《基于 CDC、Spark Streaming、Kafka 实现患者指标采集》
📢 大家好,我是 【战神刘玉栋】,有10多年的研发经验,致力于前后端技术栈的知识沉淀和传播。 💗
🌻 CSDN入驻不久,希望大家多多支持,后续会继续提升文章质量,绝不滥竽充数,欢迎多多交流。👍
文章目录
- 写在前面的话
- 背景技术
- 发明目的
- 具体方案
- 包含模块
- 相关图示
- 方案特征
- 总结陈词

写在前面的话
本篇文章分享一下博主所在公司的患者指标采集的解决方案。
主要是基于CDC、Spark Streaming、Kafka实现,由于涉及公司隐私,内容主要以方案介绍为主,有需要探讨的可以留言。
好,让我们开始。
背景技术
在现行的业务系统中,目前为了获取患者的临床指标数据需要从许多的业务表进行关联查询数据,这样获取病人的临床数据无疑增大了数据库的压力,这样的检索效率不高,每次查询都要去关联查询非常多的表,通过长篇的SQL语法查询无疑是浪费了资源。并且对病人的临床数据没有进行整合,这样不能使病人的指标数据从另外一个维度去存储,这样对数据的挖掘和利用率并不高。因此数据集市这个层次产生,主要用于存储一定范围内医院的所有临床数据集合,信息不是从各个业务系统中简单抽取出来的,而是经过一系列加工、整理和汇总的过程。为了满足数据处理的需要,并对业务数据通过实时同步加工整合临床数据。
发明目的
该技术通过基于CDC、Spark Streaming、Kafka构建数据中心加工引擎为数据集市层的数据提供一个加工计算的过程。
1、 该技术也改变以往对数据的实时计算力比较差,对数据缓冲的效率不高,不能控制数据流速度问题,通过 Kafka具有高吞吐的分布式消息的缓存;
2、 以及使用Spark Streaming流式计算处理数据计算能力差的问题,使其整体的链路通道具体高可用、易扩展和精准计算的能力;
3、 同时解决了以往对在大量数据查询的情况,效率不高,性能不佳业务场景,自此发挥的重要的作用;
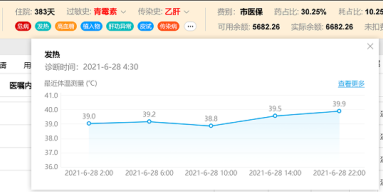
竞争优势主要是通过不断的对患者体征相关指标例如:发热标识、高血压标识、皮试标识、过敏标识、病重标识、危急值标识、输血不良反应标识、跌倒风险标识、药品不良反应标识、癌痛标识、肾功能异常标识、妊娠标识和输血史标识的数据进行根据不同的规则进行脚本计算,例如过敏标识,很多患者对阿莫西林等药物过敏和霉菌过敏等,在医生开药品时,可以根据过敏标识的二级内容,展示患者具体的过敏指标项是那些进行合理的开对应的药品以及接触物,数据加工引擎通过监听过往的病人诊病的历史记录信息,通过CDC监听对应的数据流,更具配置不同的业务表,获取历史的病人诊病信息,对过敏的信息进行捕捉和记录,回填到数据仓库患者标识维度的表中;发热标识会根据正常体温大于37.3℃小于38℃会展示发热低热标识、大于38.1℃小于39℃会展示发热中等热标识、大于39.1℃小于41℃会展示发热高热标识,大于41℃展示发热超高热标识,根据不同的温度状态我们的脚本,到针对医院不同的医疗数据进行一定的整合,将医疗数据进行多维度的挖掘,提高医疗数据从一个大数据仓库提取、加工得到有各种维护意义的患者医疗数据。以往的患者指标需要从跨越多个系统获取数据,这样无疑效率比较低,我们可以通过数据加工定制化的给其进行供数,并且可以多维度的展示患者多维度的数据,这样可以辅助临床医护人员快速对患者快速下诊断,直观看到患者的不同维度的指标数据,大大提高患者就诊速度。
具体方案
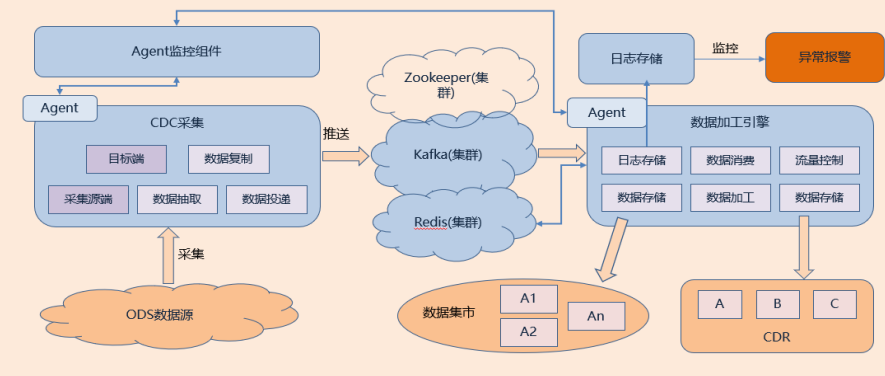
本方案以 CDC 整合 Spark Streaming 以及 Kafka 实现高可靠、高效实时、高扩展性的数据加工引擎实现数据的实时加工到数据集市中,主要包括如下步骤:
1、采集框架和消息中间件搭建:采用 CDC + Spark Streaming + Kafka 集群作为数据归档日志变动监听以及消息缓存核心组件,患者业务作为 Topic,不同患者标识业务模块作为消费组,采用消息对列发布订阅模式,不同规则作为消费的模块。
2、通过医护人员在对病人做一系列诊疗活动过程中,系统对医疗数据做存储时,CDC 对医疗数据进行实时的监听数据流。通过对数据流进行监听,对医疗数据进行不同的业务规则编写不同的脚本分析过滤,将患者预先定义好的各种患者标识的数据进行数据流的投递到 Kafka,进行数据的缓存,具有高吞吐量的分布式发布订阅消息系统,以容错的方式存储消息,生产者往队列里写消息,消费者从队列里获取消息执行预先定义的业务处理逻辑,一般在架构呈现起到解耦、削峰、异步处理的作用,这样保证数据的流可以实时的监听,对不同患者指标数据进行存储业务数据,方便医生能快速分析患者的病情。
3、通过数据中心加工引擎从 Kafka 中消费出数据流,在 Spark Streaming 流式计算引擎中,通过编写不同规则的脚本,对实时的数据链路进行计算,得到患者相关的临床指标信息以及其他业务指标信息,保证并发的效率,又可保证数据的准确性,这样才能可以使我们系统保持稳定的进行数据的批处理。
4、对执行对数据流的计算脚本进行全过程的日志记录,对异常的数据进行数据分析得出对应的报告,反馈给对应的负责人,保证数据中心加工引擎数据的完整性,高可用性,对异常数据进行监控,有异常信息,将通过消息通知到不同的责任人。
包含模块
一般大数据加工引擎的患者指标主要包含以下模块:
1、数据抽取模块
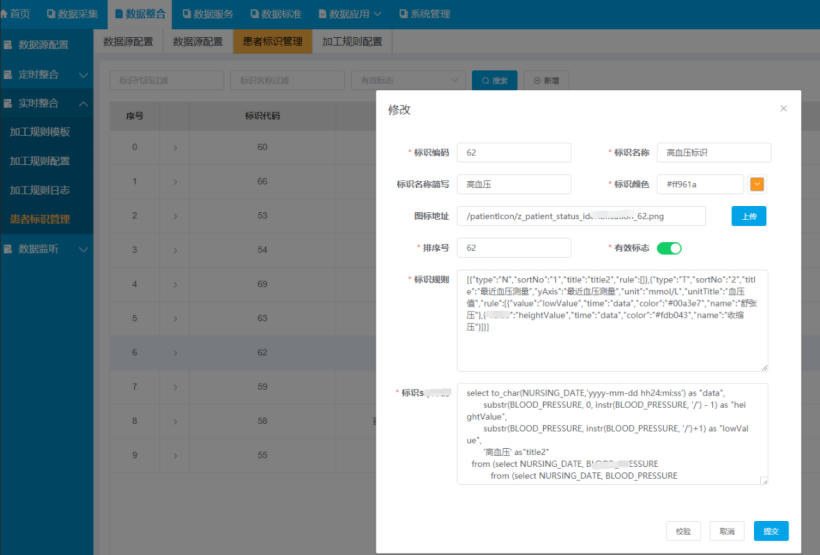
用于抽取监控不同患者医疗数据,事先可以在不同的业务抽取进程,在将比如危急值的抽取进程、发热的抽取进程、传染病抽取进程、高血压抽取进程等,将不同的监听的业务投递到高可用的消息队列主题中,主要是包括以下业务数据例如:患者肝功能不全异常标识做完肝功能检验,出报告指标白蛋白、凝血酶原时间和胆红素等数据,监听检验指标表信息,一般胆红素升高就是黄疸、凝血酶原时间反应的是血液凝固的时间,如果时间比正常值延长很多,那么就有出血的危险;高血压标识一般通过测量患者的血压,正常血压是在80~120范围内,超过140则为高血压患者,通过监听记录病人体征信息表根据预先配置的语法规则,事先得到高压患者标识;患者肾功能不全标识主要监听检验指标表血肌酐、尿素氮、ECT检验指标信息,传染病患者标识主要监听传染病登记主表信息,登记状态信息,可以可视化界面可以配置具体详情如下图。
2、消息队列模块
用于数据流的存储,可以实现数据的高可用,不同系统数据之间的解耦,需要定义同步业务的事件主题,之所以要定义不同业务事件主题的话,方便数据投递到不同的事件主题时可以处理不同患者标识的业务,这样的过程整体对不同患者标识具有一定联动解耦的作用,保证通过读取数据库库归档日志信息投递到消息中间件中、数据队列存放Kafka的当中从而减轻数据库的查询压力和数据计算拆分开来,对数据进行异步处理,从而达到效率最高。
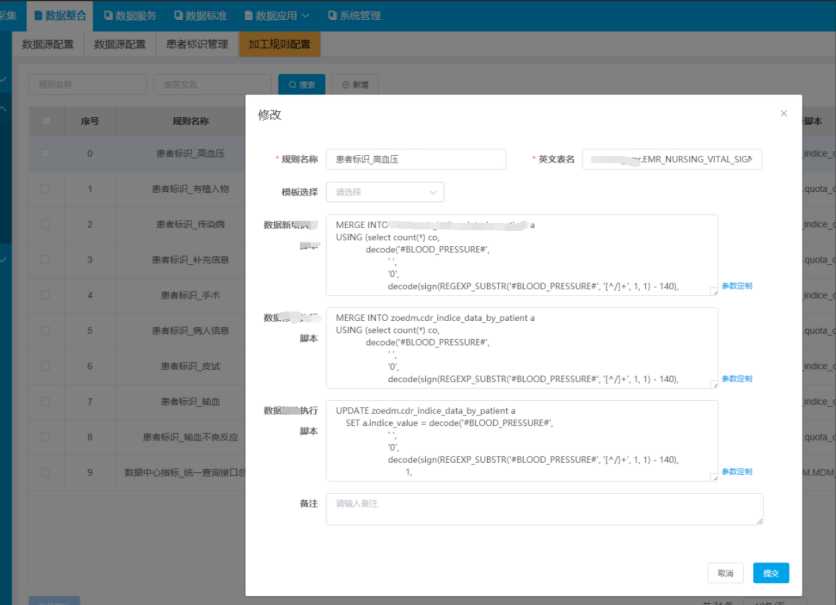
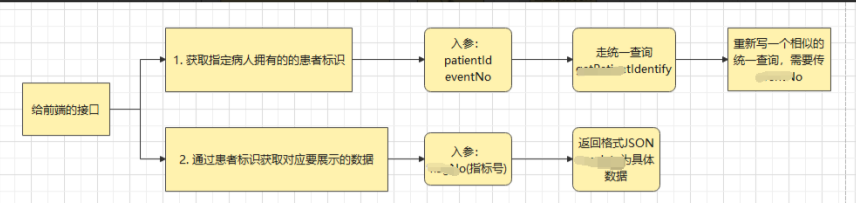
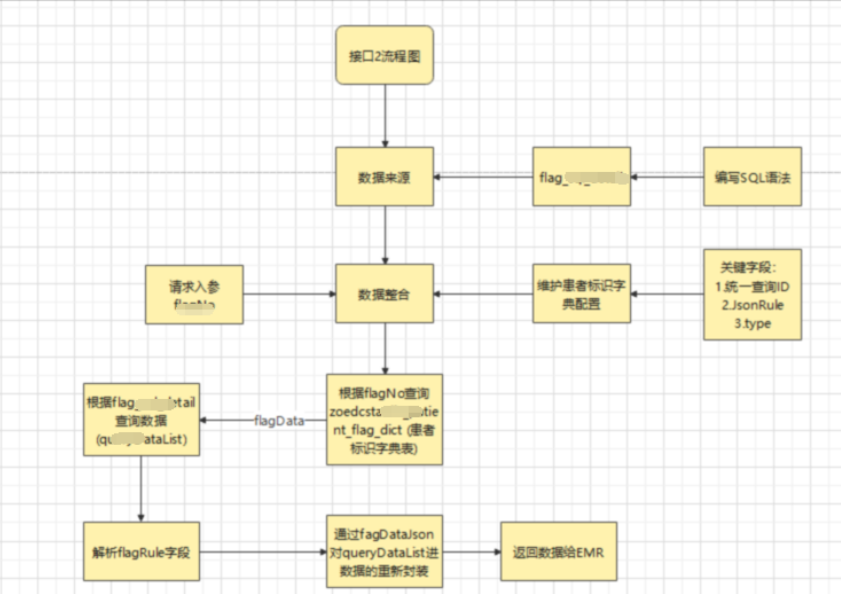
加工引擎模块,用于根据不同医疗的数据,进行不同规则患者标识脚本进行计算,得到不同维度的高可用的患者标识维度的临床数据集合,其中包含:肝功能异常数据集、肾功能不全数据集、压疮数据集、疼痛数据集、手术数据集、高血压包含详情数据集、高血糖数据集、发热数据集、跌倒数据集、药物不良反应数据集、病种数据集、病危数据集和危急值数据集等,如下图是加工规则的配置界面,以及患者标识获取以及数据详情获取的流程图。
3、数据存储模块
用于将不同维度的患者标识维度的临床数据集合存储在数据中心的集市层。
4、日志追踪模块
用于监控不同环节数据采集监控和数据加工规则执行的数据链路的状态,发生异常或者加工算法报错,进行日志的记录。
5、统一预警模块
用于对产生的异常日志,经过微信通知的方式报警或者短信通知到不同责任人,以便对异常信息进行及时处理。
相关图示
【架构图】
【效果图】
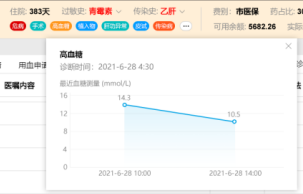
方案特征
1、目前医疗信息化行业数据中心,鲜有使用 CDC 整合 Spark Streaming 以及 Kafka 这一技术组合方案,实现高可靠、高效实时、高扩展性的数据加工引擎,进而实现数据中心大量患者医疗数据实时加工到数据集市中。
2、前期整体的技术水平挑战还是比较有难度,由于以往的方式都是通过数据库里面利用复杂的查询SQL进行患者标识的查询,这样无疑在医护人员就诊过程增加查询患者标识的时间,通过研究大数据中间件 Spark Streaming 和消息中间件Kafka 作为数据的消息对列,以及制定了患者标识展示和详情展示的流程,构建了此次的数据通道,整体的功能设计和计算的应用给医护工作人员带来较大的影响,同时也得到肯定。对比较多的医疗厂商使用 ETL 作为指标的加工工具,这样通过这种技术架构通道的方式解决了无法对变动的数据进行实时的数据捕捉、变换以及投递和数据实时计算能力差、通过ETL离线计算基本不能达到医护人员的要求等特点,这样的技术链路通道在整个医疗行业的话是较为领先的。
3、通过加工引擎中不同规则的对整理的患者标识维护的指标脚本内容保护,对数据流高可用的计算。
4、全日志追踪,监控不同环节数据链路的状态,对异常模块进行通知报警。
总结陈词
上文介绍了博主所在公司的《基于 CDC、Spark Streaming、Kafka 实现患者指标采集》方案。
💗 后续会逐步分享企业实际开发中的实战经验,有需要交流的可以联系博主。