代码解读 | Hybrid Transformers for Music Source Separation[07]
一、背景

0、Hybrid Transformer 论文解读
1、代码复现|Demucs Music Source Separation_demucs架构原理-CSDN博客
2、Hybrid Transformer 各个模块对应的代码具体在工程的哪个地方
3、Hybrid Transformer 各个模块的底层到底是个啥(初步感受)?
4、Hybrid Transformer 各个模块处理后,数据的维度大小是咋变换的?
5、Hybrid Transformer 拆解STFT模块
6、Hybrid Transformer 拆解频域编码模块
7、Hybrid Transformer 拆解频域解码模块、ISTFT模块
从模块上划分,Hybrid Transformer Demucs 共包含 (STFT模块、时域编码模块、频域编码模块、Cross-Domain Transformer Encoder模块、时域解码模块、频域解码模块、ISTFT模块)7个模块。已完成解读:STFT模块、频域编码模块(时域编码和频域编码类似,后续不再解读时域编码模块)、频域解码模块(时域解码和频域解码类似,后续不再解读频域解码模块)、ISTFT模块。
本篇目标:拆解Cross-Domain Transformer Encoder模块。
二、Cross-Domain Transformer Encoder模块
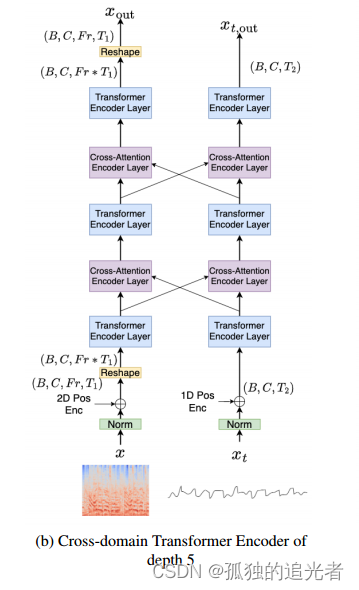
2.1 Cross-Domain Transformer Encoder模块的组成
Cross-Domain Transformer Encoder 核心源代码如下所示:
class CrossTransformerEncoder(nn.Module):def __init__(self,dim: int,emb: str = "sin",hidden_scale: float = 4.0,num_heads: int = 8,num_layers: int = 6,cross_first: bool = False,dropout: float = 0.0,max_positions: int = 1000,norm_in: bool = True,norm_in_group: bool = False,group_norm: int = False,norm_first: bool = False,norm_out: bool = False,max_period: float = 10000.0,weight_decay: float = 0.0,lr: tp.Optional[float] = None,layer_scale: bool = False,gelu: bool = True,sin_random_shift: int = 0,weight_pos_embed: float = 1.0,cape_mean_normalize: bool = True,cape_augment: bool = True,cape_glob_loc_scale: list = [5000.0, 1.0, 1.4],sparse_self_attn: bool = False,sparse_cross_attn: bool = False,mask_type: str = "diag",mask_random_seed: int = 42,sparse_attn_window: int = 500,global_window: int = 50,auto_sparsity: bool = False,sparsity: float = 0.95,):super().__init__()""""""assert dim % num_heads == 0hidden_dim = int(dim * hidden_scale)self.num_layers = num_layers# classic parity = 1 means that if idx%2 == 1 there is a# classical encoder else there is a cross encoderself.classic_parity = 1 if cross_first else 0self.emb = embself.max_period = max_periodself.weight_decay = weight_decayself.weight_pos_embed = weight_pos_embedself.sin_random_shift = sin_random_shiftif emb == "cape":self.cape_mean_normalize = cape_mean_normalizeself.cape_augment = cape_augmentself.cape_glob_loc_scale = cape_glob_loc_scaleif emb == "scaled":self.position_embeddings = ScaledEmbedding(max_positions, dim, scale=0.2)self.lr = lractivation: tp.Any = F.gelu if gelu else F.reluself.norm_in: nn.Moduleself.norm_in_t: nn.Moduleif norm_in:self.norm_in = nn.LayerNorm(dim)self.norm_in_t = nn.LayerNorm(dim)elif norm_in_group:self.norm_in = MyGroupNorm(int(norm_in_group), dim)self.norm_in_t = MyGroupNorm(int(norm_in_group), dim)else:self.norm_in = nn.Identity()self.norm_in_t = nn.Identity()# spectrogram layersself.layers = nn.ModuleList()# temporal layersself.layers_t = nn.ModuleList()kwargs_common = {"d_model": dim,"nhead": num_heads,"dim_feedforward": hidden_dim,"dropout": dropout,"activation": activation,"group_norm": group_norm,"norm_first": norm_first,"norm_out": norm_out,"layer_scale": layer_scale,"mask_type": mask_type,"mask_random_seed": mask_random_seed,"sparse_attn_window": sparse_attn_window,"global_window": global_window,"sparsity": sparsity,"auto_sparsity": auto_sparsity,"batch_first": True,}kwargs_classic_encoder = dict(kwargs_common)kwargs_classic_encoder.update({"sparse": sparse_self_attn,})kwargs_cross_encoder = dict(kwargs_common)kwargs_cross_encoder.update({"sparse": sparse_cross_attn,})for idx in range(num_layers):if idx % 2 == self.classic_parity:self.layers.append(MyTransformerEncoderLayer(**kwargs_classic_encoder))self.layers_t.append(MyTransformerEncoderLayer(**kwargs_classic_encoder))else:self.layers.append(CrossTransformerEncoderLayer(**kwargs_cross_encoder))self.layers_t.append(CrossTransformerEncoderLayer(**kwargs_cross_encoder))def forward(self, x, xt):B, C, Fr, T1 = x.shapepos_emb_2d = create_2d_sin_embedding(C, Fr, T1, x.device, self.max_period) # (1, C, Fr, T1)pos_emb_2d = rearrange(pos_emb_2d, "b c fr t1 -> b (t1 fr) c")x = rearrange(x, "b c fr t1 -> b (t1 fr) c")x = self.norm_in(x)x = x + self.weight_pos_embed * pos_emb_2dB, C, T2 = xt.shapext = rearrange(xt, "b c t2 -> b t2 c") # now T2, B, Cpos_emb = self._get_pos_embedding(T2, B, C, x.device)pos_emb = rearrange(pos_emb, "t2 b c -> b t2 c")xt = self.norm_in_t(xt)xt = xt + self.weight_pos_embed * pos_embfor idx in range(self.num_layers):if idx % 2 == self.classic_parity:x = self.layers[idx](x)xt = self.layers_t[idx](xt)else:old_x = xx = self.layers[idx](x, xt)xt = self.layers_t[idx](xt, old_x)x = rearrange(x, "b (t1 fr) c -> b c fr t1", t1=T1)xt = rearrange(xt, "b t2 c -> b c t2")return x, xtdef _get_pos_embedding(self, T, B, C, device):if self.emb == "sin":shift = random.randrange(self.sin_random_shift + 1)pos_emb = create_sin_embedding(T, C, shift=shift, device=device, max_period=self.max_period)elif self.emb == "cape":if self.training:pos_emb = create_sin_embedding_cape(T,C,B,device=device,max_period=self.max_period,mean_normalize=self.cape_mean_normalize,augment=self.cape_augment,max_global_shift=self.cape_glob_loc_scale[0],max_local_shift=self.cape_glob_loc_scale[1],max_scale=self.cape_glob_loc_scale[2],)else:pos_emb = create_sin_embedding_cape(T,C,B,device=device,max_period=self.max_period,mean_normalize=self.cape_mean_normalize,augment=False,)elif self.emb == "scaled":pos = torch.arange(T, device=device)pos_emb = self.position_embeddings(pos)[:, None]return pos_embdef make_optim_group(self):group = {"params": list(self.parameters()), "weight_decay": self.weight_decay}if self.lr is not None:group["lr"] = self.lrreturn group
通过print,打印出Cross-Domain Transformer Encoder模块分别用了三个MyTransformerEncoderLayer+两个CrossTransformerEncoderLayer。这个和论文中的模型图是一致的。频域对应下面(layers)、时域对应下面(layers_t)。
CrossTransformerEncoder((norm_in): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm_in_t): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(layers): ModuleList((0): MyTransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale())(1): CrossTransformerEncoderLayer((cross_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale()(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False))(2): MyTransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale())(3): CrossTransformerEncoderLayer((cross_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale()(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False))(4): MyTransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale()))(layers_t): ModuleList((0): MyTransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale())(1): CrossTransformerEncoderLayer((cross_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale()(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False))(2): MyTransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale())(3): CrossTransformerEncoderLayer((cross_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale()(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False))(4): MyTransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=384, out_features=384, bias=True))(linear1): Linear(in_features=384, out_features=1536, bias=True)(dropout): Dropout(p=0.0, inplace=False)(linear2): Linear(in_features=1536, out_features=384, bias=True)(norm1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((384,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.0, inplace=False)(dropout2): Dropout(p=0.0, inplace=False)(norm_out): MyGroupNorm(1, 384, eps=1e-05, affine=True)(gamma_1): LayerScale()(gamma_2): LayerScale()))
)
2.2 Transformer Encoder模块
2.2.1 为何Hybrid Transformer Demucs只使用了Transformer的Encoder部分
在介绍Transformer Encoder模块之前先思考第一个问题:为啥音源分离任务只使用Transformer Encoder模块,而不是整个Transformer模块?

为了回答这个问题,我们需要了解Transformer的组成。如上图所示,Transformer由左侧的Encoder模块+右侧的Decoder模块组成。Encoder和Decoder均由位置编码+多头注意力+前馈网络组成。
《Attention Is All You Need》
【论文原文有这么一段】
Here, the encoder maps an input sequence of symbol representations (x1, ..., xn) to a sequence of continuous representations z = (z1, ..., zn). Given z, the decoder then generates an output sequence (y1, ..., ym) of symbols one element at a time. At each step the model is auto-regressive[10], consuming the previously generated symbols as additional input when generating the next.
【翻译成中文】
编码器映射符号表示(x1,…)的输入序列。, xn)到连续表示序列z = (z1,…)、锌)。给定z,解码器然后生成输出序列(y1,…), ym)符号,一次一个元素。
大体的意思就是,Encoder的作用是把输入序列映射到一个新的序列,Decoder的作用是生成一个新的序列。
音源分离任务(此外,还有文本分类等任务)不需要生成新的序列,而是需要提取和处理输入序列特征,所以使用Transformer Encoder模块即可。而在需要生成响应或翻译的任务中,如机器翻译或文本摘要,解码器部分则发挥着关键作用。在这些任务中,编码器首先处理输入序列,提取特征,然后解码器利用这些特征生成目标序列。
拓展一下,GPT(生成式预训练变换器,Generative Pre-trained Transformer)模型主要使用了Transformer的解码器(Decoder)部分。 以下是GPT使用解码器部分的原因和特点:
1. 序列生成:GPT的主要任务是生成文本序列,这需要一个能够生成连贯、合理文本的模型。解码器部分非常适合这一任务,因为它设计用于生成序列。
2. 遮蔽自注意力:在解码器中,自注意力机制使用了遮蔽(masking),确保在生成序列的每一步时,只考虑已经生成的输出,而不会看到未来的信息,这有助于避免信息泄露问题。
3.逐层生成:GPT在解码器中逐层生成文本序列,每一层都会利用前一层的输出和编码器(在预训练阶段)或之前层的输出(在微调和生成阶段)来生成当前层的文本。
4. 条件语言生成:GPT通过条件语言生成的方式,根据给定的上下文或提示生成文本。解码器部分的自回归特性使其能够根据先前生成的文本来生成下一个词。
5. 预训练和微调:GPT通常首先在大量文本数据上进行预训练,学习语言模式和结构。预训练完成后,GPT可以在特定任务上进行微调,以适应不同的应用场景。
6. 多头注意力和位置编码:GPT的解码器部分使用多头注意力机制和位置编码,以捕捉序列内部的依赖关系和保持词序信息。
7. 层叠结构:GPT模型通常包含多个解码器层,每一层都包含自注意力机制和前馈网络,以逐步提炼和生成文本序列。
8. 并行生成:由于解码器的自注意力机制使用了遮蔽,GPT可以并行生成整个序列的每个词,这提高了生成效率。
总的来说,GPT利用了Transformer解码器部分的能力来生成文本序列,通过遮蔽自注意力和逐层生成的方式,实现了高效的条件语言生成。
2.2.2 为何Hybrid Transformer Demucs的Transformer Encoder使用位置编码

在Transformer模型中,使用位置编码(Positional Encoding)有以下几个好处:
1.保持序列顺序性:在传统的循环神经网络(RNN)中,模型可以通过时间步来捕捉序列中的顺序信息。然而,Transformer模型的自注意力机制并不考虑序列的顺序。位置编码允许模型在处理序列数据时,能够捕捉到单词之间的相对位置关系。
2.增强模型表达能力:位置编码通过为每个输入序列中的每个单词添加一个唯一的位置信息,增强了模型对序列中单词位置的感知能力,从而提高了模型对序列数据的处理能力。
3.简单有效:位置编码的实现相对简单,通常是通过将正弦和余弦函数的不同频率应用于单词的维度来实现的。这种编码方式不仅简单,而且能够有效地将位置信息融入到模型中。
4.可扩展性:位置编码的设计使得它可以很容易地扩展到不同长度的序列,因为每个位置编码都是唯一的,并且与序列的长度无关。
5.与自注意力机制的兼容性:位置编码可以与自注意力机制无缝结合,使得模型在处理输入序列时,不仅能够考虑单词之间的相互关系,还能够考虑它们在序列中的位置。
总的来说,位置编码是Transformer模型中不可或缺的一部分,它为模型提供了处理序列数据时所需的位置信息,从而提高了模型的性能和泛化能力。
位置编码源码如下所示,具体的:使用Sin和Cos实现位置编码。
def create_2d_sin_embedding(d_model, height, width, device="cpu", max_period=10000):""":param d_model: dimension of the model:param height: height of the positions:param width: width of the positions:return: d_model*height*width position matrix"""if d_model % 4 != 0:raise ValueError("Cannot use sin/cos positional encoding with ""odd dimension (got dim={:d})".format(d_model))pe = torch.zeros(d_model, height, width)# Each dimension use half of d_modeld_model = int(d_model / 2)div_term = torch.exp(torch.arange(0.0, d_model, 2) * -(math.log(max_period) / d_model))pos_w = torch.arange(0.0, width).unsqueeze(1)pos_h = torch.arange(0.0, height).unsqueeze(1)pe[0:d_model:2, :, :] = (torch.sin(pos_w * div_term).transpose(0, 1).unsqueeze(1).repeat(1, height, 1))pe[1:d_model:2, :, :] = (torch.cos(pos_w * div_term).transpose(0, 1).unsqueeze(1).repeat(1, height, 1))pe[d_model::2, :, :] = (torch.sin(pos_h * div_term).transpose(0, 1).unsqueeze(2).repeat(1, 1, width))pe[d_model + 1:: 2, :, :] = (torch.cos(pos_h * div_term).transpose(0, 1).unsqueeze(2).repeat(1, 1, width))return pe[None, :].to(device)
2.2.3 Transformer Encoder中的多头注意力做了啥?

上图是《 Attention Is All You Need》中注意力和多头注意力的原理图。对应的公式如下所示。
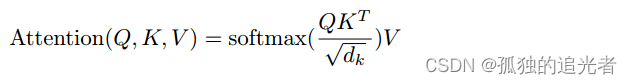
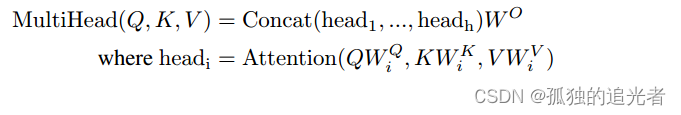
【一句话总结】
Attention干了啥?它用于计算输入序列中各个元素之间的注意力权重,从而确定每个元素在生成输出时应该给予多少关注。
多头注意力干了啥?多头注意力联合关注来自不同表示子空间的信息。
2.2.4 Transformer Encoder中的前馈网络做了啥?
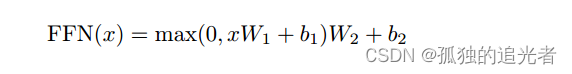
前馈网络由线性层和激活函数组成,公式如上所示。
到底FFN有啥作用?它的作用主要包括:
1. 非线性变换:前馈网络为模型提供了非线性变换的能力。在自注意力机制中,虽然可以捕捉序列内部的依赖关系,但自注意力本身是线性的。前馈网络通过引入非线性激活函数(如ReLU),增加了模型的表达能力。
2. 特征进一步提炼:在经过自注意力层处理后,前馈网络可以进一步提炼特征,提取更深层次的模式和信息。
3. 标准化和正则化:前馈网络通常与层归一化(Layer Normalization)一起使用,这有助于稳定训练过程,减少内部协变量偏移(Internal Covariate Shift)。
终于把Hybrid Transformers for Music Source Separation核心算法部分拆解完成了,完结*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。
感谢阅读,关注公众号(桂圆学AI),后台回复关键字【demucs】可以领取Hybrid Transformers for Music Source Separation核心算法讲解-汇总电子文档。