Redis八股
Redis 相关基础概念(面试问)
什么是redis
基于内存的数据库,读写速度快,常用于缓存,分布式锁等场景
Redis(Remote Dictionary Server)的本质是一种非关系型的键值数据库,更具体地说,它是一种数据结构服务器。与传统的键值存储不同,Redis不仅限于存储简单的键值对,还提供了丰富多样的数据结构和功能,使其成为一个非常灵活且功能全面的存储解决方案。

为什么用 Redis 作为 MySQL 的缓存?
简答:主要是因为 Redis 具备「高性能」和「高并发」两种特性。
高性能(能提升性能,基于内存,直接在内存中操作
假如用户第一次访问 MySQL 中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据缓存在 Redis 中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了,操作 Redis 缓存就是直接操作内存,所以速度相当快(redis基于内存,读写速度快)
高并发(内存操作的低延迟,减少对数据库的直接访问,提高并发
单台设备的 Redis 的 QPS(Query Per Second,每秒钟处理完请求的次数) 是 MySQL 的 10 倍,Redis 单机的 QPS 能轻松破 10w,而 MySQL 单机的 QPS 很难破 1w。
所以,直接访问 Redis 能够承受的请求是远远大于直接访问 MySQL 的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
Redis 和 Memcached 有什么区别?
(redis支持的数据类型更丰富,支持持久化【保证重启时,数据不丢失–AOF/RDB/混合】,可扩展性和高可用(支持主从复制和集群部署

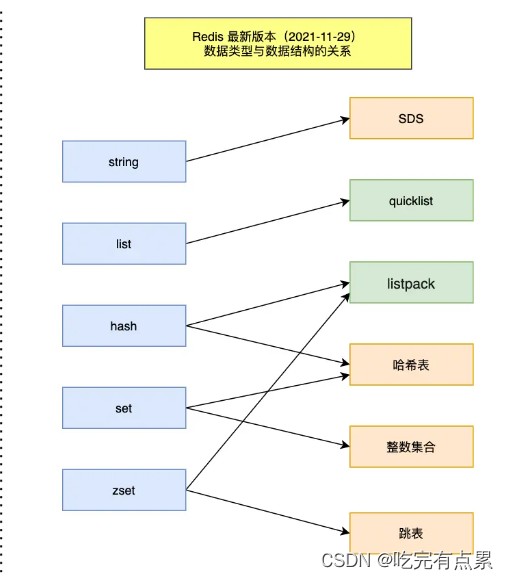
Redis 数据类型(抽象数据模型,数据结构是实现数据类型的具体方式

各自应用场景

五种常见的 Redis 数据类型是怎么实现?
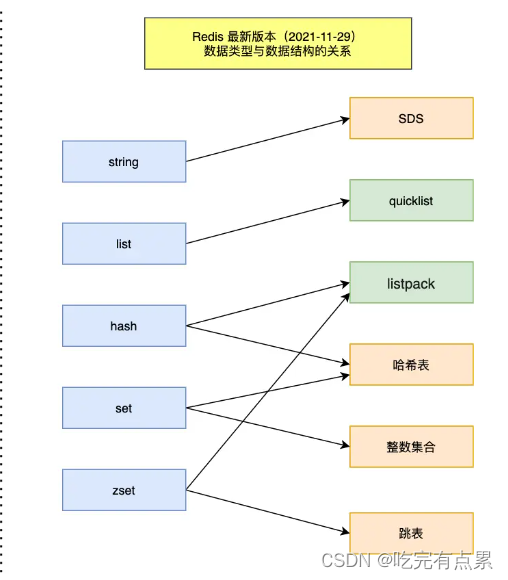
String
String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value其实不仅是字符串, 也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M
字符串对象的内部编码(encoding)有 3 种 :int、raw和 embstr
String 类型的底层的数据结构实现主要是 int 和 SDS(简单动态字符串)
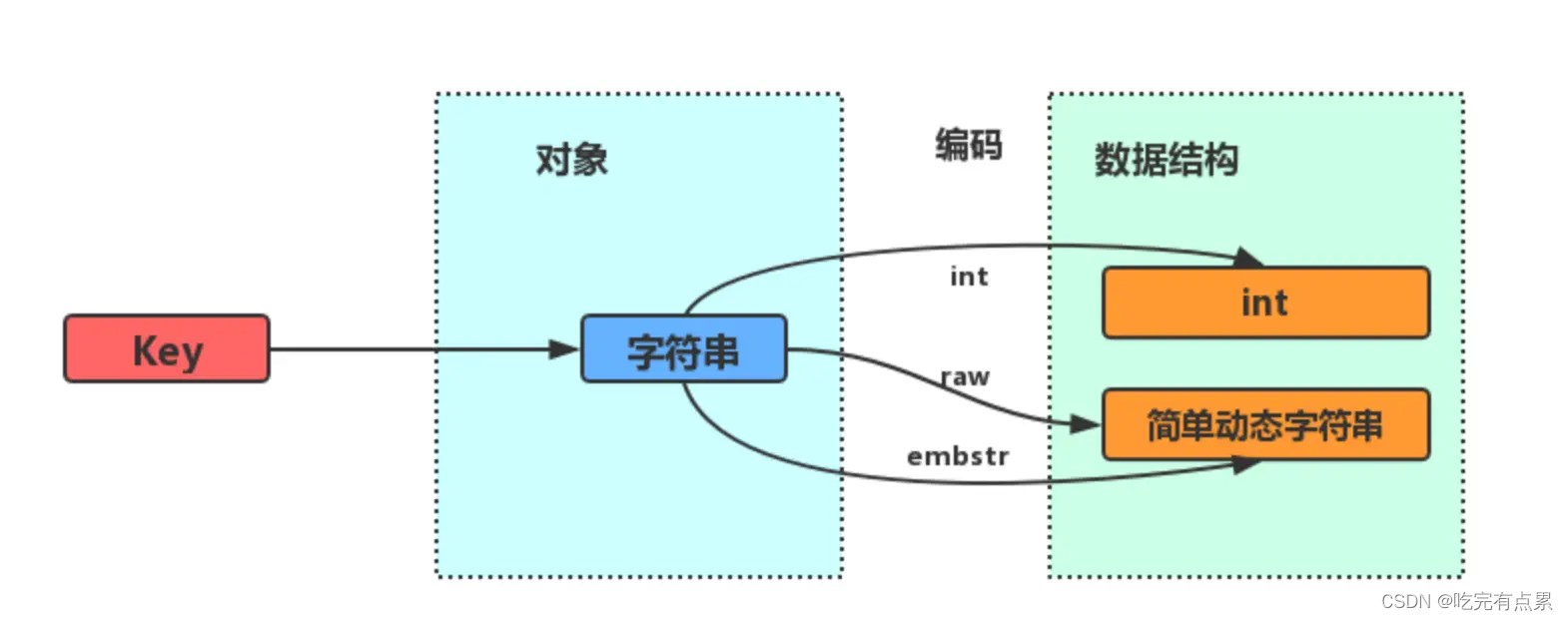
Hash,List,Set,Zset
BitMap,HyperLogLog,GEO,Stream
Redis 数据结构(面试常问)
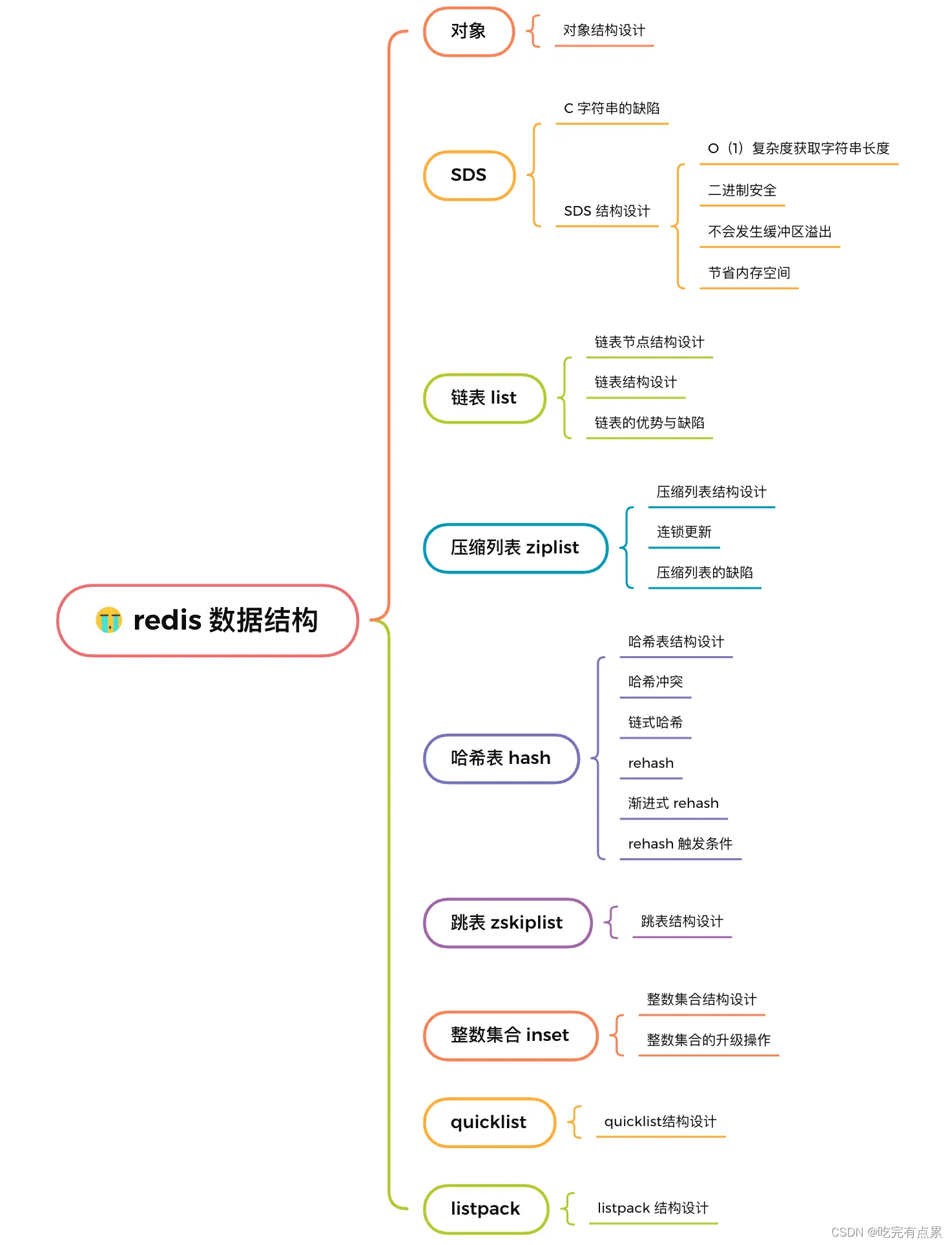
*
Redis 是怎样实现键值对(key-value)数据库
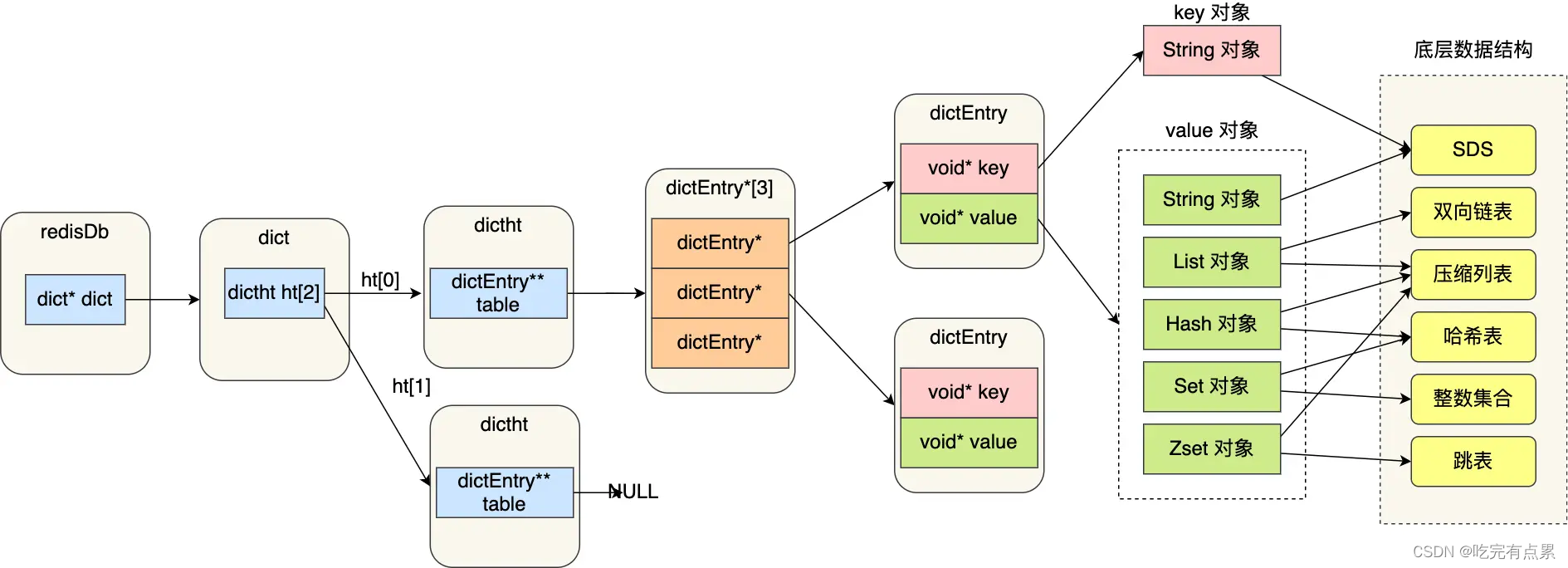
SDS
Redis 是用 C 语言实现的,但是它没有直接使用 C 语言的 char* 字符数组来实现字符串,而是自己封装了一个名为简单动态字符串(simple dynamic string,SDS) 的数据结构来表示字符串,也就是 Redis 的 String 数据类型的底层数据结构是 SDS。
为什么不用char*—有缺陷
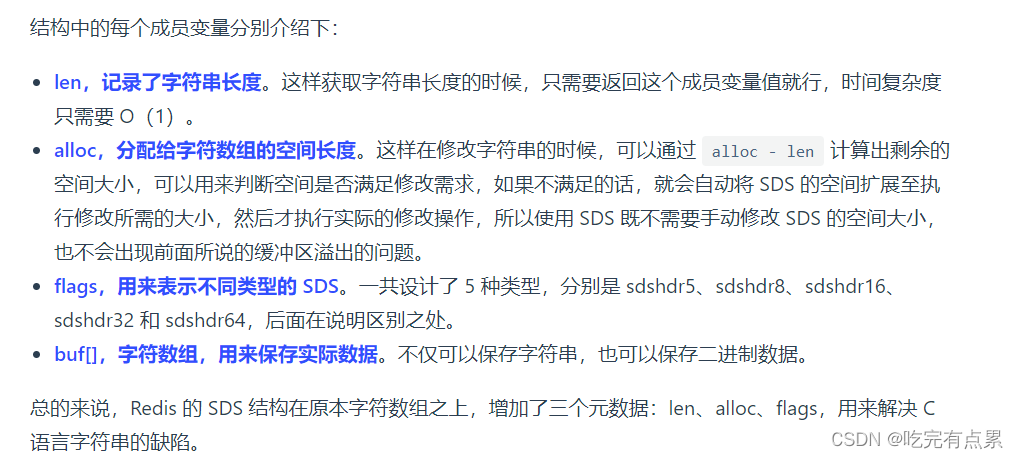
- 获取字符串长度的时间复杂度为 O(N); ----SDS改进为O(1)(SDS 结构因为加入了 len 成员变量
- 字符串的结尾是以 “\0” 字符标识,字符串里面不能包含有 “\0”字符,因此不能保存二进制数据;
- 字符串操作函数不高效且不安全,比如有缓冲区溢出的风险,有可能会造成程序运行终止;(SDS通过alloc改善
链表
 ### 压缩列表
### 压缩列表


Redis 是单线程吗?
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的
但是,Redis 程序并不是单线程的,Redis 在启动的时候,是**会启动后台线程(BIO)**的
为「关闭文件、AOF 刷盘、释放内存」这些任务创建单独的线程来处理,是因为这些任务的操作都是很耗时的,如果把这些任务都放在主线程来处理,那么 Redis 主线程就很容易发生阻塞,这样就无法处理后续的请求了
Redis 采用单线程为什么还这么快?
1.在内存中完成,CPU不是瓶颈(CPU是瓶颈,才会考虑多线程)
2.避免了多线程竞争
3.I/O多路复用(I/O多路复用是一种允许单个进程或线程同时处理多个I/O操作的技术
I/O多路复用的核心思想是使用一个或多个系统调用来监视多个I/O通道(如文件描述符),并在I/O通道准备好进行读写操作时通知应用程序。这样,应用程序就可以在单个线程中处理多个I/O请求,而无需为每个I/O请求创建单独的线程或进程。(意思就是监听,准备好开始读写了再通知线程来处理)

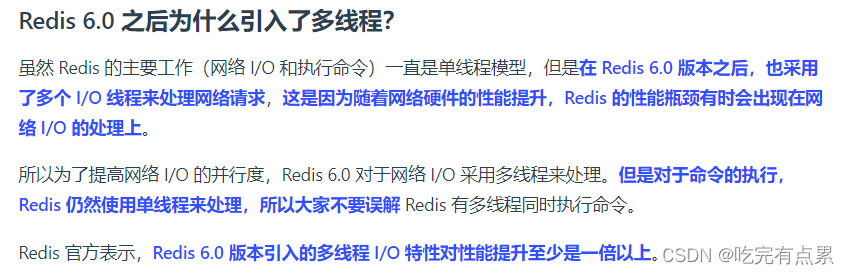
网络硬件的提升–导致瓶颈可能出现再网络IO上,所以网络I/O采取多线程
命令的执行仍然是单线程
Redis 持久化(AOF,RDB,混合持久化
如何实现数据不丢失
为了保证内存中的数据不会丢失,Redis 实现了数据持久化的机制

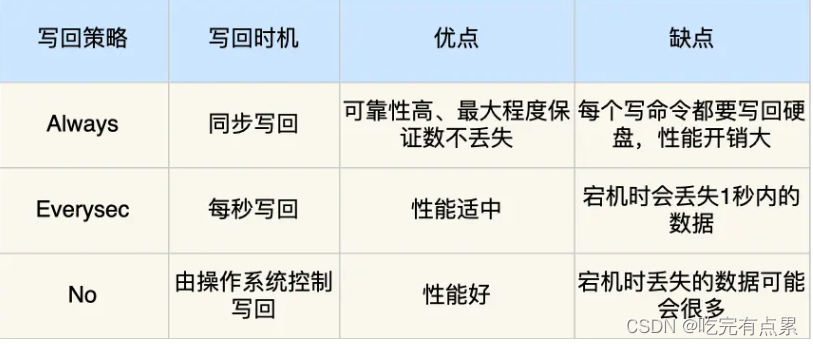
Redis 共有三种数据持久化的方式:
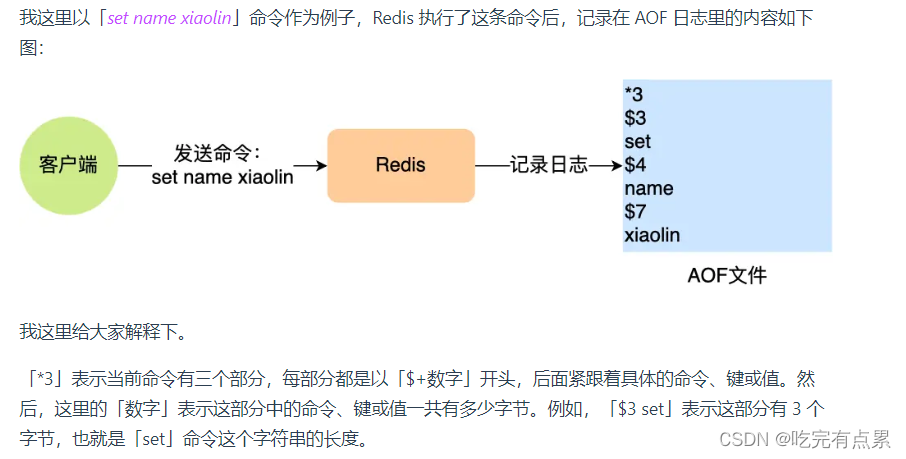
AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里;
RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RBD 的优点
AOF 日志(append only file)

RDB(Redis Database)快照

Redis 的快照是全量快照,也就是说每次执行快照,都是把内存中的「所有数据」都记录到磁盘中。所以执行快照是一个比较重的操作,如果频率太频繁,可能会对 Redis 性能产生影响。如果频率太低,服务器故障时,丢失的数据会更多。
RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
混合持久化方式
RDB 优点是数据恢复速度快,但是快照的频率不好把握。频率太低,丢失的数据就会比较多,频率太高,就会影响性能。
AOF 优点是丢失数据少,但是数据恢复不快。(因为AOF记录的是命令。恢复相当于得一条条执行命令)
为了集成了两者的优点, Redis 4.0 提出了混合使用 AOF 日志和内存快照,也叫混合持久化,既保证了 Redis 重启速度,又降低数据丢失风险。
Redis 集群
Redis 如何实现服务高可用?
(服务高可用(High Availability, HA)是指通过设计和实施特定的技术手段,确保服务能够在面对各种故障和异常情况时,仍然能够持续运行,从而提供几乎不间断的服务。高可用性是衡量服务稳定性和可靠性的重要指标。)—个人理解 就是抗风险能力 面对各种故障时,仍然能正常
主从复制是 Redis 高可用服务的最基础的保证,实现方案就是将从前的一台 Redis 服务器,同步数据到多台从 Redis 服务器上,即一主多从的模式,且主从服务器之间采用的是「读写分离」的方式。
具体来说,在主从服务器命令传播阶段,主服务器收到新的写命令后,会发送给从服务器。但是,主服务器并不会等到从服务器实际执行完命令后,再把结果返回给客户端,而是主服务器自己在本地执行完命令后,就会向客户端返回结果了。如果从服务器还没有执行主服务器同步过来的命令,主从服务器间的数据就不一致了。
所以,主从复制 无法实现强一致性保证(主从数据时时刻刻保持一致),数据不一致是难以避免的。
在使用 Redis 主从服务的时候,会有一个问题,就是当 Redis 的主从服务器出现故障宕机时,需要手动进行恢复。
为了解决这个问题,Redis 增加了哨兵模式(Redis Sentinel),因为哨兵模式做到了可以监控主从服务器,并且提供主从节点故障转移的功能。
什么是哨兵模式
一组组件(哨兵)负责监控其他组件的状态,并在检测到问题时采取措施以维护系统的稳定性和可用性。
什么是redis切片集群
Redis 切片集群(Redis Cluster)是一种分布式的数据库解决方案,用于处理大规模数据集和高并发访问的场景。当单台服务器的内存不足以存储所有的缓存数据,或者单台服务器的处理能力无法满足高并发请求时,Redis Cluster 提供了一种水平扩展的方法
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 **Redis 切片集群(Redis Cluster )**方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和节点之间的映射关系。
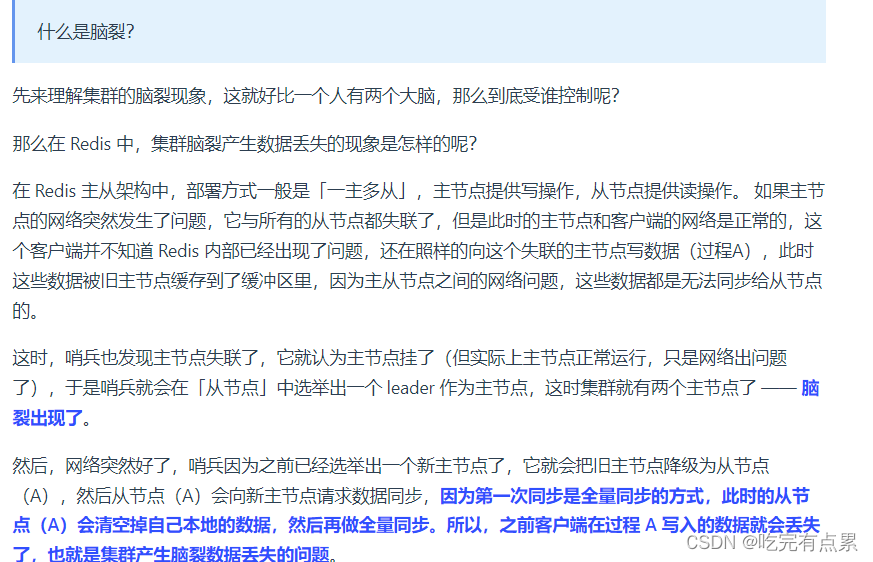
集群脑裂导致数据丢失怎么办?
简言之就是:由于网络问题,集群节点之间失去联系。主从数据不同步;重新平衡选举,产生两个主服务。等网络恢复,旧主节点会降级为从节点,再与新主节点进行同步复制的时候,由于会从节点会清空自己的缓冲区,所以导致之前客户端写入的数据丢失了。
什么是脑裂
解决方案
设置一个阈值:主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的写请求了。(断联的从库多了或从库复制主库的延迟高了都不准写了)
当主节点发现从节点下线或者通信超时的总数量小于阈值时,那么禁止主节点进行写数据,直接把错误返回给客户端。
Redis 是可以对 key 设置过期时间的,因此需要有相应的机制将已过期的键值对删除,而做这个工作的就是过期键值删除策略。
「过期字典」保存了数据库中所有 key 的过期时间

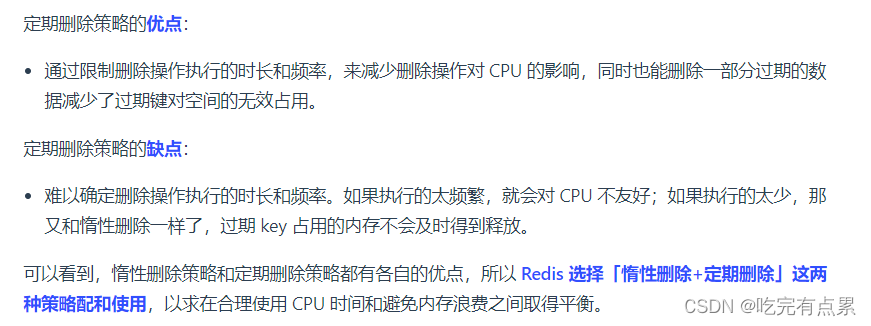
Redis 使用的过期删除策略是「惰性删除+定期删除」这两种策略配和使用。
惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。

定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。
在 Redis 的运行内存达到了某个阀值,就会触发内存淘汰机制,这个阀值就是我们设置的最大运行内存,此值在 Redis 的配置文件中可以找到,配置项为 maxmemory。
Redis 过期删除与淘汰
Redis 使用的过期删除策略是什么?
过期删除策略是「惰性删除+定期删除」这两种策略配和使用
惰性删除(我懒,不主动删除,每次都是等你需要这个key了 我在检查它过没过期
惰性删除策略的做法是,不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。
定期删除(每隔一段时间随机抽查
定期删除策略的做法是,每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。、
Redis 内存满了,会发生什么?-> redis内存淘汰策略
在 Redis 的运行内存达到了某个阀值,就会触发内存淘汰机制,这个阀值就是我们设置的最大运行内存,此值在 Redis 的配置文件中可以找到,配置项为 maxmemory。

LRU 算法和 LFU 算法有什么区别?
LRU( Least Recently Used ) 最近最少使用
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。
当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值(此值可配置),然后淘汰最久没有使用的那个。
但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。
LFU ( Least Frequently Used) 最近最不常用的
LFU 算法是根据数据访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU 算法相比于 LRU 算法的实现,多记录了「数据的访问频次」的信息
Redis 缓存设计(重点中的重点)
缓存雪崩(同一时间大量缓存失效了,全部都去访问数据库,给数据库整崩了)
当大量缓存数据在同一时间过期(失效)时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题
如何解决
同一时间大量缓存失效了
解法1:把缓存失效时间随机打散
解法2:设置缓存不过期(通过后台服务更新缓存数据)

缓存击穿(某个热点数据的缓存过期了 一堆人要访问它 ,只有问数据库,数据库被高并发请求给干崩了)
我们的业务通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为热点数据。
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
如何解决
一堆线程都要访问一个数据 解法1:加锁,同一时间只允许一个线程请求
解法2:不让热点数据过期

缓存穿透(数据库中根本没有要找的数据)
当发生缓存雪崩或击穿时,数据库中还是保存了应用要访问的数据,一旦缓存恢复相对应的数据,就可以减轻数据库的压力,而缓存穿透就不一样了。
当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题
如何解决
1.对非法请求的限制
2.设置空值或默认值
3.使用布隆过滤器快速检查,避免查询数据库
(布隆过滤器(Bloom Filter)是一种空间效率很高的概率型数据结构,用于判断一个元素是否在一个集合中
布隆过滤器在实际应用中非常广泛,特别是在大数据和分布式系统中,它可以显著减少不必要的磁盘I/O操作,提高系统性能。然而,由于其概率型的特点,布隆过滤器并不适用于需要完全准确的场合。

如何动态缓存热点数据

数据库和缓存如何保证一致性?
先删除缓存,再更新数据库,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题
而先更新数据库,再删缓存


缓存更新策略
Cache Aside(旁路缓存)策略
应用程序直接交互
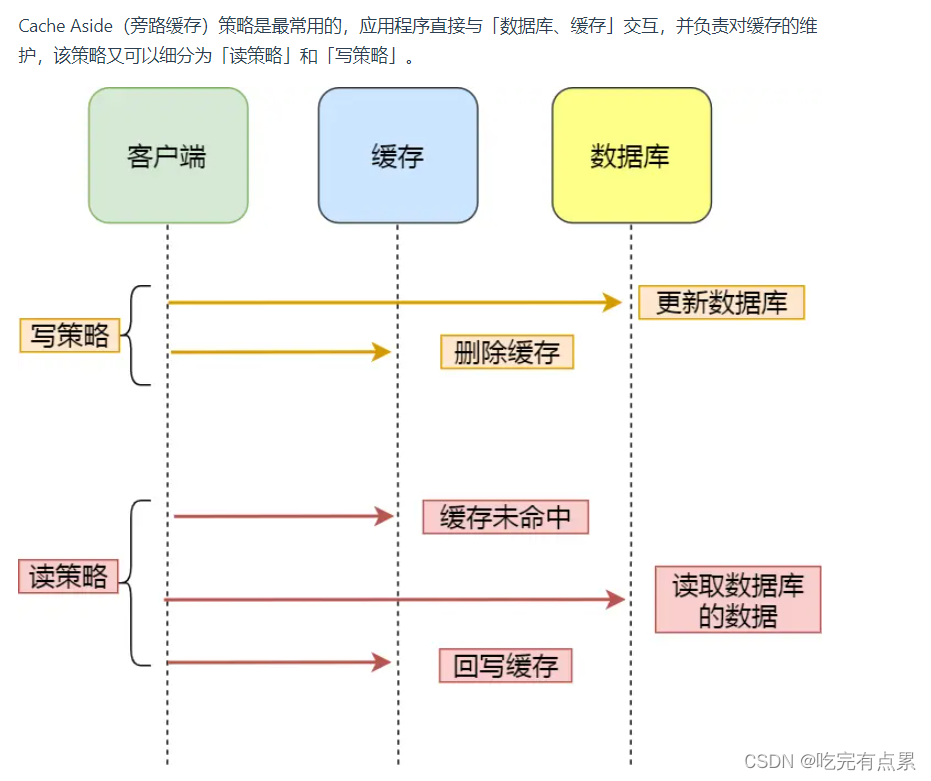
注意,写策略的步骤的顺序不能倒过来,即不能先删除缓存再更新数据库,原因是在「读+写」并发的时候,会出现缓存和数据库的数据不一致性的问题。
Cache Aside 策略适合读多写少的场景,不适合写多的场景
如何保证缓存和数据库数据的一致性?
无论是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题,当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象
----------->引出Cache Aside 策略,中文是叫旁路缓存策略。
不更新缓存,而是删除缓存中的数据。然后,到读取数据时,发现缓存中没了数据之后,再从数据库中读取数据,更新到缓存中。