Python学习从0开始——Kaggle机器学习003总结
Python学习从0开始——Kaggle机器学习003总结
- 一、加载及浏览数据
- 二、机器学习模型
- 三、模型验证
- 四、欠拟合和过拟合
- 五、随机森林
一、加载及浏览数据
# 路径
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# 读取
melbourne_data = pd.read_csv(melbourne_file_path)
# 总览
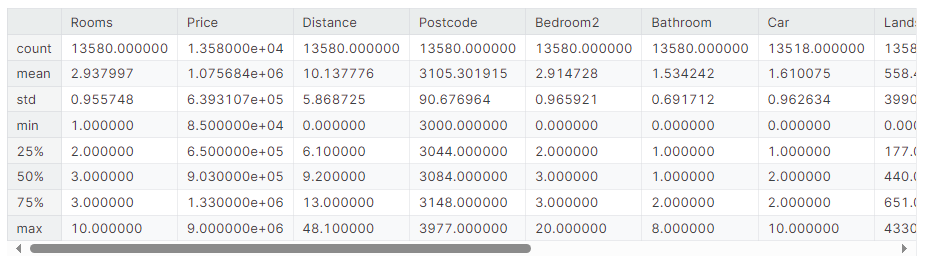
melbourne_data.describe()
输出
二、机器学习模型
# 引入pandas
import pandas as pdmelbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 所有列
melbourne_data.columns
输出:Index([‘Suburb’, ‘Address’, ‘Rooms’, ‘Type’, ‘Price’, ‘Method’, ‘SellerG’,
‘Date’, ‘Distance’, ‘Postcode’, ‘Bedroom2’, ‘Bathroom’, ‘Car’,
‘Landsize’, ‘BuildingArea’, ‘YearBuilt’, ‘CouncilArea’, ‘Lattitude’,
‘Longtitude’, ‘Regionname’, ‘Propertycount’], dtype=‘object’)
#将有缺失值的列设为不可用
melbourne_data = melbourne_data.dropna(axis=0)#通过Dot符号来提取所需列
y = melbourne_data.Price
#通过数组提取目标列
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]
#查看数据
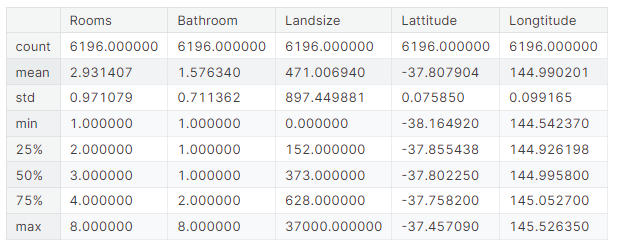
X.describe()
X.head()
输出
#使用sklearn创建模型
from sklearn.tree import DecisionTreeRegressor
#使用步骤
#Define: 是什么类型?决策树?其他类型的模型?还指定了模型类型的其他一些参数。
#Fit: 从提供的数据中捕获模式。这是建模的核心
#Predict: 预测
#Evaluate: 确定模型的预测的准确度# 定义模型。为random_state指定一个数字,以确保每次运行的结果相同
melbourne_model = DecisionTreeRegressor(random_state=1)
# 使用已知数据训练模型
melbourne_model.fit(X, y)
# 预测未知数据
print(melbourne_model.predict(X.head()))
输出:
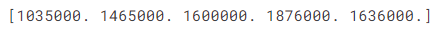
三、模型验证
通过指标分析模型质量,如平均绝对误差MAE(Mean Absolute Error)。
from sklearn.metrics import mean_absolute_errorpredicted_home_prices = melbourne_model.predict(X)
#误差
mean_absolute_error(y, predicted_home_prices)
输出
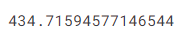
scikit-learn库有一个函数train_test_split,用于将数据分成两部分,其中一些数据作为训练数据来拟合模型,其他数据作为验证数据来计算:
from sklearn.model_selection import train_test_split#通过随机生成器分割,random_state保证每次分割相同
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
#训练
melbourne_model = DecisionTreeRegressor()
melbourne_model.fit(train_X, train_y)
#预测
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))
输出

样本内数据的平均绝对误差约为500,样本外超过25万,这就是一个几乎完全正确的模型和一个不能用于大多数实际目的的模型之间的区别。
作为参考,验证数据中的平均房屋价值为110万,所以新数据的误差大约是平均房屋价值的四分之一。但是有很多方法可以改进,比如通过实验找到更好的特征或不同的模型类型。
四、欠拟合和过拟合
有方法测量模型的准确性,就可以尝试不同的模型以得出最好的预测。在scikit-learn的文档中决策树模型有许多选项,最重要的选项决定了树的深度。树的深度是它在做出预测之前进行分裂的次数。
在机器学习和深度学习中,过拟合(Overfitting)和欠拟合(Underfitting)是两种常见的问题,它们都与模型在训练数据上的表现和在未见过的测试数据上的泛化能力之间的关系有关。
过拟合指的是模型在训练数据上表现非常好,但在测试数据上表现较差的现象。这通常是因为模型过于复杂,以至于它“记住”了训练数据中的噪声和细节,而不是学习到了数据的普遍规律。因此,当模型面对新的、未见过的数据时,它无法正确地进行预测。
过拟合的表现:
- 训练误差非常低,但测试误差很高。
- 模型在训练数据上的表现很好,但在测试数据上的表现很差。
- 模型对于训练数据中的噪声和异常值非常敏感。
解决过拟合的方法:
- 增加数据量:更多的数据可以帮助模型学习到更普遍的规律,而不是仅仅记住训练数据。
- 简化模型:减少模型的复杂度,例如减少神经网络的层数或神经元数量。
- 正则化:在损失函数中添加正则化项,如L1正则化或L2正则化,以惩罚模型的复杂度。
- 早停法(Early Stopping):在验证误差开始上升时停止训练。
- 数据增强:通过旋转、缩放、裁剪等操作来增加训练数据的多样性。
- 集成方法:如Bagging和Boosting,通过组合多个模型的预测结果来提高泛化能力。
欠拟合(Underfitting)
欠拟合指的是模型在训练数据上的表现就很差,更不用说在测试数据上了。这通常是因为模型过于简单,无法捕捉到数据中的复杂关系或规律。
欠拟合的表现:
- 训练误差和测试误差都很高。
- 模型无法对训练数据进行有效的预测。
解决欠拟合的方法:
- 增加模型复杂度:例如增加神经网络的层数或神经元数量。
- 使用更复杂的模型:例如从线性模型切换到非线性模型。
- 减少正则化强度:如果使用了正则化,可以尝试减少正则化项的权重。
- 检查数据质量:确保数据是正确标记的,并且没有过多的噪声或异常值。
- 增加训练时间:确保模型已经充分训练,没有提前停止。
在实际应用中,通常需要在这两种问题之间找到一个平衡,以使模型在训练数据和测试数据上都有良好的表现。这通常需要一些试验和调优工作。
由于我们关心新数据的准确性,这是我们从验证数据中估计的,我们希望找到欠拟合和过拟合之间的最佳点。从视觉上看,我们需要下图中(红色)验证曲线的低点。
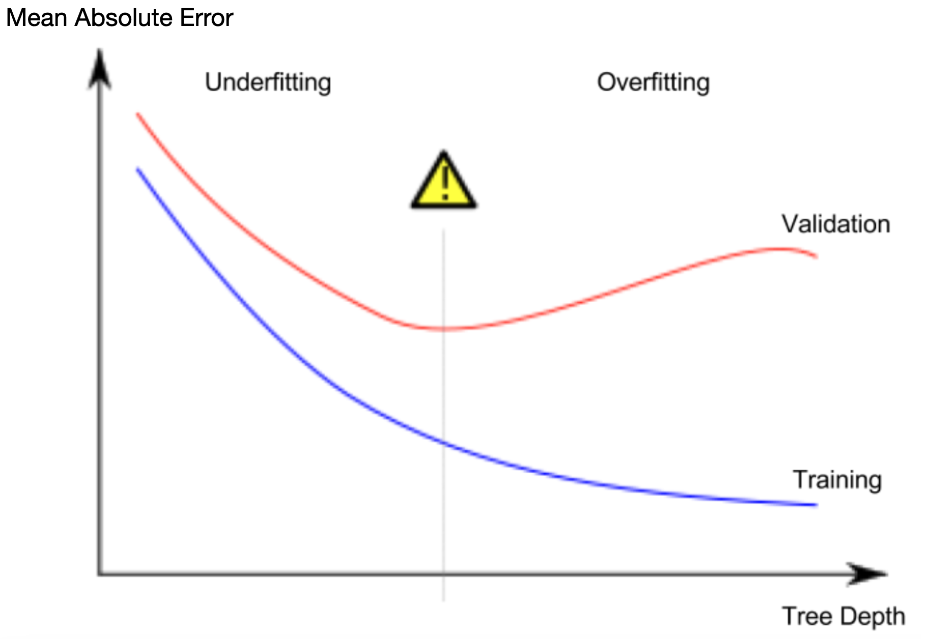
通过max_leaf_nodes参数来调整过拟合与欠拟合,我们允许模型生成的叶子越多,我们就越能从上图中的欠拟合区域移动到过拟合区域。
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressordef get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)model.fit(train_X, train_y)preds_val = model.predict(val_X)mae = mean_absolute_error(val_y, preds_val)return(mae)# compare MAE with differing values of max_leaf_nodes
for max_leaf_nodes in [5, 50, 500, 5000]:my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
输出

所以此处500是最优数量。
五、随机森林
随机森林使用许多树,它通过平均每个组成树的预测来进行预测。它通常比单一决策树具有更好的预测准确性,并且在默认参数下工作得很好。
#通过随机森林建树
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_errorforest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X, train_y)
melb_preds = forest_model.predict(val_X)
print(mean_absolute_error(val_y, melb_preds))