机器学习——随机森林
随机森林
1、集成学习方法
通过构造多个模型组合来解决单一的问题。它的原理是生成多个分类器/模型,各自独立的学习和做出预测。这些预测最后会结合成组合预测,因此优于任何一个单分类得到的预测。
2、什么是随机森林?
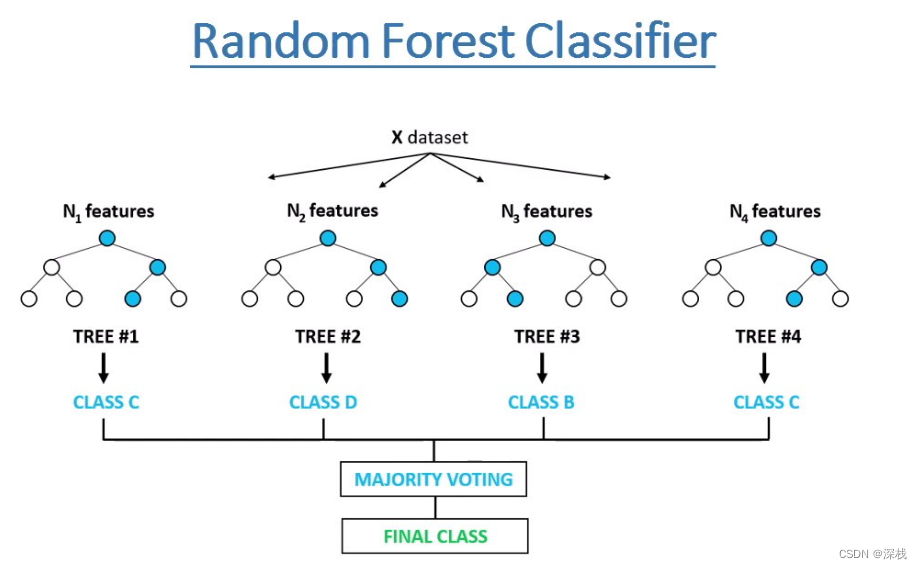
随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机:设训练集有N个样本,M个特征
1)训练集随机 (采用bootstrap,即采用随机有放回抽样方法),从训练集里随机有放回的抽取N个样本
2)特征随机生成(从M个特征中随机抽取m个特征, M >> m)
森林:指由多棵决策树构成
3、API调用
在sklearn中,提供了随机森林的API,如下
sklearn.ensemble.RandomForestClassifier(n_estimator= 10, criterion='gini', max_depth=None, bootstrap = True,random_state =None, max_features='auto')
"""
n_estimator:预估器个数,即决策树数量
criterion:分割特征的测量方法,默认为基尼系数
max_depth:最大深度,即分类层数
bootstrap:默认为True,是否在构建树的时候有放回抽样
max_features:每个决策树的最大特征数量,如果设置为auto,则m=sqrt(M),M表示样本数量
"""
4、随机森林实例–预测泰坦尼克号生存乘客生存率
参数介绍:pclass表示客舱等级(间接反映乘客阶级),survived表示是否存活,后面依次表示姓名,年龄,乘客登船港口,家庭住址,房间号,船票1号码,boat表示是否登上救生艇,登上了则显示对应救生艇编号,空值表示没有登上,sex为性别
import pandas as pd
data = pd.read_csv(r'E:\Python_learning\py基础\machine_learning\titanic\titanic.csv')
# 筛选关键因素

# 选取特征列
features = data[['pclass','age','boat','sex']]
target = data['survived']
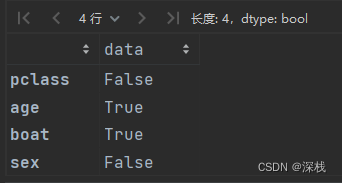
# 先查看有无缺失值
pd.isnull(features).any() # 发现年龄、是否乘坐救生舱有空值
# 填补空缺值
features.fillna({'age':features['age'].mean()},inplace=True)
# 转换为字典
features = features.to_dict(orient='records')
# 使用字典特征抽取,转化成one-hot编码
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,target)
transfer = DictVectorizer(sparse=False)
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
estimator = RandomForestClassifier()
para_dict={"n_estimators":[120,200,300,500,800,1200], 'max_depth':[5,8,15,25,30]}
estimator = GridSearchCV(estimator, param_grid=para_dict, cv=4)
estimator.fit(x_train,y_train)
y_predict = estimator.predict(x_test)
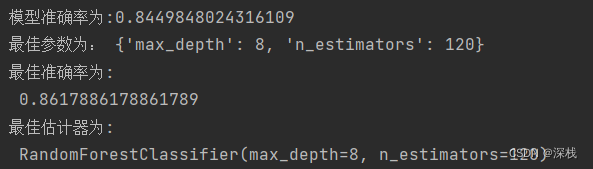
print(f"模型准确率为:{estimator.score(x_test, y_test)}")
print("最佳参数为:", estimator.best_params_)
print("最佳准确率为:\n", estimator.best_score_)
print("最佳估计器为:\n", estimator.best_estimator_)
print("交叉验证结果:\n", estimator.cv_results_)