【RAG KG】GraphRAG开源:查询聚焦摘要的图RAG方法
前言
传统的 RAG 方法在处理针对整个文本语料库的全局性问题时存在不足,例如查询:“数据中的前 5 个主题是什么?”

对于此类问题,是因为这类问题本质上是查询聚焦的摘要(Query-Focused Summarization, QFS)任务,而不是传统的显式检索任务。
Graph RAG 通过使用 LLM 构建基于图的文本索引,从源文档构建知识图谱。通过构建知识图谱,能够将复杂的、大规模文本数据集转化为易于理解和操作的知识结构,以便更好地理解实体(如人物、地点、机构等)之间的相互关系。
一、方法
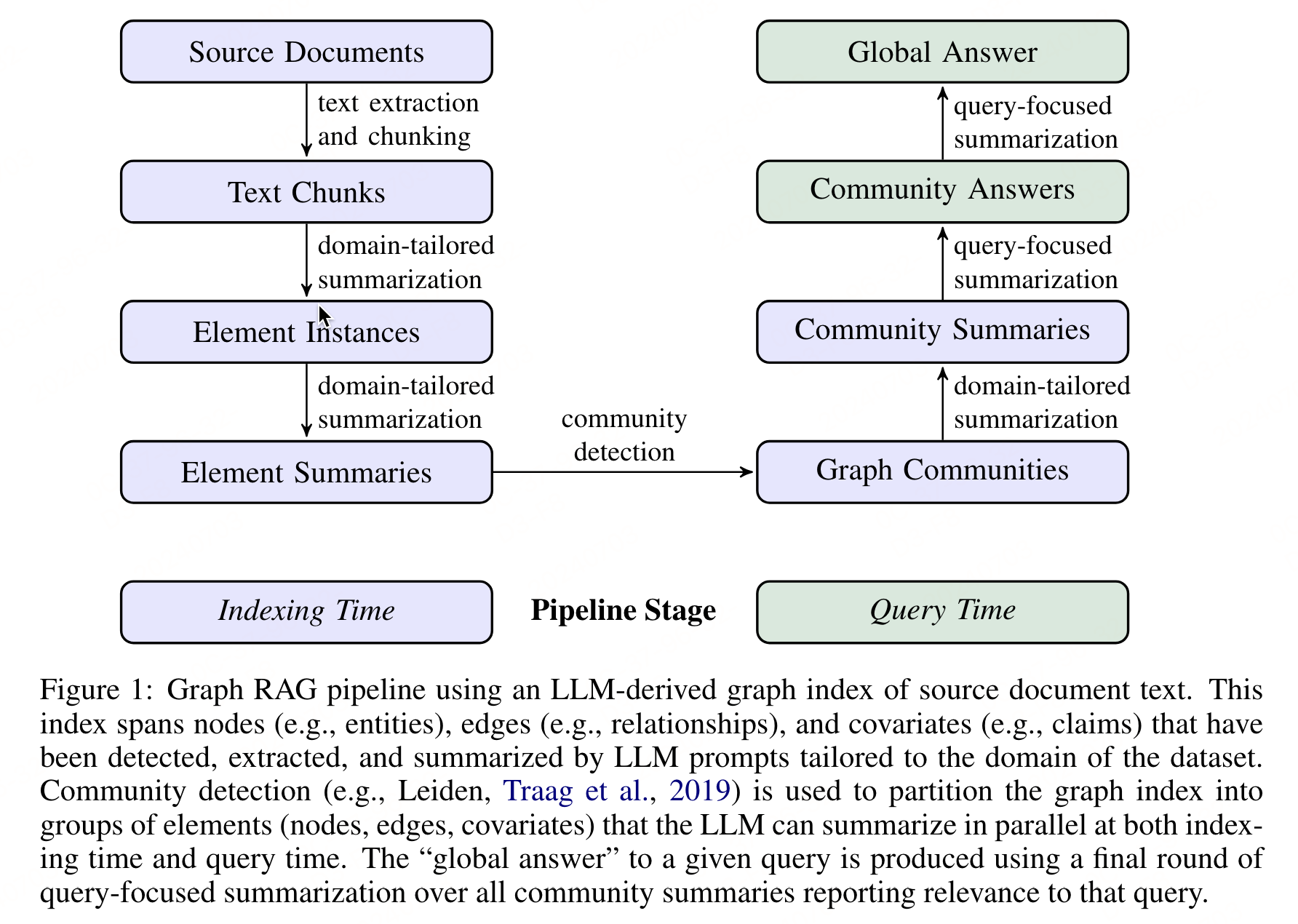
1.1 源文档分块
该步骤是 Graph RAG 流程的基础,它决定了后续构建知识图谱和生成摘要的质量。主要需要考虑的就是源文档的分割粒度(《【RAG】Dense X Retrivel:合适的检索粒度对RAG的重要性(浅看命题粒度的定义及分解方法)》),需要决定输入文本从源文档中提取出来后,应该以何种粒度分割成文本块以供处理。这个决策会影响到后续步骤中 LLM 提取图索引元素的效率和效果。块大小的主要影响如下:
-
LLM 上下文窗口:文本块的长度会影响 LLM 调用的次数以及上下文窗口的召回率(recall)。较长的文本块可以减少对 LLM 的调用次数,但可能会因为更长的上下文而导致信息提取的召回率下降。
-
召回率与精度的平衡:在提取过程中,需要平衡召回率和精度。较长的文本块可能提高召回率,但可能会牺牲精度。
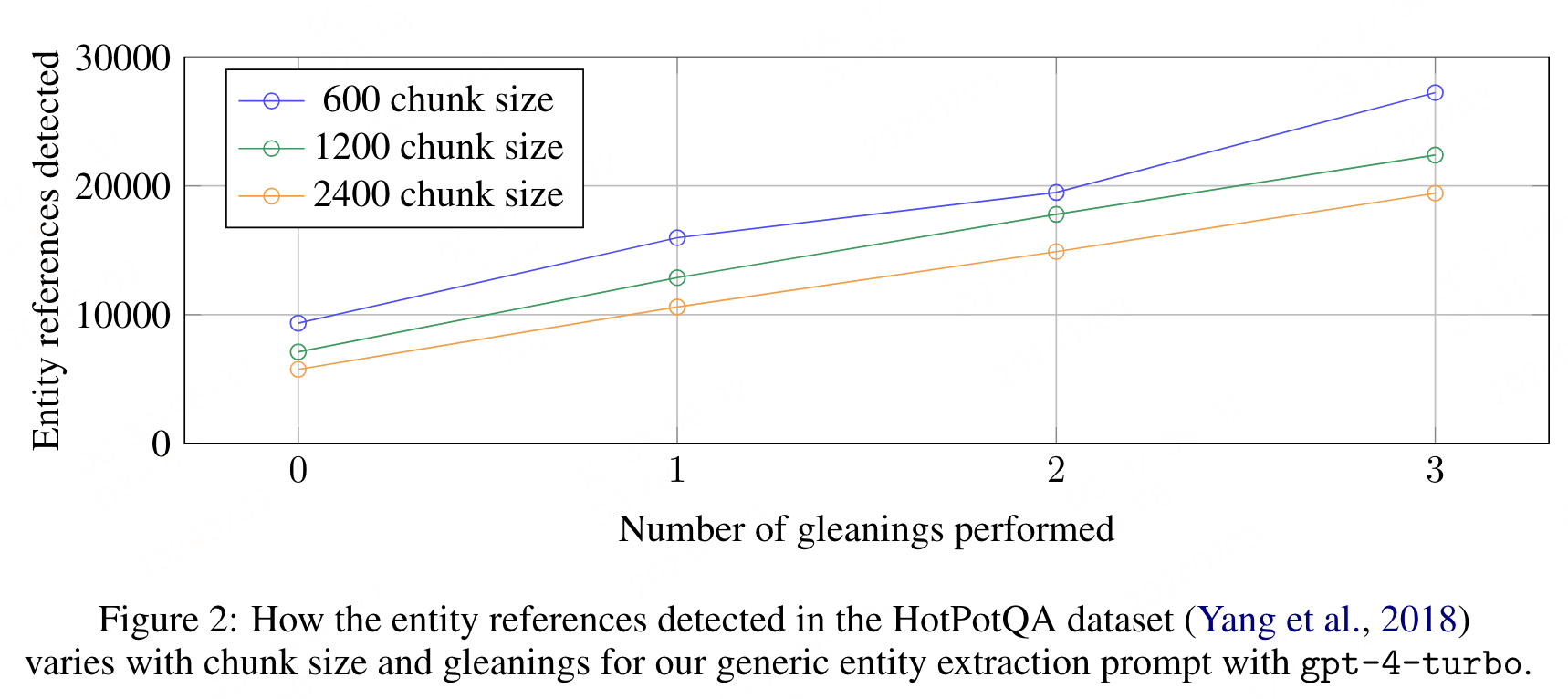
上图展示了在 HotPotQA 数据集上,使用不同大小的文本块(600、1200、2400 tokens)和 通用实体提取提示(entity extraction prompt)与 gpt-4-turbo 进行单次提取时,检测到的实体引用数量的变化。结果表明,使用较小的文本块(600 tokens)能够提取出几乎是使用较大文本块(2400 tokens)两倍的实体引用。
1.2 信息抽取(实例提取)
该步骤是构建图索引的关键环节,它确保了从文本数据中提取出有用的结构化信息(KG)(识别并提取源文本中每个文本块的图节点和边的实例),为后续的社区检测和摘要生成打下了基础。
方法:
-
KG构建:使用 LLM + prompt 来识别上一步得到的文本块中的所有实体,包括它们的名称、类型和描述。然后,识别实体之间的关系,包括源实体、目标实体以及关系的描述。
-
附加协变量提取:除了实体和关系之外,还可以使用次级提取提示来提取与提取的节点实例相关的附加协变量(covariates)。默认的协变量提示旨在提取与检测到的实体相关的声明,包括主题、对象、类型、描述、源文本跨度以及开始和结束日期。
-
漏提取兜底:为了平衡效率和质量的需要,使用多轮“gleanings”来鼓励 LLM 检测在先前提取轮次中可能遗漏的任何实体。这是一个多阶段过程,首先要求 LLM 评估是否所有实体都已被提取,如果 LLM 响应有遗漏,则使用一个提示来鼓励 LLM 提取这些遗漏的实体。

上图中每个圆圈代表一个实体(例如,一个人、一个地点或一个组织),实体大小表示该实体具有的关系数量,颜色表示相似实体的分组。颜色分区是一种建立在图形结构之上的自下而上的聚类方法,它使我们能够回答不同抽象层次的问题。
1.3 实例提取->实例摘要
使用 LLM 提取实体、关系和声明的描述,这本身就是一种抽象摘要的形式。LLM 需要能够创建独立有意义的摘要,这些摘要可能暗示了文本中未明确陈述的概念(例如,隐含的关系)。通过摘要化过程,能够将大量文本信息浓缩成更加简洁、易于处理的格式,这有助于提高后续处理步骤的效率。并且,在处理长文本时,实例摘要有助于避免信息在大型语言模型的长上下文中被忽略或丢失的问题。
1.4 实例摘要->图社区
图模型构建-同质无向加权图:将实例摘要阶段得到的信息构建成一个同质无向加权图。在这个图中,实体作为节点,它们之间的关系作为边。边的权重可以表示为检测到的关系实例的归一化计数,这有助于反映关系的强度或频率。
社区检测算法:
- 社区划分:使用社区检测算法将图划分为多个社区(communities)。这些社区由彼此之间联系更紧密的节点组成,相对于图中的其他节点,社区内部的节点之间的连接更为频繁。
- Leiden算法:文章中特别提到了使用 Leiden 算法进行社区检测,因为该算法能够有效地恢复大规模图的层次社区结构。Leiden 算法考虑了社区的模块化,能够提供不同层次的社区划分。
1.5 图社区到社区摘要
为每个社区创建报告式的摘要,这些摘要独立于其他社区,但共同构成了对整个数据集全局结构和语义的理解。社区摘要本身对于理解数据集的全局结构和语义非常有用,可以作为在没有具体问题时对整个语料库进行探索和理解的工具。
1.6 社区摘要到社区答案再到全局答案
- 准备社区摘要
随机分配:社区摘要被随机打乱并分成预定大小的块。这样做是为了保证相关信息分散在不同的上下文窗口中,而不是集中在一个窗口中,从而避免了信息的潜在丢失。 - 生成中间答案(Map社区答案)
- 并行生成:对于每个社区摘要块,LLM 被用来并行生成中间答案。同时,LLM 还被要求为生成的答案生成一个0到100之间的有用性得分,以指示生成的答案对目标问题的有用程度。
- 过滤:得分为0的答案将被过滤掉,因为它们对回答问题没有帮助。
- 汇总成全局答案(Reduce到全局答案)
- 排序和汇总:根据有用性得分,将中间社区答案按降序排序,并将它们逐步添加到一个新的上下文窗口中,直到达到令牌限制。
- 生成最终答案:当所有相关的部分答案都被考虑后,最终的上下文窗口被用来生成返回给用户的全局答案。
二、实验
原文使用了两个大规模数据集来验证Graph RAG方法的有效性:一个包含1669个文本块的播客转录数据集(约100万个token)和一个包含3197个文本块的新闻文章数据集(约170万个token)。相当于10本小说。
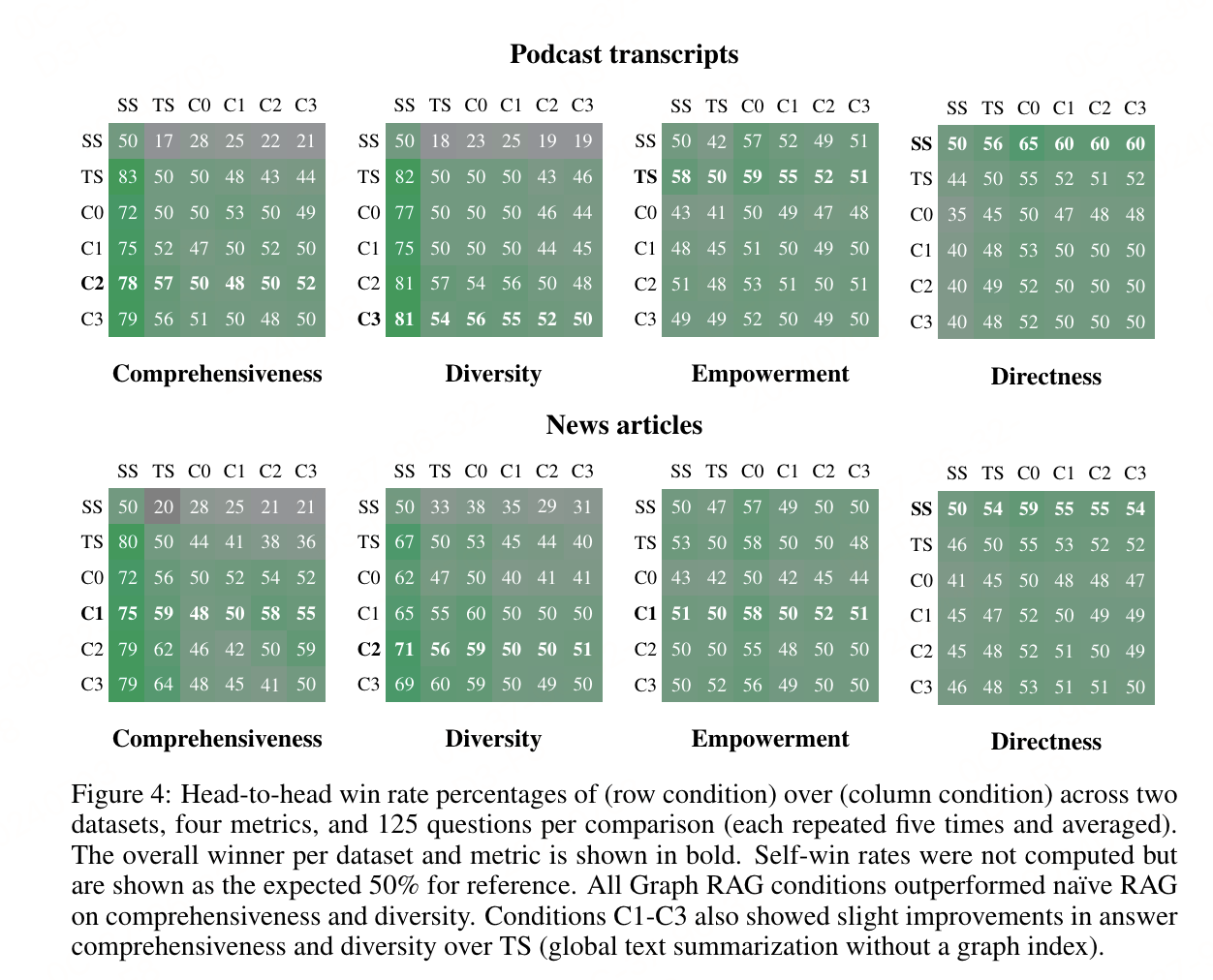
通过与naive RAG和全局文本摘要方法的比较,GraphRAG在全面性和多样性上优势明显,尤其是在使用8k tokens上下文窗口时,测试的最小上下文窗口大小(8k)在所有比较中普遍表现更好,尤其是在全面性上(平均胜率为58.1%),同时在多样性(平均胜率=52.4%)和授权性(平均胜率=51.3%)上与更大的上下文尺寸表现相当。
还有一个私有数据集上的实验,链接如下:
https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
参考文献
-
私有数据集实验:https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
-
paper:From Local to Global: A Graph RAG Approach to Query-Focused Summarization,https://arxiv.org/pdf/2404.16130
-
代码已开源:https://github.com/microsoft/graphrag