RAG优化技巧 | 7大挑战与解決方式 | 提高你的LLM: 下篇
在当今快速发展的人工智能领域,大型语言模型(LLM)已经成为无处不在的技术,它们不仅改变了我们与机器交流的方式,还在各行各业中发挥着革命性的影响。
然而,尽管LLM + RAG的能力已经让人惊叹,但我们在使用RAG优化LLM的过程中,还是会遇到许多挑战和困难,包括但不限于检索器返回不准确或不相关的数据,并且基于错误或过时信息生成答案。因此本文旨在提出RAG常见的7大挑战,并附带各自相应的优化方案,期望能够帮助我们改善RAG。
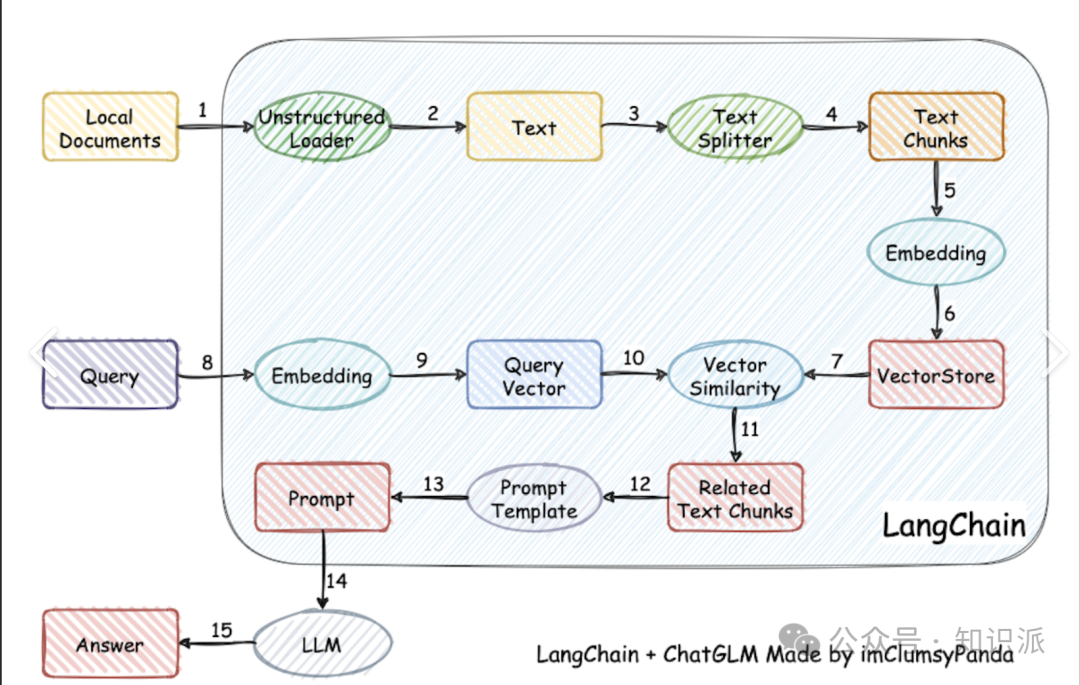
下图展示了RAG系统的两个主要流程:检索和查询;红色方框代表可能会遇到的挑战点,主要有7项:
- \1. Missing Content: 缺失內容
- \2. Missed Top Ranked: 错误排序內容,导致正确答案沒有被成功 Retrieve
- \3. Not in Context: 上限文限制,导致正确答案沒有被采用
- \4. Wrong Format: 格式错误
- \5. Incomplete: 回答不全面
- \6. Not Extracted: 未能检索信息
- \7. Incorrect Specificity: 不合适的详细回答
由于篇幅比较长,上一篇我们谈了前 3 项, 这一篇我们谈谈剩余的 4 种策略:
格式错误
当我们使用prompt要求LLM以特定格式(如表格或列表)提取信息,但却被LLM忽略时,可以尝试以下3种解决策略:
1. 改进prompt
我们可以采用以下策略来改进 prompt,解决这个问题:
A.明确说明指令
B.简化请求并使用关键字
C.提供示例
D.采用迭代提示,提出后续问题
2. 输出解析器
输出解析器负责获取LLM的输出,并将其转换为更合适的格式,因此当我们希望使用LLM生成任何形式的结构化数据时,这非常有用。它主要在以下方面帮助确保获得期望的输出:
A. 为任何提示/查询提供格式化指令
B. 对大语言模型的输出进行 解析 。
Langchain提供了许多不同类型Output Parsers的流接口,以下是示范代码,具体细节请参阅官方文档[1]。

3. Pydantic parser
Pydantic 是一个多功能框架,它能够将输入的文本字符串转化为结构化的Pydantic物件。Langchain有提供此功能,归类在Output Parsers中,以下是示范code,可以参考官方文件[2]。

回答不完整
有时候 LLM 的回答并不完全错误,但会遗漏了一些细节。这些细节虽然在上下文中有所体现,但并未被充分呈现出来。例如,如果有人询问“文档A、B和C主要讨论了哪些方面?”对于每个文档分别提问可能会更加适合,这样可以确保获得更详细的答案。
查询转换
提高 RAG 系统效能的一个策略是添加一层查询理解层,也就是在实际进行检索前,先进行一系列的 Query Rewriting。具体而言,我们可以采用以下四种转换方法:
1.1 路由:在不改变原始查询的基础上,识别并导向相关的工具子集,并将这些工具确定为处理该查询的首选。
1.2 查询重写:在保留选定工具的同时,通过多种方式重构查询语句,以便跨相同的工具集进行应用。
1.3 子问题:将原查询拆解为若干个更小的问题,每个问题都针对特定的工具进程定向,这些工具是根据它们的元数据来选择。
1.4 ReAct 代理选择器:根据原始查询判断最适用的工作,并为在该工作上运行而特别构造了查询。
Llamaindex已经为这个问题整理出了一系列方便操作的功能,请查看官方文件[3];而Langchain的大部分功能则散落在Templates中,例如HyDE的实现和论文内容。以下是使用Langchain进行HyDE的示例:
from langchain.llms import OpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain, HypotheticalDocumentEmbedder
from langchain.prompts import PromptTemplatebase_embeddings = OpenAIEmbeddings()
llm = OpenAI()# Load with `web_search` prompt
embeddings = HypotheticalDocumentEmbedder.from_llm(llm, base_embeddings, "web_search")# 现在我们可以将其用作任何嵌入类!
result = embeddings.embed_query("Where is the Taj Mahal?")
Not Extracted(未能检索信息)
当RAG系统面对众多信息时,往往难以准确提取出所需的答案,关键信息的遗漏降低了回答的质量。研究显示,这种情况通常发生在上下文中存在过多干扰或矛盾信息时。以下是针对这一问题提出的三种解决策略:
1. 数据清洗
数据的质量直接影响到检索的效果,这个痛点再次突显了优质数据的重要性。在责备你的 RAG 系统之前,请确保你已经投入足够的精力去清洗数据。
2. 信息压缩
提示信息压缩技术在长上下文场景下,首次由 LongLLMLingua 研究项目提出,并已在 LlamaIndex 中得到应用,相对 Langchain 的资源则较零散。现在,我们可以将 LongLLMLingua 作为节点后处理器来实施,这一步会在检索后对上下文进行压缩,然后再送入 LLM 处理。
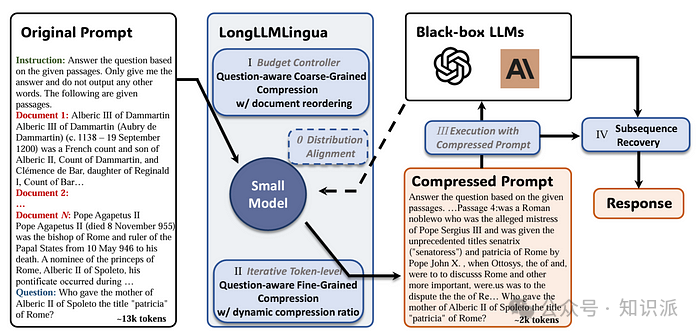
以下是在 LlamaIndex 中使用 LongLLMLingua 的示范,其他细节可以参考官方文件[4]:

3. LongContextReorder
这在第二个挑战,Missed Top Ranked中有提到,为了解决LLM在文件中间会有「迷失」的问题,它通过重新排序检索到的节点来优化处理,特别适用于需要处理大量顶级结果的情形。细节示范可以参考上面的内容。
不正确的具体性(Incorrect Specificity)
有时,LLM 的回答可能不够详细或具体,用户可能需要进行多次追问才能得到清晰的解答。这些答案可能过于笼统,无法有效满足用户的实际需求。
因此,我们需要采取更高级的检索策略来寻找解决方案。
当我们发现回答缺乏期望的详细程度时,通过优化检索策略可以显著提升信息获取的准确性。LlamaIndex 提供了许多高级检索技巧,而Langchain 在这方面资源较少。以下是一些在 LlamaIndex 中能够有效缓解此类问题的高级检索技巧:
- • Auto Merging Retriever[5]
- • Metadata Replacement + Node Sentence Window[6]
- • Recursive Retriever[7]
总结
本文探讨了使用 RAG 技术时可能面临的七大挑战,并针对每个挑战提出了具体的优化方案,以提升系统准确性和用户体验。
- • 缺失内容:解决方案包括数据清理和提示工程,确保输入数据的质量并引导模型更准确地回答问题。
- • 未识别出的最高排名:可通过调整检索参数和优化文件排序来解决,以确保向用户呈现最相关的信息。
- • 背景不足:扩大处理范围和调整检索策略至关重要,以包含更广泛的相关信息。
- • 格式错误:可以通过改进提示、使用输出解析器和
Pydantic解析器实现,有助于按照用户期望的格式获取信息。 - • 不完整部分:可通过查询转换来解决,确保全面理解问题并作出回应。
- • 未提取部分:数据清洗、消息压缩和
LongContextReorder是有效的解决策略。 - • 特定性不正确:可以通过更精细化的检索策略如 Auto Merging Retriever、元数据替换等技巧来解决问题,并进一步提高信息查找精度。
通过对 RAG 系统挑战的深入分析和优化,我们不仅可以提升LLM的准确性和可靠性,还能大幅提高用户对技术的信任度和满意度。
希望这篇能帮助我们改善我们的 RAG 系统。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。