif __name__ == '__main__':print("安装torch版本为: ", torch.__version__)print("是否安装完成Pytorch-GPU : ", torch.cuda.is_available())arr = torch.zeros(5, 5)print("生成全零矩阵:\n", arr)
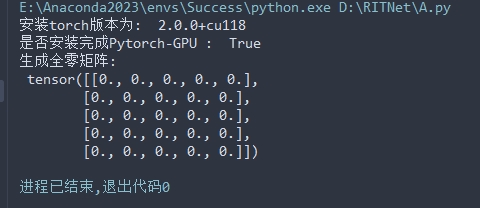
可喜可贺,实在是可喜可贺!
b.其它包的安装
全部使用 pip 进行安装(一定要关掉 VPN)
pip install scikit-learn
pip install numpy
pip install opencv-python # 即cv2
pip install pillow
pip install matplotlib
pip install tqdm
pip install torchsummary
pip install argparse三、代码调整
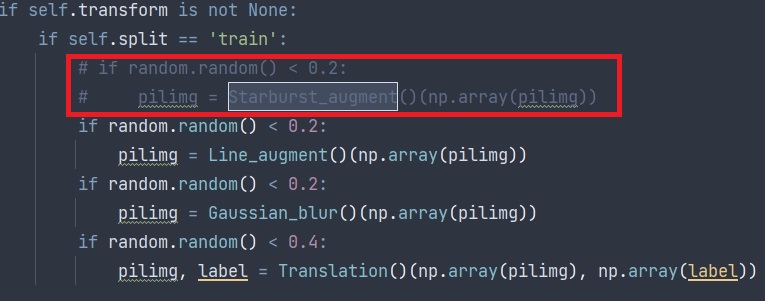
想要运行 train.py,我们还需对其它 .py 文件进行调整.由于给原始瞳孔图像添加星爆图像这部分一直报错(维度问题),尝试解决了很多次,但都没能成功解决,于是把这部分图像预处理代码注释掉了,如果后续有哪位朋友解决了这个问题,还请和大家分享分享!
1.将 dataset.py 中的 Starburst_augment 类全部注释,同时在 IrisDataset 类中的 __getitem__ 函数中注释掉调用 Starburst_augment 类的代码
2.将 __init__中的一行代码转移到__getitem__ 中去.具体操作见下方:
class IrisDataset(Dataset):def __init__(self, filepath, split='train', transform=None, **args):self.transform = transformself.filepath = osp.join(filepath, split)self.split = splitlistall = []for file in os.listdir(osp.join(self.filepath, 'images')):if file.endswith(".png"):listall.append(file.strip(".png"))self.list_files = listallself.testrun = args.get('testrun')# 将下面这行代码换个位置,换到下方的__getitem__函数中去self.clahe = cv2.createCLAHE(clipLimit=1.5, tileGridSize=(8, 8))def __len__(self):if self.testrun:return 10return len(self.list_files)def __getitem__(self, idx):# 从init移过来的self.clahe = cv2.createCLAHE(clipLimit=1.5, tileGridSize=(8, 8))imagepath = osp.join(self.filepath, 'images', self.list_files[idx] + '.png')pilimg = Image.open(imagepath).convert("L")H, W = pilimg.width, pilimg.height整体复现流程就是这样,如果大家自己在复现过程中遇到解决不了的问题可以来私信我(复现论文真的好麻烦好累但别无它选)