聊聊二叉堆、红黑树、时间轮在定时任务中的应用
定时任务作为常用的一种调度方式,在各大系统得到了广泛的应用。
笔者也曾写过两篇关于定时任务框架介绍的文章:
- 《介绍一下,spring cloud下的另一种定时任务解决方案》
- 《四叉堆在GO中的应用-定时任务timer》
之前都是以如何使用为主,这次从数据结构与调度机制角度出发,对java中的定时任务再整体回顾一下。
单线程队列-timer
首先回顾下jdk中自带的timer。
以每隔5秒输出当前时间戳为例,代码如下:
Timer timer = new Timer();timer.scheduleAtFixedRate(new TimerTask() {@Overridepublic void run() {System.out.println(System.currentTimeMillis());}}, 0, 5_000);
代码非常简洁,调用timer的scheduleAtFixedRate对TimerTask中的方法进行定时触发。
看一下Timer类的构成,类图如下:
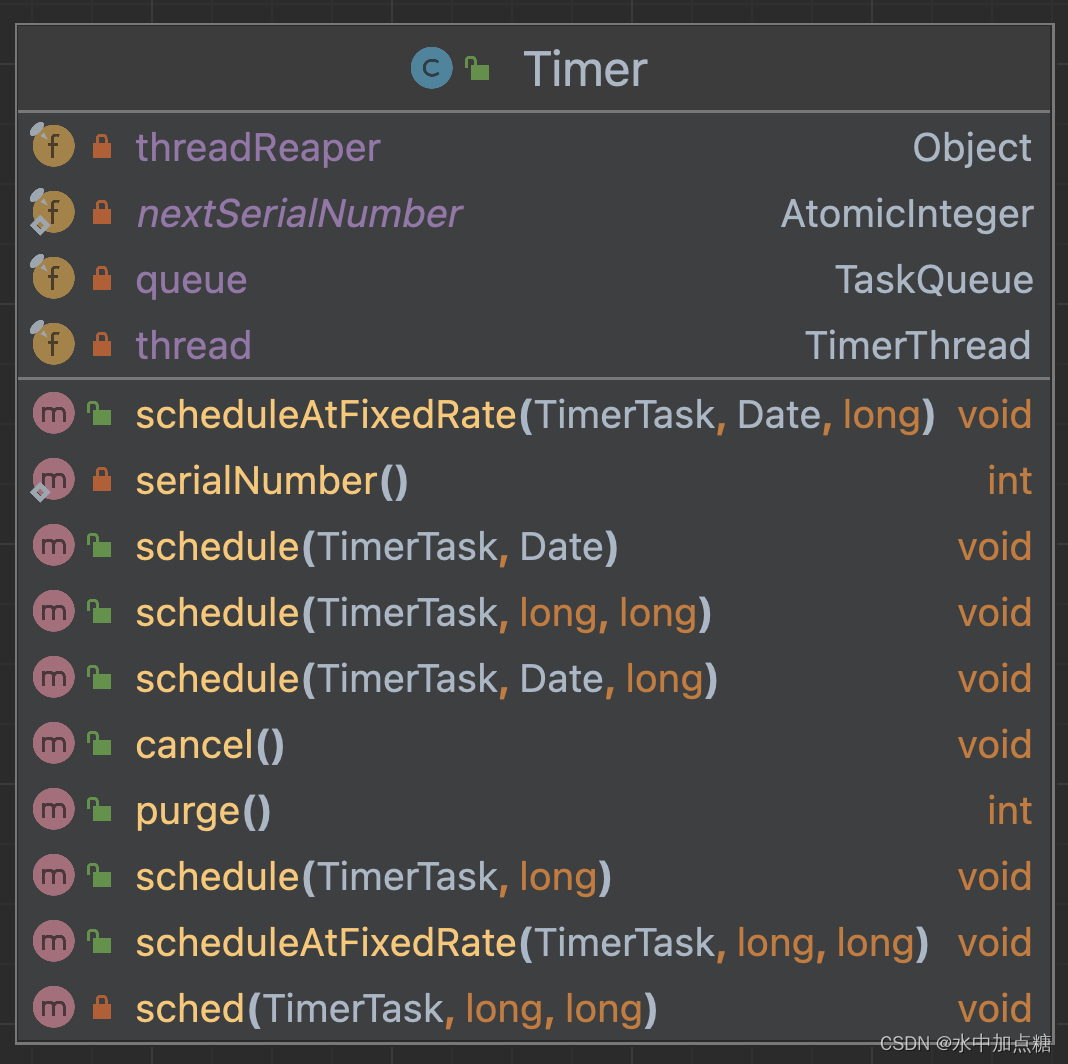
结合代码看一下:
public class Timer {//存放TimerTask的队列private final TaskQueue queue = new TaskQueue();//执行TimerTask的线程private final TimerThread thread = new TimerThread(queue);private final Object threadReaper = new Object() {@SuppressWarnings("deprecation")protected void finalize() throws Throwable {synchronized(queue) {thread.newTasksMayBeScheduled = false;queue.notify(); // In case queue is empty.}}};private static final AtomicInteger nextSerialNumber = new AtomicInteger(0);
nextSerialNumber是static的,以确保在同一个JVM中所有的serialNumber都是自增唯一的。
以定时执行某个任务为例,向Timer提交一个定时任务调用的是scheduleAtFixedRate方法。
public void scheduleAtFixedRate(TimerTask task, long delay, long period) {if (delay < 0)throw new IllegalArgumentException("Negative delay.");if (period <= 0)throw new IllegalArgumentException("Non-positive period.");//执行时间=当前时间戳+延迟时间sched(task, System.currentTimeMillis()+delay, period);}private void sched(TimerTask task, long time, long period) {if (time < 0)throw new IllegalArgumentException("Illegal execution time.");// Constrain value of period sufficiently to prevent numeric// overflow while still being effectively infinitely large.if (Math.abs(period) > (Long.MAX_VALUE >> 1))period >>= 1;synchronized(queue) {if (!thread.newTasksMayBeScheduled)throw new IllegalStateException("Timer already cancelled.");synchronized(task.lock) {if (task.state != TimerTask.VIRGIN)throw new IllegalStateException("Task already scheduled or cancelled");task.nextExecutionTime = time;task.period = period;task.state = TimerTask.SCHEDULED;}//将次task添加到队列中queue.add(task);if (queue.getMin() == task)queue.notify();}}
timer除了支持定时周期性任务scheduleAtFixedRate,也支持一次性延迟任务,最终都会调用用sched方法。
sched方法中仅实现入队的操作,且如果提交的Task位于队列头部则立即唤醒queue。
timer中入队的操作为二叉堆算法实现,细节不再复述。
如果向timer提交的TASK不位于队列头部,则由Timer中的TimerThread调度,首次调度时间为Timer初始化时开始。
public Timer(String name) {thread.setName(name);thread.start();}
调用过程为一个死循环,详细逻辑位于mainLoop方法中。
public void run() {try {mainLoop();} finally {// Someone killed this Thread, behave as if Timer cancelledsynchronized(queue) {newTasksMayBeScheduled = false;queue.clear(); // Eliminate obsolete references}}}private void mainLoop() {while (true) {try {TimerTask task;boolean taskFired;synchronized(queue) {// Wait for queue to become non-emptywhile (queue.isEmpty() && newTasksMayBeScheduled)queue.wait();if (queue.isEmpty())break; // Queue is empty and will forever remain; die// Queue nonempty; look at first evt and do the right thinglong currentTime, executionTime;task = queue.getMin();synchronized(task.lock) {if (task.state == TimerTask.CANCELLED) {queue.removeMin();continue; // No action required, poll queue again}currentTime = System.currentTimeMillis();executionTime = task.nextExecutionTime;if (taskFired = (executionTime<=currentTime)) {if (task.period == 0) { // Non-repeating, removequeue.removeMin();task.state = TimerTask.EXECUTED;} else { // Repeating task, reschedulequeue.rescheduleMin(task.period<0 ? currentTime - task.period: executionTime + task.period);}}}if (!taskFired) // Task hasn't yet fired; waitqueue.wait(executionTime - currentTime);}if (taskFired) // Task fired; run it, holding no lockstask.run();} catch(InterruptedException e) {}}}
判断队列头部TASK是否达到执行时间,如满足则调用task.run,也就是运行此定时任务。
采用二叉堆,在一个线程中调用,与GO中自带的定时任务非常类似,整体比较简单。
线程池timer
通过前文了解,咱们知道了通过Timer+TimerTask可实现简单类型的定时任务,但在实际开发过程中如果安装了alibaba的代码规范检测插件(https://github.com/alibaba/p3c),Alibaba Java Coding Guidelines
则会对TimerTask报告警,如:

它要求使用ScheduledExecutorService来替换Timer。
那么,ScheduledExecutorService是何方神圣?
熟悉JAVA的老司机都知道ScheduledExecutorService它是一个接口,其完整路径为:java.util.concurrent.ScheduledExecutorService ,其类图如下:
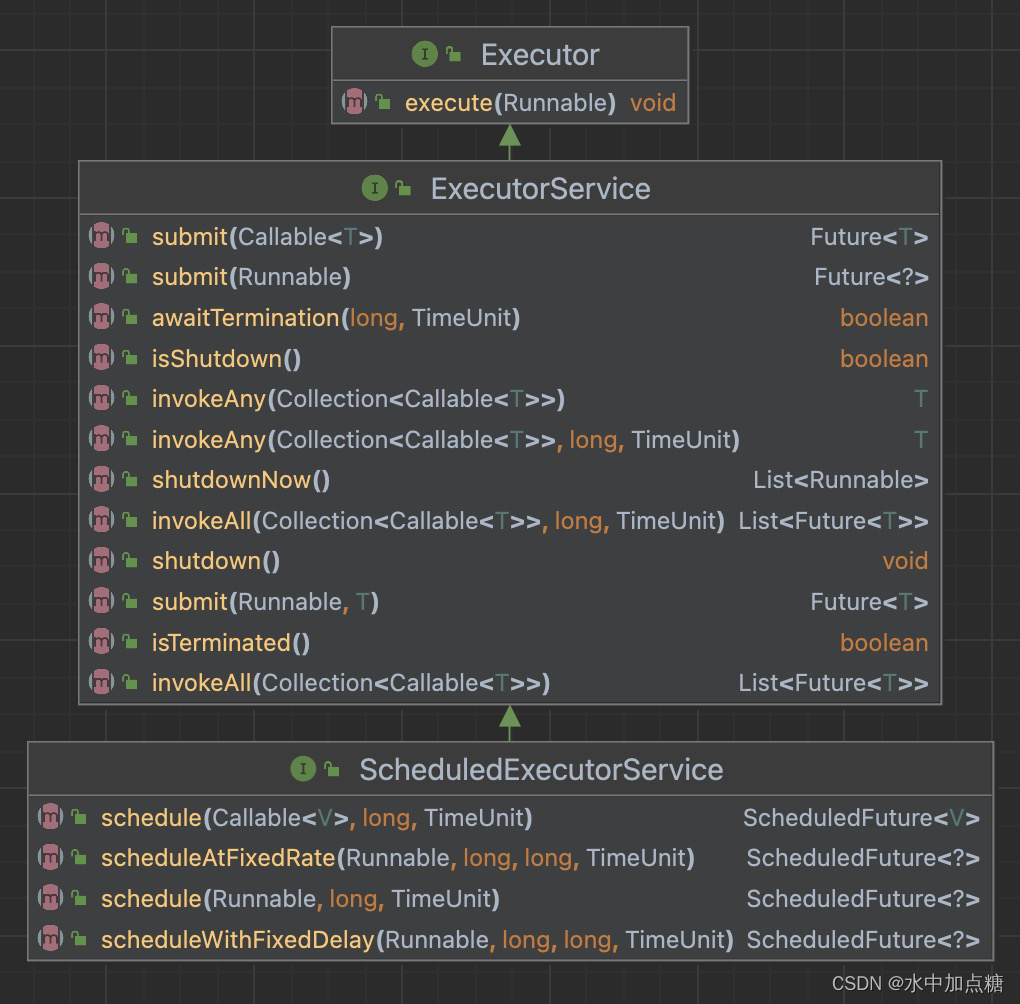
它提供了与Timer类似的方法,有:
public ScheduledFuture<?> schedule(Runnable command,long delay, TimeUnit unit);public <V> ScheduledFuture<V> schedule(Callable<V> callable,long delay, TimeUnit unit);public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit);public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay,TimeUnit unit);
在JDK中自带的ScheduledExecutorService实现类为ScheduledThreadPoolExecutor,其继承自ThreadPoolExecutor。
快速创建可使用JDK中的Executors生成一个ScheduledThreadPoolExecutor,如:
ScheduledExecutorService schService = Executors.newSingleThreadScheduledExecutor();
也或者手动指定ScheduledThreadPoolExecutor的构造参数创建,常用构造参数为:
public ScheduledThreadPoolExecutor(int corePoolSize,ThreadFactory threadFactory,RejectedExecutionHandler handler)
DelayedWorkQueue
以单参数corePoolSize为例,可以看到ScheduledThreadPoolExecutor的一个重要入参数为DelayedWorkQueue。
public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE,DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,new DelayedWorkQueue());}
与DelayQueue类似的,DelayedWorkQueue也是一个延迟队列,基于堆实现。它主要用于ScheduledThreadPoolExecutor中的任务调度管理。
JDK源码中对于DelayedWorkQueue介绍为:
/** A DelayedWorkQueue is based on a heap-based data structure* like those in DelayQueue and PriorityQueue, except that* every ScheduledFutureTask also records its index into the* heap array. This eliminates the need to find a task upon* cancellation, greatly speeding up removal (down from O(n)* to O(log n)), and reducing garbage retention that would* otherwise occur by waiting for the element to rise to top* before clearing. But because the queue may also hold* RunnableScheduledFutures that are not ScheduledFutureTasks,* we are not guaranteed to have such indices available, in* which case we fall back to linear search. (We expect that* most tasks will not be decorated, and that the faster cases* will be much more common.)** All heap operations must record index changes -- mainly* within siftUp and siftDown. Upon removal, a task's* heapIndex is set to -1. Note that ScheduledFutureTasks can* appear at most once in the queue (this need not be true for* other kinds of tasks or work queues), so are uniquely* identified by heapIndex.*/
关于DelayedWorkQueue中对堆的详细操作这里不再展开,与其他堆的操作类似的,都由siftUp(上推)和siftDown(下沉)构成,与DelayQueue不同的地方是DelayedWorkQueue中存储的每个节点会记录它在队列中的index。这样做的好处是在取消某个任务时可以快速定位到被取消的任务在堆中的位置,
每当有新的任务被提交到ScheduledThreadPoolExecutor时,最终都会被添加到此队列中。
private void delayedExecute(RunnableScheduledFuture<?> task) {if (isShutdown())reject(task);else {super.getQueue().add(task);if (!canRunInCurrentRunState(task) && remove(task))task.cancel(false);elseensurePrestart();}}
任务的调度由父类ThreadPoolExecutor中的Worker进行触发,每个Worker是一个单独的线程,在它的RunWorker方法中会一直尝试从workQueue中获取队列头部的Task进行执行。
final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true;try {while (task != null || (task = getTask()) != null) {w.lock();// If pool is stopping, ensure thread is interrupted;// if not, ensure thread is not interrupted. This// requires a recheck in second case to deal with// shutdownNow race while clearing interruptif ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {beforeExecute(wt, task);try {task.run();afterExecute(task, null);} catch (Throwable ex) {afterExecute(task, ex);throw ex;}} finally {task = null;w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}}
getTask方法为:
private Runnable getTask() {boolean timedOut = false; // Did the last poll() time out?for (;;) {int c = ctl.get();// Check if queue empty only if necessary.if (runStateAtLeast(c, SHUTDOWN)&& (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {decrementWorkerCount();return null;}int wc = workerCountOf(c);// Are workers subject to culling?boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;if ((wc > maximumPoolSize || (timed && timedOut))&& (wc > 1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c))return null;continue;}try {Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();if (r != null)return r;timedOut = true;} catch (InterruptedException retry) {timedOut = false;}}}
在ScheduledThreadPoolExecutor中的workQueue则为DelayedWorkQueue。
ScheduledThreadPoolExecutor与Timer相比,在性能和成熟度方面都对Timer进行了加强,如在单jvm场景中使用ScheduledThreadPoolExecutor来实现定时任务是一个不错的选择。
quartz调度机制
ScheduledThreadPoolExecutor基于线程池实现了许多Timer所没有的特性。
Timer和ScheduledThreadPoolExecutor自带的类,在很多方面它们仍然具有很多共同点,如:
- 任务均使用内存存储
- 不支持集群
- 任务的数据存储底层使用二叉堆结构
为了更适应复杂的业务场景,业界也先后诞生出了众多的定时任务框架,其中最为突出的是:至今仍被广泛应用的非quartz莫属。

其源码地址为:https://github.com/quartz-scheduler/quartz
quartz内容众多,本文仅对quartz中的trigger调度部分进行简单分析。
quartz中对于任务的存储默认也采用内存存储,实现类为RAMJobStore,除此之外也支持JDBCJobStore以将任务数据写入到数据库中。
在quartz中定义一个任务需要由Scheduler(调度器)、Job(任务)、Trigger(触发器)这3部分组成。
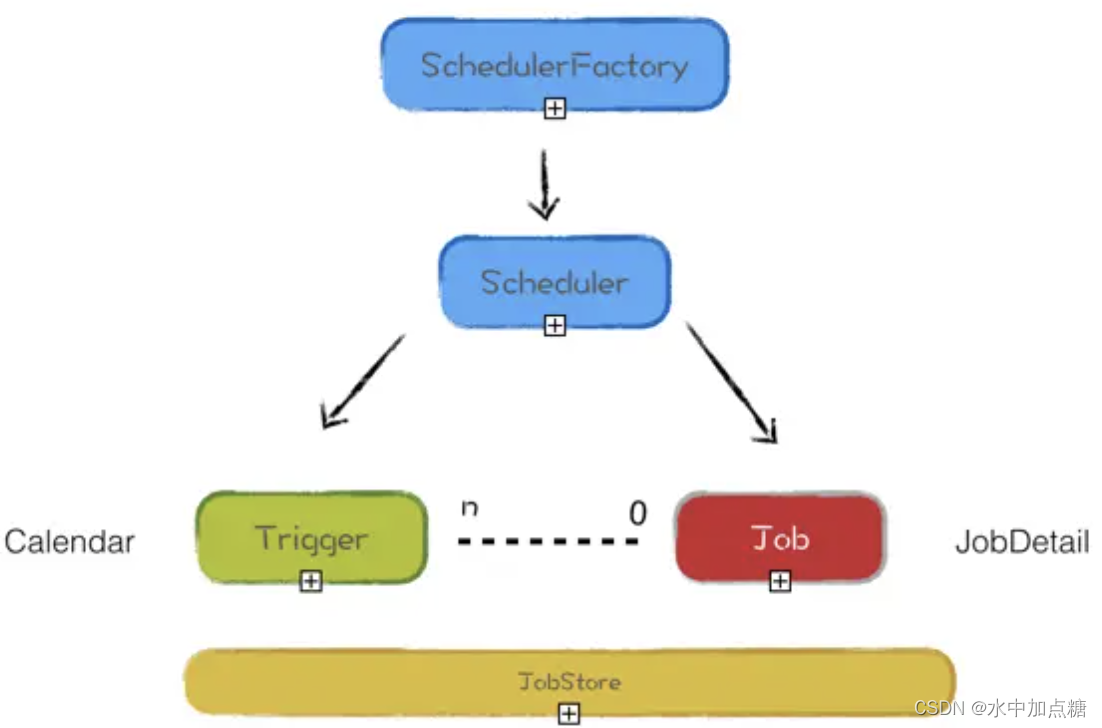
- Job为具体需要被执行的任务
- Trigger为任务所被期往执行的时间
- Scheduler为任务被执行的容器组
Trigger分两种:CronTrigger与SimpleTrigger,区别为CronTrigger支持以cron表达式定义任务的执行时间。
以quartz中的SimpleTrigger和RAMJobStore为例,当提交了一个job到quartz中,它最终会被存储到对应的store中。
被执行的方法为:org.quartz.core.QuartzScheduler#scheduleJob(org.quartz.JobDetail, org.quartz.Trigger)
public Date scheduleJob(JobDetail jobDetail,Trigger trigger) throws SchedulerException {validateState();……// 调用对应的jobStore保存此job和triggerresources.getJobStore().storeJobAndTrigger(jobDetail, trig);notifySchedulerListenersJobAdded(jobDetail);notifySchedulerThread(trigger.getNextFireTime().getTime());notifySchedulerListenersSchduled(trigger);return ft;
RAMJobStore被执行的方法为:org.quartz.simpl.RAMJobStore#storeTrigger
protected TreeSet<TriggerWrapper> timeTriggers = new TreeSet<TriggerWrapper>(new TriggerWrapperComparator());public void storeTrigger(OperableTrigger newTrigger,boolean replaceExisting) throws JobPersistenceException {TriggerWrapper tw = new TriggerWrapper((OperableTrigger)newTrigger.clone());synchronized (lock) {if (triggersByKey.get(tw.key) != null) {if (!replaceExisting) {throw new ObjectAlreadyExistsException(newTrigger);}//删除已有的重复triggerremoveTrigger(newTrigger.getKey(), false);}if (retrieveJob(newTrigger.getJobKey()) == null) {throw new JobPersistenceException("The job ("+ newTrigger.getJobKey()+ ") referenced by the trigger does not exist.");}// add to triggers by jobList<TriggerWrapper> jobList = triggersByJob.get(tw.jobKey);if(jobList == null) {jobList = new ArrayList<TriggerWrapper>(1);triggersByJob.put(tw.jobKey, jobList);}jobList.add(tw);// add to triggers by groupHashMap<TriggerKey, TriggerWrapper> grpMap = triggersByGroup.get(newTrigger.getKey().getGroup());if (grpMap == null) {grpMap = new HashMap<TriggerKey, TriggerWrapper>(100);triggersByGroup.put(newTrigger.getKey().getGroup(), grpMap);}grpMap.put(newTrigger.getKey(), tw);// add to triggers by FQN maptriggersByKey.put(tw.key, tw);if (pausedTriggerGroups.contains(newTrigger.getKey().getGroup())|| pausedJobGroups.contains(newTrigger.getJobKey().getGroup())) {tw.state = TriggerWrapper.STATE_PAUSED;if (blockedJobs.contains(tw.jobKey)) {tw.state = TriggerWrapper.STATE_PAUSED_BLOCKED;}} else if (blockedJobs.contains(tw.jobKey)) {tw.state = TriggerWrapper.STATE_BLOCKED;} else {// 将此TriggerWrapper添加到timerTriggers中timeTriggers.add(tw);}}
}
从源码中可以看出trigger最终会被添加到一个被TriggerWrapper修饰的TreeSet中,其比较器为TriggerWrapperComparator:
class TriggerTimeComparator implements Comparator<Trigger>, Serializable {private static final long serialVersionUID = -3904243490805975570L;// This static method exists for comparator in TC clustered quartzpublic static int compare(Date nextFireTime1, int priority1, TriggerKey key1, Date nextFireTime2, int priority2, TriggerKey key2) {//先比较下次执行时间if (nextFireTime1 != null || nextFireTime2 != null) {if (nextFireTime1 == null) {return 1;}if (nextFireTime2 == null) {return -1;}if(nextFireTime1.before(nextFireTime2)) {return -1;}if(nextFireTime1.after(nextFireTime2)) {return 1;}}// 执行时间相同时比较优先级int comp = priority2 - priority1;if (comp != 0) {return comp;}return key1.compareTo(key2);}public int compare(Trigger t1, Trigger t2) {return compare(t1.getNextFireTime(), t1.getPriority(), t1.getKey(), t2.getNextFireTime(), t2.getPriority(), t2.getKey());}}
当完成了Job的存储后,其触发代码位于QuartzSchedulerThread中run中。这个方法中代码较长,简单看一下:
public void run() {int acquiresFailed = 0;while (!halted.get()) {try {// check if we're supposed to pause...synchronized (sigLock) {// ……// wait a bit, if reading from job store is consistently// failing (e.g. DB is down or restarting)..// ……int availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();synchronized (sigLock) {if (halted.get()) {break;}}if(availThreadCount > 0) { // will always be true, due to semantics of blockForAvailableThreads...List<OperableTrigger> triggers;long now = System.currentTimeMillis();clearSignaledSchedulingChange();try {// 调用jobStore返回一批最先被执行的任务triggers = qsRsrcs.getJobStore().acquireNextTriggers(now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());acquiresFailed = 0;if (log.isDebugEnabled())log.debug("batch acquisition of " + (triggers == null ? 0 : triggers.size()) + " triggers");} catch (JobPersistenceException jpe) {// ……}if (triggers != null && !triggers.isEmpty()) {now = System.currentTimeMillis();long triggerTime = triggers.get(0).getNextFireTime().getTime();long timeUntilTrigger = triggerTime - now;// ……boolean goAhead = true;synchronized(sigLock) {goAhead = !halted.get();}if(goAhead) {try {// 标记为正在执行List<TriggerFiredResult> res = qsRsrcs.getJobStore().triggersFired(triggers);if(res != null)bndles = res;} catch (SchedulerException se) {// ……}}for (int i = 0; i < bndles.size(); i++) {TriggerFiredResult result = bndles.get(i);TriggerFiredBundle bndle = result.getTriggerFiredBundle();Exception exception = result.getException();……JobRunShell shell = null;try {// 创建job执行的RunShellshell = qsRsrcs.getJobRunShellFactory().createJobRunShell(bndle);shell.initialize(qs);} catch (SchedulerException se) {// 运行出错,标记为已完成,并标记为运行异常 qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);continue;}// 运行此JOBif (qsRsrcs.getThreadPool().runInThread(shell) == false) {// this case should never happen, as it is indicative of the// scheduler being shutdown or a bug in the thread pool or// a thread pool being used concurrently - which the docs// say not to do...getLog().error("ThreadPool.runInThread() return false!");qsRsrcs.getJobStore().triggeredJobComplete(triggers.get(i), bndle.getJobDetail(), CompletedExecutionInstruction.SET_ALL_JOB_TRIGGERS_ERROR);}}continue; // while (!halted)}} else { // if(availThreadCount > 0)// should never happen, if threadPool.blockForAvailableThreads() follows contractcontinue; // while (!halted)}// ……} catch(RuntimeException re) {getLog().error("Runtime error occurred in main trigger firing loop.", re);}} // while (!halted)// drop references to scheduler stuff to aid garbage collection...qs = null;qsRsrcs = null;
}
runInThread最终调用的类为org.quartz.simpl.SimpleThreadPool.WorkerThread中的run方法。
public void run() {boolean ran = false;while (run.get()) {try {synchronized(lock) {while (runnable == null && run.get()) {lock.wait(500);}if (runnable != null) {ran = true;// 调用JOB的runrunnable.run();}}} catch (InterruptedException unblock) {// ……}}
}
以上便是quartz中关于一个job存储和调度的具体代码。quartz细节过多且非常庞大这里仅看了下核心片段部分,总结一下:
- 在RAMJobStore中,任务在被添加时会被放入一个红黑树中,放入的顺序为先以最先执行时间判断,再以优先级判断。
- quartz中的任务调度会由schedule中的QuartzSchedulerThread持续从JobStore中取出job放入到worker线程中执行。
时间轮算法
通过前文的了解,从timer、ScheduledExecutorService到quartz,如仅从底层存储的数据结构进行划分,存放定时任务的数据结构有二叉堆、红黑树。
在二叉堆与红黑树中,新增一个节点时间复杂度均为:O(logn),当需要处理的定时任务较多时,则性能也会随之降低。
那么,是否存在一种算法即便面对数量众多的定时任务,调度的复杂度也能很低?
Timing Wheel Algorithm–时间轮算法,这便是接下来要回顾的内容。
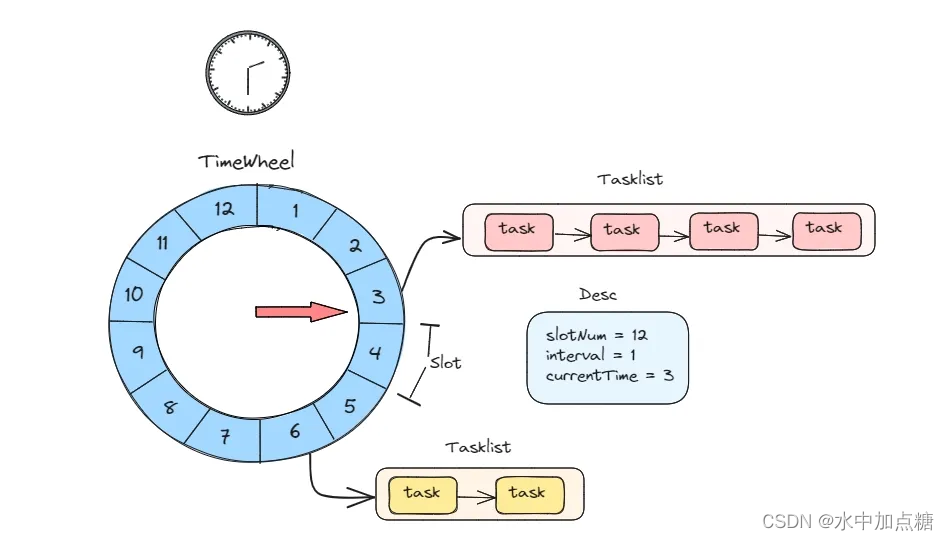
关于时间轮的介绍文章也非常多,简单理解:它是一个由时间槽和链表构成的数据结构。
每个时间槽中有一个数值,时钟每拨动一次,当前时间的指针也随之转动,时间槽中数值的单位决定了这个时间轮的精度。在定时任务场景中,每个时间槽内由一个存放了Task的链表组成,时钟指向某个时间槽时,则代表该槽内满足运行条件的task可以被运行。
在新的Task需要被新增时,根据当前时间槽定计算出新Task应该被放置的位置,并添加到该槽的链表中。这点与HashMap很类似,新增节点的时间复杂度近似O(1)。
多级时间轮
前面描述的时间轮是单轮时间轮。以上图单轮12格、每秒移动一格为例,能实现的最长周期为12秒,如想要实现一分钟内的倒计时周期则需要将时间槽调整为60格,更高精度则需要将轮子的周期继续扩充,以此类推。
尽管通过增加槽数可以实现更多粒度的控制,但它并不是一种好的解决方式,毕竟槽数的增加也会让空间占用同比上升,较长延迟的任务也无法实现。
为此,一种类似水表的时间轮便诞生了——多级时间轮。
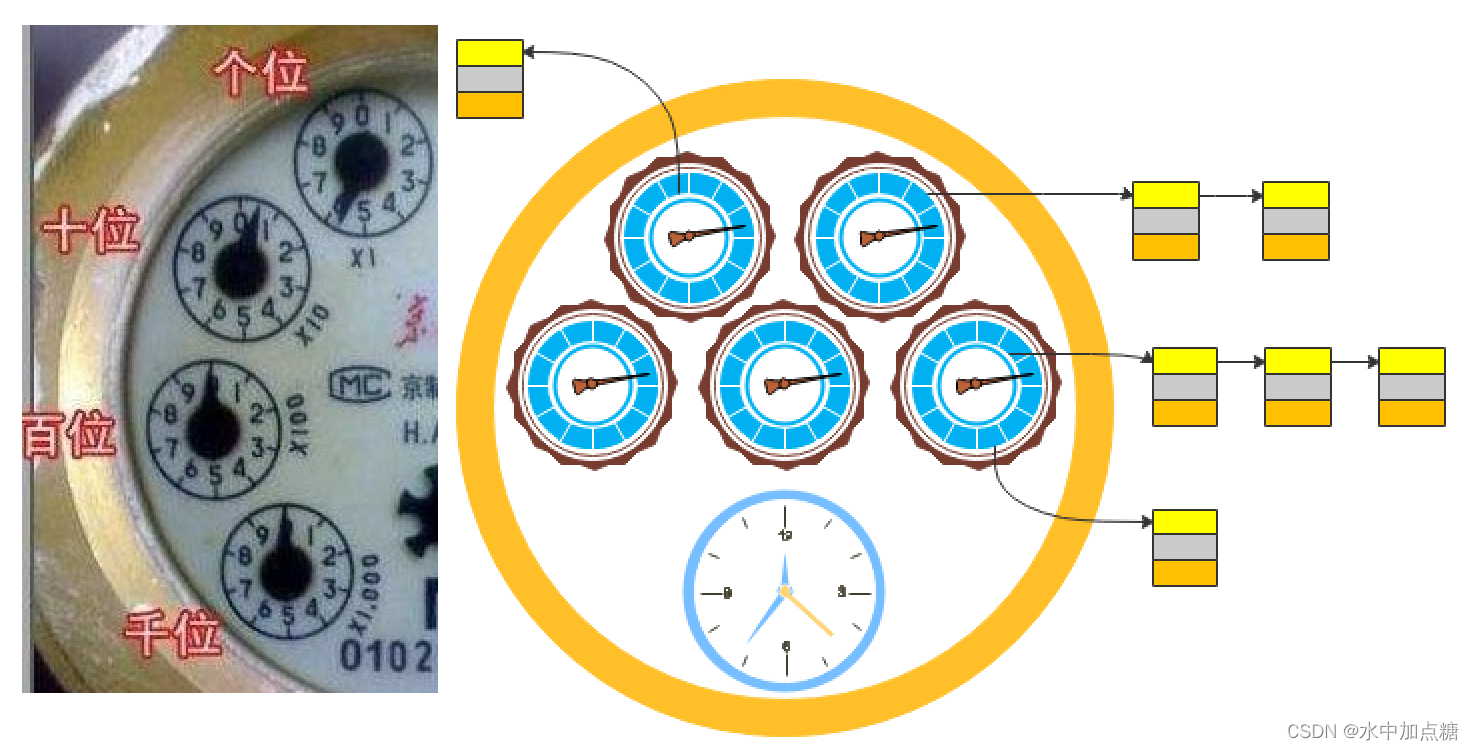
在多级时间轮中,用多个单时间轮构成一个整体上的逻辑时间轮,每个时间轮具有不同的刻度,刻度小的满一卷后更高一级刻度的轮子进一格,以此类推。
多层级时间轮
除了多级时间轮外,还有另一种类似的时间轮——多层时间轮。

工作机制与手表类似,最外层指针跑满一卷后内层指针前进一格,以此类推。
多层多级时间轮对比
与多级时间轮相比,多层时间轮实现所需的数据结构上仅需要一个大的单轮即可,可以节约更多的存储空间。
一般来讲,多层时间轮侧重于在单一时间轮内通过多层次结构(如链表)管理任务,提高时间槽内的任务调度效率,比较适合任务间隔较小且频繁的场景。
如果需要处理大跨度的任务,则更适合使用多级时间轮。
netty时间轮
上面对时间轮的理论知识进行了介绍,接下来看一下使用“多级时间轮”在netty框架中的实际应用。
HashedWheelTimer用法
HashedWheelTimer maintains a data structure called ‘wheel’. To put simply, a wheel is a hash table of TimerTasks whose hash function is ‘dead line of the task’.
HashedWheelTimer是netty中实现的时间轮,使用一个哈希表来存储每个task的信息。
在编程和计算机科学中,哈希函数是一种将任意长度的数据(如字符串或数字)映射到固定长度(如较小的整数)的算法。
以实现1秒后延迟输出信息为例,其代码为:
final HashedWheelTimer timer = new HashedWheelTimer();//延迟1秒执行任务timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws Exception {System.out.println("Task executed after 1 second delay");}}, 1, TimeUnit.SECONDS);
以实现每隔3秒输出信息为例,其代码为:
//每3秒输出当前时间
timer.newTimeout(new TimerTask() {@Overridepublic void run(Timeout timeout) throws Exception {System.out.println("now=" + System.currentTimeMillis());//再次提交,实现循环定时执行timer.newTimeout(this, 3, TimeUnit.SECONDS);}
}, 3, TimeUnit.SECONDS);
运行结果为: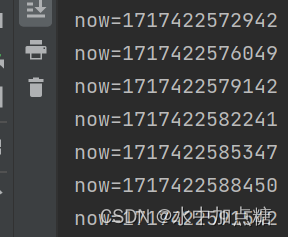
代码非常简短也很有效。
new一个HashedWheelTimer,并使用newTimeout传入所需要执行的TimerTask和延迟时间即可。
HashedWheelTimer类图总览
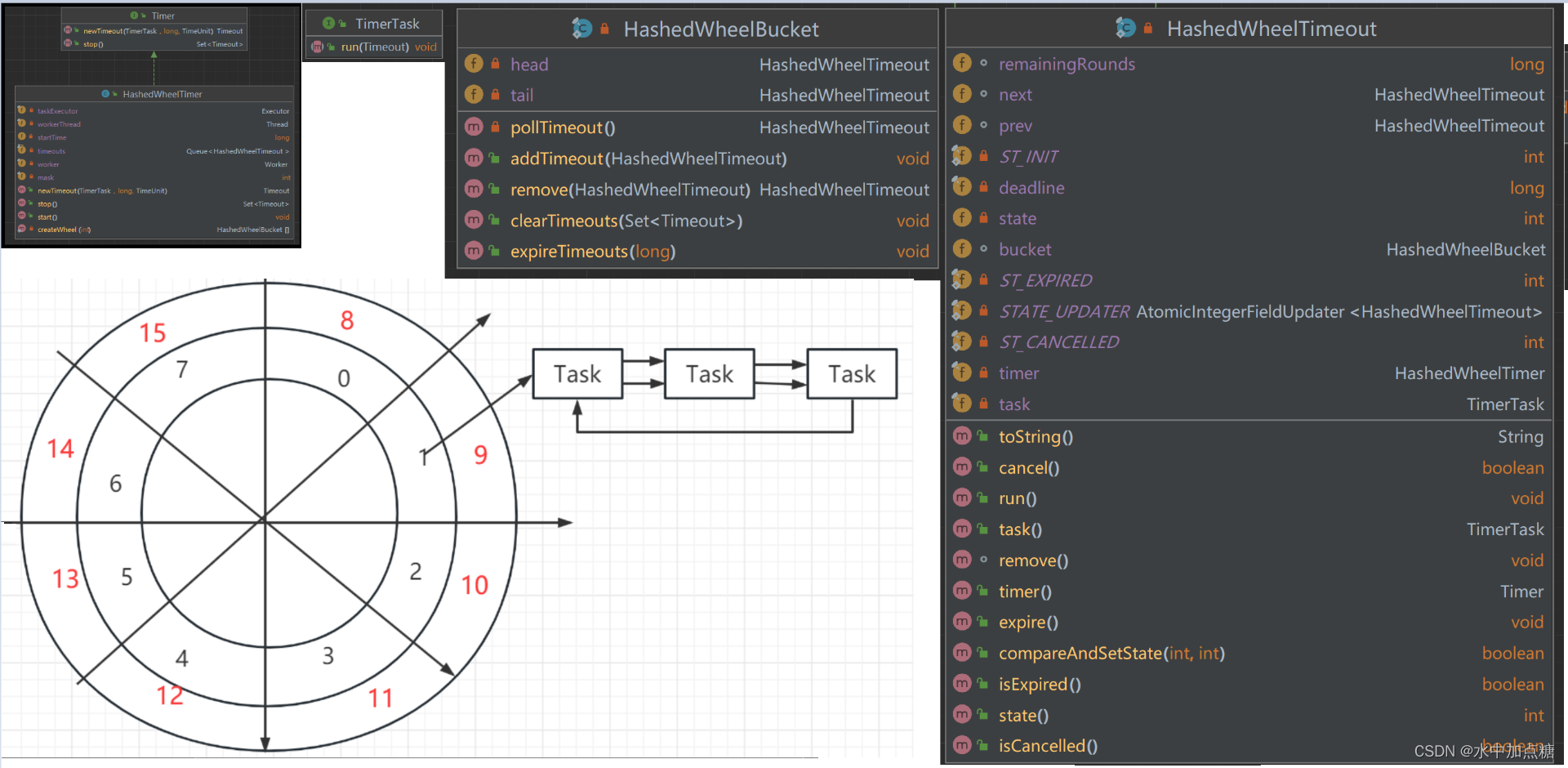
以上为HashedWheelTimer类结构总览图。需要关注的关键信息有:
HashedWheelTimer,时间轮:
- wheel,时间轮数组,由多个时间槽(HashedWheelBucket)构成,即一个wheel内有多个HashedWheelBucket
- taskExecutor,执行时间槽内任务的线程池
- workerThread,时间轮调度线程
- worker,在workerThread中执行的具体类,负责对时间轮和里面的任务进行调度
- timeouts,存放新提交任务的队列,实际入槽由worker执行时触发
- startTime,时间轮首次转动的时间,单位为纳秒
TimerTask,被提交到时间轮中的任务,有且仅有一个run方法,用于执行具体业务
HashedWheelTimeout,包装TimerTask的类:
- task,即具体执行任务的TimerTask
- next,邻居1号,同一个时间槽队列中的后一个HashedWheelTimeout
- prev,邻居2号,同一个时间槽队列中的前一个HashedWheelTimeout
- remainingRounds,剩余层数,0层时且时间槽匹配就会被执行
- deadline,task应该被执行的相对时间
- bucket,此HashedWheelTimeout所处的时间槽,位于哪个HashedWheelBucket内
- expire方法,提交本task任务到线程池
HashedWheelBucket,时间槽,管理HashedWheelTimeout的容器:
- head,HashedWheelTimeout队列的第一个
- tail,HashedWheelTimeout队列的最后一个
- expireTimeouts方法,时间指针指向该时间槽时,对该槽内的HashedWheelTimeout任务提交到线程池或层数减一
这里对HashedWheelTimer整体进行重点总览,在下文中将对HashedWheelTimer的详细实现进行介绍。
HashedWheelTimer构造方法
HashedWheelTimer提供了多个构造方法,一般用最简单的无参构造函数就行,所涉及到的源码如下:
public HashedWheelTimer() {this(Executors.defaultThreadFactory());}public HashedWheelTimer(ThreadFactory threadFactory) {// 精度为100毫秒,即0.1秒this(threadFactory, 100, TimeUnit.MILLISECONDS);}public HashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit) {// 指定512个时间槽,一圈51.2秒this(threadFactory, tickDuration, unit, 512);}public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel) {this(threadFactory, tickDuration, unit, ticksPerWheel, true);}public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection) {this(threadFactory, tickDuration, unit, ticksPerWheel, leakDetection, -1);}public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,long maxPendingTimeouts) {this(threadFactory, tickDuration, unit, ticksPerWheel, leakDetection,maxPendingTimeouts, ImmediateExecutor.INSTANCE);}public HashedWheelTimer(ThreadFactory threadFactory,long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,long maxPendingTimeouts, Executor taskExecutor) {checkNotNull(threadFactory, "threadFactory");checkNotNull(unit, "unit");checkPositive(tickDuration, "tickDuration");checkPositive(ticksPerWheel, "ticksPerWheel");this.taskExecutor = checkNotNull(taskExecutor, "taskExecutor");// Normalize ticksPerWheel to power of two and initialize the wheel.// 创建时间轮wheel = createWheel(ticksPerWheel);mask = wheel.length - 1;// Convert tickDuration to nanos.long duration = unit.toNanos(tickDuration);// Prevent overflow.if (duration >= Long.MAX_VALUE / wheel.length) {throw new IllegalArgumentException(String.format("tickDuration: %d (expected: 0 < tickDuration in nanos < %d",tickDuration, Long.MAX_VALUE / wheel.length));}if (duration < MILLISECOND_NANOS) {logger.warn("Configured tickDuration {} smaller than {}, using 1ms.",tickDuration, MILLISECOND_NANOS);this.tickDuration = MILLISECOND_NANOS;} else {this.tickDuration = duration;}workerThread = threadFactory.newThread(worker);leak = leakDetection || !workerThread.isDaemon() ? leakDetector.track(this) : null;this.maxPendingTimeouts = maxPendingTimeouts;if (INSTANCE_COUNTER.incrementAndGet() > INSTANCE_COUNT_LIMIT &&WARNED_TOO_MANY_INSTANCES.compareAndSet(false, true)) {reportTooManyInstances();}}private static HashedWheelBucket[] createWheel(int ticksPerWheel) {ticksPerWheel = MathUtil.findNextPositivePowerOfTwo(ticksPerWheel);// 给时间轮的槽赋值HashedWheelBucket[] wheel = new HashedWheelBucket[ticksPerWheel];for (int i = 0; i < wheel.length; i ++) {wheel[i] = new HashedWheelBucket();}return wheel;}
关键信息有:
- HashedWheelTimer默认的构造方法创建了1个包含有512个槽位的时间轮,每个槽位的时间间隔为0.1秒,即一个时间轮的最长周期为51.2秒
- 指定了运行提交任务的线程池为ImmediateExecutor.INSTANCE,即在当前调用的线程中执行任务
- 创建了一个worker线程,用于管理此时间轮中的所有任务
HashedWheelTimer调度原理
需要注意的是,HashedWheelTimer仅对时间轮进行了创建,并未对任务进行实际的调度。
一个HashedWheelTimer的实际调度,由首次调用newTimeout方法时触发,源码如下:
// 创建一个多【生产者】单【消费者】的队列,用来存放具体的Timeout任务private final Queue<HashedWheelTimeout> timeouts = PlatformDependent.newMpscQueue();public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {// ……// 确保work线程已启动,如未启动则启动start();// Add the timeout to the timeout queue which will be processed on the next tick.// During processing all the queued HashedWheelTimeouts will be added to the correct HashedWheelBucket.// 计算出此任务的deadline;此任务运行需等待时长=当前时间+延迟时间-轮子首次转动时间long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;// Guard against overflow.if (delay > 0 && deadline < 0) {deadline = Long.MAX_VALUE;}// 将当前task封装为HashedWheelTimeout,并添加到timeouts队列中HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);timeouts.add(timeout);return timeout;}public void start() {switch (WORKER_STATE_UPDATER.get(this)) {case WORKER_STATE_INIT:if (WORKER_STATE_UPDATER.compareAndSet(this, WORKER_STATE_INIT, WORKER_STATE_STARTED)) {// 如work线程未启动则进行启动,让轮子转起来workerThread.start();}break;case WORKER_STATE_STARTED:break;case WORKER_STATE_SHUTDOWN:throw new IllegalStateException("cannot be started once stopped");default:throw new Error("Invalid WorkerState");}// Wait until the startTime is initialized by the worker.while (startTime == 0) {try {startTimeInitialized.await();} catch (InterruptedException ignore) {// Ignore - it will be ready very soon.}}}
workerThread.start()则执行的是io.netty.util.HashedWheelTimer.Worker中的run方法。
它负责时间轮的持续转动及对任务的调度执行,源码如下:
public void run() {// 对startTime进行初始化,设置为轮子首次转动的时间戳startTime = System.nanoTime();// ……// Notify the other threads waiting for the initialization at start().startTimeInitialized.countDown();do {// 嘀嗒,sleep间隔时间并得到当前deadline,deadline=System.nanoTime()-startTimefinal long deadline = waitForNextTick();if (deadline > 0) {// 使用位运算得到当前idx,mask=wheel.length-1,wheel.length是2的N次幂,mask是全1的二进制数int idx = (int) (tick & mask);// 处理已被取消的任务processCancelledTasks();// 拿到当前指针指向的时间槽HashedWheelBucket bucket =wheel[idx];// 将刚提交的任务分配到时间槽上transferTimeoutsToBuckets();// 执行当前时间槽中满足条件的任务;槽数+层数均匹配就执行此taskbucket.expireTimeouts(deadline);tick++;}} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);// Fill the unprocessedTimeouts so we can return them from stop() method.for (HashedWheelBucket bucket: wheel) {bucket.clearTimeouts(unprocessedTimeouts);}for (;;) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {break;}if (!timeout.isCancelled()) {unprocessedTimeouts.add(timeout);}}processCancelledTasks();}
上面代码中会进行一个死循环让时间指针滴答滴答转动起来,每到达一个时间槽时会让新提交的task进行入槽。入槽流程代码如下:
private void transferTimeoutsToBuckets() {// transfer only max. 100000 timeouts per tick to prevent a thread to stale the workerThread when it just// adds new timeouts in a loop.for (int i = 0; i < 100000; i++) {HashedWheelTimeout timeout = timeouts.poll();if (timeout == null) {// all processedbreak;}if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {// Was cancelled in the meantime.continue;}// 需要等待的槽数=任务运行需等待时长/每个槽的间隔时长long calculated = timeout.deadline / tickDuration;// 需要等待的层数=(需要等待的槽数-已走过的槽数)/总槽数timeout.remainingRounds = (calculated - tick) / wheel.length;final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.// 此任务应运行的槽值int stopIndex = (int) (ticks & mask);// 拿到时间槽,并放到该槽的末尾HashedWheelBucket bucket = wheel[stopIndex];bucket.addTimeout(timeout);}
}
waitForNextTick为时间指针等待的间隔方法,代码如下:
private long waitForNextTick() {// 计算出指向下一个时间槽的相对时间long deadline = tickDuration * (tick + 1);for (;;) {// 得到此时间轮的当前时间final long currentTime = System.nanoTime() - startTime;// 计算出还应该等待的时长,理论时间-时间时间则为应等待的时间。此处+999999/1000000的目的是为了向上取整long sleepTimeMs = (deadline - currentTime + 999999) / 1000000;if (sleepTimeMs <= 0) {// 不需要等待了,则直接返回当前时间if (currentTime == Long.MIN_VALUE) {return -Long.MAX_VALUE;} else {return currentTime;}}// Check if we run on windows, as if thats the case we will need// to round the sleepTime as workaround for a bug that only affect// the JVM if it runs on windows.//// See https://github.com/netty/netty/issues/356if (PlatformDependent.isWindows()) {sleepTimeMs = sleepTimeMs / 10 * 10;if (sleepTimeMs == 0) {sleepTimeMs = 1;}}try {// 等待一下,时间到了再指向下一个时间槽Thread.sleep(sleepTimeMs);} catch (InterruptedException ignored) {if (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_SHUTDOWN) {return Long.MIN_VALUE;}}}
}
在worker中指向某个时间槽时,会将该槽内的所有任务过一便,该执行的就执行,该取消的取消,该减层数的减层数。expireTimeouts是HashedWheelBucket的方法,代码如下:
public void expireTimeouts(long deadline) {// 从该时间槽内的链表头部开始HashedWheelTimeout timeout = head;// process all timeoutswhile (timeout != null) {// 迭代链表中的每个task节点HashedWheelTimeout next = timeout.next;if (timeout.remainingRounds <= 0) {// 此task位于最外层,则将其从队列中移除next = remove(timeout);if (timeout.deadline <= deadline) {// task应该执行时间位于当前时间前,调用expire方法运行此tasktimeout.expire();} else {// The timeout was placed into a wrong slot. This should never happen.throw new IllegalStateException(String.format("timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));}} else if (timeout.isCancelled()) {//此task已被取消,从链表中移除next = remove(timeout);} else {//让内层的task向外移动一层,距离触发又近了一圈timeout.remainingRounds --;}// 链表迭代timeout = next;}
}public void expire() {// expire代表此task已经可以被执行了if (!compareAndSetState(ST_INIT, ST_EXPIRED)) {return;}try {// 将此task提交线程池中执行timer.taskExecutor.execute(this);} catch (Throwable t) {if (logger.isWarnEnabled()) {logger.warn("An exception was thrown while submit " + TimerTask.class.getSimpleName()+ " for execution.", t);}}
}
最后想说
“程序=算法+数据结构。”
不同的算法与数据结构有着它独特的美,在实际业务运用时也需要从具体的业务出发进行多维度分析,选择一个底层实现最适合的框架,以让您的业务场景运行起来速度又快占用空间又少,岂不美哉。