分布式之日志系统平台ELK
ELK解决了什么问题
我们开发完成后发布到线上的项目出现问题时(中小型公司),我们可能需要获取服务器中的日志文件进行定位分析问题。但在规模较大或者更加复杂的分布式场景下就显得力不从心。因此急需通过集中化的日志管理,将所有服务器上的日志进行收集汇总。所以ELK应运而生,它通过一系列开源框架提供了一整套解决方案,将所有节点上的日志统一收集、存储、分析、可视化等。
- 注意:ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析(比如我们之前项目开发中通过ES实现了用户在不同周期内访问系统的活跃度)和收集的场景,日志分析和收集只是更具有代表性而并非唯一性
概念
ELK是Elasticsearch(存储、检索数据)、Logstash(收集、转换、筛选数据)、Kibana(可视化数据) 三大开源框架的首字母大写简称,目前通常也被称为Elastic Stack(在 ELK的基础上增加了 Beats)

Elasticsearch(ES,Port:9200)
- 开源分布式搜索引擎,提供搜集、分析、存储数据功能
- ES是面向文档document存储,它可以存储整个对象或文档(document)。同时也可以对文档进行索引、搜索、排序、过滤。这种理解数据的方式与传统的关系型数据库完全不同,因此这也是ES能够执行复杂的全文搜索的原因之一,document可以类比为RDMS中的行
- ES使用JSON作为文档序列化格式,统一将document数据转换为json格式进行存储,JSON已经成为NoSQL领域的标准格式
- ES是基于Lucene实现的全文检索,底层是基于倒排的索引方法,用来存储在全文检索下某个单词在一个/组文档中的存储位置[倒排索引是ES具有高检索性能的本质原因]
-
ES-head插件(Port:9100)
- 查看我们导入的数据是否正常生成索引
-
数据删除操作
-
数据浏览
-
Index: Index是文档的容器,在ES的早期版本中的index(类似于RDMS中的库)中还包含有type(类似于RDMS中的表)的概念。但在后续版本中,type被逐渐取消而index同时具有数据库和表的概念
-
查询DSL: 使用JSON格式并基于RESTful API进行通信,提供了全文搜索、范围查询、布尔查询、聚合查询等不同的搜索需求
Logstash(Port:5044)

- ELK的数据流引擎,从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过滤后输出到ES
- Filebeat是一个轻量级的日志收集处理工具(Agent),占用资源少,可在各服务器上搜集信息后传输给Logastash(官方推荐)
- logback+rabbitmq整合日志模式下,我们在logstash.conf配置input从rabbitmq绑定的队列读取日志->filter解析和处理(可选)->output输出日志到目标ES
Kibana(Port:5601)
- 分析和可视化数据:利用工具分析 es中的数据,编制图表仪表板,利用仪表、地图和其他可视化显示发现的内容
- 搜索、观察和保护数据:向应用和网站添加搜索框,分析日志和指标,并发现安全漏洞
- 管理、监控和保护 Elastic Stack:监控和管理 es集群、kibana等 elastic stack的运行状况,并控制用户访问特征和数据
- 常用核心功能
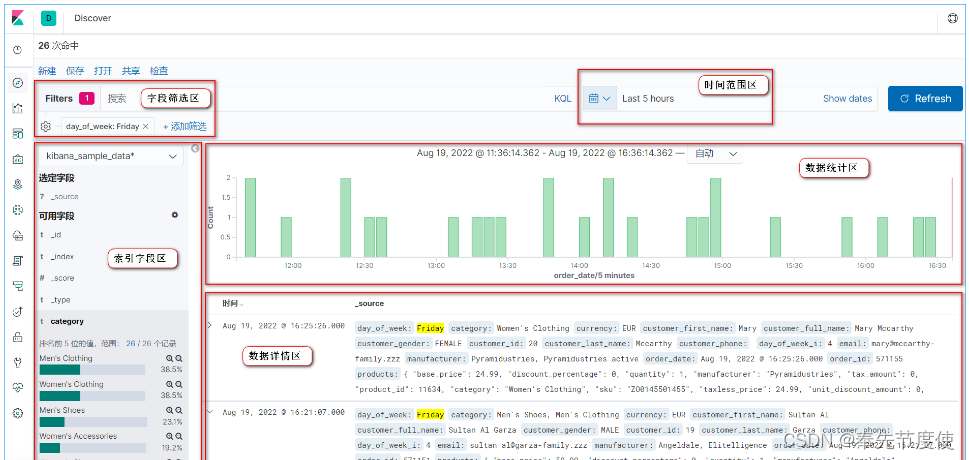
- Discover: 浏览ES索引中的数据,还可以添加筛选条件进而查看感兴趣的数据
-
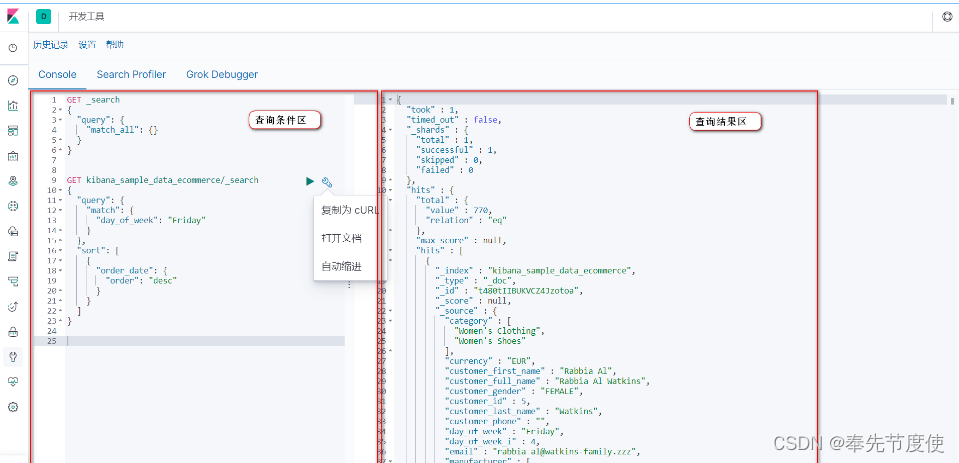
- Dev_Tool: 用ES支持的语法编写查询条件查询,也可用于测试代码中的查询条件
-
- 管理:索引管理和索引模式
- 索引管理:查看索引的运行状况、状态、主分片和副本分片等信息
- 索引模式:用于匹配命名符合一定规律的单个或多个索引,便于在 discover界面查看和分析目标索引的数据
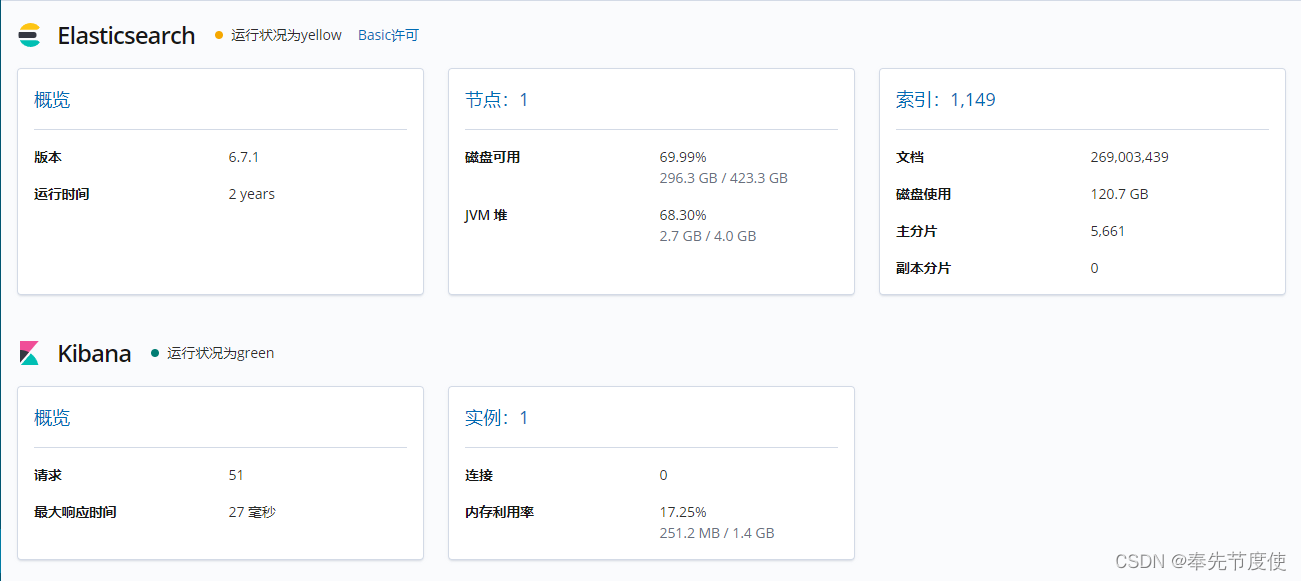
- Monitoring: 查看ES集群版本、运行时间、节点状态情况和索引情况
- 管理:索引管理和索引模式
-
- 可视化: 根据需求可创建条形图、饼图、云图(词云图)进行个性化定制
项目实战
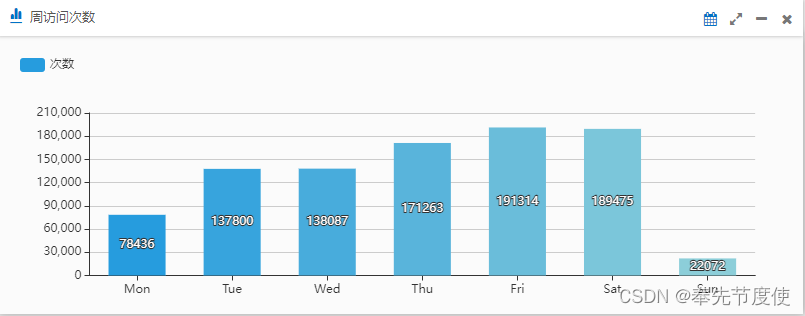
在公司项目实际开发中我们基于logback -> rabbitmq -> elk 工作模式进行日志收集,实现了日志的集中管理。在此基础上通过ES搜索建立系统可视化看板来显示用户在不同周期内访问系统的活跃度
注意:logback是日志框架(log4j也是一种日志框架),而slf4j是日志门面接口
具体相关核心实现流程
- Maven导入Logback、ElasticSearch依赖
<dependency><groupId>net.logstash.logback</groupId><artifactId>logstash-logback-encoder</artifactId><version>5.1</version> </dependency> <dependency><groupId>net.logstash.log4j</groupId><artifactId>jsonevent-layout</artifactId><version>1.7</version> </dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>6.3.1</version> </dependency> <dependency><groupId>org.elasticsearch.client</groupId><artifactId>transport</artifactId><version>6.3.1</version> </dependency> <dependency><groupId>org.elasticsearch.plugin</groupId><artifactId>transport-netty4-client</artifactId><version>6.3.1</version> </dependency> - 定义logback-prod.xml配置文件
# 首先需要在application.yml文件配置log日志相关属性配置 logging:config: classpath:logback-prod.xml #配置logback文件,本地开发不需要配置file: logs/${logback.log.file} #存储日志的文件#我们logback采用Rabbitmq方式收集日志时消息服务配置信息 logback:log:path: "./logs/"file: logback_amqp.logamqp:host: 10.225.225.225port: 5672username: adminpassword: admin<?xml version="1.0" encoding="UTF-8"?> <configuration scan="true" scanPeriod="60 seconds" debug="false"><include resource="org/springframework/boot/logging/logback/base.xml" /><contextName>logback</contextName><!-- 日志输出路径: source对应的值取自application.yml文件--><springProperty scope="context" name="log.path" source="logback.log.path" /><springProperty scope="context" name="log.file" source="logback.log.file" /><springProperty scope="context" name="logback.amqp.host" source="logback.amqp.host"/><springProperty scope="context" name="logback.amqp.port" source="logback.amqp.port"/><springProperty scope="context" name="logback.amqp.username" source="logback.amqp.username"/><springProperty scope="context" name="logback.amqp.password" source="logback.amqp.password"/><!-- 输出到logstash的appender--><appender name="stash-amqp" class="org.springframework.amqp.rabbit.logback.AmqpAppender"> <!--日志收集模式:logback -> rabbitmq -> elk 工作模式,因此我们需要使用net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder实现--><encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder"><providers><pattern><!-- 其中"application": "application"中的值必须为小写,否则elk创建index报错(elk创建index基本规则为:字母必须都为小写) --><pattern>{"time": "%date{ISO8601}", "thread": "%thread", "level": "%level", "class": "%logger{60}", "message": "%message", "application": "application" }</pattern></pattern></providers></encoder><host>${logback.amqp.host}</host> <port>${logback.amqp.port}</port> <username>${logback.amqp.username}</username> <password>${logback.amqp.password}</password><declareExchange>true</declareExchange> <exchangeType>fanout</exchangeType> <exchangeName>ex_common_application_Log</exchangeName> <!-- 需在rabbitmq页面手动配置交换机与队列--><generateId>true</generateId> <charset>UTF-8</charset> <durable>true</durable> <deliveryMode>PERSISTENT</deliveryMode> </appender> <!--输出到控制台--><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!--输出到文件--><!-- 按照每天生成日志文件 --><appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/${log.file}</file><rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"><!--日志文件输出的文件名,如果文件名为.zip结尾,则归档时支持自动压缩--><fileNamePattern>${log.path}/%d{yyyy/MM}/${log.file}.%i.zip</fileNamePattern><!--日志文件保留天数--><MaxHistory>30</MaxHistory><!-- 最多存储5GB日志 --><totalSizeCap>5GB</totalSizeCap><!-- 每个文件最大500MB --><maxFileSize>300MB</maxFileSize></rollingPolicy><encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 总开关 --><!-- 日志输出级别 --><root level="info"><!-- <appender-ref ref="console" /> --><appender-ref ref="file" /><appender-ref ref="stash-amqp" /></root> </configuration> - SpringBoot集成Elasticsearch
# 所属应用的yml文件配置elasticsearch信息 elasticsearch:protocol: httphostList: 10.225.225.225:9200 # elasticsearch集群-单节点connectTimeout: 5000socketTimeout: 5000connectionRequestTimeout: 5000maxConnectNum: 10maxConnectPerRoute: 10username: # 帐号为空password: # 密码为空Elasticsearch配置类
package com.bierce;import java.io.IOException; import java.util.concurrent.TimeUnit; import org.apache.commons.lang3.StringUtils; import org.apache.http.HttpHost; import org.apache.http.auth.AuthScope; import org.apache.http.auth.UsernamePasswordCredentials; import org.apache.http.client.CredentialsProvider; import org.apache.http.client.config.RequestConfig.Builder; import org.apache.http.impl.client.BasicCredentialsProvider; import org.apache.http.impl.nio.client.HttpAsyncClientBuilder; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestClientBuilder; import org.elasticsearch.client.RestClientBuilder.HttpClientConfigCallback; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.client.sniff.ElasticsearchHostsSniffer; import org.elasticsearch.client.sniff.HostsSniffer; import org.elasticsearch.client.sniff.SniffOnFailureListener; import org.elasticsearch.client.sniff.Sniffer; import org.springframework.beans.factory.annotation.Value; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration;/*** * @ClassName: ElasticSearchConfiguration* @Description: ES配置类*/ @Configuration public class ElasticSearchConfiguration {@Value("${elasticsearch.protocol}") // 基于Http协议private String protocol;@Value("${elasticsearch.hostlist}") // 集群地址,如果有多个用“,”隔开private String hostList;@Value("${elasticsearch.connectTimeout}") // 连接超时时间private int connectTimeout;@Value("${elasticsearch.socketTimeout}") // Socket 连接超时时间private int socketTimeout;@Value("${elasticsearch.connectionRequestTimeout}") // 获取请求连接的超时时间private int connectionRequestTimeout;@Value("${elasticsearch.maxConnectNum}") // 最大连接数private int maxConnectNum;@Value("${elasticsearch.maxConnectPerRoute}") // 最大路由连接数private int maxConnectPerRoute;@Value("${elasticsearch.username:}")private String username;@Value("${elasticsearch.password:}")private String password;// 配置restHighLevelClient,// 当Spring容器关闭时,应该调用RestHighLevelClient类的close方法来执行清理工作@Bean(destroyMethod="close")public RestHighLevelClient restHighLevelClient() { String[] split = hostList.split(",");HttpHost[] httphostArray = new HttpHost[split.length];SniffOnFailureListener sniffOnFailureListener = new SniffOnFailureListener();//获取集群地址进行ip和端口后放入数组for(int i=0; i<split.length; i++) {String hostName = split[i];httphostArray[i] = new HttpHost(hostName.split(":")[0], Integer.parseInt(hostName.split(":")[1]), protocol);}// 构建连接对象// 为RestClient 实例设置故障监听器RestClientBuilder builder = RestClient.builder(httphostArray).setFailureListener(sniffOnFailureListener);// 异步连接延时配置builder.setRequestConfigCallback(new RestClientBuilder.RequestConfigCallback() {@Overridepublic Builder customizeRequestConfig(Builder requestConfigBuilder) {requestConfigBuilder.setConnectTimeout(connectTimeout);requestConfigBuilder.setSocketTimeout(socketTimeout);requestConfigBuilder.setConnectionRequestTimeout(connectionRequestTimeout);return requestConfigBuilder;}});// 连接认证CredentialsProvider credentialsProvider = new BasicCredentialsProvider();if( StringUtils.isNotBlank( username ) && StringUtils.isNotBlank(password )) {credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));}// 异步连接数配置builder.setHttpClientConfigCallback(new HttpClientConfigCallback() {@Overridepublic HttpAsyncClientBuilder customizeHttpClient(HttpAsyncClientBuilder httpClientBuilder) {httpClientBuilder.setMaxConnTotal(maxConnectNum);httpClientBuilder.setMaxConnPerRoute(maxConnectPerRoute);// 设置帐号密码if(credentialsProvider != null && StringUtils.isNotBlank( username ) && StringUtils.isNotBlank(password )) {httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);}return httpClientBuilder;}});RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);RestClient restClient = restHighLevelClient.getLowLevelClient();HostsSniffer hostsSniffer = new ElasticsearchHostsSniffer(restClient,ElasticsearchHostsSniffer.DEFAULT_SNIFF_REQUEST_TIMEOUT,ElasticsearchHostsSniffer.Scheme.HTTP);try {/* 故障后嗅探,不仅意味着每次故障后会更新节点,也会添加普通计划外的嗅探行为,* 默认情况是故障之后1分钟后,假设节点将恢复正常,那么我们希望尽可能快的获知。* 如上所述,周期可以通过 `setSniffAfterFailureDelayMillis` * 方法在创建 Sniffer 实例时进行自定义设置。需要注意的是,当没有启用故障监听时,* 这最后一个配置参数不会生效 */Sniffer sniffer = Sniffer.builder(restClient).setSniffAfterFailureDelayMillis(30000).setHostsSniffer(hostsSniffer).build();// 将嗅探器关联到嗅探故障监听器上sniffOnFailureListener.setSniffer(sniffer); sniffer.close();} catch (IOException e) {e.printStackTrace();}return restHighLevelClient;} } - 通过ES提供的API搜索相关数据
package com.bierce;/*** * @ClassName: UserVisitInfo* @Description: 用戶访问系统相关信息类**/ public class UserVisitInfo {private String dayOfWeek; // 星期几private Long docCount; //访问次数public UserVisitInfo() {}public UserVisitInfo(String dayOfWeek, Long docCount) {super();this.dayOfWeek = dayOfWeek;this.docCount = docCount;}public String getDayOfWeek() {return dayOfWeek;}public void setDayOfWeek(String dayOfWeek) {this.dayOfWeek = dayOfWeek;}public Long getDocCount() {return docCount;}public void setDocCount(Long docCount) {this.docCount = docCount;}@Overridepublic String toString() {return "UserVisitInfo [dayOfWeek=" + dayOfWeek + ", docCount=" + docCount + "]";} }package com.bierce;import java.util.ArrayList; import java.util.List; import com.bierce.UserVisitInfo; import org.elasticsearch.action.search.SearchResponse; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.index.query.QueryBuilder; import org.elasticsearch.index.query.QueryBuilders; import org.elasticsearch.script.Script; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.Aggregations; import org.elasticsearch.search.aggregations.bucket.histogram.Histogram; import org.elasticsearch.search.aggregations.bucket.histogram.HistogramAggregationBuilder; import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service;/*** * @ClassName: VisitUserCountSearchTemplate* @Description: 获取用户不同周期内活跃度**/ @Service public class VisitUserCountSearchTemplate {private static final String INDEX_PREFIX = "user-visit-";@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** * @Title: getUserActivityInfo* @Description: 获取用户访问系统活跃度* @param startDate* @param endDate* @return*/public List<UserVisitInfo> getUserActivityInfo(String startDate, String endDate) {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.size(0);searchSourceBuilder.query(QueryBuilders.matchAllQuery());// 设置聚合查询相关參數String aggregationName = "timeslice";String rangeField = "@timestamp";String termField = "keyword";Script script = new Script("doc['@timestamp'].value.dayOfWeek");String[] igonredAppCode = {"AMQP", "Test"}; QueryBuilder timeQueryBuilder = QueryBuilders.boolQuery().must(QueryBuilders.rangeQuery(rangeField).gte(startDate).lte(endDate)).mustNot(QueryBuilders.termsQuery(termField, igonredAppCode)).filter(QueryBuilders.existsQuery(termField));// 按照星期几搜索对应数据HistogramAggregationBuilder dayOfWeekAggregationBuilder = AggregationBuilders.histogram(aggregationName).script(script).interval(1).extendedBounds(1, 7);searchSourceBuilder.query(timeQueryBuilder);searchSourceBuilder.aggregation(dayOfWeekAggregationBuilder); SearchResponse searchResponse = ElasticsearchUtils.buildSearchSource(INDEX_PREFIX + "*", searchSourceBuilder, client); List<UserVisitInfo> userActivityInfoList = new ArrayList<>();Aggregations aggregations = searchResponse.getAggregations();Histogram dayOfWeekHistogram = aggregations.get(aggregationName);List<? extends Histogram.Bucket> buckets = dayOfWeekHistogram.getBuckets();for(Histogram.Bucket bucket: buckets) {String dayOfWeek = bucket.getKeyAsString();long docCount = bucket.getDocCount();UserVisitInfo item = new UserVisitInfo(dayOfWeek, docCount);userActivityInfoList.add(item);}return userActivityInfoList;} } - 将数据返回给前台进行页面渲染,最终实现的效果