如何优化PyTorch以加快模型训练速度?
PyTorch是当今生产环境中最流行的深度学习框架之一。随着模型变得日益复杂、数据集日益庞大,优化模型训练性能对于缩短训练时间和提高生产力变得至关重要。
本文将分享几个最新的性能调优技巧,以加速跨领域的机器学习模型的训练。这些技巧对任何想要使用PyTorch实现高级性能调优的人都大有帮助。
技巧1:通过分析识别性能瓶颈
在开始调优之前,你应该了解模型训练管道中的瓶颈。分析(Profiling)是优化过程中的关键步骤,因为它有助于识别需要注意的内容。你可以从PyTorch的内置自动求梯度分析器、TensorBoard和英伟达的Nsight系统中进行选择。下面不妨看一下三个示例。
- 代码示例:自动求梯度分析器
import torch.autograd.profiler as profiler
with profiler.profile(use_cuda=True) as prof:
# Run your model training code here
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))在这个示例中,PyTorch的内置自动求梯度分析器识别梯度计算开销。use_cuda=True参数指定你想要分析CUDA内核执行时间。prof.key_average()函数返回一个汇总分析结果的表,按总的CUDA时间排序。
- 代码示例:TensorBoard集成
import torch.utils.tensorboard as tensorboard
writer = tensorboard.SummaryWriter()
# Run your model training code here
writer.add_scalar('loss', loss.item(), global_step)
writer.close()你还可以使用TensorBoard集成来显示和分析模型训练。SummaryWriter类将汇总数据写入到一个文件,该文件可以使用TensorBoard GUI加以显示。
- 代码示例:英伟达Nsight Systems
nsys profile -t cpu,gpu,memory python your_script.py对于系统级分析,可以考虑英伟达的Nsight Systems性能分析工具。上面的命令分析了Python脚本的CPU、GPU和内存使用情况。
技巧2:加速数据加载以提升速度和GPU利用率
数据加载是模型训练管道的关键组成部分。在典型的机器学习训练管道中,PyTorch的数据加载器在每个训练轮次开始时从存储中加载数据集。然后,数据集被传输到GPU实例的本地存储,并在GPU内存中进行处理。如果数据传输到GPU的速度跟不上GPU的计算速度,就会导致GPU周期浪费。因此,优化数据加载对于加快训练速度、尽量提升GPU利用率至关重要。
为了尽量减少数据加载瓶颈,你可以考虑以下优化:
- 使用多个worker并行化数据加载:使用PyTorch的数据加载器与多个worker并行化数据加载。这允许CPU并行加载和处理数据,从而减少GPU空闲时间。
- 使用缓存加速数据加载:使用Alluxio作为训练节点和存储之间的缓存层,以实现数据按需加载,而不是将远程数据直接加载到本地存储或将训练数据复制到本地存储。
- 代码示例:并行化数据加载
下面这个示例是使用PyTorch的数据加载器和多个worker并行化加载数据:
import torch
from torch.utils.data import DataLoader, Dataset
class MyDataset(Dataset):
def __init__(self, data_path):
self.data_path = data_path
def __getitem__(self, index):
# Load and process data for the given index
data = load_data(self.data_path, index)
data = preprocess_data(data)
return data
def __len__(self):
return len(self.data_path)
dataset = MyDataset(data_path='path/to/data')
data_loader = DataLoader(dataset, batch_size=32, num_workers=4)
for batch in data_loader:
# Process the batch on the GPU
inputs, labels = batch
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()在这个示例中,定义了自定义数据集类MyDataset。它为每个索引加载和处理数据。然后创建一个有多个worker(本例中有四个)的数据加载器实例来并行化加载数据。
- 代码示例:使用Alluxio缓存来加速PyTorch的数据加载
Alluxio是一个开源分布式缓存系统,提供快速访问数据的机制。Alluxio缓存可以识别从底部存储(比如Amazon S3)频繁访问的数据,并在Alluxio集群的NVMe存储上分布式存储热数据的多个副本。如果使用Alluxio作为缓存层,你可以显著缩短将数据加载到训练节点所需的时间,这在处理大规模数据集或慢速存储系统时特别有用。
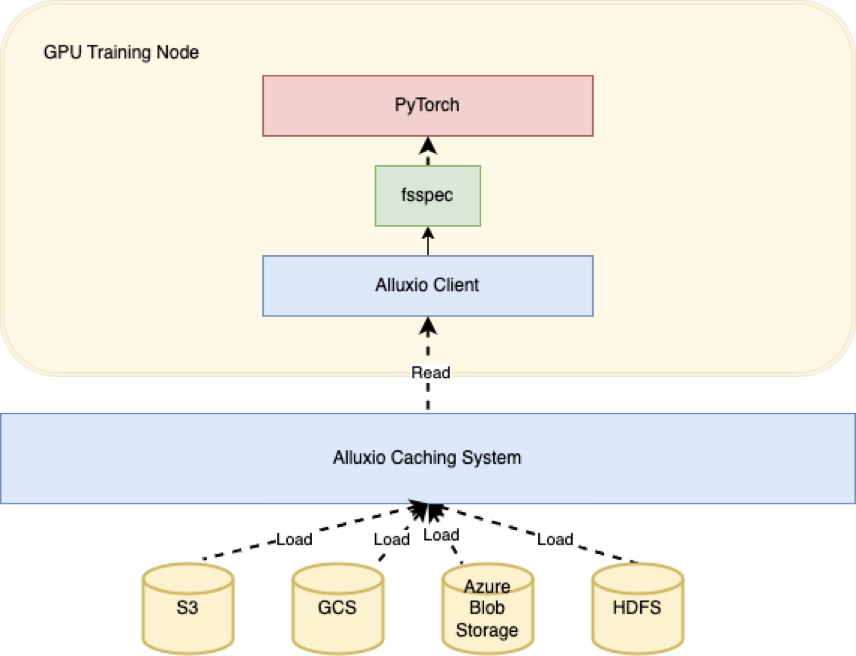
下面这个示例表明了你如何使用Alluxio与PyTorch和fsspec(文件系统规范)来加速数据加载:
首先,安装所需的依赖项:
pip install alluxiofs
pip install s3fs接下来,创建一个Alluxio实例:
import fsspec
from alluxiofs import AlluxioFileSystem
# Register Alluxio to fsspec
fsspec.register_implementation("alluxiofs", AlluxioFileSystem,
clobber=True)
# Create Alluxio instance
alluxio_fs = fsspec.filesystem("alluxiofs", etcd_hosts="localhost",
target_protocol="s3")然后,使用Alluxio和PyArrow在PyTorch中加载Parquet文件这个数据集:
# Example: Read a Parquet file using Pyarrow
import pyarrow.dataset as ds
dataset = ds.dataset("s3://example_bucket/datasets/example.parquet",
filesystem=alluxio_fs)
# Get a count of the number of records in the parquet file
dataset.count_rows()
# Display the schema derived from the parquet file header record
dataset.schema
# Display the first record
dataset.take(0)在这个示例中,创建了一个Alluxio实例并将其传递给PyArrow的dataset函数。这允许我们通过Alluxio缓存层从底层存储系统(本例中为S3)读取数据。
技巧3:为资源利用率优化批任务大小
优化GPU利用率的另一项重要技术是调整批任务大小,它会显著影响GPU和内存利用率。
- 代码示例:批任务大小优化
import torch
import torchvision
import torchvision.transforms as transforms
# Define the model and optimizer
model = torchvision.models.resnet50(pretrained=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Define the data loader with a batch size of 32
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=4
)
# Train the model with the optimized batch size
for epoch in range(5):
for inputs, labels in data_loader:
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = torch.nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()在本例中,批任务大小定义为32。batch_size参数指定了每个批中的样本数量。shuffle=True参数随机化批处理的顺序,num_workers=4参数指定用于加载数据的worker线程的数量。你可以尝试不同的批任务大小,以找到在可用内存范围内尽量提高GPU利用率的最佳值。
技巧4:可识别GPU的模型并行性
处理大型复杂模型时,单个GPU的限制可能会成为训练的瓶颈。模型并行化可以通过在多个GPU上共同分布模型以使用它们的加速能力来克服这一挑战。
1.利用PyTorch的DistributedDataParallel(DDP)模块
PyTorch提供了DistributedDataParallel(DDP)模块,它可以通过支持多个后端来实现简单的模型并行化。为了尽量提高性能,使用NCCL后端,它针对英伟达GPU进行了优化。如果使用DDP来封装模型,你可以跨多个GPU无缝分布模型,将训练扩展到前所未有的层面。
- 代码示例:使用DDP
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
# Define your model and move it to the desired device(s)
model = MyModel()
device_ids = [0, 1, 2, 3] # Use 4 GPUs for training
model.to(device_ids[0])
model_ddp = DDP(model, device_ids=device_ids)
# Train your model as usual2.使用PyTorch的Pipe模块实现管道并行处理
对于需要顺序处理的模型,比如那些具有循环或自回归组件的模型,管道并行性可以改变游戏规则。PyTorch的Pipe允许你将模型分解为更小的部分,在单独的GPU上处理每个部分。这使得复杂模型可以高效并行化,缩短了训练时间,提高了整体系统利用率。
3.减少通信开销
虽然模型并行化提供了巨大的好处,但也带来了设备之间的通信开销。以下是尽量减小影响的几个建议:
a.最小化梯度聚合:通过使用更大的批大小或在同步之前本地累积梯度,减少梯度聚合的频次。
b.使用异步更新:使用异步更新,隐藏延迟和最大化GPU利用率。
c.启用NCCL的分层通信:让NCCL库决定使用哪种分层算法:环还是树,这可以减少特定场景下的通信开销。
d.调整NCCL的缓冲区大小:调整NCCL_BUFF_SIZE环境变量,为你的特定用例优化缓冲区大小。
技巧5:混合精度训练
混合精度训练是一种强大的技术,可以显著加速模型训练。通过利用现代英伟达GPU的功能,你可以减少训练所需的计算资源,从而加快迭代时间并提高生产力。
1.使用Tensor Cores加速训练
英伟达的Tensor Cores是专门用于加速矩阵乘法的硬件块。这些核心可以比传统的CUDA核心更快地执行某些操作。
2.使用PyTorch的AMP简化混合精度训练
实现混合精度训练可能很复杂,而且容易出错。幸好,PyTorch提供了一个amp模块来简化这个过程。使用自动混合精度(AMP),你可以针对模型的不同部分在不同精度格式(例如float32和float16)之间切换,从而优化性能和内存使用。
- 代码示例:PyTorch的AMP
以下这个示例表明了如何使用PyTorch的amp模块来实现混合精度训练:
import torch
from torch.amp import autocast
# Define your model and optimizer
model = MyModel()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Enable mixed precision training with AMP
with autocast(enabled=True, dtype=torch.float16):
# Train your model as usual
for epoch in range(10):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()3.使用低精度格式优化内存使用
以较低精度格式(比如float16)存储模型权重可以显著减少内存使用。当处理大型模型或有限的GPU资源时,这点尤为重要。如果使用精度较低的格式,你可以将较大的模型放入到内存中,从而减少对昂贵内存访问的需求,并提高整体训练性能。
记住要尝试不同的精度格式并优化内存使用,以便为你的特定用例获得最佳结果。
技巧6:新的硬件优化:GPU和网络
新的硬件技术出现为加速模型训练提供了大好机会。记得尝试不同的硬件配置,并优化你的工作流,以便为特定用例获得最佳结果。
1.利用英伟达A100和H100 GPU
最新的英伟达A100和H100 GPU有先进的性能和内存带宽。这些GPU为用户提供了更多的处理能力,使用户能够训练更大的模型、处理更大的批任务,并缩短迭代时间。
2.利用NVLink和InfiniBand加速GPU-GPU通信
当跨多个GPU训练大型模型时,设备之间的通信开销可能成为一大瓶颈。英伟达的NVLink互连技术在GPU之间提供了高带宽低延迟的链路,从而实现更快的数据传输和同步。此外,InfiniBand互连技术为连接多个GPU和节点提供了一种易于扩展的高性能解决方案。它有助于尽量减小通信开销,缩短同步梯度和加速模型训练所花费的时间。