初识C++ · 模拟实现list
目录
前言
1 push_back pop_back
2 迭代器类
2.1 == !=
2.2 ++ --
2.3 *
3 Print_List
4 有关自定义类型
5 有关const迭代器
6 拷贝构造 赋值 析构 Insert erase
前言
有了string,vector的基础,我们模拟实现list还是比较容易的,这里同样,先看源码进行简单的分析,这里直接说了就,list的模拟实现难就难在于,需要三个自定义类型,所以我们的重难点就是如何捋清它们三个之间的关系:




一共三个自定义类型,分别是用来控制节点的,控制迭代器的,控制链表的,那么为什么会这么复杂呢?尤其是在迭代器部分的模板有三个参数。
对于vector来说,空间是连续的,所以我们想要访问它的内容是很容易的,在vector和string中的迭代器可以理解为指针,指针++,就可以找到下一个空间,但是链表不同,链表的空间不是连续的,所以内置类型指针的++满足不了访问下一个空间的目的,那么为了能操纵迭代器的行为,我们这里就需要一个自定义类型,来让迭代器按照我们的想法去移动。
在list类中,我们看到只有一个成员变量,即node,那么随着typedef看过去,就知道link_type是控制节点的类的指针类型。
迭代器具体等会再细说,现在大体模式了解了,就开始进入吧。
1 push_back pop_back
文档里面说list是双向带头循环链表,所以我们需要一个哨兵位,也需要两个指针,所以,我们先创建一个节点类,节点类的模板也是必要的,因为节点里面不可能存的只有一种类型,除此之外还有调用对应的构造函数,因为是带头循环,所以创建好一个节点之后需要让它自己指向自己,这是构造函数的写法:
template <class T>
struct ListNode
{ListNode<T>* _next;ListNode<T>* _prev;T _data;ListNode(const T& val = T()):_next(nullptr),_prev(nullptr),_data(val){}
};对此代码稍微有点陌生的是ListNode<T>*的写法,其实就是该节点类型的指针,便于指向下一块空间而已,对于构造函数的参数是和vector的resize很像的,给一个缺省值方便初始化,T()的写法也不陌生了吧。
节点类里面存在的是指针域和数值域,其余的也没有什么要特殊注意的。
节点类我们就创建好了,那么就该创建一个list类了:
template<class T>
class list
{
public:typedef ListNode<T> Node;private:Node* _head;size_t _size;
};对于计数问题我们可以遍历的时候单独创建一个变量,也可以在类里面直接创建一个变量,insert的时候++,erase的时候--,两种方式任选其一都是没问题的。
这里的所以typedef最好都放在限定符的后面,有时候是会报错的,比如找不到什么的,为了方便,这里就把ListNode<T>重命名了Node。
那么,现在就满足了实现push_back的基本条件,push_back实现本身是没啥问题的,在数据结构中就提到了连接的问题,这里就直接连接了:
void push_back(const T& val)
{Node* newnode = new Node(val);newnode->_next = _head;newnode->_prev = _head->_prev;_head->_prev->_next = newnode;//下两个的顺序不能变_head->_prev = newnode;_size++;
}这里的连接推荐的是先连接newnode,防止动其他节点的时候被修改了,比如_head->_prev要后连接,不然就会变成了newnode->_prev = newnode,就会出问题了。
尾删的操作也是很简单的,但是链表为空的时候不能删除,所以我们需要一个判断链表是否为空的函数:
bool empty_list()
{return _head->_next != _head;
}当然,链表为空的时候_size是为0的,所以判断为空的条件有两个,我们选取任意一个都可以的。
void pop_back()
{assert(empty_list());Node* tail = _head->_prev;Node* new_tail = tail->_prev;new_tail->_next = _head;_head->_prev = new_tail;_size--;
}那么现在我们就可以对数据进行添加和删除了,现在的情况就是,如何打印数据呢?前言提及,对于链表的迭代器不是像普通迭代器一样那么简单,所以我们这里,需要创建一个迭代器类。
2 迭代器类
对于迭代器里面,我们要搞懂一个问题就是,这个类的用处是什么?成员变量有哪些?成员函数有什么?
对于第一个问题,不用多说,是用来遍历链表的,那么第二个问题,成员变量有什么?
我们要遍历一个链表,无非就是要下一个位置的地址,在一个节点类里面,我们有前后两个节点的地址,所以我们要遍历一个链表,就需要一个当前节点,有一个节点就够了,所以:
template <class T>
struct ListIterator
{typedef ListNode<T> Node;typedef ListIterator iterator;Node* _node;ListIterator(Node* node):_node(node){}};因为节点和迭代器我们是要访问全部成员的,所以使用了结构体,在源码里面也是这样操作的。
按照上文的理解,我们只需要一个节点,所以成员变量只有一个Node* _node,这里也要用到重命名,因为类域不一样,所以我们不能接着用list中使用的typedef,这里创建好之后,我们应该进入下一个问题,成员函数有什么?
这个问题的答案来源于,我们使用迭代器需要干什么?遍历打印的时候,我们需要判断该节点是不是尾节点,需要解引用该节点,得到里面的数值,需要迭代器++到下一个空间,也可能需要--到上一个空间,当节点里面存的是自定义类型,更麻烦,我们还需要对->进行重载,这个先不管,先一个一个函数的重载。
2.1 == !=
判断节点是否相等的唯一条件是,地址是否相等:
bool operator!=(const iterator& it)
{return _node != it._node;
}bool operator==(const iterator& it)
{return _node == it._node;
}2.2 ++ --
为了重载更完美,重载前置和后置:
iterator operator++(int)
{Self tmp(*this);_node = _node->_next;return tmp;
}
iterator& operator++()
{_node = _node->_next;return *this;
}iterator& operator--()
{_node = _node->_prev;return *this;
}iterator operator--(int)
{Self tmp(*this);_node = _node->_prev;return tmp;
}返回值是引用可以减少拷贝,但是返回的是临时对象,就不能返回引用了,这个在string里面提及过,也没有什么要特别注意的。
2.3 *
T& operator*()
{return _node->_data;
}就,so easy。
返回引用是因为遍历的时候涉及到修改,所以需要引用类型。
那么,80%的迭代器已经完成了。
3 Print_List
想要实现打印,我们的三件套,范围for,迭代器,下标访问,就失效了一个,list里面不存在下标访问。现在需要的是begin和end函数,返回的是头结点和尾结点的地址,为了和源码保持一致,这里还要实现一个const版本的,但是没什么难度:
iterator begin()
{return _head->_next;
}
iterator end()
{return _head;
}const_iterator begin() const
{return _head->_next;
}
const_iterator end() const
{return _head->_prev;
}end节点就是哨兵位节点,即_head,现在打印的基本条件我们都满足了,那就试试吧:
template<class T>
void Print_List(list<T>& ll)
{list<int>::iterator it1 = ll.begin();while(it1 != ll.end()){cout << *it1 << " ";it1++;}cout << endl;
}不管是用范围for也好还是迭代器,本质都是用迭代器,这里就使用迭代器就完事了。
模板也是必不可少的,因为是在类外实现的,所以我们需要类域访问限定符,这里用到的* ++ != 等操作我们都实现了,就可以完美实现打印。
测试代码:
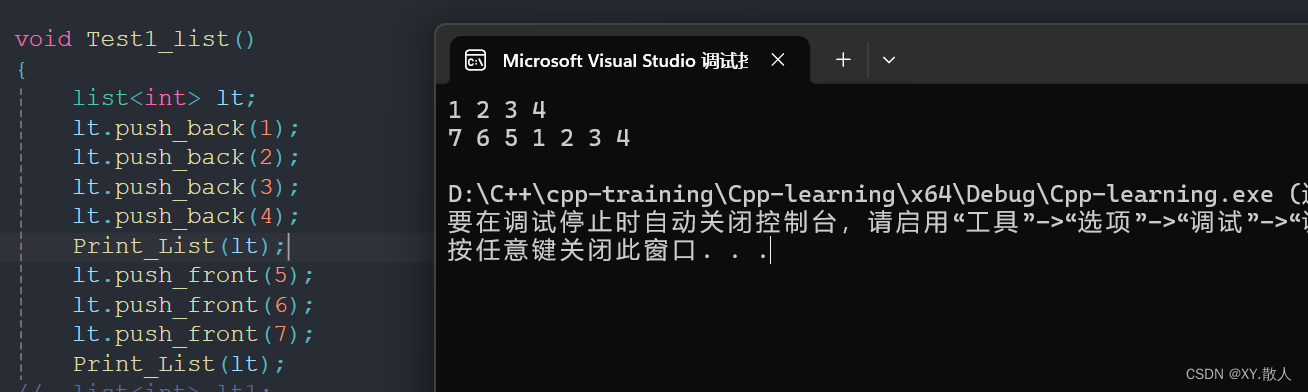
void Test1_list()
{list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);Print_List(lt);lt.push_front(5);lt.push_front(6);lt.push_front(7);Print_List(lt);
}
4 有关自定义类型
如果,我是说如果:
struct A
{int _a1;int _a2;A(int a1 = 1,int a2 = 2):_a1(a1),_a2(a2){}
};
链表存了一个这个,我们应该如何打印呢?相信这算得上一个难度,我们先抛开这个问题,先看如如何在链表里面存进这种类型的数据:
void Test2_list()
{list<A> lt;A aa1(1, 2);//构造A aa2 = { 1,2};//隐式类型转换lt.push_back(aa1);//有名对象lt.push_back(A(2,1));//匿名对象lt.push_back({1,2});//隐式类型转换lt.push_back({9,9});
}这和在vector里面存入一个string是一样的,有名对象和匿名对象,这个过一下就好了,我们回想C语言的一段代码:
void test_list2()
{A* ptr = &aa1;(*ptr)._a1;ptr->_a1;
}对于一个指针,想要访问成员,需要用到->,那么我们也可以对指针进行解引用,得到该结构体,再使用.操作符进行访问,所以->实际上的操作可以理解为解引用之后再使用.操作符,那么要变身了:
T* operator->()
{return &_node->_data;
}while (it != lt.end())
{cout << it->_a1 << ":" << it->_a2 << " ";cout << it.operator->()->_a1 << ":" << it.operator->()->_a2 << " ";cout << (*it)._a1 << ":" << (*it)._a2 << " ";it++;
}得到了指针,就能打印,所以重载->的返回值是指针,那么为什么,打印的时候可以直接it->_a1,对于it来说,它是一个迭代器类的指针,它的成员变量是没有_a1的,这就不得不说我们的编译器了,编译器实际上,是优化了一下,真正的代码是it.operator->()->_a1,先调用了->函数,然后返回的数据类型的指针,再次调用->,这次调用的就不是函数了,是->这个操作符,这才得以打印,所以,,优化容易让人有点看不懂。
5 有关const迭代器
对于const迭代器来说,我们有一个简单粗暴的解决办法,就是重新创建一个类,原来的迭代器是ListIterator,const迭代器就叫ListConstIterator就好了:
template <class T>
struct ListConstIterator
{typedef ListNode<T> Node;typedef ListConstIterator<T> Self;Node* _node;ListConstIterator(Node* node):_node(node){}const T& operator*(){return _node->_data;}const T* operator->(){return &_node->_data;}//返回的是迭代器Self operator++(int){Self tmp(*this);//Self tmp = _node; //错辣_node = _node->_next;return tmp;}Self& operator++(){_node = _node->next;return *this;}Self& operator--(){_node = _node->_prev;return *this;}Self operator--(int){Self tmp(*this);_node = _node->_prev;return tmp;}//迭代器里面是node 比较就是地址比较bool operator!=(const Self& it){return _node != it._node;}bool operator==(const Self& it){return _node == it._node;}
};实际上我们只改动了两个地方,一个是*一个是->的返回值,无非是T*变成了const T*,加一个const而已。
但是仅仅是为了这两个地方,单独引入一个类太不划算了,所以这里,再次用到了模板:
template <class T,class Ref,class Ptr>
struct ListIterator
{typedef ListNode<T> Node;typedef ListIterator<T,Ref,Ptr> Self;Node* _node;ListIterator(Node* node):_node(node){}//T& operator*()Ref operator*(){return _node->_data;}//T* operator->()Ptr operator->(){return &_node->_data;}
};无非就是返回的指针和地址而已,那么根据参数的不同,我们返回的类型不同就ok了:
template<class T>
class list
{
public:typedef ListNode<T> Node;typedef ListIterator<T,T&,T*> iterator;typedef ListIterator<T,const T&,const T*> const_iterator;iterator begin(){return _head->_next;}iterator end()//end节点就是哨兵位{return _head;}const_iterator begin() const{return _head->_next;}const_iterator end() const{return _head->_prev;}
}然后再再再重命名一下,就大功告成了。
测试代码:
void PrintList(const list<int>& lt){list<int>::const_iterator it = lt.begin();while (it != lt.end()) {//*it += 10;cout << *it << ' ';it++;}cout << endl;}6 拷贝构造 赋值 析构 Insert erase
剩下的就是收尾工作了。
insert和erase的基本没什么要注意的,已经在数据结构里面实现过了,这里直接给上代码了:
void Insert(iterator pos,const T& val)
{Node* cur = pos._node;Node* prev = cur->_prev;Node* newnode = new Node(val);newnode->_next = cur;newnode->_prev = prev;cur->_prev = newnode;prev->_next = newnode; _size++;
}iterator erase(iterator pos)
{Node* cur = pos._node;Node* prev = cur->_prev;Node* next = cur->_next;prev->_next = next;next->_prev = prev;delete cur;_size--;return iterator(next);
}因为预防迭代器失效的问题,erase的返回值要给iterator,其他的就是正常的连接了。
实现了之后push_back和pop_back也可以复用了:
void push_back(const T& val)
{Insert(end(), val);
}void pop_back()
{erase(end()--);
}对于拷贝构造来说,参数是引用,我们的实现方式是开一个头结点,然后为尾插,使用的是const版本的迭代器:
list(const list<T>& lt)
{empty_init();for (auto& e : lt){push_back(e);}
}这里的empty_init就是list的构造函数:
void empty_init()
{_head = new Node;_head->_next = _head;_head->_prev = _head;_size = 0;
}
list()
{empty_init();
}源码是这么写的,我觉得是因为不能显式的调用析构,所以需要给创造头结点的函数给单独拉出来,按照源码咯就。
对于赋值来说,使用现代写法就可以:
list<T>& operator=(list<T> lt)
{swap(lt);return *this;
}void swap(list<T>& lt)
{std::swap(_head, lt._head);std::swap(_size, lt._size);
}对于析构,析构即释放每个空间,实际上就是把每个节点都删除了就好,所以这里来个clear函数,专门用来删除节点:
void clear()
{iterator it = begin();while (it != end()){it = erase(it);}
}~list()
{clear();delete _head;_head = nullptr;
}析构函数就完美实现了。
那么list的实现,就到此为止了。
感谢阅读!