其他信息: 尝试读取或写入受保护的内存。这通常指示其他内存已损坏。_KeyDB: 基于多线程模型且Redis API兼容的内存数据库...
什么是KeyDB?
KeyDB是基于内存中的高性能数据库,支持多种数据类型,磁盘持久性和高可用性。与Redis™API和协议兼容,KeyDB是现有Redis™部署的直接替代品,具有许多增强功能,更高的性能和更低的总拥有成本(TCO)。

KeyDB专为既用作缓存又用作主数据库而设计,是一种快速且通用的NoSQL数据库,可在许多应用程序中使用。它的低资源需求和高速意味着更少的实例管理和更低的成本。KeyDB希望充分利用为实例提供的硬件,以实现更高的吞吐量和效率。
为什么选择KeyDB?
KeyDB是一个完全开源的数据库,旨在利用所有硬件资源。KeyDB使得突破通常由价格和复杂性决定的界限成为可能。
- 100%与Redis协议,API和模块兼容
- 无需复杂的分片和集群
- 将您的资源加倍,将副本变成主副本,同时保持高可用性
- 不限于小数据大小或受昂贵的RAM约束
- 通过简单的设置即可实现闪电般的快速速度
- 成为您的意见得到倾听和重视的社区的一部分
为什么分叉Redis?
对于代码库的发展方式,KeyDB有不同的理念。作者认为易用性,高性能和“动力内聚”方法是创造良好用户体验的最佳方法。尽管非常尊重Redis的开发与维护者,但开发者们认为Redis方法过于注重代码的简单性,而以用户的复杂性为代价。这导致需要外部组件和解决方法来解决常见问题,从而导致总体上更加复杂。
由于存在意见分歧,因此适合KeyDB的功能可能不适用于Redis。分支允许探索这一新的开发路径并实现可能永远不会成为Redis一部分的功能。KeyDB与上游Redis更改保持同步,在适用的情况下,我们还提供上游错误修复和更改。我们希望这两个项目能够继续发展并相互学习。
KeyDB有何不同?
1.降低运营成本
KeyDB使用独特的多层数据结构在内存和非易失性内存(NVM)(例如闪存)之间共享信息。与将数据保留在昂贵的RAM中的其他仅内存数据库不同,KeyDB可以将不常使用的数据卸载到较便宜的存储介质上。
过去使用FLASH合并快速内存数据库的尝试只是用固定在单独的基于磁盘的数据库上。此方法需要两次查询才能访问基于磁盘的数据,并防止将密钥存储在非易失性存储器中。结果,不能充分利用非易失性存储器。这种方法的最终结果是更高的资源消耗,更高的延迟和更低的吞吐量。
相反,KeyDB是完全集成的双层数据库。KeyDB不会执行其他操作来访问基于闪存的数据,并且仅受基础硬件的吞吐量限制。结果,KeyDB能够通过廉价的非易失性存储器获得接近RAM的性能。
2.有效利用系统资源
KeyDB包含比Redis更好的内存和性能。与相同的硬件上的Redis™相比,KeyDB节省的内存最多比Redis™少75%,并且支持的吞吐量比Redis™高10%。性能增强和分层存储的有效利用的独特结合旨在提高性能,同时降低成本。
3.云设计原则
从一开始,KeyDB的设计就考虑了云。KeyDB旨在利用廉价的临时存储优势,与使用IOP配置的EBS存储的传统数据库相比,可显着降低成本。KeyDB能够将数据直接备份到Amazon S3™,以确保最低的成本。
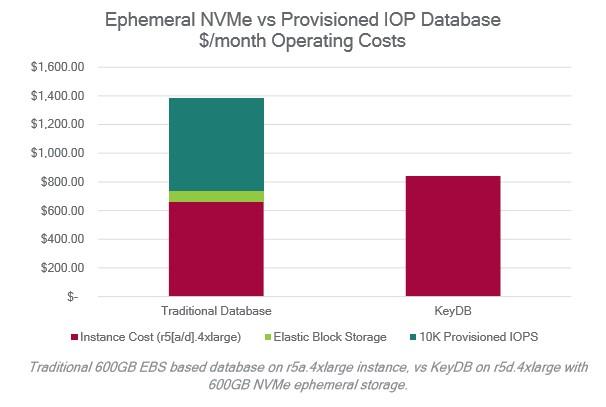
KeyDB独特的云优化架构可将成本降低40%以上。
4.使用冗余实例
维持高可用性设置的一大弊端是启动副本实例,这对于处理增加的负载可能无济于事。即使花费时间来设置接受读取的副本,处理流量和负载的能力也不一定会加倍。Active Replication和Multi-Master配置允许副本实例作为合并的强制接受每个实例的读取和写入。此操作基于最后写入胜出原则。
KeyDB可以处理分裂大脑的情况,其中主机之间的连接被切断,但写操作仍在继续。每个写入都带有时间戳,当连接恢复时,每个主机将共享其新数据。最新的写作将获胜。这样可以防止过时的数据覆盖断开连接后写入的新数据。
Active-Replica是实例的单个副本节点,其中两个节点都设置为彼此的副本。多主机配置类似,但是可以进行多种设置。每个主机可以是几个实例的主机,也可以是所有其他允许不同拓扑的实例。带有时间戳的写操作可以使发生故障的节点自动重启,并在返回时同步到最新值。
在启动时,每个KeyDB实例将计算一个动态UUID。此UUID不会保存,仅在整个过程中都存在。当副本连接到其主数据库时,它将通知主数据库其UUID,而主数据库将使用其自己的答复。比较两个UUID,以通知服务器两个客户端是否来自同一个KeyDB实例(IP和端口不足,因为同一台计算机上可能存在不同的进程)。如果UUID也是我们的副本,则用于防止将更改更改广播到发送给它们的主机。添加了新的配置选项以启用此模式,并且启用后,即使它是副本,KeyDB也可写(默认情况下,它是禁用的)。除了用于防止循环中客户端之间无限跳动查询的额外逻辑外,复制代码通常会执行。
5. 基准数据
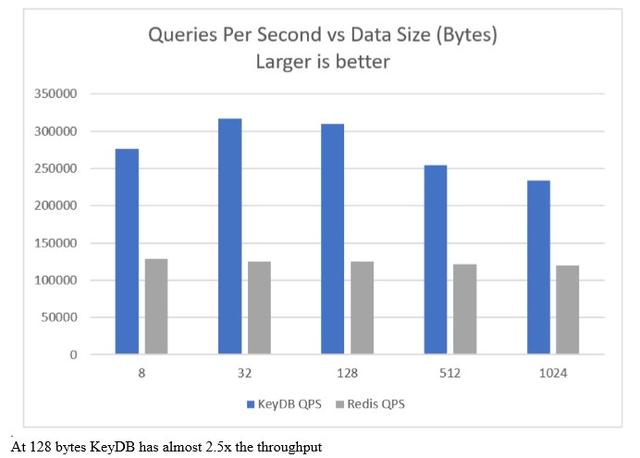
第一张图表显示,添加多线程支持后,吞吐量增加了一倍以上。但是,Redis™不仅用于需要吞吐量的地方,而且还用于对延迟高度敏感的应用程序中。我们也在那里取得了不错的成绩:
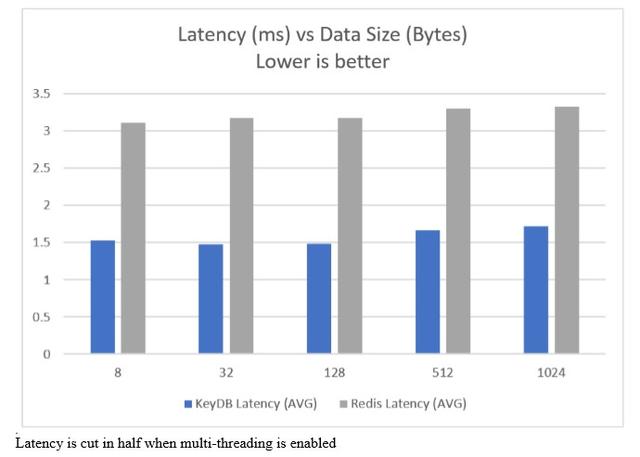
出于基准测试的目的,我们在AWS上使用了两个m5a.2xlarge实例。一个运行服务器,另一个运行我们的基准测试工具。我们决定将Memtier作为其产生更高流量的能力的基准工具。KeyDB使用4个线程运行,而memtier设置为使用8个线程进行所有测试。使用专用IP,所有流量都在同一AWS可用区中。
KeyDB 进一步介绍
KeyDB是一种开放源代码的内存中 数据结构存储,用作数据库,缓存和消息代理。它支持数据结构,例如字符串,哈希,列表,集合,带范围查询的排序集,位图),超日志,带有半径查询和流的地理空间索引。KeyDB具有内置的复制,Lua脚本,LRU收回,事务和不同级别的磁盘持久性,并通过Active-Replication或Sentinel以及通过KeyDB Cluster的自动分区提供了高可用性。
您可以 在这些类型上运行 原子操作,例如追加到字符串。在哈希中增加值;将元素推送到列表;计算集的交集,并集和差;或在排序集中获得排名最高的成员。
为了获得出色的性能,KeyDB使用 内存数据集。根据您的用例,您可以通过将数据集 偶尔转储到磁盘上,或者通过 将每个命令附加到log来持久化它 。如果只需要功能丰富的网络内存缓存,则可以选择禁用持久性。
KeyDB还支持琐碎的设置主从异步复制,具有非常快速的非阻塞式第一次同步,通过网络拆分实现部分重新同步的自动重新连接。
其他功能包括:
- 交易次数
- 发布/订阅
- Lua脚本
- 生存时间有限的键
- LRU收回钥匙
- 自动故障转移
用户可以从大多数编程语言中使用KeyDB。
KeyDB是用ANSI C编写的, 并且可以在大多数POSIX系统中使用,例如Linux,* BSD,OS X,而无需外部依赖。Linux和OS X是开发KeyDB并进行了更多测试的两个操作系统,我们 建议使用Linux进行部署。KeyDB可以在基于Solaris的系统中使用,例如SmartOS,但是尽力提供了支持 。Windows版本没有官方支持,但是Microsoft开发并维护了KeyDB的Win-64端口。
其他资源
- Try our docker container: https://hub.docker.com/r/eqalpha/keydb
- Talk on Gitter: https://gitter.im/KeyDB
- Visit our Website: https://keydb.dev
- See options for channel partners and support contracts: https://keydb.dev/support.html
- Learn with KeyDB’s official documentation site: https://docs.keydb.dev
【备注:本文参考了KeyDB官网、白发书及其Github内容整理而成】