线程池前置知识
并发和并行
并发是指在单核CPU上,多个线程占用不同的CPU时间片。线程在物理上还是串行执行的,但是由于每个线程占用的CPU时间片非常短(比如10ms),看起来就像是多个线程都在共同执行一样,这样的场景称作并发 (concurrency)。
并行是指在多核或者多CPU上,多个线程是在真正的同时执行,这样的场景称作并行(parallel)。
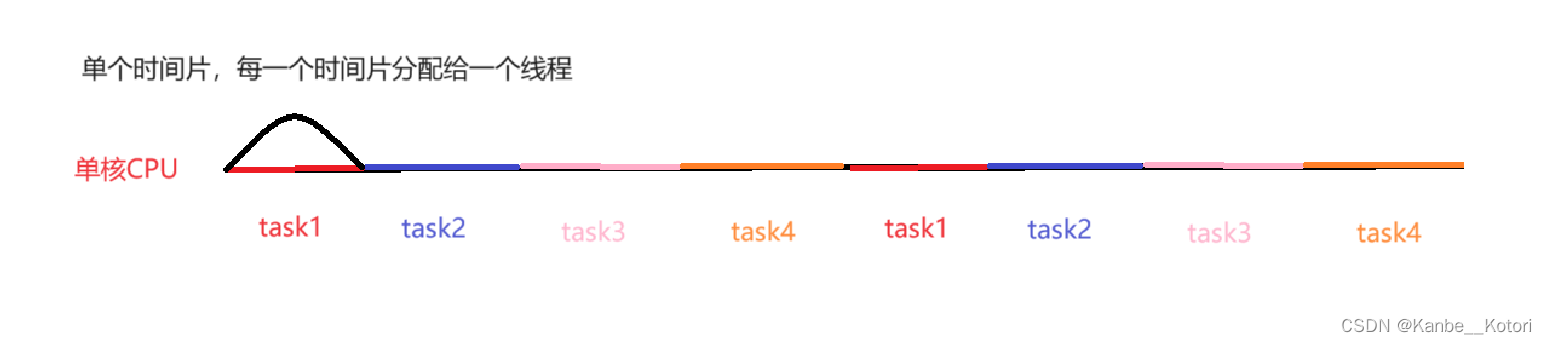
如上图所示,task1、task2、task3、task4是串行执行的,它们的执行有先后顺序,只有task1执行完了或task1的时间片使用完毕了,task2才会才会执行,task3、task4也是如此。所以task1、2、3、4它们在现实层面上并不能一起执行,只不过是执行每一个任务的用时都非常的短,在人类的感知上会觉得它们在一起执行一样,这就是并发。
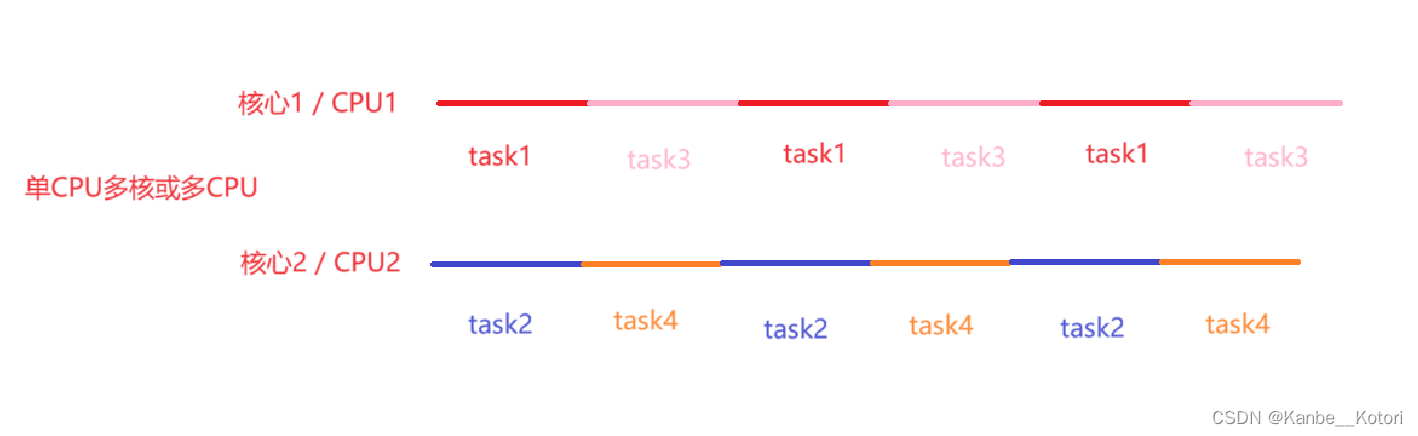
并行要求多CPU或单CPU多核心。如上图所示(以单CPU多核为例),task1和task2分别在不同的核心上执行,它们之间并不存在先后关系。在task1在核心1上执行的同时,task2也在核心2上执行,它们真正在物理层面实现的同时执行,不存在task1在执行,task2就无法执行,这样就可以说task1和task2是并行的。
我们还可以从图中看出,在不同的核心上同样进行这并发,task1与task3是并发的、task2与task4是并发的,所以在并行的同时也能够进行并发,而且也能看出来线程并不是越多越好,在上图中,如果只有task1和task2两个任务,它们就能一直并行,但现在还多了task3和task4,所以它们还要并发执行,这样就加大了时间的开销。(task1也有可能与task2并发执行,因为task1与task2不一定一直在两个核心上分别执行,CPU也有可能把它们调度到一个核心上)
来个比喻:并发是一个人(CPU / 核心)同时吃三个馒头(线程),而并行是三个人(CPU / 核心)同时吃三个馒头(线程)。
多线程的优势
多线程可以提高程序的运行效率,但是多线程程序就一定好吗?这是要看具体场景的。
我们可以把程序分为两类,一类是IO密集型、另一类是CPU密集型。
IO密集型任务是指在执行过程中主要涉及到输入输出(IO)操作的任务。这些任务通常需要与外部资源进行交互,如读写文件、网络请求、数据库查询等,而实际的计算量相对较小。
CPU密集型任务是指在执行过程中主要涉及到大量的计算和处理,而涉及到的IO操作相对较少的任务。这些任务通常需要大量的CPU资源和运算能力。

在IO密集型任务中,CPU的使用率相对较低,大部分时间都花费在等待IO操作完成上。一个线程在执行IO操作时,它会将CPU资源释放给其他可执行的线程。这是因为IO操作通常涉及等待外部资源响应或完成,例如从磁盘读取数据、网络请求等,这些操作需要较长的时间来完成。IO密集型的程序在IO操作没有准备好时就会进入等待队列中等待资源就绪,而等待队列的线程是不会被调度的。因此,多线程在这种情况下能够充分利用等待IO操作的时间,执行其他任务,从而提高程序的并发性和响应能力。所以不管是单CPU单核还是单CPU多核还是多CPU,IO密集型都合适设计成多线程程序。如果程序中既有IO操作也有计算操作,那也可以设计成多线程程序。
CPU密集型在只有单CPU单核时不适合设计成多线程任务,在多核或多CPU的情况下可以设计成多线程程序。我们把每个线程比作一个机器人,每个核心比作一个计算器,如果现在我们需要计算0到1亿的和,那么在只有一个计算器的情况下,是一个机器人计算的快还是两个机器人计算的快呢(一定要借助计算器)?答案是一个机器人计算的快。
这是为什么呢?这是因为,如果只有一个机器人参与运算,那么它要做的就只有一件事:从0到1亿逐渐累加,并记录答案就好了。但如果需要两个机器人参与的话,首先在一个机器人计算的同时,另一个一定在等待,这就已经是一种浪费了;其次要计算结果就一定需要计算器,这就说明了它们之间需要传递计算器,传递计算器(线程调度)是需要时间的,这就表明了在传递计算器的过程中一定会出现时间的浪费;最后就是,机器人在得到计算器后总不能从头开始算吧,他需要确定现在已经算到了哪里、现在要从哪开始算、算到现在的结果是多少......(上下文切换)这些也都是要时间的。这就已经注定了在单核的情况下,CPU密集型任务是不适合多线程的。在多核或多CPU的情况下,我们可以把一个任务拆分成两个任务,比如把从0加到1亿查分成从0加到5千万和从五千万+1加到1亿,然后分别给两个线程执行,此时它们是并发执行的,不存在需要传递计算器的情况,这样效率就能大大提高。
线程的消耗
多线程好,那么多少个线程才算好?是越多越好吗?那当然不是,因为线程是需要占用资源的。
线程的创建和销毁都需要较多资源。不管你使用的什么语言,程序创建线程都是需要通过系统接口来实现的(语言层面上的线程库只是对系统接口进行了封装,本质上还是在调用系统接口),而调用系统接口就需要从用户态转变为内核态(陷入内核),然后操作系统需要为线程创建PCB(task_struct)、内核栈、页目录/页表、描述地址空间相应的数据结构(mm_struct、vm_area_struct指明代码段、数据段等从哪开始,到哪结束,哪段内存是可读、可写还是可读可写、可执行)最后再返回用户态,可以看出创建线程的消耗是很大的,同理销毁线程需要回收这部分资源也需要较大的开销。如果在服务执行的过程中实时的创建和销毁线程,这就非常消耗系统资源,如果这个服务是秒杀抢购这些高流量服务的话,就更不能把资源消耗在线程的创建和销毁上了。
线程栈本身占用大量资源。线程是共享创建其的进程的地址空间的,在32位系统下,一个进程最多能使用的内存大小为4G,其中1G为内核空间,所以一个进程最多能够自由使用3G的内存。
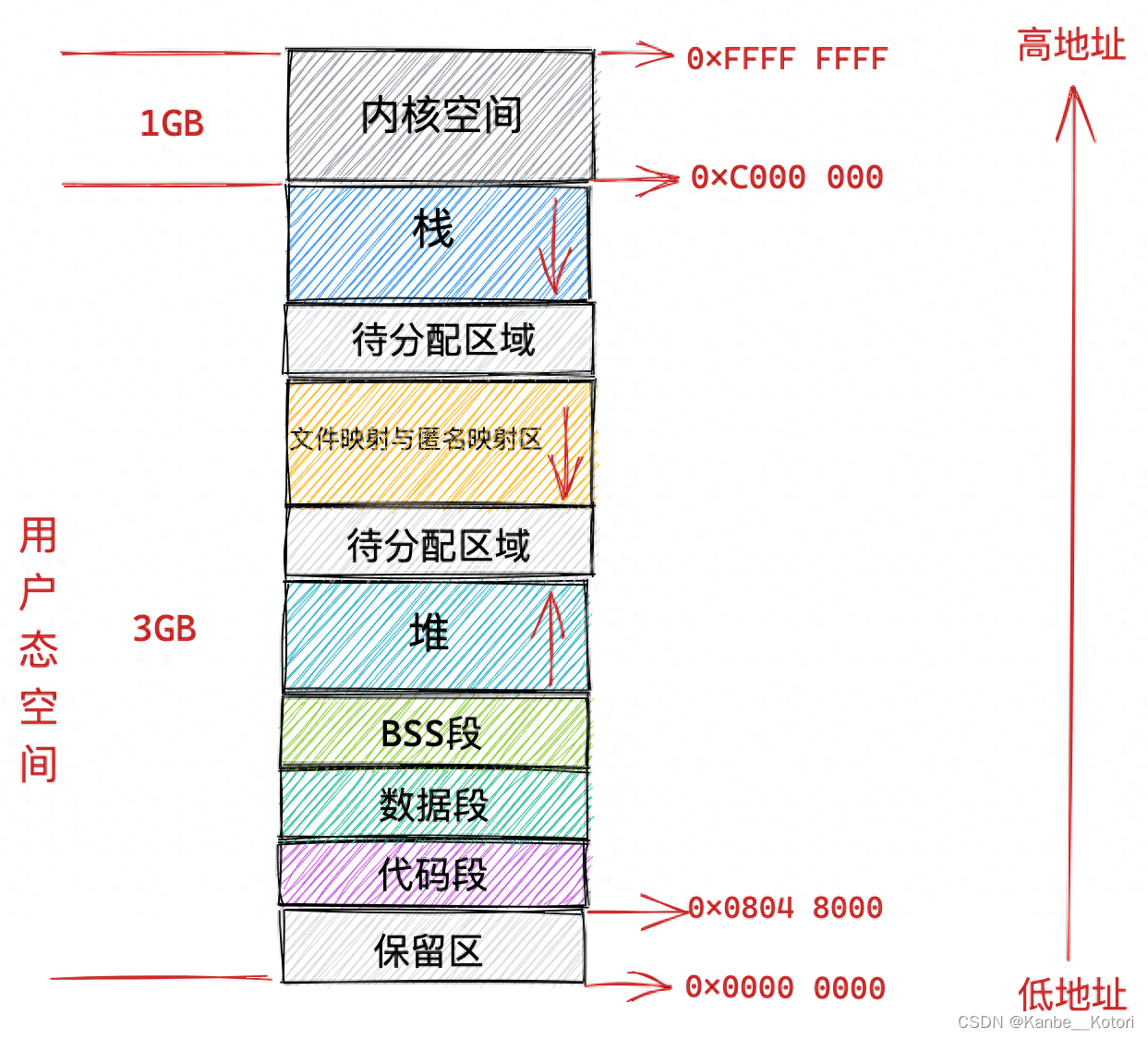
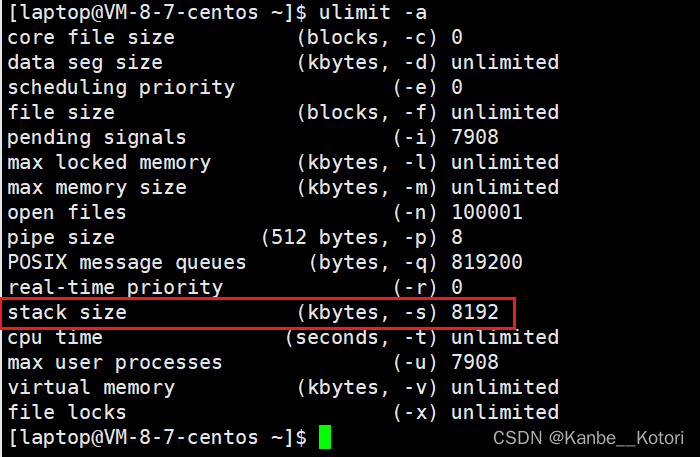
Linux在默认情况下,一个线程栈的大小为8M,所以一个进程最多创建380左右个线程(3 * 1024 / 8 = 384,数据段、堆、共享区等也要占空间,所以不可能创建384个线程)。
这里贴一篇文章可供参考:一个进程最多可以创建多少个线程?
因为线程栈需要占用的空间很大,所以如果创建了大量的线程就会占用大量的空间,那么留给程序用来处理任务的空间就会很小,反而会降低程序的效率,而且如果创建了大量的线程但是有很多线程处于闲置状态的话,那更是一种浪费。
线程的上下文切换要占用大量时间。程序中线程越多,每个线程能分配到的时间片就越小,那么就需要更加频繁调度线程,而线程的调度是需要切换上下文的,切换上下文是一个非常耗时的操作,那么CPU就需要花大量的时间在切换上下文上,这样CPU的使用效率就不高了。
大量线程同时唤醒会使系统经常出现锯齿状负载或者瞬间负载量很大导致宕机。如果创建的大量线程都在执行IO操作并正在阻塞等待资源,当在同一时间资源准备就绪时,就会有大量的线程就会被唤醒等待被调度,这样系统就会在短时间内负载特别高,可能会导致宕机。
所以一般来说,线程的数量是由CPU的核心数量来确定的(如4个核心就创建4个线程,8个核心就创建8个线程,因为这样就能真正的实现并行来提高效率),muduo、libevent、Netty、mina等知名网络库都是按照这样的规则来创建线程的。
线程池的两种模式
操作系统上创建线程和销毁线程都是很"重"的操作,耗时耗性能都比较多,那么在服务执行的过程中,如果业务量比较大,实时的去创建线程、执行业务、业务完成后销毁线程,那么会导致系统的实时性能降低,业务的处理能力也会降低。
线程池的优势就是,在服务进程启动之初,就事先创建好线程池里面的线程,当业务流量到来时需要分配线程,直接从线程池中获取一个空闲线程执行task任务即可,task执行完成后,也不用释放线程,而是把线程归还到线程池中继续给后续的task提供服务。
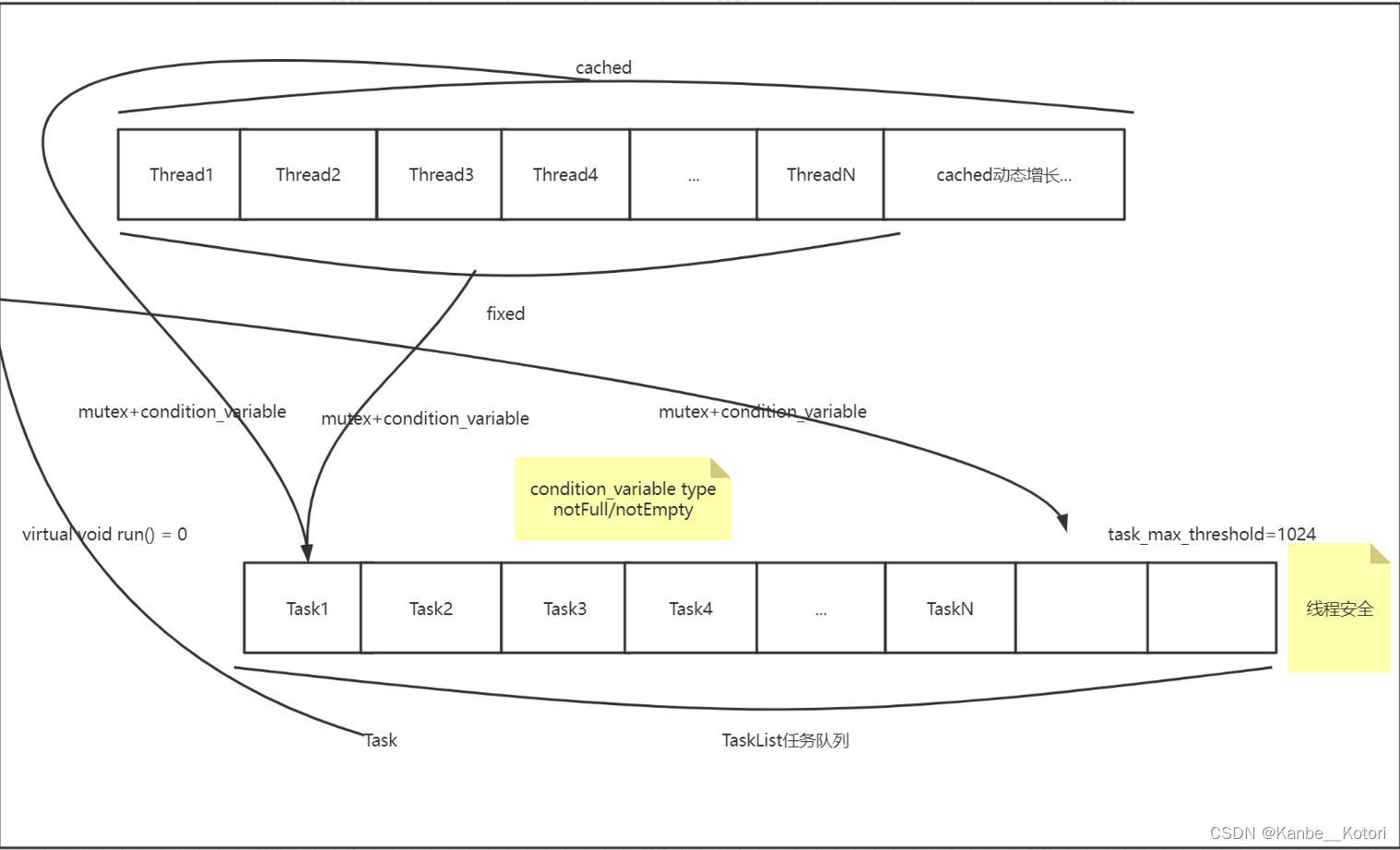
fixed模式线程池线程池里面的线程个数是固定不变的,一般是ThreadPool创建时根据当前机器的CPU核心数量进行指定。
cached模式线程池线程池里面的线程个数是可动态增长的,根据任务的数量动态的增加线程的数量,但是会设置一个线程数量的阈值(线程过多的坏处上面已经讲过了),任务处理完成,如果动态增长的线程空闲了60s还没有处理其它任务,那么关闭线程,保持池中最初数量的线程即可。
当任务数量特别多,并且任务内容为IO等耗时较长的任务时,如果为fixed模式线程池,可能就会导致线程池内的线程全部被占用,后续到达任务队列的任务没有线程可以处理,此时就可以使用cached模式线程池来动态创建新的线程来处理任务,等到任务可以由原先的线程来及时处理时,就可以把新创建的线程销毁掉。但大部分情况下,fixed模式线程池就可以了。