大模型:分本分割模型
目录
一、文本分割
二、BERT文本分割模型
三、部署模型
3.1 下载模型
3.2 安装依赖
3.3 部署模型
3.4 运行服务
四、测试模型
一、文本分割
文本分割是自然语言处理中的一项基础任务,目标是将连续的文本切分成有意义的片段,这些片段可以是句子、短语或是结构性元素如段落。文本分割对于后续的文本分析、信息提取、机器翻译、情感分析等多种NLP应用至关重要。
二、BERT文本分割模型
BERT文本分割-中文-通用领域(nlp_bert_document-segmentation_chinese-base),该模型基于wiki-zh公开语料训练,对未分割的长文本进行段落分割。提升未分割文本的可读性以及下游NLP任务的性能。
三、部署模型
3.1 下载模型
git clone https://www.modelscope.cn/iic/nlp_bert_document-segmentation_chinese-base.git
3.2 安装依赖
# vi requirements.txt
# basic requirements
fastapi>=0.110.0
uvicorn>=0.29.0
pydantic>=2.7.0
tiktoken>=0.6.0
sse-starlette>=2.0.0
transformers>=4.37.0
torch>=2.1.0
sentencepiece>=0.2.0
sentence-transformers>=2.4.0
accelerate
modelscope
#安装依赖
pip install requirements.txt
3.3 部署模型
# 文件名:api-server-nlp-bert.py# -*- coding: utf-8 -*-
# This is a sample Python script.import argparse
import os
import uuid
from pydantic import BaseModelimport uvicorn
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
from utils import num_tokens_from_string
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks# 声明API
app = FastAPI(default_timeout=1000 * 60 * 10)# 统一异常处理
@app.exception_handler(Exception)
async def all_exceptions_handler(request: Request, exc: Exception):"""处理所有异常"""return JSONResponse(status_code=500,content={"msg": str(exc)})# 自定义中间件
@app.middleware("http")
async def unified_interception(request: Request, call_next):# 在这里编写你的拦截逻辑# 例如,检查请求的header或参数# 如果不满足条件,可以直接返回响应,不再调用后续的路由处理token = request.headers.get("Authorization")# if token is None:# return JSONResponse({"message": "Missing Authorization"}, status_code=401)# 如果满足条件,则继续调用后续的路由处理response = await call_next(request)# 在这里编写你的响应处理逻辑# 例如,添加或修改响应头# 返回最终的响应return response# 文档分割请求信息
class DocumentRequest(BaseModel):# 模型平台platform: str = None# 模型model: str# 内容input: str# 监控
@app.get("/api/models")
async def models():# 构造返回数据response = {"model": MODEL_NAME}return JSONResponse(response, status_code=200)# 向量化
@app.post("/api/v1/document/segmentation")
async def embeddings(request: DocumentRequest):if len(request.input) <= 0:return JSONResponse({"msg": "数据不能为空!"}, status_code=500)# 请求idrequest_id = str(uuid.uuid4())# 文档分割result = pipeline(documents=request.input)# 按行拆分,并过滤空行lines = [line for line in result[OutputKeys.TEXT].splitlines() if line.strip() != ""]# 构造返回数据response = {"output": {"lines": [{"text": text,"index": index}for index, text in enumerate(lines)]},"request_id": request_id,"usage": {"total_tokens": num_tokens_from_string(request.input)}}return JSONResponse(response, status_code=200)if __name__ == '__main__':# 定义命令行解析器对象parser = argparse.ArgumentParser(description='模型参数解析器')# 添加命令行参数、默认值parser.add_argument("--host", type=str, default="0.0.0.0")parser.add_argument("--port", type=int, default=8880)parser.add_argument("--model_path", type=str, default="")parser.add_argument("--model_name", type=str, default="")# 从命令行中结构化解析参数args = parser.parse_args()# 模型路径MODEL_PATH = args.model_pathMODEL_NAME = args.model_nameif len(MODEL_PATH) <= 0:raise Exception("模型不能为空!")# 如果没有传入模型名称,则从路径中获取if len(MODEL_NAME) == 0:MODEL_DIR,MODEL_NAME = os.path.split(MODEL_PATH)# 向量模型pipeline = pipeline(task=Tasks.document_segmentation,model=MODEL_PATH)# 启动 uvicorn 服务uvicorn.run(app, host=args.host, port=args.port)
3.4 运行服务
# 运行脚本,指定模型路径
python api-server-nlp-bert.py --model_path=F:\llm\model\nlp_bert_document-segmentation_chinese-base
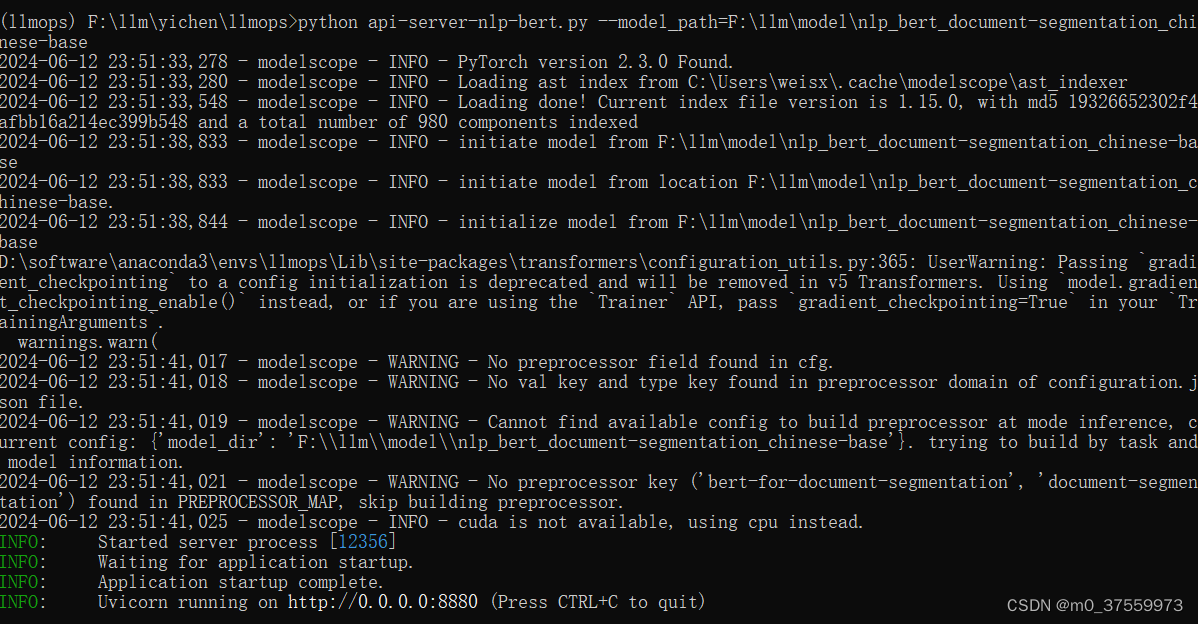
四、测试模型
curl -X POST -H "Content-Type: application/json" 'http://localhost:8880/api/v1/document/segmentation' \
-d '{"platform": "tongyi", "model": "nlp_bert_document-segmentation_chinese-base", "input":"《相见欢·林花谢了春红》 林花谢了春红,太匆匆。 无奈朝来寒雨晚来风。 胭脂泪,相留醉,几时重。 自是人生长恨水长东。 《虞美人·春花秋月何时了》 春花秋月何时了?往事知多少。 小楼昨夜又东风,故国不堪回首月明中。 雕栏玉砌应犹在,只是朱颜改。 问君能有几多愁?恰似一江春水向东流。 《相见欢·无言独上西楼》 无言独上西楼,月如钩。 寂寞梧桐深院锁清秋。别是一般滋味在心头。 《浪淘沙令·帘外雨潺潺》 帘外雨潺潺,春意阑珊。 罗衾不耐五更寒。 梦里不知身是客,一晌贪欢。 独自莫凭栏,无限江山。 别时容易见时难。 流水落花春去也,天上人间。 《渔父·浪花有意千里雪》 浪花有意千里雪,桃花无言一队春。 一壶酒,一竿身,快活如侬有几人。 《清平乐·别来春半》 别来春半,触目柔肠断。 砌下落梅如雪乱,拂了一身还满。雁来音信无凭,路遥归梦难成。 离恨恰如春草,更行更远还生。 《渡中江望石城泣下》 江南江北旧家乡,三十年来梦一场。 吴苑宫闱今冷落,广陵台殿已荒凉。 云笼远岫愁千片,雨打归舟泪万行。 兄弟四人三百口,不堪闲坐细思量。"}'