Browserless 网页抓取:Playwright 中的 NodeJS

什么是 Playwright?
Playwright 是一个用于 Web 测试和自动化的开源框架。基于 Node.js,由 Microsoft 开发,它通过单一 API 支持 Chromium、Firefox 和 WebKit。它可以在 Windows、Linux 和 macOS 上运行,并且兼容 TypeScript、JavaScript、Python、.NET 和 Java。
在 Playwright 中使用 NodeJS 进行 Web 爬取的优势是什么?
Playwright 不仅仅是一个工具,而是一个全面的 Web 爬取解决方案,结合了在 Node.js 中的强大功能、灵活性和效率,以满足现代 Web 自动化最苛刻的要求。
- 强大的页面交互处理
- 自动处理动态内容
- 抗反爬技术的韧性
在 Node.js 中,Playwright 的无头模式是一个巨大的优势。它允许你在没有可视界面的情况下运行浏览器,加快了爬取过程,非常适合大规模任务。
Playwright 能够很好地处理复杂的 Web 交互,例如加载动态内容、管理用户输入和处理异步操作。这使得它非常适合从依赖 JavaScript 的现代网站中爬取数据。网络请求拦截功能是另一个强项。它让你可以控制请求和响应,帮助绕过反爬措施并优化你的爬取过程。
Playwright 的另一个优点是它与 Node.js 项目的集成非常简单。你可以轻松地将其融入现有的工作流程中,并与其他 JavaScript 或 TypeScript 库一起使用。此外,由于它可以跨 Windows、Linux 和 macOS 运行,你可以在不同的平台上部署爬取脚本而无需任何麻烦。
什么是 Browserless?
Browserless 是由 Nstbrowser 设计的基于云的无头浏览器服务,用于执行没有图形界面的 Web 操作和自动化脚本。
Browserless 的一个关键特性是它能够通过集成的 Anti-detect、Web Unblocker 和智能代理系统绕过常见的障碍,如 CAPTCHAs 和 IP 封锁。这些工具确保你的自动化脚本即使在具有严格安全措施的网站上也能顺利运行。
Browserless 支持云容器集群,使你能够轻松扩展操作。无论你是在 Windows、Linux 还是 macOS 上运行,我们的平台都能为你的 Web 自动化需求提供一致的企业级解决方案。它设计得非常适合与你现有的工作流程无缝集成,提供一个强大且可靠的高性能 Web 操作环境。
对 Web 爬取和 Browserless 有任何精彩的想法和疑问吗?
让我们看看其他开发者在 Discord 和 Telegram 上分享了什么!
如何使用 Playwright 和 NodeJS 进行 Web 爬取?

步骤1:安装和设置 PlaywrightPlaywright
首先,请确保你的系统上已安装 Node.js。如果没有,下载并安装 LTS 版本。之后,使用 Node.js 的包管理器 npm 安装 Playwright。
npm init playwright@latest执行安装命令并进行以下选择以开始:
- 在 TypeScript 和 JavaScript 之间选择(默认是 TypeScript)。
- 命名你的测试文件夹(如果已经存在测试文件夹,则默认为
test或e2e)。 - 选择是否添加 GitHub Actions 工作流,以便在 CI 上运行测试。
- 确定是否立即安装 Playwright 浏览器(默认情况下为真,但你也可以稍后手动使用
npx playwright install安装)。
步骤2:使用 Playwright 启动浏览器
像普通的浏览器一样,Playwright 也可以渲染 JavaScript、图像等,因此它可以提取动态加载的数据。由于它模拟正常的用户行为,脚本更难以检测和阻止。
import { chromium } from 'playwright';
const browser = await chromium.launch({ headless: false }); // 打开浏览器并创建一个新标签
const page = await browser.newPage();
await page.goto('https://developer.chrome.com/'); // 访问指定的 URL
await page.setViewportSize({ width: 1080, height: 1024 }); // 设置视口大小
console.log('[浏览器已打开!]');默认情况下,Playwright 在无头模式下运行。在提供的代码中,我们通过设置 headless: false 来禁用无头模式,允许你可视化测试脚本。由于在 package.json 中启用了 "type": "module" 设置,允许 ES 模块执行,因此示例和以下代码不需要异步函数。
步骤3:开始爬取
我们将从一个基本的 Web 爬取任务开始,让你快速熟悉 Playwright。让我们提取 Amazon 上 Apple AirPods Pro 的评论!
有效的 Web 爬取始于 分析页面。你需要确定你想要提取的数据的位置。浏览器的调试控制台对我们非常有帮助:
打开网页后,你需要通过按 Ctrl + Shift + I(Windows/Linux)或 Cmd + Option + I(Mac)打开调试控制台。
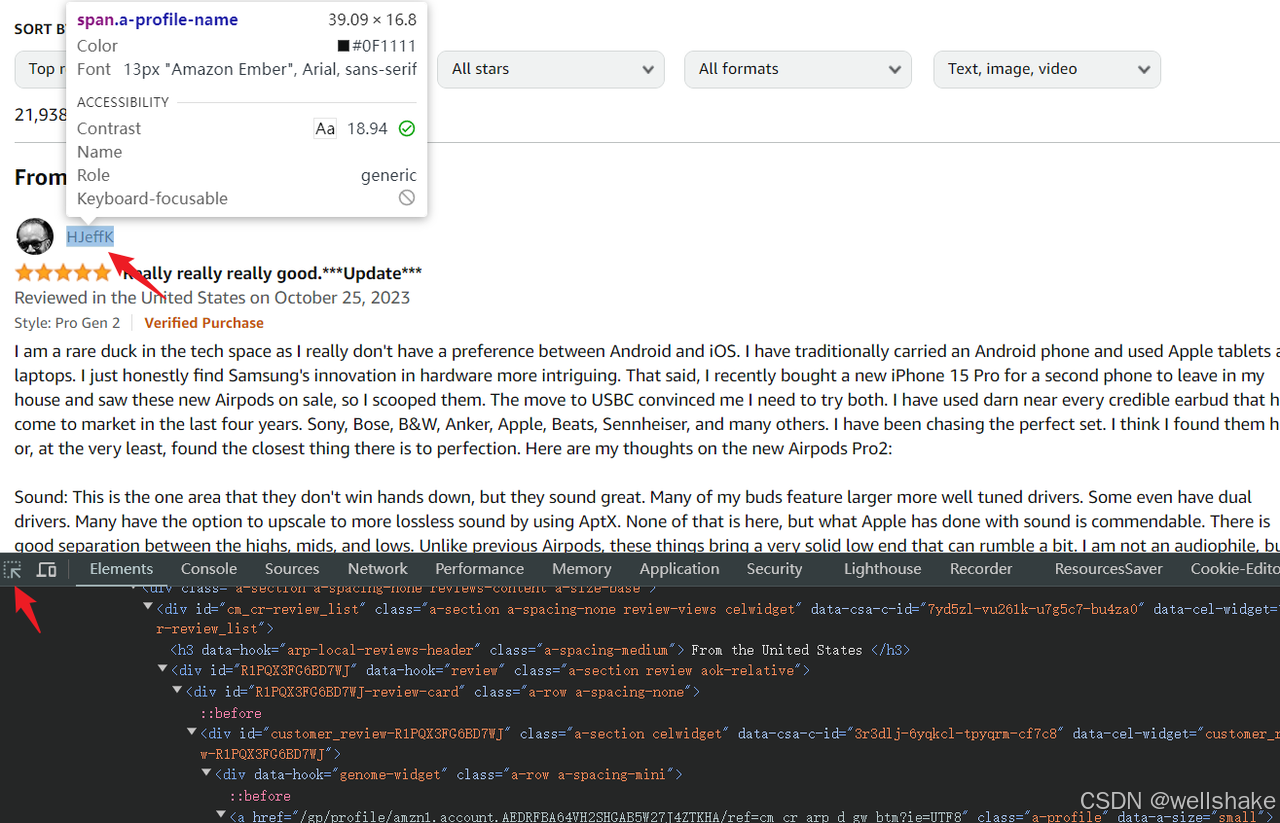
- 在控制台的左上角选择元素选择器。
- 将鼠标悬停在你想要爬取的元素上,控制台中会高亮显示对应的 HTML 代码。
Playwright 支持各种选择元素的方法,但使用简单的 CSS 选择器通常是入门的最简单方式。之前使用的 .devsite-search-field 就是 CSS 选择器的一个例子。
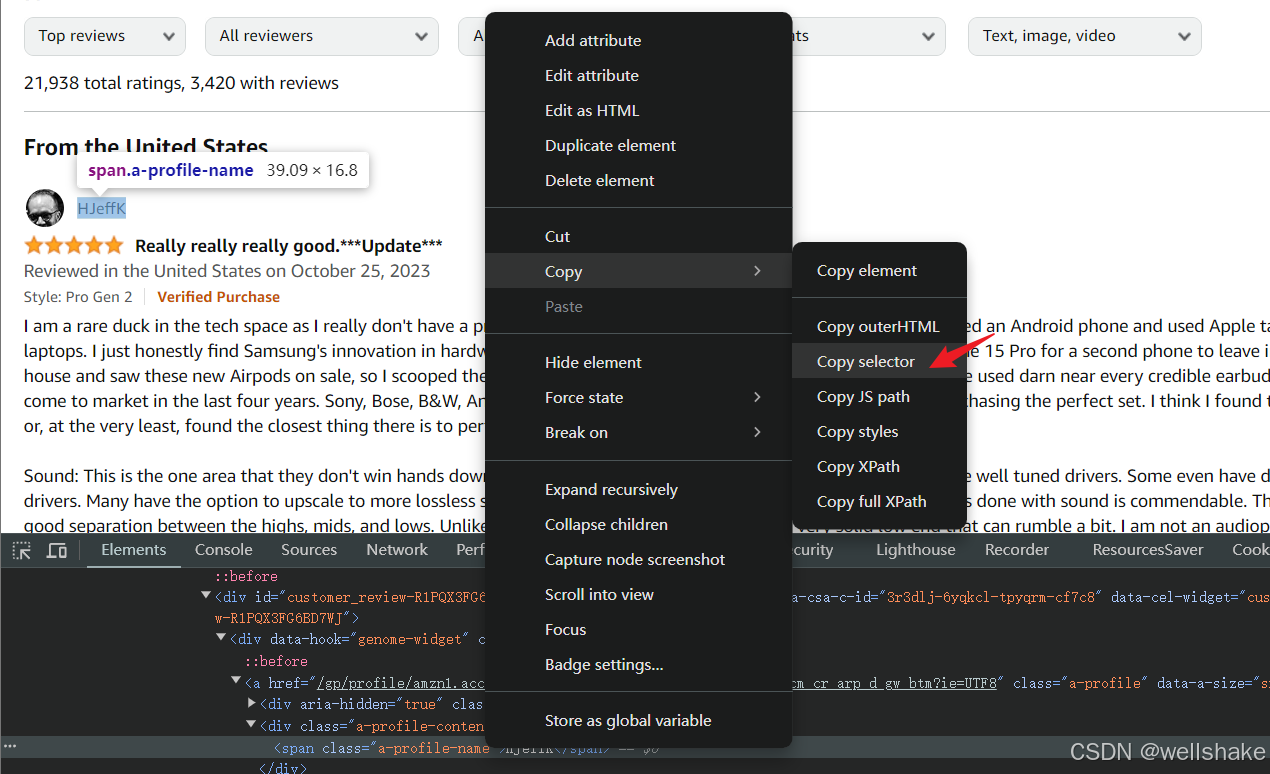
对于复杂的 CSS 结构,调试控制台可以直接复制 CSS 选择器。右键点击你想抓取的元素 HTML,并选择 打开菜单 > 复制 > 复制选择器。
现在选择器已经确定,我们可以使用 Playwright 尝试获取我上面选择的用户名。
import { chromium } from 'playwright'; // 你也可以使用 'firefox' 或 'webkit'
// 启动一个新的浏览器实例
const browser = await chromium.launch();
// 创建一个新页面
const page = await browser.newPage();
// 访问指定的 URL
await page.goto('https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews');
// 等待节点加载,最多等待10秒
await page.waitForSelector('div[data-hook="genome-widget"] .a-profile-name', { timeout: 10000 });
// 提取用户名
const username = await page.$eval('div[data-hook="genome-widget"] .a-profile-name', node => node.textContent);
console.log('[用户名]===>', username);
// 关闭浏览器
await browser.close();你可以调整代码,不仅提取单个用户名,还可以提取完整的评论列表:
- 使用
page.waitForSelector确保评论元素完全加载。 - 使用
page.$$选择所有匹配指定选择器的元素。
然后,循环遍历评论元素列表,并从每个元素中提取必要的信息。提供的代码将捕获标题、评分、用户名、文本内容和头像的 data-src 属性(包括头像的 URL)。
正如所展示的那样,代码:
page.goto用于导航到所需页面。waitForSelector用于等待目标节点正确显示。page.$eval用于获取第一个匹配的元素,并通过回调函数提取特定属性。
await page.waitForSelector('div[data-hook="review"]');
const reviewList = await page.$$('div[data-hook="review"]');接下来,我们需要遍历评论元素的列表并从每个评论元素中获取所需信息。
在以下代码中,我们可以获取内容的标题、评分、用户名和文本内容,以及头像元素节点的 data-src 属性值,这就是头像的 URL 地址。
for (const review of reviewList) {const title = await review.$eval('a[data-hook="review-title"] > span:nth-of-type(2)',node => node.textContent,);const rate = await review.$eval('i[data-hook="review-star-rating"] .a-icon-alt',node => node.textContent,);const username = await review.$eval('div[data-hook="genome-widget"] .a-profile-name',node => node.textContent,);const avatar = await review.$eval('div[data-hook="genome-widget"] .a-profile-avatar img',node => node.getAttribute('data-src'),);const content = await review.$eval('span[data-hook="review-body"] span',node => node.textContent,);console.log('[log]===>', { title, rate, username, avatar, content });
}第四步:导出数据
运行上述代码后,您应该能够在终端中看到日志信息的输出。
如果您想进一步保存这些数据,可以使用基本的 Node.js 模块 fs 将数据写入 JSON 文件,以便后续数据分析。以下是一个简单的工具函数:
import fs from 'fs';// 保存为 JSON 文件
function saveObjectToJson(obj, filename) {const jsonString = JSON.stringify(obj, null, 2);fs.writeFile(filename, jsonString, 'utf8', (err) => {err ? console.error(err) : console.log(`文件保存成功:${filename}`);});
}完整代码如下。运行后,您可以在当前脚本执行路径中找到 amazon_reviews_log.json 文件,记录了所有爬取的结果!
import { chromium } from 'playwright';
import fs from 'fs';
// 启动浏览器
const browser = await chromium.launch();
const page = await browser.newPage();
// 访问页面
await page.goto(`https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews`
);// 等待评论元素加载
await page.waitForSelector('div[data-hook="review"]');
// 获取所有评论元素
const reviewList = await page.$$('div[data-hook="review"]');
const reviewLog = [];// 遍历评论元素列表
for (const review of reviewList) {const title = await review.$eval('a[data-hook="review-title"] > span:nth-of-type(2)',node => node.textContent.trim());const rate = await review.$eval('i[data-hook="review-star-rating"] .a-icon-alt',node => node.textContent.trim());const username = await review.$eval('div[data-hook="genome-widget"] .a-profile-name',node => node.textContent.trim());const avatar = await review.$eval('div[data-hook="genome-widget"] .a-profile-avatar img',node => node.getAttribute('data-src'));const content = await review.$eval('span[data-hook="review-body"] span',node => node.textContent.trim());console.log('[log]===>', { title, rate, username, avatar, content });reviewLog.push({ title, rate, username, avatar, content });
}// 保存为 JSON 文件
function saveObjectToJson(obj, filename) {const jsonString = JSON.stringify(obj, null, 2);fs.writeFile(filename, jsonString, 'utf8', (err) => {err ? console.error(err) : console.log(`文件保存成功:${filename}`);});
}saveObjectToJson(reviewLog, 'amazon_reviews_log.json');
await browser.close();使用 Playwright 进行其他网页操作
点击按钮
使用 page.click 点击按钮,并设置延迟以使操作更像人类操作。以下是一个简单的示例。
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://example.com/'); // 访问指定的 URL
await page.waitForTimeout(3000)
await page.click('p > a', { delay: 200 })滚动页面
在 page.evaluate 上,可以通过调用 Window API 设置滚动条的位置。page.evaluate 是一个非常有用的 API:
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://www.nstbrowser.io/'); // 访问指定的 URL// 滚动到页面底部
await page.evaluate(() => {window.scrollTo(0, document.documentElement.scrollHeight);
});获取元素列表
要获取多个元素,我们可以使用 page.$$eval,它可以获取所有匹配指定选择器的元素,最后在回调函数中遍历这些元素以获取特定属性。
import { chromium } from 'playwright'
// 启动浏览器
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://news.ycombinator.com/');await page.waitForSelector('.titleline > a')
// 获取文章标题
const titles = await page.$$eval('.titleline > a', elements =>elements.map(el => el.innerText)
);
// 输出捕获的标题
console.log('文章标题:');
titles.forEach((title, index) => console.log(`${index + 1}: ${title}`));拦截 HTTP 请求
page.route 方法用于拦截页面上的请求。'**/*' 是一个通配符,表示匹配所有请求。然后可以在回调函数中处理所有请求。参数 route 用于设置请求是正常执行还是被中断,也可以用于重写响应。
import { chromium } from 'playwright'
const browser = await chromium.launch({ headless: false });
const page = await browser.newPage();await page.route('**/*', (route) => {const request = route.request();// 拦截并阻止字体请求if (request.url().includes('https://fonts.gstatic.com/')) {route.fulfill({status: 404,contentType: 'image/x-icon',body: ''});console.log('图标请求已阻止');// 拦截并阻止样式表请求} else if (request.resourceType() === 'stylesheet') {route.abort();console.log('样式表请求已阻止');// 拦截并阻止图像请求} else if (request.resourceType() === 'image') {route.abort();console.log('图像请求已阻止');// 允许其他请求继续} else {route.continue();}
});await page.goto('https://www.youtube.com/');截图
Playwright 提供了开箱即用的截图 API,这是一个非常实用的功能。您可以通过 quality 控制截图文件的质量,并通过 clip 裁剪图像。如果您对截图比例有要求,可以设置 viewport 来实现。
import { chromium } from 'playwright';const browser = await chromium.launch({ viewport: { width: 1920, height: 1080 } });
const page = await browser.newPage();
await page.goto('https://www.youtube.com/');// 捕获整个页面
await page.screenshot({ path: 'screenshot1.png' });
// 捕获 JPEG 图像,将质量设置为 50
await page.screenshot({ path: 'screenshot2.jpeg', quality: 50 });
// 裁剪图像,指定裁剪区域
await page.screenshot({ path: 'screenshot3.jpeg', clip: { x: 0, y: 0, width: 150, height: 150 } });
console.log('截图已保存');
await browser.close();Playwright vs. Puppeteer vs. Selenium
| 标准 | Playwright | Puppeteer | Selenium |
|---|---|---|---|
| 浏览器支持 | Chromium, Firefox 和 WebKit | 基于 Chromium 的浏览器 | Chrome, Firefox, Safari, Internet Explorer 和 Edge |
| 语言支持 | TypeScript, JavaScript, Python, .NET 和 Java | Node.js | Java, Python, C#, JavaScript, Ruby, Perl, PHP, TypeScript |
| 操作系统 | Windows, macOS, Linux | Windows 和 OS X | Windows, macOS, Linux, Solaris |
| 社区和生态系统 | 不断增长的社区,Microsoft 的强大支持和持续开发 | 由 Google 支持的强大社区,特别适合关注 Chromium 的用户 | 成立时间久,有庞大活跃的社区和广泛的生态系统,包括插件和集成 |
| CI/CD 集成支持 | 是 | 是 | 是 |
| 录制和回放支持 | 在 Chrome DevTools 的 Sources 面板中 | Playwright CodeGen | Selenium IDE |
| 网页抓取差异 | 具有现代功能和速度,适合不同浏览器的抓取 | 在 Chrome 中表现优秀,速度快 | 多功能的网页抓取工具,但可能较慢 |
| 无头模式 | 支持所有支持的浏览器的无头模式 | 支持无头模式,但仅限于基于 Chromium 的浏览器 | 支持无头模式,但实现因浏览器驱动而异 |
| 截图 | PDF 和图像捕获,尤其是在 Chromium 中 | PDF 和图像捕获,易于使用 | 不支持内置 PDF 捕获 |
最终想法
Playwright 非常强大!
它提供了一个强大而多功能的网页抓取工具包。此外,Playwright 的出色文档和不断增长的社区为您的自动化任务带来了极大的便利。
在这篇博客中,您对 Playwright 有了更深入的了解:
- Playwright 网页抓取的优势。
- 在 Playwright 中高效使用 NodeJS。
- 使用 Playwright 完成其他操作。