从0开始学人工智能测试节选:Spark -- 结构化数据领域中测试人员的万金油技术(三)
分布式计算原理
分布式计算的原理总结一句话就是:分而治之。

- 把数据分片,存在不同的机器中,解决数据存储的压力。
- 客户端和服务端之间通过相关协议来自动的完成在不同的机器之间进行数据的存取,用户并不感知数据的物理存储结构。 用户面对的只有hdfs://xxx/user/xx.txt这样的路径地址。 其余的都由客户端和服务端自动完成。
所有的分布式软件都是分而治之的思路, 当数据量大到了单机无法承载的时候, 那么就利用上面的原理 ,把数据分布到不同的机器中。 这样的架构也就可以支持横向扩展,也就是当存储软件的性能或者磁盘空间不够用时, 只要加机器就可以了。
下面是HDFS(一个分布式文件系统,属于hadoop生态)的架构图:
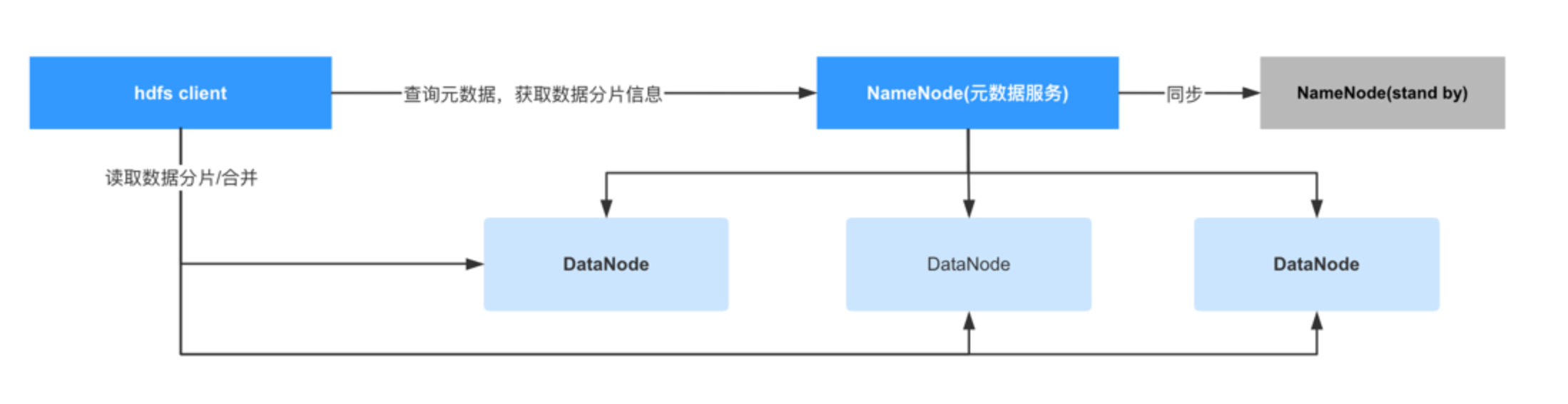
- DataNode:真正存储数据的节点
- NameNode:元数据服务器,存储所有数据的元信息,比如数据存储在哪些机器中的哪些路径。
- NameNode(standby):NameNode的备用节点,当主NameNode故障后,该服务会接替成为NameNode
- Hdfs client会负责查询NameNode获取数据分片信息并处理后返回给用户,用户不感知数据分布情况。
在HDFS中, NameNode负责存储所有文件的元数据, 实际上所有的分布式文件存储软件都有一个类似NameNode的角色,毕竟数据分散在N个不同的机器中, 为了不让用户感知到这复杂的文件分布, 所以需要有这样的一个角色来保存这些文件的元数据,这样客户端才可以跟服务端交互自动的完成文件的整合工作,用户也可以在不感知的前提下读写文件, 大大降低了使用的复杂度。
需要注意的是对于HDFS来说, 可以支持的文件数量都是有限的,并且对于小文件的存储非常的不友好。 因为HDFS是基于数据都是大数据的前提下进行设计的,所以它在文件切片并保存在不同的机器上的时候,是默认128M为一个block(块)进行存储,即便文件不足128M也会按128M进行保存。 也就是如果一个小文件只有28M,那么在HDFS中也会占用128的存储空间, 这100M就是浪费的。 并且对于HDFS来说,我们可以看到它的设计里虽然可以有多个NameNode,但在同一个时间内只能有一个NameNode对外提供服务。 这是出于高可用的考虑(简化元数据在多个namenode同步的问题,因为只有一个namenode在线, 所以剩下了很多数据一致性的问题),但它的缺点就是它没有负载均衡的能力,当文件数量过多时,就会对NameNode产生很大的压力, 使得集群整体的性能受到影响。所以我们在测试分布式存储软件本身的时候,也需要测试它能够承载的文件数量。 所以一般在分布式存储软件中,或者大数据系统中, 一般测试人员都会测试海量小文件的场景 -- 构造海量的小文件并保存在存储系统中,验证它的各项性能指标。 后面讲到造数工具的时候, 会演示如何在短时间内构造这样大批量的数据。
分布式计算
分布式计算的原理也是一样的,都是分而治之:

数据存储的时候可以把数据分布在不同的机器中, 那么在计算时也可以把一个大的任务拆分成N个小任务在调度到不同的机器中来完成。 它的大概过程是这样的:
- 计算任务分布在不同的节点中,各自掌握一段数据分片
- 每个计算任务各自计算自己掌握的数据
- 各个任务计算完毕后进行汇总并返回给客户端
shuffle与数据倾斜
当我们了解到分布式计算的基本运算原理后,就可以开始了解在大数据领域中最著名的一个设计, 同样也号称是大数据领域中的头号性能杀手 -- shuffle。 这是从 MapReduce 时代就开始的分布式计算独特的设计理念。 理解好 shuffle 的原理对学习 spark 甚至是任何一门大数据技术都是至关重要的。Shuffle 中文翻译为 “洗牌”,需要 Shuffle 的关键性原因是某种具有共同特征的数据需要最终汇聚到一个 partition 上进行计算。为什么要这么做呢? 因为对于一个分布式计算框架来说,网络通信的开销是十分昂贵的。假设我们有一千个计算节点在并发的执行一个计算任务。它们要聚合,计算,统计。数据在这一千个节点之间流动会造成相当大的网络负担。所以 spark 的设计者们为了减少网络开销而设计了 shuffle。它的原理就是尽量把一个计算任务所要处理的所有数据都聚集在一个 partition 上,这样就节省了很多的网络开销。 例如我们今天学到的 groupByKey() 聚合操作,spark 一旦执行到这一步的时候,会把所有 key 相同的数据分配到同一个 partition 上以供后续操作。例如 key 为 A 的行分配到 X 节点进行计算,key 为 B 的行分配到 Y 节点进行计算,这样在之后的计算中就免去了网络开销。而这个过程就是 shuffle。所谓洗牌就是这个意思了。
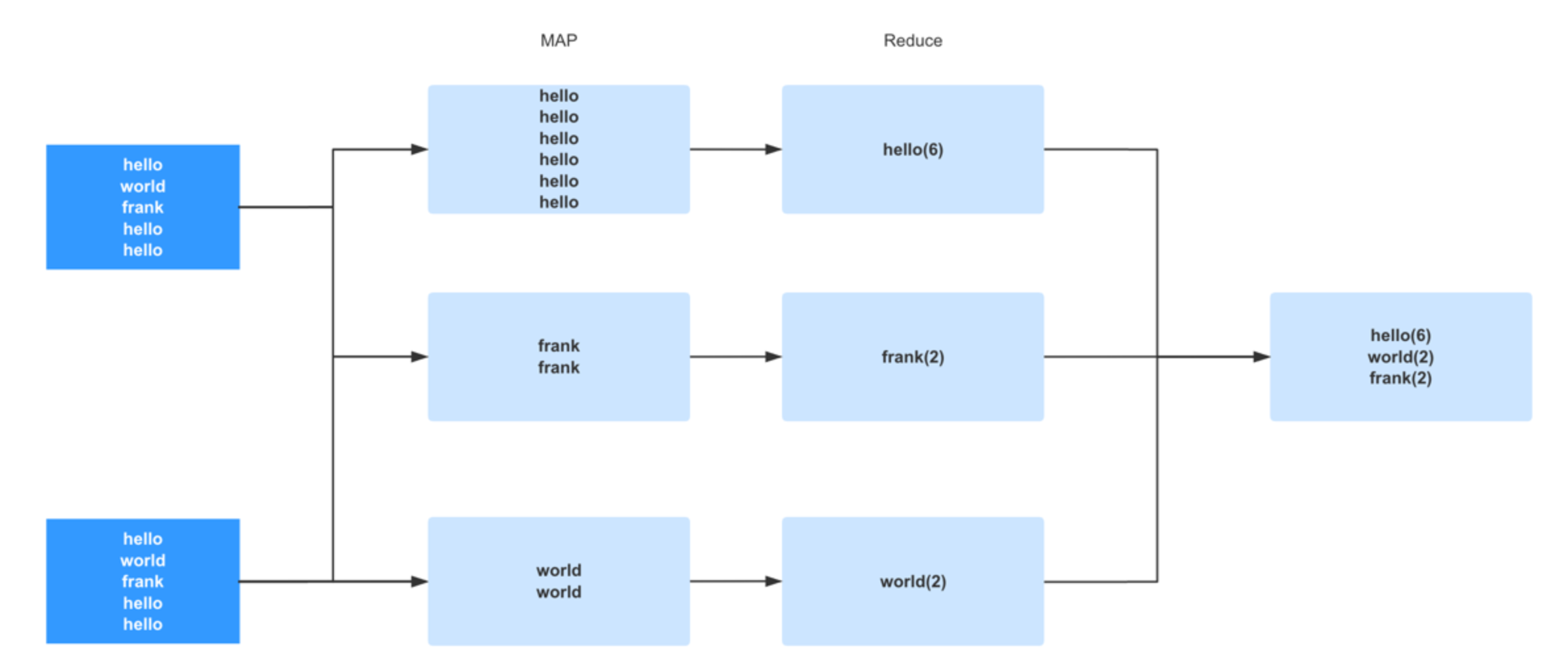
我们了解了 shuffle 相关的概念和原理后其实可以发现一个问题,那就是 shuffle 比较容易造成数据倾斜的情况。 例如上面我们看到的图,在这批数据中,hello 这个单词的行占据了绝大部分,当我们执行 groupByKey 的时候触发了 shuffle。这时候大部分的数据 (Hello) 都汇集到了一个 partition 上。这种极端的情况就会造成著名的长尾现象,就是说由于大部分数据都汇集到了一个 partition 而造成了这个 partition 的 task 运行的十分慢。而其他的 task 早已完成,整个任务都在等这个大尾巴task 的结束。 这种现象破坏了分布式计算的设计初衷,因为最终大部分的计算任务都在一个单点上执行了。所以极端的数据分布就成为了机器学习和大数据处理这类产品的劲敌,我跟我司的研发人员聊的时候,他们也觉得数据倾斜的情况比较难处理,当然我们可以做 repartition(重新分片) 来重新整合 parition 的数量和分布等操作,以及避免或者减少 shuffle 的成本,也可以重新分配key来避免数据倾斜,各家不同的业务有不同的做法。在做这类产品的性能测试的时候,也跟我们以往的互联网模式不同,产品的压力不在于并发量上,而在于数据量和数据分布上(大数据产品中,批处理业务很少有极高的并发操作,只有流计算里才会有高并发,而流计算我们放到以后的章节来讲)。
总而言之对于大数据产品来说,数据是否符合真实场景(包括数据的分布,分片,行数,列数等等)就决定性能测试的结果是否准确。 在很多产品中很难从线上直接拉取数据,有些场景是因为线上也没有足够的高质量数据,也有的是因为数据量实在过于庞大, 比如我们曾经测试过百亿,千亿和万亿规模的数据。 即便线上环境有这样庞大的数据, 但要把数据从线上同步到测试环境也会长期占用极其庞大的网络带宽, 这为线上带来了很大的风险。 同时对于很多做TOB类型的大数据产品来说(大数据产品大多都是TOB的,当然不一定是私有云, 也可能是公有云), 客户数据是保密的,我们没有办法直接拿现成客户数据。
所以综上所述, 测试人员需要开发一款造数工具来在短时间内构建海量的数据, 而这部分内容,我将会在下一个章节讲解。
更多内容欢迎来到我的知识星球:
