PointNet点云语义分割
在本教程中,我们将学习如何在斯坦福 3D 室内场景数据集 (S3DIS) 上训练 Point Net 进行语义分割。S3DIS 是一个 3D 数据集,包含来自多栋建筑的室内空间点云,占地面积超过 6000 平方米 [1]。Point Net 是一种新颖的架构,它使用整个点云,能够执行分类和分割任务 [2]。如果你一直在关注 Point Net 系列,那么你已经知道它的工作原理和编码方法。
在上一个教程中,我们学习了如何在 Shapenet 数据集的迷你版本上训练 Point Net 进行分类。在本教程中,我们将使用 S3DIS 数据集训练 Point Net 进行语义分割。本教程的代码位于此存储库中,我们将使用此笔记本进行工作。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、S3DIS 数据集
可以通过在此处请求访问来下载本文使用的完整 S3DIS 数据集。数据集分为六个不同的区域,对应不同的建筑物。每个区域内有不同的室内空间,对应不同的房间,如办公室或会议室。
此数据集有两个版本,原始版本和对齐版本,我们选择使用对齐版本。对齐版本与原始版本相同,只是每个点云都经过旋转,使得 x 轴沿房间入口对齐,y 轴垂直于入口墙壁,z 轴保持垂直轴。这种对齐形成了一个规范(即通用)坐标系,使我们能够利用每个点云中发现的一致结构 [1]。
1.1 数据缩减
数据集在磁盘上接近 30GB(压缩后为 6GB),但我们有一个缩减版本,解压后仅占用约 6GB。在数据缩减过程中,真实数据点颜色已被删除,所有数据点都已转换为 float32,剩下包含 (x,y,z) 点和一个类的 Nx4 数组。每个空间都被划分为大约 1x1 米的子空间并保存为 hdf5 文件。完成该过程超出了本教程的范围,但这里是用于生成缩减数据集的笔记本。
1.2 数据超参数
谈到数据时,我们可能并不经常想到超参数,但各种增强(甚至规范化)实际上都是超参数,因为它们在学习过程中发挥着重要作用 [3]。
我们的数据超参数可以分为两类:实际变换本身(例如图像旋转与图像扭曲)和控制变换的参数(例如图像旋转角度)。模型无法直接学习其中任何一项,我们通常根据验证性能调整这些参数,就像我们对模型超参数(例如学习率、批量大小)所做的那样。还值得注意的是,数据超参数可以大大提高模型的学习能力,这可以通过经验验证。
在训练集和验证集中,我们添加标准差为 0.01 的随机高斯噪声。仅在训练集中,我们以 0.25 的概率随机绕垂直轴旋转。限制绕垂直轴的旋转可使基础结构发生变化,而地板、墙壁和天花板(背景)在所有分区中都保持类似的关系。对于所有分割,我们执行最小/最大规范化,以便每个分区的范围从 0-1。与 [2] 类似,我们在训练和验证期间随机为每个分区向下采样 4096 个点。在测试期间,我们更喜欢使用更多点来更好地了解模型性能,因此我们使用 15000 个点进行向下采样。
PyTorch 数据集脚本位于此处,请跟随笔记本了解如何生成数据集。对于我们的分割,我们使用区域 1-4 进行训练,区域 5 进行验证,区域 6 进行测试。
1.3 数据探索
图 1 显示了完整空间的示例。而图 2 显示了常规 VS 旋转分区的示例。

图 1. 一个完整的空间,其中的颜色表示不同的类别
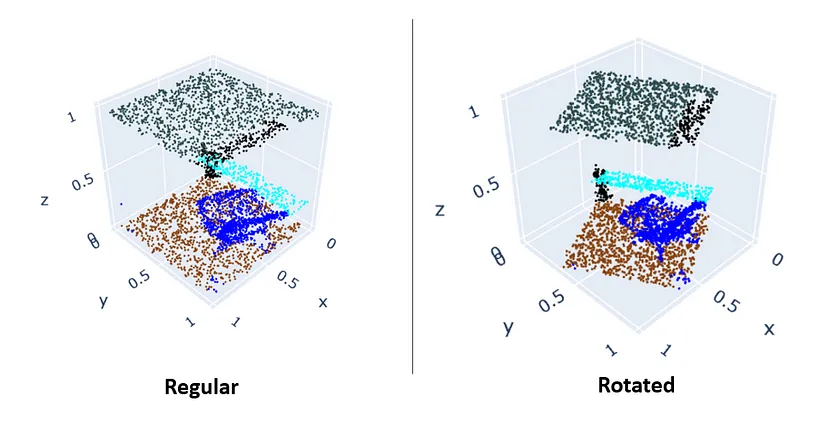
图 2. 常规 VS 旋转训练分区
现在让我们探索训练类别频率,它们显示在图 3 中。我们可以看到这个数据集非常不平衡,一些类别似乎构成了背景类别(天花板、地板、墙壁)。我们应该注意到,杂乱类别实际上是任何其他杂项对象的类别,例如墙上的白板或图片,或桌子上的打印机。
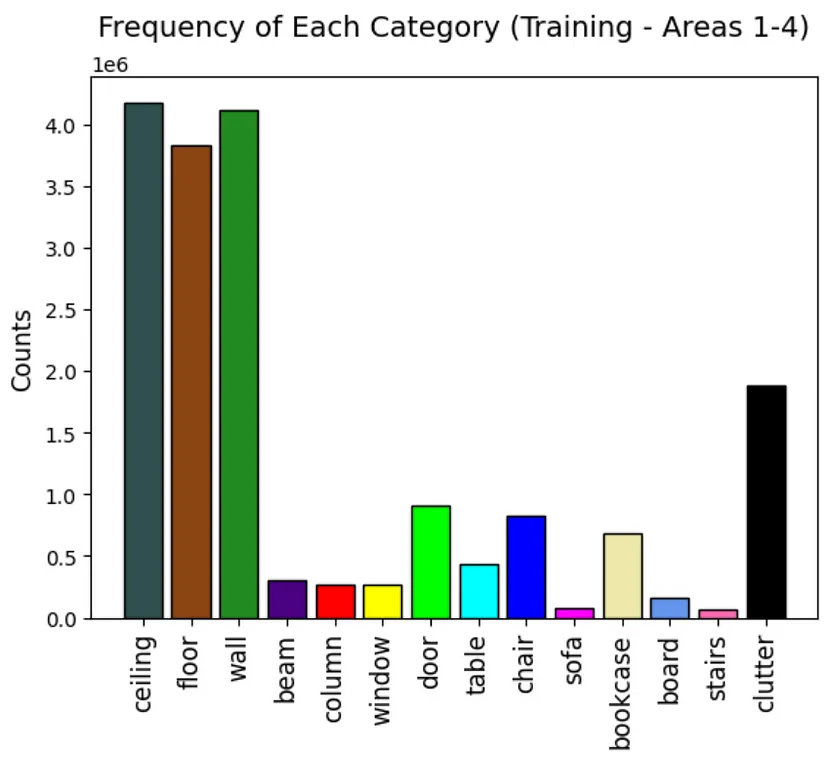
图 3. S3DIS 数据集的类频率
2、方法论
当你听到语义分割时,可能会想到图像,因为它是识别给定图像中每个像素的概念 [4]。分割可以推广到高维空间,对于 3D 点云,它是为每个 3D 点分配一个类的概念。
为了更好地理解这个问题由什么组成,我们应该很好地理解点云实际上是什么。让我们考虑一下我们想要分割的类,如果你看图 2,你会注意到每个类(杂乱除外)都有独特且一致的结构。即墙壁、地板和天花板是平坦且连续的平面;椅子和书柜等物品也应该在许多不同区域具有一致的结构。我们希望我们的模型能够以一定的准确度识别不同类别的不同结构。我们需要构建一个损失函数来诱使我们的模型以有用的方式学习这些结构。
损失函数
在图 2 中,我们可以清楚地看到这个数据集是不平衡的。我们以与分类教程类似的方式解决这个问题。我们结合了平衡焦点损失,它基于交叉熵损失,并增加了几个额外的项来缩放它。
第一个缩放因子是类权重 (alpha),它决定了每个类的重要性,这就是“平衡”项的来源。我们可以使用逆类权重,也可以手动将其设置为超参数。
第二个项将平衡交叉熵损失转换为平衡焦点损失,该项被视为一个调节因子,它迫使模型专注于困难的类别,即那些预测置信度较低的类别 [5]。调节因子通过超参数 gamma 控制,如图 4 所示。gamma 项的范围可能是 0-5,但实际上取决于具体情况。
![]()
图 4. t 类的焦点损失。alpha 是类权重,gamma 次幂的项是调制项,对数项是交叉熵损失。
[1] 的作者认为,语义分割问题实际上最好作为检测问题而不是分割问题来处理。我们在这里不会对此进行过多的阐述,但我们将尝试在我们的损失函数中考虑整体类结构。我们的模型需要学习类结构的基本表示,它需要学习它们是连续的而不是稀疏的。我们可以结合 Dice Loss 来帮助解释这一点。Dice 分数量化了我们预测的类与基本事实的重叠程度。Dice Loss 只是 1 减去 Dice 系数,如图 5 所示,我们添加了 epsilon 以避免除以零 [6]。
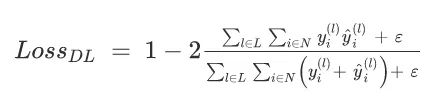
图 5.骰子损失
我们加入了 Dice Loss,以防止模型预测稀疏结构分类。也就是说,我们更希望分割整面墙,而不是将墙和杂物混合在一起。在训练期间,我们添加了 Focal Loss 和 Dice Loss,并将其用作我们的损失。损失函数的代码可在此处获得,PyTorch 中的 Dice Loss 代码如下:
@staticmethod
def dice_loss(predictions, targets, eps=1):targets = targets.reshape(-1)predictions = predictions.reshape(-1)cats = torch.unique(targets)top = 0bot = 0for i, c in enumerate(cats):locs = targets == cy_tru = targets[locs]y_hat = predictions[locs]top += torch.sum(y_hat == y_tru)bot += len(y_tru) + len(y_hat)return 1 - 2*((top + eps)/(bot + eps))3、模型训练
模型超参数在下面的训练设置代码中列出,笔记本在这里。
import torch.optim as optim
from point_net_loss import PointNetSegLossEPOCHS = 100
LR = 0.0001# manually set alpha weights
alpha = np.ones(len(CATEGORIES))
alpha[0:3] *= 0.25 # balance background classes
alpha[-1] *= 0.75 # balance clutter classgamma = 1optimizer = optim.Adam(seg_model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.0001, max_lr=0.01, step_size_up=2000, cycle_momentum=False)
criterion = PointNetSegLoss(alpha=alpha, gamma=gamma, dice=True).to(DEVICE)我们手动加权背景和杂波类别,并将焦点损失的伽马设置为 1。我们使用 Adam 优化器和循环学习率调度器。[7] 的作者指出,学习率是最重要的超参数,并建议循环学习率 (CLR) 可以更快地产生更好的结果,而无需大量调整学习率。
我们采用了 CLR 方法,还应注意,此实验的大部分超参数调整工作都集中在数据超参数上。但是,我们应该注意到,与静态学习率相比,使用 CLR 可以提高模型性能。
训练结果
在训练期间,我们跟踪了损失、准确率、马修斯相关系数 (MCC) 和并集交集 (IOU)。训练结果如图 6 所示。
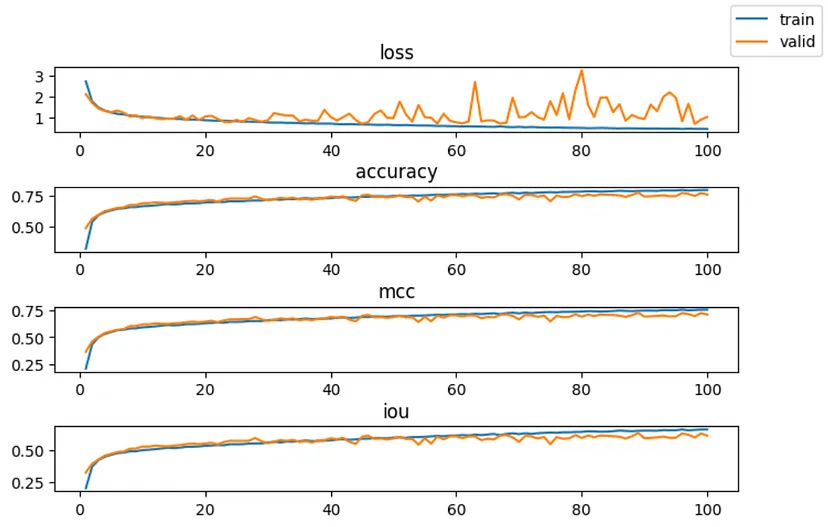
图 6. 训练指标
我们看到在第 30 个时期左右,验证损失开始变得不稳定,尽管如此,指标仍在改善。指标的锯齿状是循环学习率的典型特征,因为指标往往在每个周期结束时达到峰值 [7]。
我们从分类教程中知道,MCC 通常比 F1 分数或准确度 [8] 更能表示分类。即使我们正在进行分割训练,它仍然是一个很好的指标。
我们真正感兴趣的是 IOU(或 Jaccard 指数)。这是因为类不仅仅是类别,它们是包含在点云中的连续结构。我们希望看到我们的预测与基本事实的重叠百分比,这就是 IOU 量化的内容。图 6 显示了如何根据集合计算 IOU。
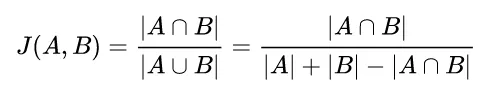
图 6. Jaccard 指数(交并比)
我们通过以下方式在 PyTorch 中计算 IOU:
def compute_iou(targets, predictions):targets = targets.reshape(-1)predictions = predictions.reshape(-1)intersection = torch.sum(predictions == targets) # true positivesunion = len(predictions) + len(targets) - intersectionreturn intersection / union 4、模型评估
从我们的训练中,我们发现在第 68 个时期训练的模型在测试集上产生了最佳的 IOU 性能。区域 6 的测试指标如下图 7 所示,对于这个区域,我们在训练和验证时使用每个分区 15000 个点,而不是 4096 个点。由于所有分割都具有相似的结构,因此模型学习到的权重会转移到更密集的测试点云。
![]()
图 7. 模型 68 的测试指标
为了真正评估我们的模型,我们在数据加载器中创建了一个特殊函数来获取构成完整空间的分区。然后我们可以将这些分区拼接在一起以获得完整空间。这样我们就可以看到整个预测空间与基本事实的比较情况。数据集的代码再次位于此处,我们可以使用以下命令获取随机空间:
points, targets = s3dis_test.get_random_partitioned_space()图 8 显示了几个完整测试空间的结果。这是几个办公室布局中分割效果良好的情况。可以看到,杂乱部分(黑色)似乎被随机分配到预测点云中的区域。
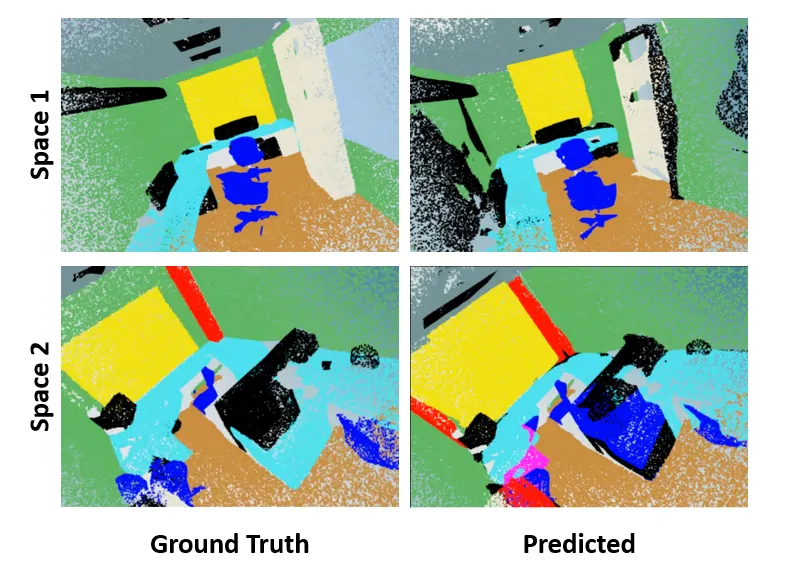
图 8. 两个随机测试空间的分割结果
完整视图看起来很不错,但检查模型在每个分区上的表现仍然很重要。这使我们能够真正看到模型如何很好地学习类的结构。各种分区的分割结果如图 9 所示。
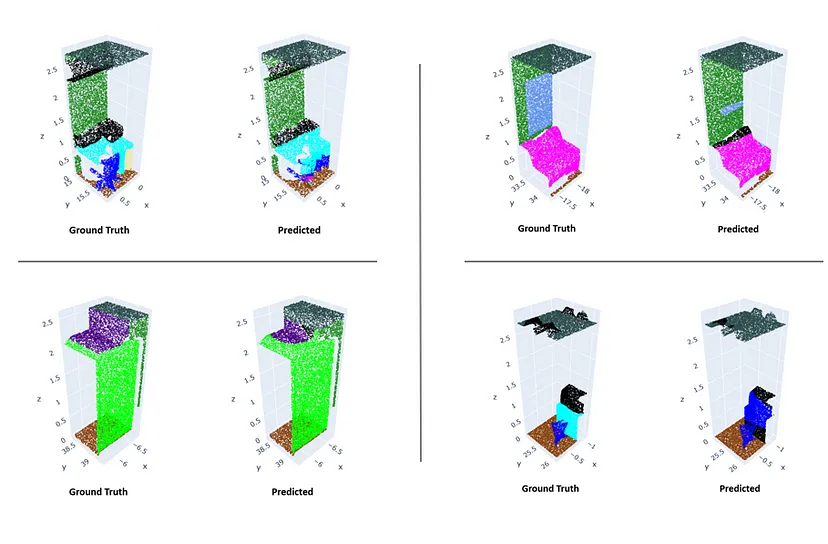
图 9. 各种测试分区的分割结果
在图 9 右上角的分区示例中,你将看到该模型难以定义杂乱(黑色)和表格(浅绿色)的边界。一般观察是,任何过度扰动都倾向于被标记为杂乱。总体而言,该模型的性能相当不错,因为它能够获得由 IOU 量化的合理分割性能。我们还可以观察到测试空间上的一些相当合理的性能,如图 8 所示。
5、临界集
如果你还记得 Point Net 文章的介绍,Point Net 能够学习点云结构的骨架,[2] 将其称为临界集(critical sets)。
在分类教程中,我们能够查看学习到的临界集,我们将在本教程中执行相同操作。我们为每个分区使用 1024 个点,因为这是模型学习到的全局特征的维度。下面给出了拼接和显示整个空间的临界集的代码。请参阅笔记本以了解更多详细信息。
points = points.to('cpu')
crit_idxs = crit_idxs.to('cpu')
targets = targets.to('cpu')pcds = []
for i in range(points.shape[0]):pts = points[i, :]cdx = crit_idxs[i, :]tgt = targets[i, :]critical_points = pts[cdx, :]critical_point_colors = np.vstack(v_map_colors(tgt[cdx])).T/255pcd = o3.geometry.PointCloud()pcd.points = o3.utility.Vector3dVector(critical_points)pcd.colors = o3.utility.Vector3dVector(critical_point_colors)pcds.append(pcd)# o3.visualization.draw_plotly([pcds]) # works in Colab
draw(pcds, point_size=5) # Non-Colab我们使用颜色的真实标签显示临界集,结果如下图 9 所示。

图 9. 随机测试空间的地面实况与学习到的临界集之间的比较
图 10 显示了另一个随机临界集的 GIF。由此可以更清楚地看出,临界集保持了室内空间的基本结构。

图 10. 随机测试空间的临界集
6、结束语
在本教程中,我们了解了 S3DIS 数据集以及如何在其上训练 Point Net。已经学会了如何组合损失函数以实现良好的分割性能。
即使我们在空间分区上进行训练,我们也能够将这些分区拼接在一起并在我们观察到良好性能的测试集上可视化它们的性能。我们能够查看学习到的临界集并确认模型实际上正在学习室内空间的底层结构。
原文链接:PointNet点云语义分割 - BimAnt