统一 transformer 与 diffusion !Meta 融合新方法剑指下一代多模态王者
本文引入了 Transfusion,这是一种可以在离散和连续数据上训练多模态模型的方法。
来源丨机器之心
一般来说,多模态生成模型需要能够感知、处理和生成离散元素(如文本或代码)和连续元素(如图像、音频和视频数据)。
在离散模态领域,以预测下一个词为目标的语言模型占据主导地位,而在生成连续模态方面,扩散模型及其泛化形式则是当前最先进技术。
研究者一直试图将语言模型与扩散模型结合,一种方法是直接扩展语言模型,使其能够利用扩散模型作为一个工具,或者将一个预训练的扩散模型嫁接到语言模型上。另一种替代方案是对连续模态进行量化处理,然后在离散的 token 上训练一个标准的语言模型,这种方法虽然简化了模型架构,但也会造成信息的丢失。
在这项工作中,来自 Meta 、 Waymo 等机构的研究者展示了通过训练单个模型来预测离散文本 token 和扩散连续图像,从而实现两种模态的完全集成,且不会丢失任何信息。
具体而言,本文引入了一个训练模型的新方法 Transfusion,能够无缝地生成离散和连续的模态。Transfusion 将语言模型损失函数与扩散相结合,在混合模态序列上训练单个 transformer。
该研究还在文本和图像数据混合基础上从头开始预训练多个 Transfusion 模型,最多可达到 7B 参数量,并针对各种单模态和跨模态基准建立扩展定律

论文地址:https://arxiv.org/pdf/2408.11039
论文标题:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
实验表明,Transfusion 的扩展能力显著优于将图像量化并在离散图像 token 上训练语言模型的方法。通过引入特定于模态的编码和解码层,该研究证明可以进一步提高 Transfusion 模型的性能,并且甚至可以将每张图像压缩到仅 16 个 patch。
最后将 Transfusion 方法扩展到 70 亿参数和 2 万亿多模态 token,能够生成与相似规模的扩散模型和语言模型相媲美的图像和文本,从而获得两个领域的优势。这意味着 Transfusion 模型不仅能够处理图像和文本的生成,还能在这两种类型的生成上达到领先水平,有效地结合了图像和文本生成的优点。
在 GenEval 基准测试中,本文模型(7B)优于其他流行模型,例如 DALL-E 2 和 SDXL;与那些图像生成模型不同,它可以生成文本,在文本基准测试中达到与 Llama 1 相同的性能水平。因此,Transfusion 是一种很有前途的训练真正多模态模型的方法。
Transfusion 介绍
Transfusion 是一种训练单一统一模型来理解和生成离散和连续模态的方法。本文的主要创新是证明了可以在共享数据和参数上对不同模态使用单独的损失(针对文本使用语言建模,针对图像使用扩散)。图 1 说明了 Transfusion。
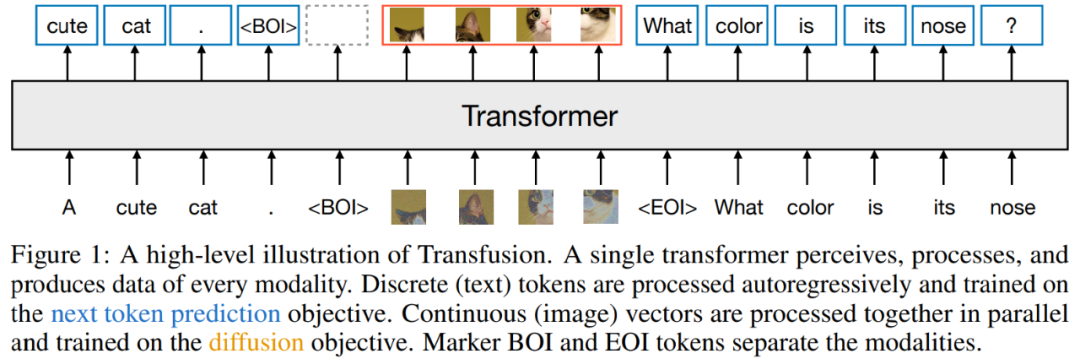
模型架构:模型中的大部分参数来自单个 transformer,用来处理每一个序列,不论其模态如何。Transformer 接收一系列高维向量作为输入,并产生相似的向量作为输出。研究者为了将数据转换成这种空间,他们使用了具有非共享参数的轻量级特定于模态的组件。
对于文本,这些是嵌入矩阵,Transformer 将每个输入的整数转换成向量空间,每个输出向量转换成一个关于词汇表的离散分布。
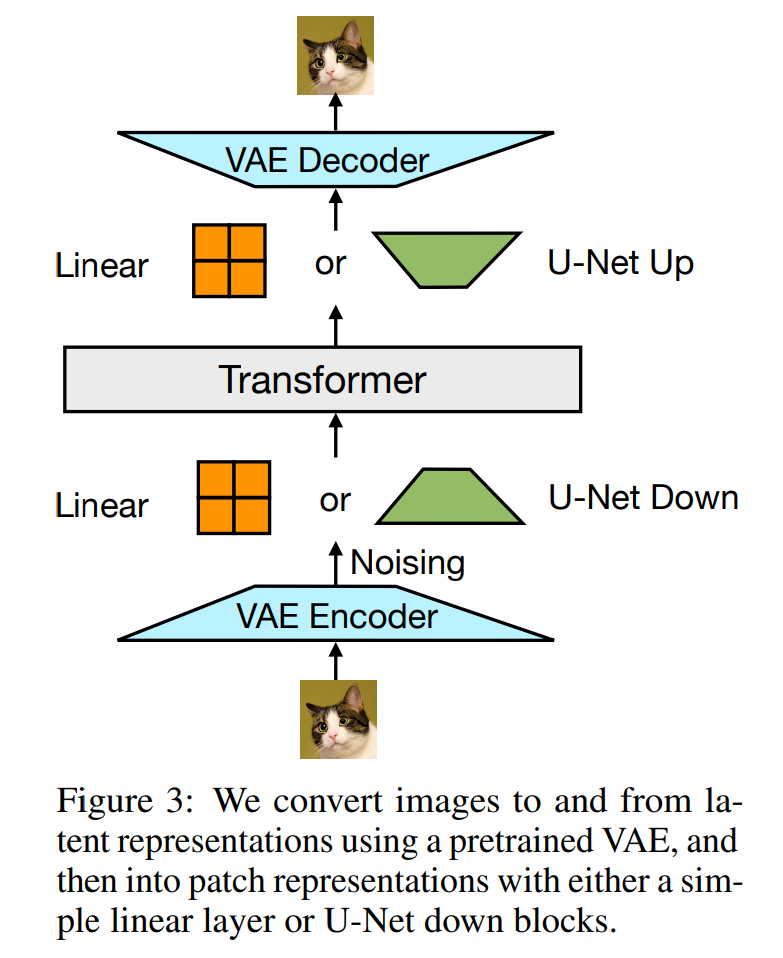
对于图像,研究者尝试了两种方法来压缩 k×k patch 向量的局部窗口到一个单一 transformer 向量(以及反向操作):(1)一个简单的线性层;(2)U-Net 的 up 和 down 块。图 3 展示了整体架构。
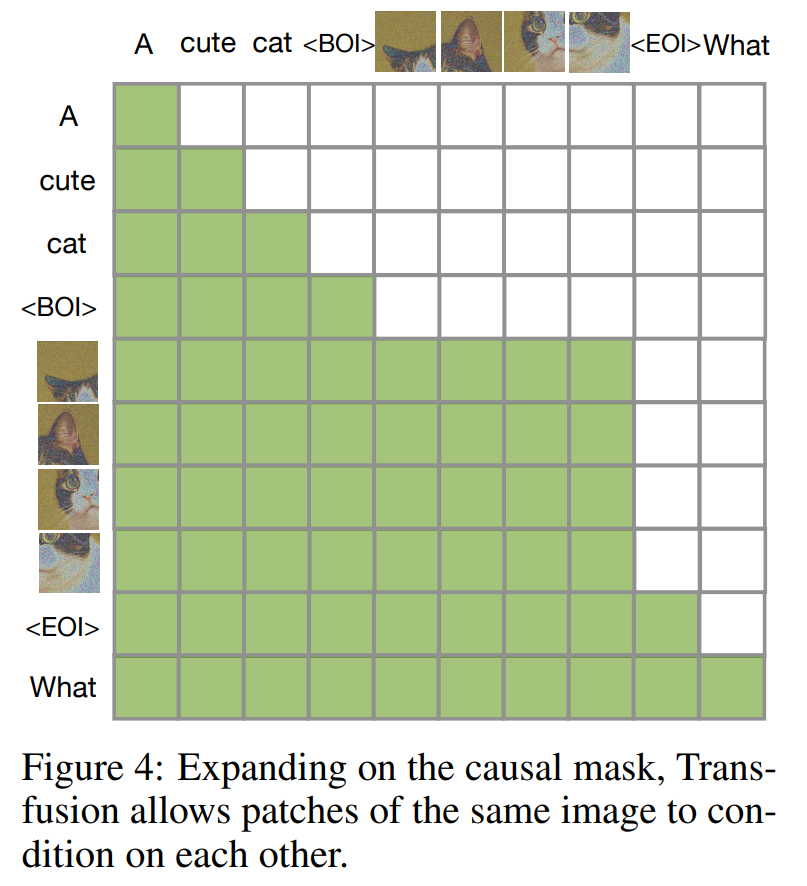
Transfusion 注意力:语言模型通常使用因果掩码来有效地计算单个前向 - 后向传播中整个序列的损失和梯度,而不会泄露未来 token 的信息。虽然文本是自然连续的,但图像不是,并且通常使用不受限制的(双向)注意力进行建模。
Transfusion 通过将因果注意力应用于序列中的每个元素,并将双向注意力应用于每个单独图像的元素中,从而结合了两种注意力模式。这使得每个图像 patch 能够关注同一图像中的每一个其他 patch,但只限于关注序列中之前出现的文本或其他图像的 patch 。这种设计允许图像内部的高效信息交流,同时限制了与序列前面内容的交互,有助于模型在处理复杂数据序列时,更好地聚焦和整合相关信息。图 4 显示了 Transfusion 注意力掩码的示例。
训练目标:为了训练模型,研究者将语言建模目标![]() 应用于文本 token 的预测;将扩散目标
应用于文本 token 的预测;将扩散目标![]() 应用于图像 patch 的预测。总损失可以表示为如下形式:
应用于图像 patch 的预测。总损失可以表示为如下形式:

实验结果
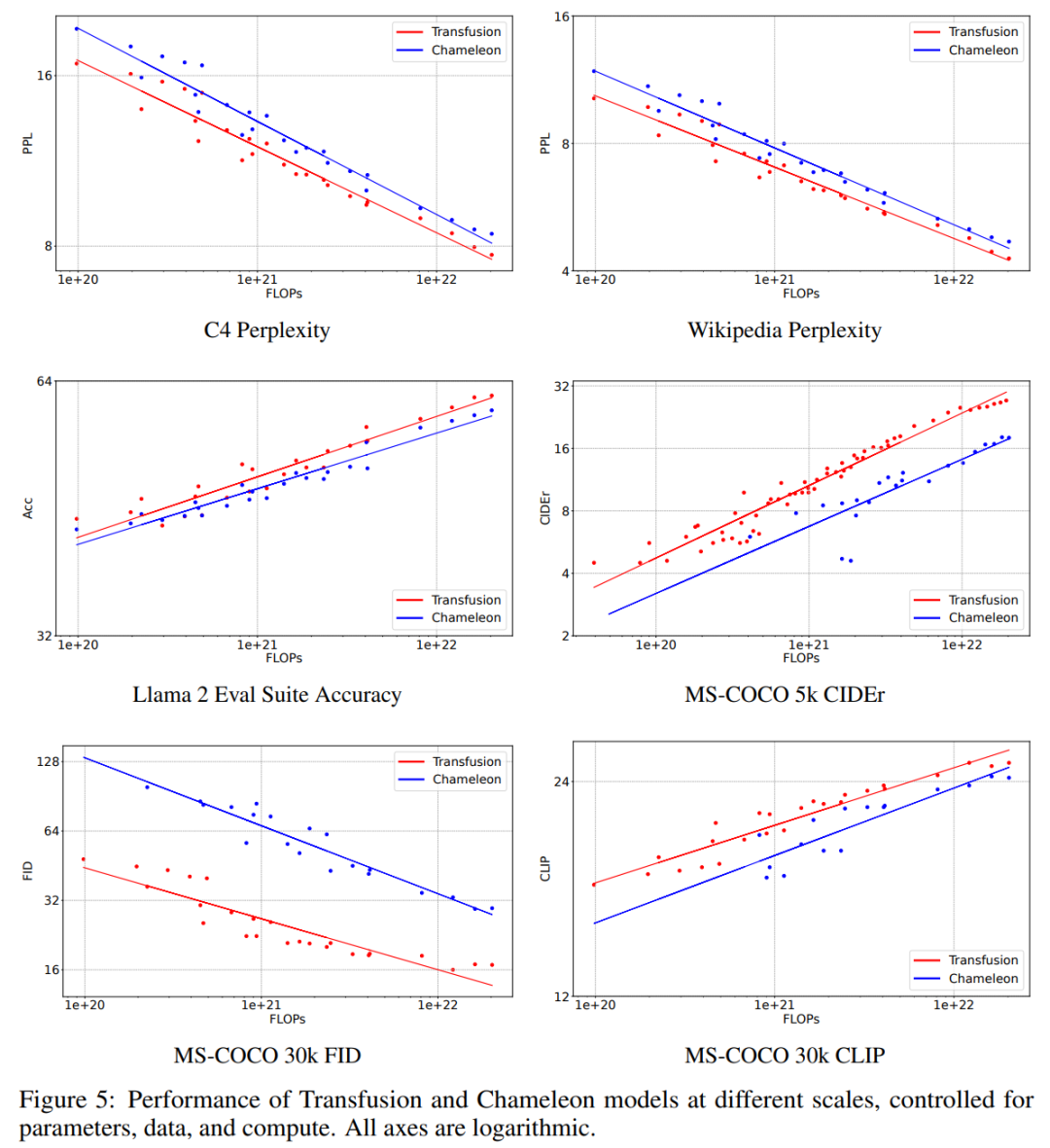
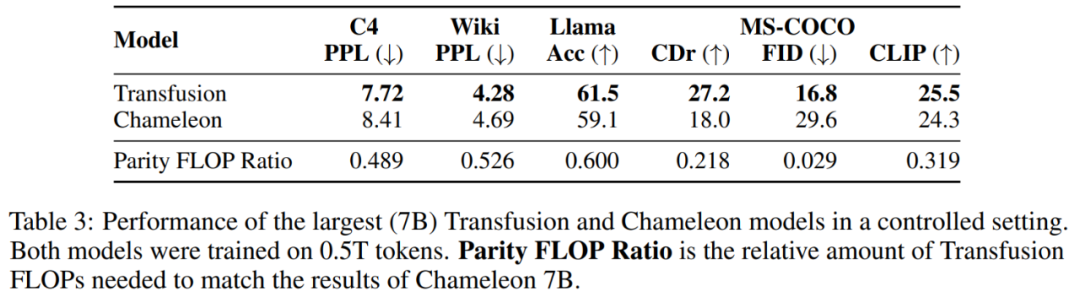
该研究通过实验证明了 Transfusion 是一种可行、可扩展的统一多模态模型训练方法。研究者在一系列标准的单模态和跨模态基准上评估模型性能,如表 1 所示。
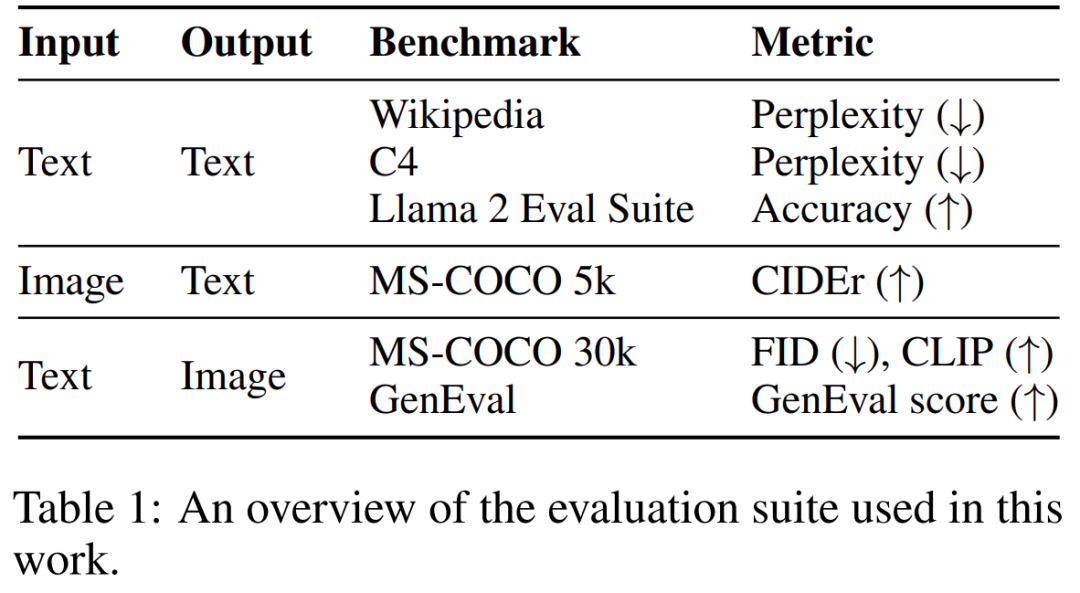
图 5 直观显示了扩展趋势。在每个基准测试中,Transfusion 始终表现出比 Chameleon 更好的扩展规律。虽然线条接近平行,但 Transfusion 的优势更明显。
该研究在 2T token 的数据集上训练了一个 7B 参数模型,生成的图像如下所示:

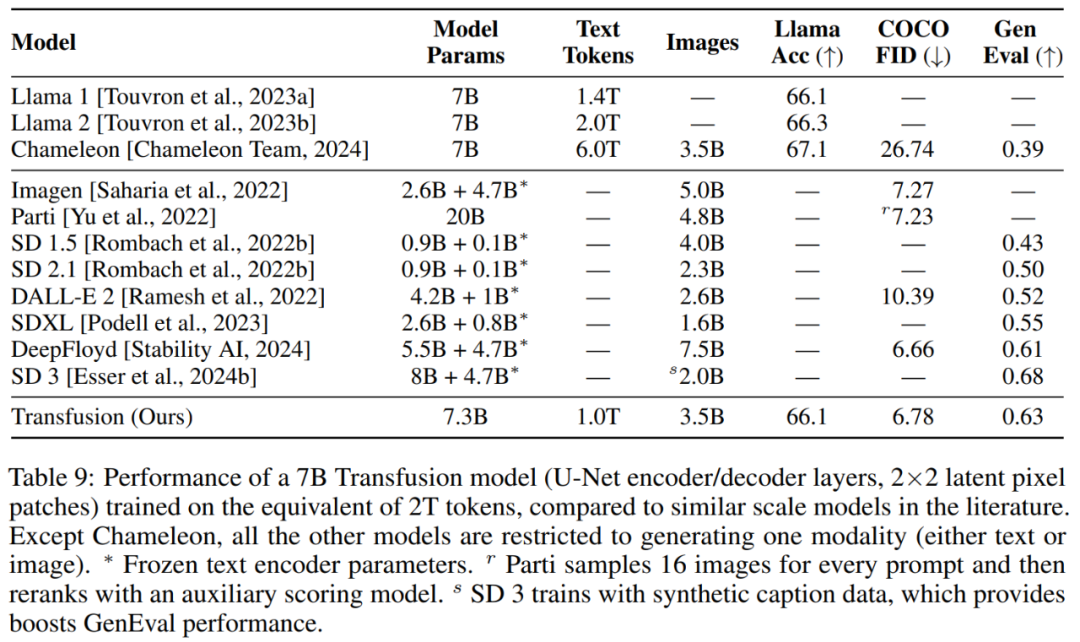
表 9 显示,Transfusion 实现了与 DeepFloyd 等高性能图像生成模型类似的性能,同时超越了之前发布的模型,包括 SDXL。
图像编辑。经过微调的 Transfusion 模型可以按照指示执行图像编辑,比如将纸杯蛋糕从盘子中移除。
