注意力机制和Transformer模型各部分功能解释
文章目录
- Transformer
- 1、各部分功能解释
- 2、通过例子解释
- a.输入预处理
- 位置编码
- b.Encoder 的处理
- c.Decoder的输入
- Decoder的工作流程
- d.输出预测
- 总结
Attention代码和原理理解
Transformer
运行机理:
(1)假设我们需要进行文本生成任务。我们将已经有的文本首先通过词嵌入并进行位置编码作为输入,输入到encoder中,encoder的目的是使得词不仅仅有了自己的信息,还有了自己上下文的信息,即全局信息,即词有了语义信息。
(2)在训练时,我们使用当前已经预测出来的词作为decoder的输入(当然这些词使用的是正确的词即使可能预测过程中有错误,也使用掩码掩盖未来的词),我们将其与encoder输出的向量进行结合使用注意力层最后使用全连接得到新的预测结果,得到一个预测接下来我们继续将这个预测的词增加作为decoder的输入,直到预测结束。
注意:
- Decoder的输入:从一个特定的起始符号开始,并逐步使用之前步骤生成的词来生成新的词,直到序列完成。
- Encoder的输入:在整个序列生成过程中保持不变,为Decoder提供必要的上下文信息。
1、各部分功能解释
Transformer快速入门
标准的 Transformer 模型主要由两个模块构成:
-
Encoder(左边):负责理解输入文本,为每个输入构造对应的语义表示(语义特征);
-
Decoder(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列。Decoder的输入是当前预测出来的文本,在训练时是正确文本,而预测时是预测出来的文本。 当然都包含位置编码,训练时也需要使用掩码。
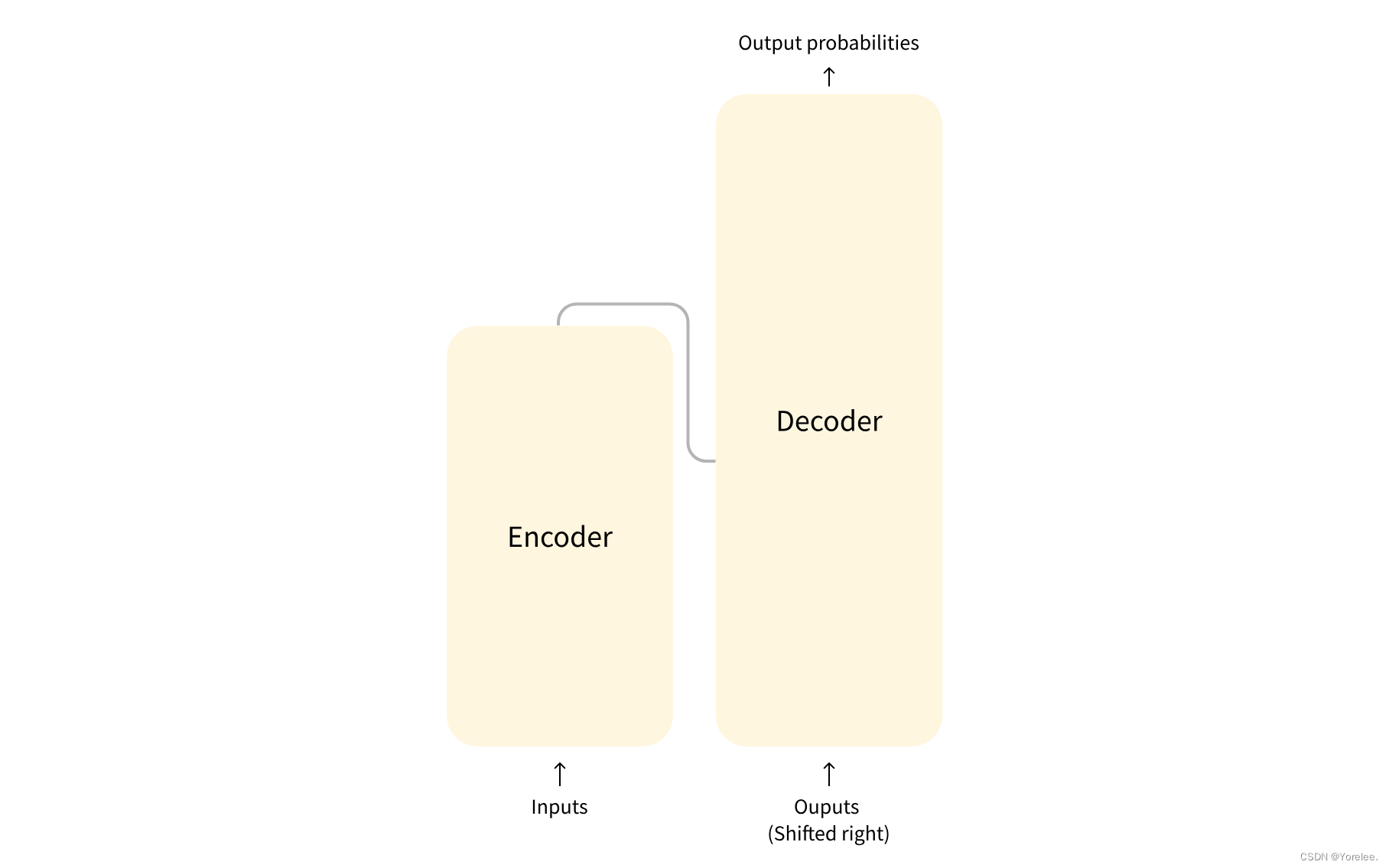
这两个模块可以根据任务的需求而单独使用: -
纯 Encoder 模型:适用于只需要理解输入语义的任务,例如句子分类、命名实体识别;
-
纯 Decoder 模型:适用于生成式任务,例如文本生成;
-
Encoder-Decoder 模型或 Seq2Seq 模型:适用于需要基于输入的生成式任务,例如翻译、摘要。
2、通过例子解释
Transformer模型在处理 “Harry Potter is a wizard and hates __ the most.” 这一句子时的工作流程和各个组件的作用。
a.输入预处理
假设我们的句子 “Harry Potter is a wizard and hates” 已经通过分词处理,并且每个词都被映射到了一个整数ID。例如:
- Harry -> 2021
- Potter -> 1057
- is -> 56
- a -> 15
- wizard -> 498
- and -> 7
- hates -> 372
这些整数ID接着被转换为词嵌入向量。词嵌入层会从一个预训练的嵌入矩阵中提取每个ID对应的向量。
位置编码
对于 “Harry Potter is a wizard and hates” 这七个词,Transformer还需要知道每个词的位置。因此,每个词嵌入向量会加上一个位置向量,位置向量通过一定的函数(如正弦和余弦函数)生成,以反映词在句子中的顺序。
b.Encoder 的处理
经过词嵌入和位置编码后,这组向量输入到Encoder。Encoder中的每一层都包括两部分:多头自注意力机制和前馈神经网络。
- 多头自注意力机制允许模型评估每个词与句子中其他词的关系强度。这有助于捕获比如"Harry Potter"和"wizard"之间的联系。
- 前馈神经网络对自注意力层的输出进行进一步转换。
每一层的输出都会被送入下一层,直到最后一层。Encoder的最终输出是一个加工过的、包含整个句子信息的向量序列。
好的,让我来更详细地解释Transformer模型中Decoder的工作机制,特别是它的输入是如何处理的。
c.Decoder的输入
在理解Decoder的输入之前,我们首先要明确,Transformer模型通常用于处理序列到序列的任务,比如机器翻译、文本摘要等。在这些任务中,Decoder的角色是基于Encoder的输出,生成一个输出序列。
假设我们的任务是文本填空,比如在句子 “Harry Potter is a wizard and hates __ the most.” 中填入缺失的部分。在实际应用(如训练或预测)过程中,Decoder的输入通常有两部分:
-
已知的输出序列的前缀:这是模型在生成每个新词时,已经生成的输出序列的部分。在训练阶段,这通常是目标序列(ground truth)中的前缀;在推理阶段,这是模型逐步生成的输出。例如,如果我们预测的第一个词是 “Voldemort”,那么在预测下一个词时,“Voldemort” 就成了已知的输出序列的前缀。
-
位置编码:和Encoder相同,每个词的词嵌入会加上位置编码。位置编码帮助模型理解词在序列中的位置关系,这对于生成有顺序关系的文本尤其重要。
Decoder的工作流程
在得到输入后,Decoder的每一层会执行以下几个操作:
-
掩蔽多头自注意力(Masked Multi-Head Self-Attention):
- 这一步骤和Encoder中的自注意力类似,但有一个关键区别:它会使用掩蔽(masking)来防止未来位置的信息泄漏。这意味着在生成第 ( n ) 个词的预测时,模型只能访问第 ( n-1 ) 个词及之前的词的信息。
- 例如,当模型正在生成 “Voldemort” 后面的词时,它不能“看到”这个词之后的任何词。
-
编码器-解码器自注意力(Encoder-Decoder Attention):
- 这一步是Decoder的核心部分,其中Decoder利用自己的输出作为查询(Query),而将Encoder的输出作为键(Key)和值(Value)。
- 这允许Decoder根据自己已经生成的文本部分(通过查询),和输入句子的语义表示(通过键和值),生成下一个词的预测。这是一个信息整合的过程,通过Encoder的上下文信息来指导输出序列的生成。
-
前向馈网络(Feed-Forward Network):
- 与Encoder中相同,每个自注意力层后面都会跟一个前向馈网络,这个网络对每个位置的输出独立处理,进一步转换特征表示。
d.输出预测
Decoder的输出通过一个线性层和softmax层,生成每个可能词的概率分布。选择概率最高的词作为预测结果。
总结
因此,在Decoder中,输入主要是基于到目前为止已经生成的输出序列(加上位置信息),而这些输入通过Decoder的多层结构进行处理,每层都包括掩蔽自注意力、编码器-解码器自注意力和前向馈网络,以生成最终的输出序列。这种结构设计使得Transformer能够在考虑到整个输入序列的上下文的同时,逐步构建输出序列。