探索大模型技术及其前沿应用——TextIn文档解析技术
前言
中国图象图形大会(CCIG 2024)于近期在西安召开,此次大会将面向开放创新、交叉融合的发展趋势,为图像图形相关领域的专家学者和产业界同仁,搭建一个展示创新成果、展望未来发展,集高度、深度、广度三位于一体的交流平台。大会期间,合合信息智能创新事业部研发总监常扬做了《文档解析技术加速大模型训练与应用》主题报告,介绍了TextIn文档解析技术的技术特征。下面为大家分享一下这次报告的主要内容。
发展现状
目前大模型训练和应用过程中面临训练Token耗尽、训练语料质量要求高、LLM文档问答应用中文档解析不精准的问题。目前互联网能够提供的语料资源预计将在2026年耗尽,提升大模型应用效果需要更多更高质量的语料。同时文档类语料(chart-pdf或chart-excel等)识别精度很差,严重影响模型应用效果。
而目前提高大模型训练效果最佳场景集中于书籍、论文等文档中,而它们往往都是PDF格式,甚至是图片扫描件。我们再训练时需要对这些文档进行文档格式识别、图表内容及标题提取、版面正确解析、阅读顺序处理的转换,同时要确保转换速度足够快。比如下面这个gpt阅读文档的例子: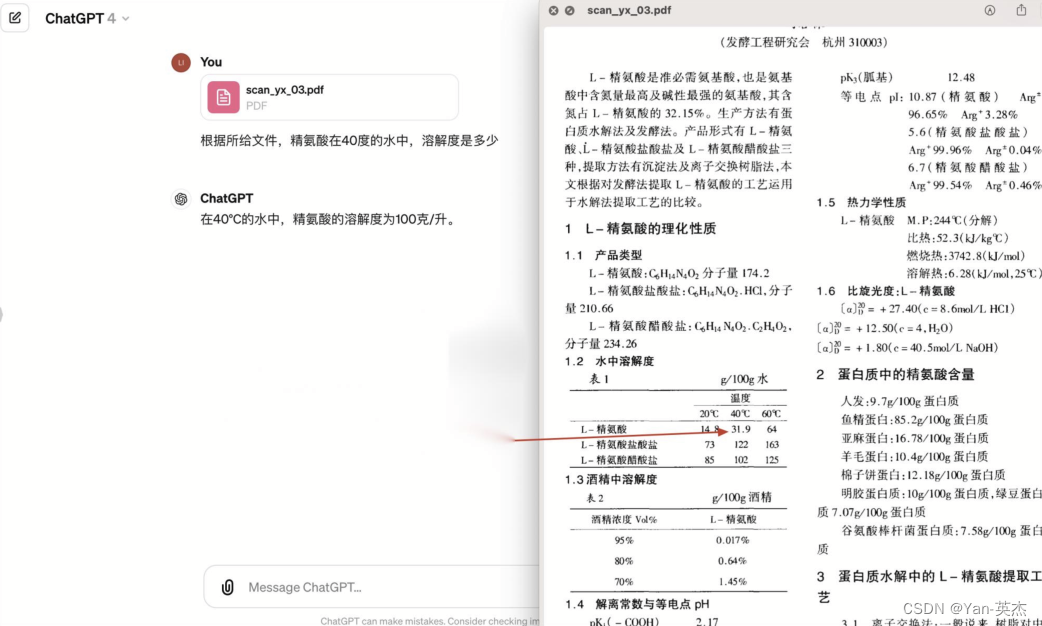
在这个例子中,由于文章包含一个非标准的列表,使得大模型没有识别到内容。

这个例子中,由于双栏排版使得大模型识别到了错误的内容。这些例子都说明目前迫切需要一个具备多文档元素识别、版面分析、高性能的文档解析技术,并将其应用在大模型的准备过程中。
技术难点
由于文档版式多样,模型很难有一个统一的处理方式。比如下面的一些例子:

在这个例子中,页眉的形式多种多样,没有统一的格式。
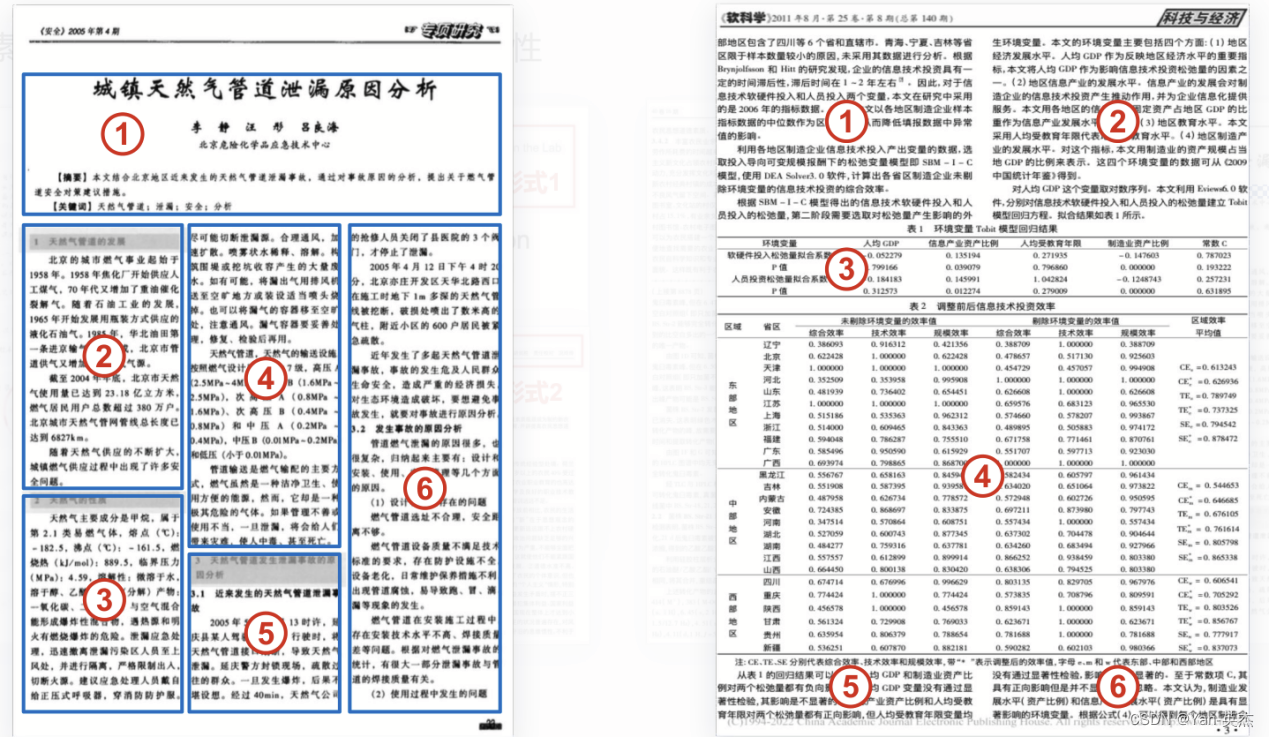
这个例子中表格和多栏排版混合为文档解析增加了困难。
这个例子中无线表格和合并单元格会使得文字无法定位。

这个例子中,公式的出现阻碍了文字信息的识别和提取。
在这些例子里,我们观察到有元素遮盖、重叠,元素(页眉页脚等)有多样性;版式(双栏、跨页、三栏)造成的阅读顺序差异,多栏中插入表格的影响,无线表格以及单元格合并拆分带来的识别困难,单行公式、行内公式以及表格内公式的影响等等一些问题。
TextIn文档解析技术
针对上面的问题,合合信息研发了TextIn文档解析技术,它专注于处理电子档、扫描件。在识别到文档类型后会提取其中的文字,之后基于合合信息多年的技术积累,对文档进行物理和逻辑版面分析。整个处理流程如下:
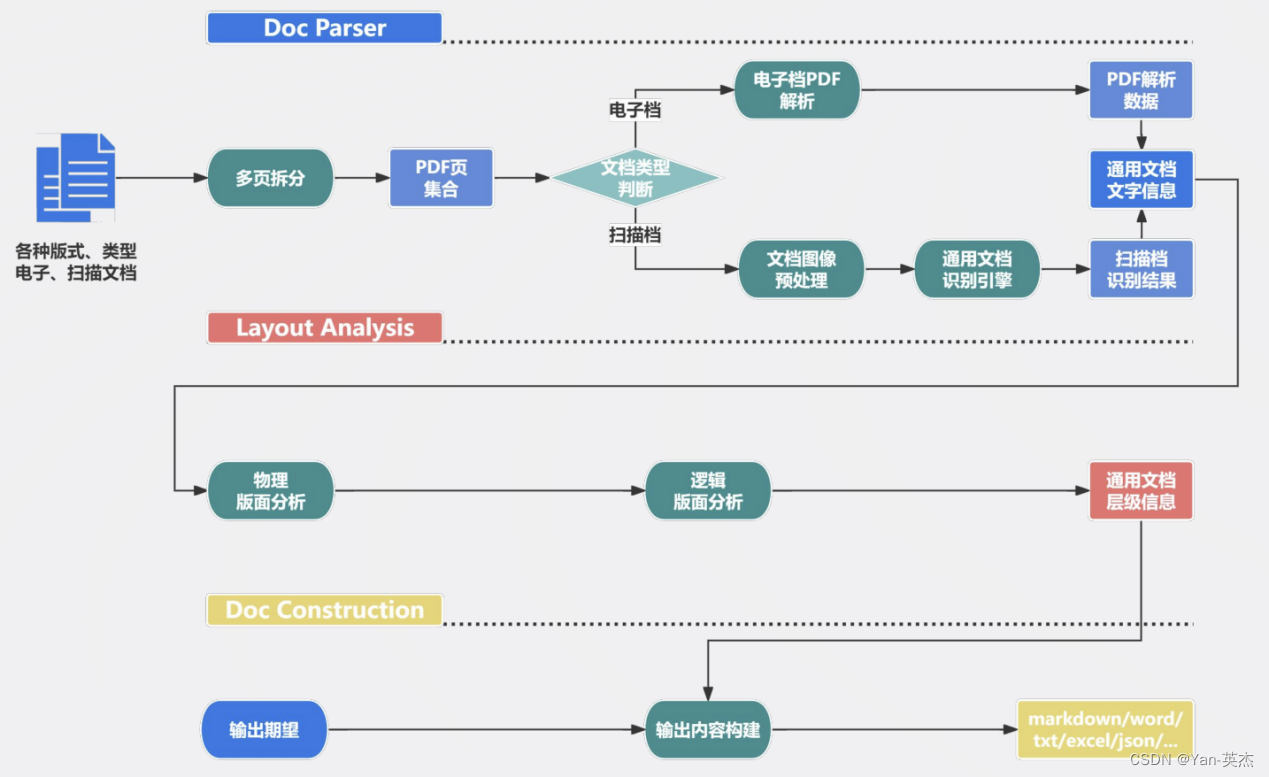
首先将各种类型的文档进行多页拆分,之后按照文档类型进行对应的预处理,然后提取文档数据,整合为通用文档文字信息。之后再对文档进行物理版面分析以及逻辑版面分析,将其与文字信息合并为一个通用文档层级信息。最后依据模型训练需求,将结果转换为指定的格式。
核心技术
TextIn的核心技术选用了业界领先的模块,旨在实现高精度的文档解析效果。这些模块涵盖了文档图像预处理算法、版面分析算法框架以及逻辑版面分析算法,具体功能如下:
文档图像预处理算法包括区域提取、干扰去除、形变矫正、图像恢复和图像增强等模块。这些模块的主要任务是提升文字信息提取的准确性和效率。
区域提取可以识别并提取出文档中具有文字信息的区域,确保后续处理聚焦在有用的部分。

形变矫正通过分析形变文档的偏移场,将其矫正为正常的图像,并利用附近的像素点填充缺失部分,确保图像的完整性。

图像恢复和图像增强则进一步优化图像质量,使得文字信息更加清晰和易于识别。图像文档干扰去除算法使用U2net卷积提取出图像的背景,然后通过cab技术去除干扰,得到一个更高质量的图像。

版面分析算法框架分为物理版面分析和逻辑版面分析两个主要模块。物理版面分析侧重于视觉特征,识别文档中的各个元素,将相关性高的文字聚合到一个区域,这一过程主要关注文档的视觉布局和结构。逻辑版面分析则侧重于语义特征,聚焦于文档结构,其主要任务是通过语义建模将不同的文字块形成层次结构,例如通过树状结构展示文档的语义层次关系。检测模型选用了单阶段的检测模型,关注小规模数据和模型的调优,以提升识别精度

文档布局分析将文档转换为标准的“页-节-段-切片”层次化布局,有助于系统更高效地处理文档内容。

大模型在工作时,先定位目标页面,再寻找相关切片,从而提高运行速度和精度。逻辑版面分析算法通过预测每个段落与上一个段落的关系,将其分为子标题、子段落、合并、旁系、主标题、表格标题等类型。如果是旁系类型,则继续向上查找父节点,并判断其层级关系,直至找到最终的父节点。
通过这一系列技术,TextIn在文档解析工作上展现了卓越的效果。

此外,在与生成式模型的配合应用上,TextIn同样表现出色,进一步提升了文档解析和处理的整体性能。
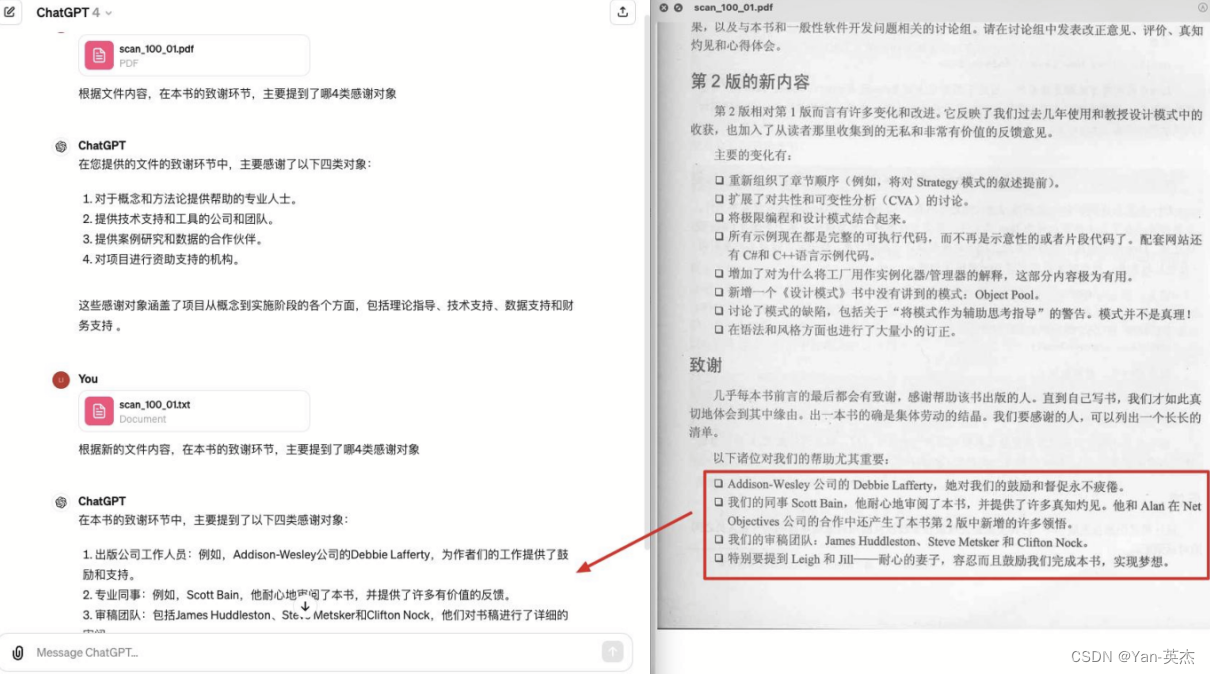
技术解析
DocUNet网络
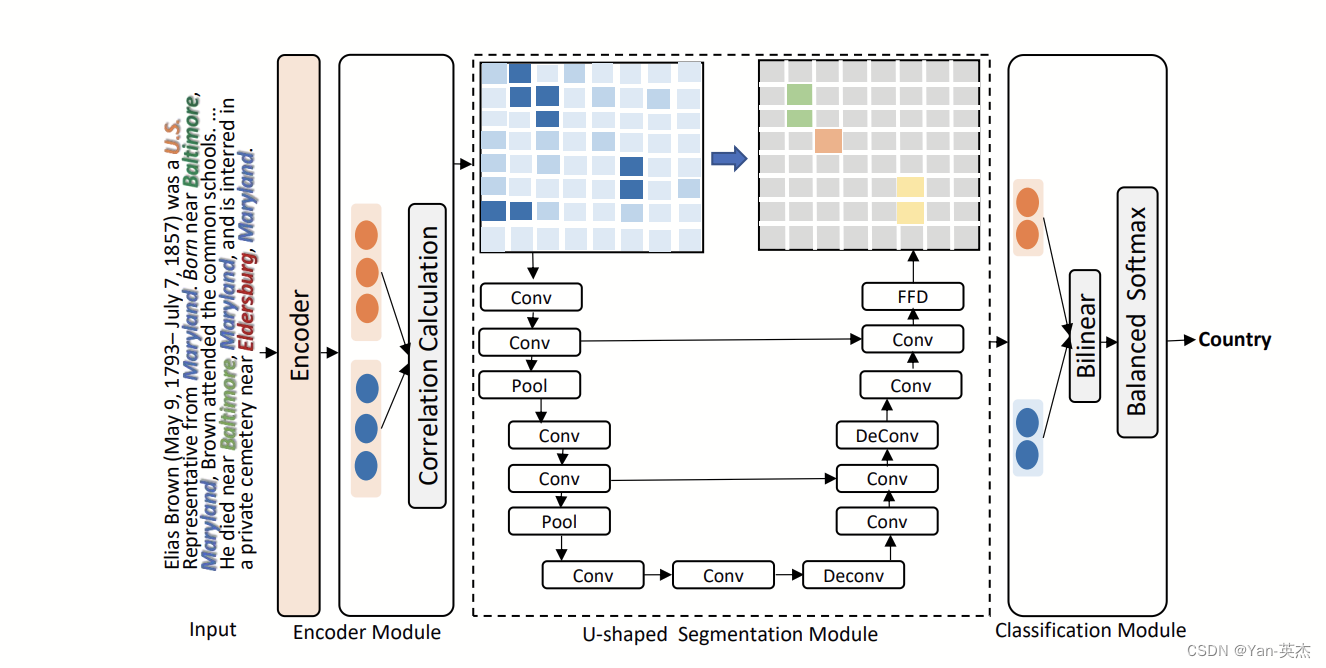
DocUNet模型可以捕获文档级RE的三元组之间的本地上下文信息和全局相互依赖性,将文档级RE表述为语义分割。具体来说,用一个编码器模块来捕获实体的上下文信息,并引用一个U形分割模块来捕获图像样式特征图上的三元组之间的全局相互依赖性。它的主要步骤是:首先通过一个编码器提取输入图像的特征,然后计算相关性并传入U形分割模块进行预测,最后通过损失函数调整结果,进行分类。
U2Net网络
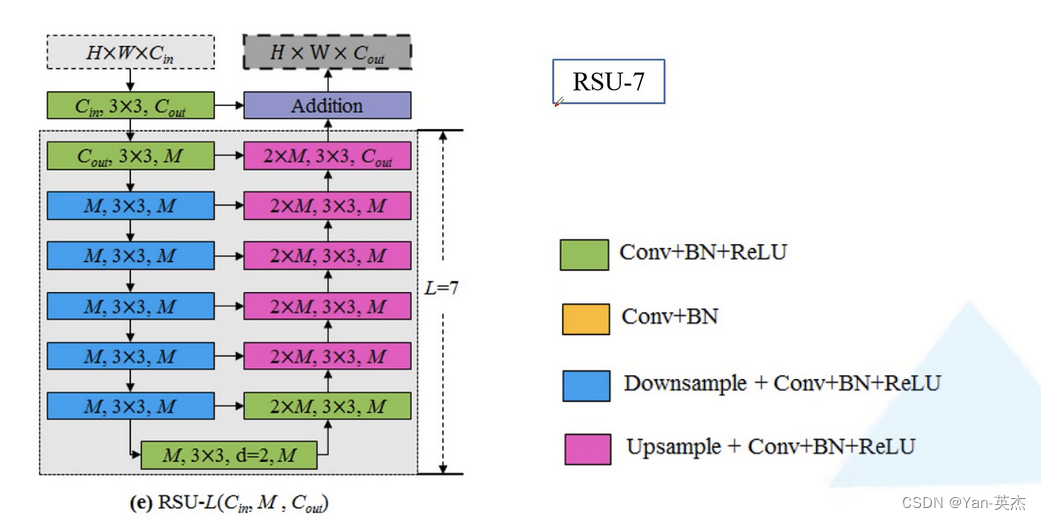
U2net是一种用于图像分割的神经网络模型。它的网络结构为大型的U-net结构的每一个block里面也为U-net结构。其中Block总共分两种,一种是Encoder1-4以及Decoder1-4,另一种是Encoder5-6和Decoder5。

第一种block在Encoder阶段,每通过一个block后都会通过最大池化层下采样2倍,在Decoder阶段,通过每一个block前都会用双线性插值进行上采样。如下图,绿色代表卷积+BN+ReLU,蓝色代表下采样+卷积+BN+ReLU,紫色代表上采样+卷积+BN+ReLU,在RSU-7中下采样了5次,也即把输入特征图下采样了32倍,同样在Decoder阶段上采样了32倍还原为原始图像大小。
 第二种block是RSU-4F主要是在RSU-4的基础上,将下采样和上采样换成了膨胀卷积,整个过程中特征图大小不变。
第二种block是RSU-4F主要是在RSU-4的基础上,将下采样和上采样换成了膨胀卷积,整个过程中特征图大小不变。

在每个block工作完成后,将每个阶段的特征图进行融合,并对他们做3*3的卷积,卷积核个数为1,再用线性插值进行上采样恢复到原图大小,进行concat拼接,使用sigmoid函数输出最终分割结果。
Transformer模型
Transformer模型是近年大火的模型。它由多个编码器和解码器块堆叠构成,每个块包括两个子层:多头自注意力层和全连接前馈层。每个子层后增加了一个残差连接,并进行层归一化操作。
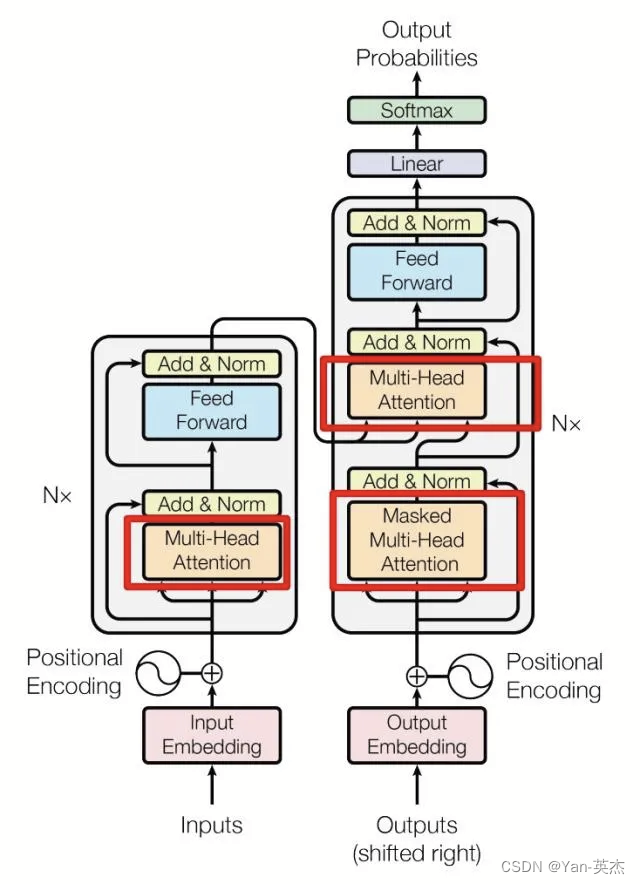
多头自注意力层包含若干自注意力层。自注意力层使用权重矩阵得到查询向量Q、键向量K和值向量V,带入公式即可得到输出,最终的输出即为前馈神经网络的输入。全连接前馈层包括一个两层的全连接网络和一个非线性激活函数。
残差连接与归一化层的引入可以解决梯度消失的问题。残差连接需要输入和输出的维度相同,此处将输出维度设置成 . 归一化将每一层神经元的输入都转成均值方差都一样的,可以加快收敛。
解码器相比编码器增加了一个多他自注意力层,并采用了掩码操作,目的是防止Q去对序列中尚未解码的位置施加操作。解码器输出结果经过线性连接后,由一个Softmax层计算预测值。
体验TextIn文本解析Demo
TextIn的官网上提供了一个对给定的句子列表进行向量化,并计算句子之间的相似度的案例。下面是详细步骤:
首先我们定义一个包含两个句子的列表 sentences。
sentences = ["数据1", "数据2"]之后使用 'acge_text_embedding' 预训练模型初始化 SentenceTransformer 对象,并将其赋值给 model 变量。
model = SentenceTransformer('acge_text_embedding')接下来使用 model.encode() 方法对 sentences 列表中的句子进行向量化,得到两组嵌入向量 embeddings_1 和 embeddings_2。设置参数normalize_embeddings为True,表示归一化这些向量,使其长度为1。
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)最后计算两组向量 embeddings_1 和 embeddings_2 之间的相似度。@ 符号表示矩阵乘法,embeddings_2.T 表示 embeddings_2 的转置矩阵。这将得到一个相似度矩阵 similarity,其中 similarity[i][j] 表示 sentences[i] 和 sentences[j] 之间的余弦相似度。
similarity = embeddings_1 @ embeddings_2.T完整代码如下:
from sentence_transformers import SentenceTransformersentences = ["数据1", "数据2"]
model = SentenceTransformer('acge_text_embedding')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)总结
上海合合信息科技股份有限公司通过其智能文字识别技术TextIn文档解析在电子档解析和扫描档识别领域表现出色,保证了准确识别且不漏检、不错检。该技术在处理无线表、跨页表格、页眉、页脚、公式、图像、印章、流程图、目录树等元素方面非常出色。此外,TextIn文档解析已经适配云服务集群,在云服务方面综合体验良好,速度快、服务稳定,能够实现100页PDF解析工作最快1.46秒。上海合合信息科技股份有限公司还致力于为全球企业和个人用户提供创新的数字化、智能化服务,其开发的C端产品全球累计用户下载超过23亿,月活跃用户约1.3亿,其中名片全能王和扫描全能王免费版在App Store排行榜上名列前茅。