ECCV2024|LightenDiffusion 超越现有无监督方法,引领低光图像增强新纪元!


论文链接:https://arxiv.org/pdf/2407.08939
git链接:https://github.com/JianghaiSCU/LightenDiffusion
亮点直击
提出了一种基于扩散的框架,LightenDiffusion,结合了Retinex理论的优势和扩散模型的生成能力,用于无监督低光图像增强。进一步提出了自我约束的一致性损失,以改善视觉质量。
提出了一个内容传输分解网络,在潜空间中执行分解,旨在获取富含内容的反射率图和无内容的照明图,以促进无监督恢复。
大量实验证明,LightenDiffusion在超越现有的无监督竞争对手的同时,与监督方法相比具有更好的泛化能力。
本文提出了一种基于扩散的无监督框架,将可解释的Retinex理论与低光图像增强的扩散模型相结合,命名为LightenDiffusion。具体而言,提出了一种内容传输分解网络,在潜空间而非图像空间中执行Retinex分解,使得未配对的低光和正常光图像的编码特征能够被分解成富含内容的反射率图和无内容的照明图。随后,将低光图像的反射率图和正常光图像的照明图作为输入,通过扩散模型进行无监督恢复,以低光特征为指导,进一步提出了自我约束的一致性损失,以消除正常光内容对恢复结果的干扰,从而提高整体视觉质量。在公开的真实世界基准数据集上进行了大量实验表明,LightenDiffusion在超越现有无监督竞争对手的同时,与监督方法相媲美,并且更具通用性,适用于各种场景。
方法
概述
本文提出的框架的整体流程如下图2所示。给定一个未配对的低光图像 和正常光图像 ,首先使用一个编码器 ,它由 个级联的残差块组成,每个块使用最大池化层将输入按比例降采样 倍,将输入图像转换为潜空间表示,表示为 和 。然后,设计了一个内容传输分解网络(CTDN),将这些特征分解为富含内容的反射率图 和 ,以及无内容的照明图 和 。随后, 和 作为扩散模型的输入,结合低光特征的指导,生成恢复的特征 。最后,恢复的特征将送入解码器 进行重建,生成最终的恢复图像 。
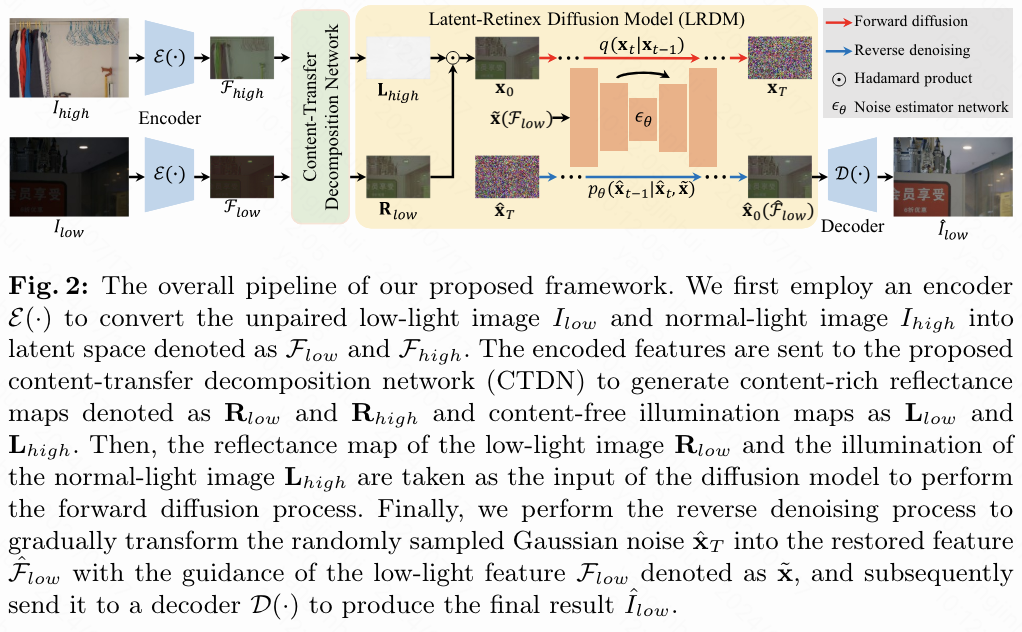
内容传输分解网络
根据Retinex理论,图像可以分解为反射率图和照明图,即:

在上述情况下,符号 ⊙ 表示Hadamard乘积运算。其中,R代表应在各种照明条件下保持一致的固有内容信息,而L表示应该是局部平滑的对比度和亮度信息。然而,现有方法通常在图像空间内执行分解以获取上述组件,这导致内容信息未能完全分解到反射率图中,部分保留在照明图中,如下图3(a)所示。

为了缓解这个问题,引入了一个内容传输分解网络(CTDN),它在潜空间内执行分解。通过在这个潜空间中编码内容信息,CTDN促进了生成包含丰富内容相关细节的反射率图,并保持不受内容相关影响的照明图。如下图4所示,首先按照[14]的方法估计初始的反射率和照明图为:
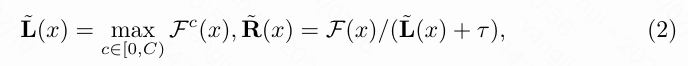
当处理每个像素 时,其中 是一个小常数,用于避免零分母。估计的地图通过两个分支进行了细化。首先,使用多个卷积块来获取嵌入特征,即 ,。随后,利用交叉注意力(CA)模块 来加强反射图中的内容信息。此外,还采用了自注意力(SA)模块 来进一步提取光照图中的内容信息,并将其补充到反射图中。最终输出的反射图 和光照图 可以表示为 和 。
如上图3(b) 所示,CTDN能够生成内容丰富的反射地图,充分展示图像的内在信息,并生成只显示光照条件的光照地图。
Latent-Retinex 扩散模型
一种直接获得理想情况下增强特征的简单方法是将低光特征的反射图(R_{low})与正常光图像的照明图(L_{high})相乘,即 。然而,上述方法存在两个挑战:
-
Retinex分解不可避免地会导致信息损失;
-
恢复的图像可能会呈现出现象,因为参考正常光图像的照明图仍包含顽固的内容信息。
虽然CTDN在大多数场景中通常是有效的,但在一些挑战性情况下,估计的照明图的准确性可能会受到影响。为解决这些问题,提出了一种Latent-Retinex扩散模型(LRDM),利用扩散模型的生成能力来补偿内容损失并消除潜在的意外现象。方法遵循标准的扩散模型,进行前向扩散和反向去噪过程以生成恢复的结果。
前向扩散。 鉴于未配对图像的分解组件,将低光图像的反射图 和正常光图像的照明图 视为输入,表示为 ,进行前向扩散过程。使用预定义的方差进度 ,逐步将 转化为服从高斯噪声 ,经过 T 步骤,可以表述为:
![]()
在这里, 表示时间步 的噪声数据。通过参数重整化,可以将多个高斯分布合并并优化,从而直接从输入 得到 ,并将方程(4)简化为闭合形式:其中 , ,且 。
逆去噪. 通过利用条件扩散模型提供的编辑和数据合成能力,旨在在低光图像的编码特征 的指导下,逐渐将随机抽样的高斯噪声 逆向去噪到一个清晰的结果 ,从而保证恢复的结果与以 为条件的分布具有高保真度。反向去噪过程可以表述为:
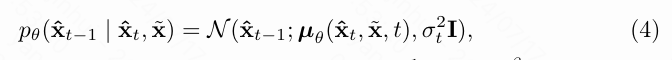
其中, 是方差,而 是均值。
在训练阶段,扩散模型的目标是优化网络的参数 ,使得估计的噪声向量 接近高斯噪声,具体表述为:
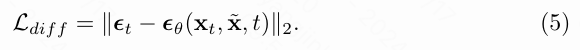
在推理过程中,通过隐式采样策略从扩散模型学习的分布中获得经过逆向去噪处理的恢复特征 ,随后将其送入解码器生成最终结果 。然而,正如上文所述,如果估计的照明图仍包含内容信息,输入 可能会呈现出伪影,这可能影响所学习的分布,导致 受到干扰。
因此,本文提出了一个自约束一致性损失 ,以使恢复的特征能够与输入的低光图像共享相同的内在信息。具体而言,在训练阶段,首先执行反去噪过程,按照 [20, 22, 76] 的方法生成恢复的特征,并根据传统的Gamma校正方法从低光图像的分解结果构建伪标签 作为参考,其中 ,这里 是光照校正因子。因此, 的目标是约束特征的相似性,以促使扩散模型重建 ,如下所示:
![]()
总体而言,低光图像恢复扩散模型(LRDM)的训练策略总结如下面算法 1 所示,用于优化的目标函数重写为 。

网络训练
本文的方法采用了两阶段的网络训练策略。在第一阶段中,遵循 [10] 的方法,利用SICE数据集中的配对低质量图像,表示为 和 ,来优化编码器 ,CTDN,以及解码器 ,同时冻结扩散模型的参数。编码器和解码器通过内容损失 进行优化,如下所示:
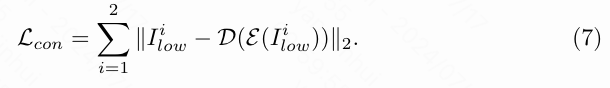
CTDN被优化使用分解损失 ,如[58, 71, 74] 所述,包括重建损失 ,反射一致性损失 ,和光照平滑损失 。 的目标是确保分解的组成部分能够重建输入特征,表达式如下所示:
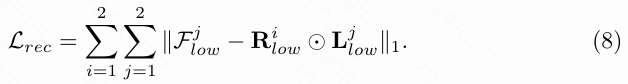
反射一致性损失 的目标是强制网络生成不变的反射率图像,而光照平滑损失 则用于确保光照图像具有局部平滑性,分别可以表达为:
![]()
在上述公式中,∇ 表示水平和垂直梯度,λg 是用来平衡结构感知强度的系数。用于优化CTDN的整体分解损失定义为 。
在第二阶段,收集了约180,000对未配对的低光/正常光图像对,用于在冻结其他模块参数的同时优化扩散模型。
实验
与现有方法的比较
将本文的方法与四类现有的低光图像增强(LLIE)方法进行比较:
-
传统方法:包括LIME、SDDLLE、BrainRetinex和CDEF。
-
监督方法:包括RetinexNet、KinD++、LCDPNet、URetinexNet、SMG、PyDiff和GSAD。这些方法在LOL训练集上进行训练。
-
半监督方法:包括DRBN和BL。
-
无监督方法:包括Zero-DCE、EnlightenGAN、RUAS、SCI、GDP、PairLIE和NeRCo。
需要注意的是,GDP和本文的方法的性能报告是五次评估的平均值。
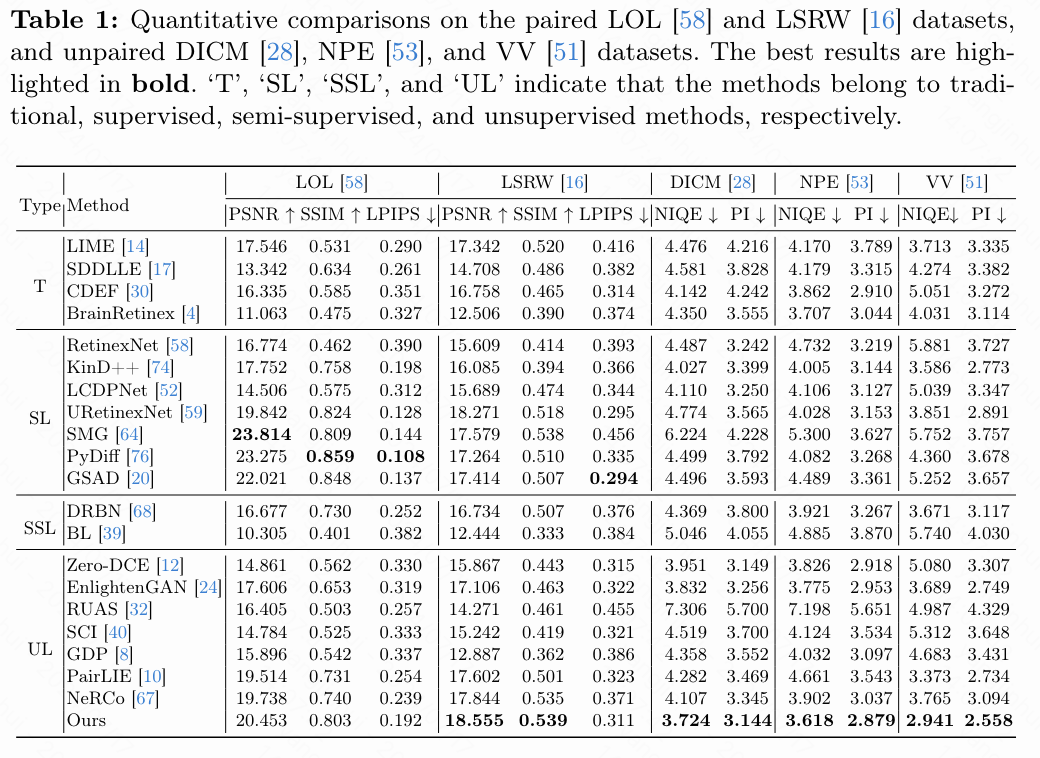
定量比较. 首先在LOL和LSRW测试集上将本文的方法与所有比较方法进行量化比较。如下表1所示,LightenDiffusion在这两个基准上表现优于所有的无监督竞争对手。未能在LOL数据集上超过监督方法的原因是,它们通常在该数据集上进行训练,因此可以达到令人满意的性能。然而,本文的方法在LSRW数据集上超过了监督方法,在PSNR和SSIM上达到最高值,尽管在LPIPS方面稍逊色。为了进一步验证本文方法的有效性,还将提出的LightenDiffusion与比较方法在DICM、NPE和VV这三个未配对基准数据集上进行比较。如表1所示,无监督方法在这些未见过的数据集上表现出比监督方法更好的泛化能力,而本文的方法在所有三个数据集上均取得了最佳结果。这表明本文的方法能够生成视觉上令人满意的图像,并且能够很好地推广到各种场景中。
定性比较. 下图5中展示了本文的方法与竞争方法在配对数据集上的视觉比较结果。图中的第1至2行分别来自LOL和LSRW测试集。可以看到,先前的方法可能会产生曝光不足、色彩失真或噪声放大的结果,而本文的方法能够有效改善全局和局部对比度,重建更清晰的细节,并抑制噪声,从而产生视觉上令人愉悦的结果。

在下图6中,还提供了在未配对基准数据集上的结果。图中的第1至3行分别来自DICM、NPE和VV数据集。先前的方法在这些场景中往往表现出泛化能力较差,特别是第2行,在光源周围产生了伪影或者产生了过曝的结果。相比之下,本文的方法能够呈现正确的曝光和生动的颜色,证明了在泛化能力上的优势。

低光人脸检测
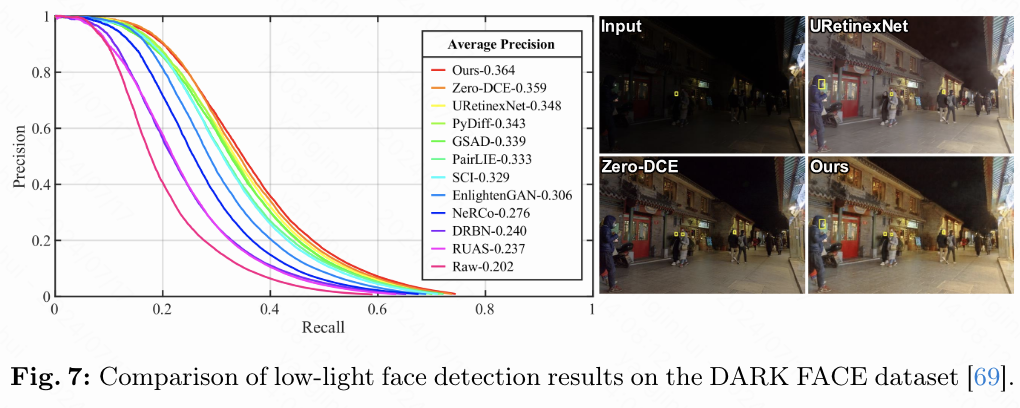
在DARK FACE数据集上进行实验,该数据集包含6,000张在弱光条件下拍摄的图像,并带有标注的标签用于评估,旨在研究低光图像增强(LLIE)方法作为预处理步骤在改善低光人脸检测任务中的影响。遵循文献 [12, 22, 40] 的方法,使用本文的方法以及其他10种竞争的LLIE方法来恢复图像,然后使用知名的检测器RetinaFace在IoU阈值为0.3的条件下进行评估,绘制精确度-召回率(P-R)曲线并计算平均精度(AP)。
如下图7所示,与未增强的原始图像相比,本文的方法有效地将RetinaFace的精度从20.2%提高到36.4%,并且在高召回率区域表现优于其他方法,这显示了本文方法的潜在实际价值。
消融实验
本节进行了一系列消融研究,以验证不同组件选择的影响。使用了前文中描述的实现细节进行训练,并在LOL和DICM数据集上展示了定量结果,如下表2所示。下面讨论详细的设置。
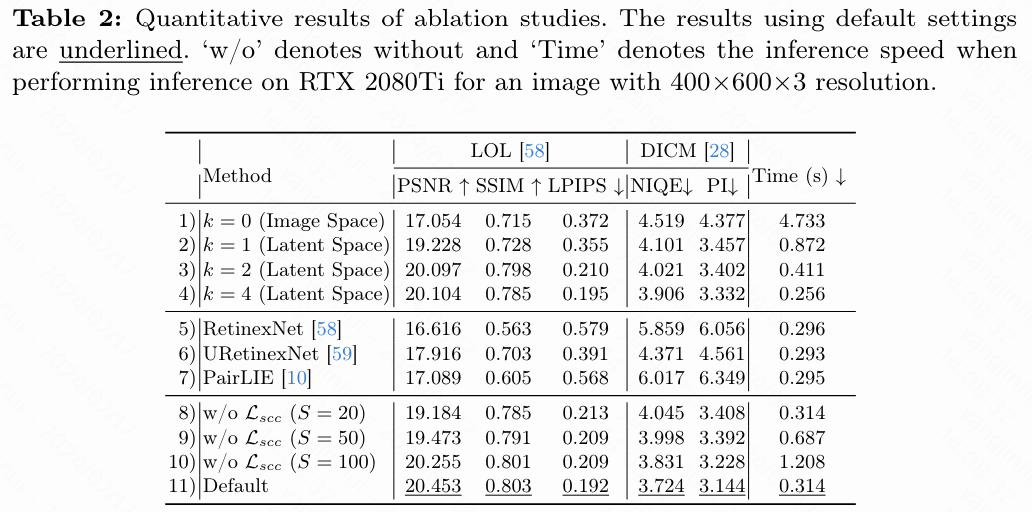
潜空间与图像空间比较:为了验证latentRetinex分解策略的有效性,进行了实验,分别在图像空间进行分解(即k=0),以及在潜空间的不同尺度进行分解(即k∈[1, 4])。如下图8(a)所示,在图像空间进行分解很难实现令人满意的分解效果,因为光照图可能会包含某些内容信息,导致恢复的图像出现伪影。相反,如下图8(b)-(d)所示,通过在潜空间进行分解可以生成仅表示光照条件的光照图,这有助于扩散模型生成视觉保真度高的恢复图像。此外,如上表2的第1-4行报告的结果显示,增加k可以提升整体性能和推理速度,但在k=4时会因特征信息丰富度大幅降低而导致轻微的性能下降,这对扩散模型的生成能力有不利影响。为了在性能和效率之间找到平衡,选择k=3作为默认设置。

Retinex分解网络。 为了验证CTDN的有效性,将其替换为三种先前基于Retinex的方法的分解网络,包括RetinexNet、URetinexNet和PairLIE,用于估计反射率和光照图。如上图8(e)-(g)所示,先前的分解网络无法获得无内容的光照图,导致恢复的结果具有模糊的细节和伪影。相比之下,本文的方法通过精心设计的CTDN网络架构,能够生成富含内容的反射率图和无内容的光照图,从而在比较中表现出显著的性能优势,如上表2所报告的结果。
损失函数。 为了验证提出的自约束一致性损失的有效性,进行了一个实验,将其从用于优化扩散模型的目标函数中移除。如上表2的第8行所报告的结果显示,移除会导致整体性能下降。此外,将采样步长S增加到50和100,评估使用纯扩散损失训练的扩散模型的性能,即公式(5),因为扩散模型生成的结果质量随着S的增加而提高,如下图9所示。与第11行的默认设置相比,将采样步长增加到S = 100能够产生与使用训练的模型相媲美的性能,但推理速度减慢了将近4倍,这证明了损失函数可以帮助模型实现高效和稳健的恢复。

结论
LightenDiffusion,这是一个基于扩散的框架,将Retinex理论与扩散模型结合,用于无监督的低光图像增强(LLIE)。技术上,提出了一个内容转移分解网络,它在潜空间内进行分解,以获取富含内容的反射率图和无内容的光照图,从而便于后续的无监督恢复过程。低光图像的反射率图和正常光图像的光照图在不同场景下作为输入用于扩散模型的训练。此外,本文提出了一个自约束一致性损失,进一步约束恢复的结果具有与低光输入相同的内在内容信息。实验结果表明,本文的方法在定量和视觉上均优于现有的竞争方法。
参考文献
[1] LightenDiffusion: Unsupervised Low-Light Image Enhancement with Latent-Retinex Diffusion Models