hdfs的慢盘检测
这是我的第105篇原创文章
慢盘检测引入的背景
hdfs作为一个存储系统,势必会使用大量的磁盘。然而,在长期的使用过程中,磁盘也难免会磨损,出现损坏的磁道或扇区,导致磁盘读写变慢,IO操作耗时变长,从而引发业务的耗时增加(例如spark/flink计算任务的耗时增加等)。但是,要确认是磁盘变慢引起的业务耗时增加,这个排查过程是比较困难的,同时排查过程也是非常耗时耗力的。
在“降本增效”,运维便利性大环境的趋势下,hdfs引入了慢盘检测的特性。
慢盘识别的原理
所谓"慢盘",只是一个相对的概念,也就是在同一个DN中,对某个磁盘IO操作的耗时相比其他磁盘更大,并且超过了配置的指定阈值,那么这个盘就被定义为"慢"盘。
了解了这个慢盘的定义,其实慢盘识别的大概逻辑基本上也就清楚了。既然是比较磁盘IO操作的耗时,自然而然首先是要记录IO的耗时。在Datanode里面,每次涉及磁盘IO操作的动作,都会统计其耗时,例如sync、flush、read、write等,这些信息最终都会被存储在metrics中。
有了IO操作耗时的统计之后,在独立的慢盘检测线程中,会定时获取所有磁盘的IO操作耗时信息,然后按类别分别计算出绝对中位差,根据中位差计算出上限值(包括与配置指定阈值的比较,两者取较大的值作为真正的上限值),磁盘IO操作耗时大于这个上限值的就是慢盘了。
注:任意一种操作类型的耗时大于该类型计算出的上限值,都会被认为是慢盘。
相关代码如下所示:
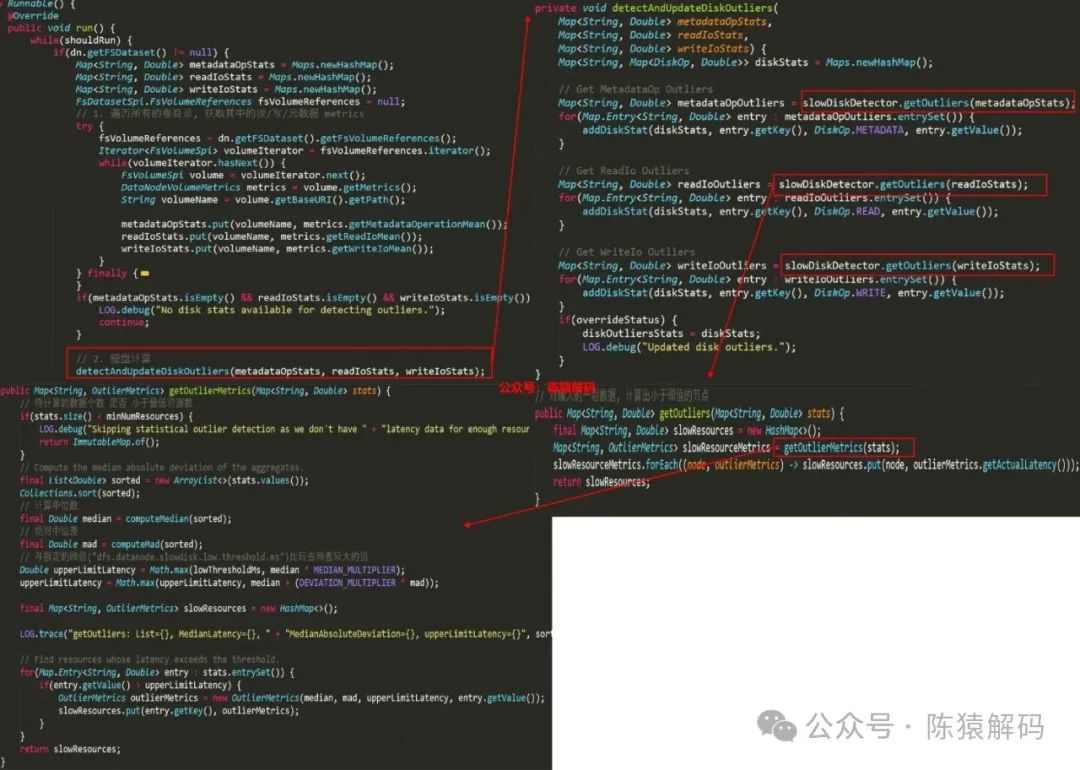
慢盘识别的处理
慢盘识别后,datanode会通过心跳向namenode汇报,并最终在可以JMX指标中查看。这样,通过定时获取这些指标信息,可以快速地识别出哪些是慢盘,协助运维。
除此之外,从使用者的角度来看,一旦检测出慢盘后,后续的block应该要能尽量避免写入该盘。
原生能力中,通过参数控制排除慢盘的个数达到这个效果。具体来说就是,当识别出慢盘后,按IO操作耗时排序,将"最慢"的N个盘(参数控制)加入到待排除列表中。当有block写入,进行磁盘挑选时,从候选磁盘列表中过滤掉这些慢盘,再从剩下的磁盘中继续按原有逻辑挑选合适的磁盘。
慢盘检测相关的配置参数有:
// IO操作的采样率, 大于0意味着启用慢盘检测,默认值为0
dfs.datanode.fileio.profiling.sampling.percentage
// 慢盘检测的时间间隔,默认值为30min
dfs.datanode.outliers.report.interval
// 慢盘检测的的最小磁盘个数,默认值为5
dfs.datanode.min.outlier.detection.disks
// 慢盘IO耗时阈值, 即IO耗时超过这个值才可能被定义为慢盘,默认值为20ms
dfs.datanode.slowdisk.low.threshold.ms
// block分配磁盘时最大可以排除的慢盘个数,默认值为0
dfs.datanode.max.slowdisks.to.exclude原生逻辑的一些问题
1)检测逻辑的局限性
首先,metrics中记录的IO操作耗时,其周期单位是10s,即每个操作耗时实际上是每10s内的平均值,每隔10s进行清零重新计算。对应的配置在hadoop-metircs2.properties中(*.period),metrics具体的统计计算逻辑在这里不展开说明,后续单独整理。
那么,慢盘检测线程定时获取到的IO操作耗时,实际上是该时间点往前推10s(最多20s)内的平均耗时。
正常情况下对hdfs写入来说,各个盘的写入量是差不多的,如果进入写入高峰期,那就是整个节点所有盘的写入速度都明显变慢,没有异常值,这种情况是不会报磁盘慢的。但如果出现特殊情况,只有个别盘突然进入一个短暂高峰期,它的写延迟将明显上涨,在这个时间段内恰好遇到慢盘检测,那么就会将该盘识别为慢盘,这显然是不合理的情况。
对于这个问题,社区上有提供相应的patch,但一直没有被纳入。其优化逻辑为:采用计数的方式来判断这个磁盘是否真正出了问题。每5分钟做一次统计,如果在一个小时内,出现了6次以上的写入慢,可以认为这是一块有问题的磁盘,将生成SlowDiskReport报告给NN。
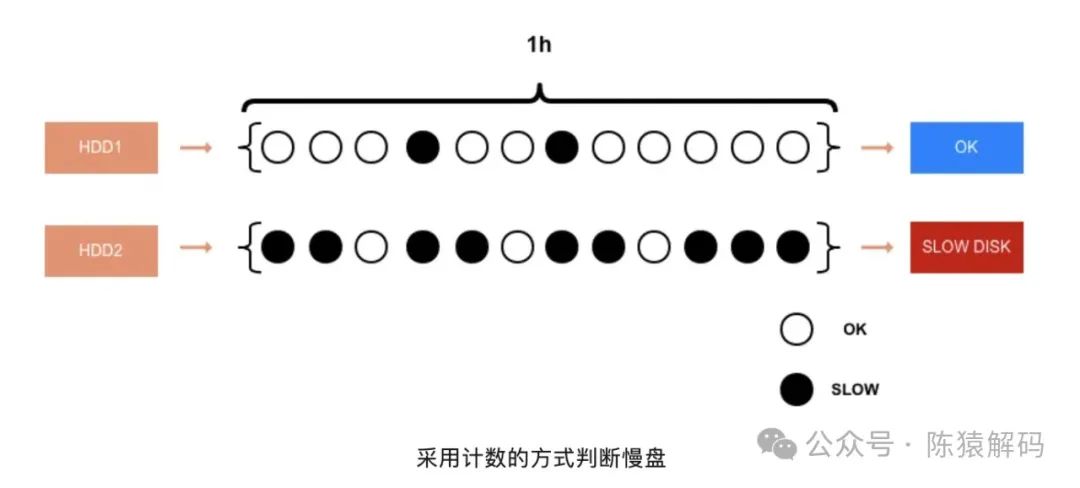
具体的实现方式是,每个盘都维护一个长度为12的Queue,每5分钟尝试更新一次Queue,如果盘的WriteIo平均值大于upperLimitLatency,就将此刻timestamp加入Queue,表示在这一周期出现了写入磁盘慢,如果Queue满了就把队首成员踢掉再入列。在生成SlowDiskReport的时候,如果队列是满的且队首成员的timestamp在一个小时以内,就意味着,在最近一个小时,磁盘写慢的时间超过了30分钟,该磁盘将会被加入SlowDiskReport上报给NN。
2)没有区分不同的存储介质
慢盘检测默认是对同一个DN中的所有卷目录所在磁盘来比较,无法过滤掉指定卷目录,也无法仅对指定卷目录进行检测。那么,在同一个DN中有不同存储介质的场景下,比如SSD与HDD混合,慢盘检测逻辑就不够准确了,因为HDD的IO操作耗时显然是比SSD的IO操作耗时要高很多的,因此在HDD中,即便是正常的IO操作耗时,也可能会被识别为慢盘。
3)写入的完全屏蔽
从前面的逻辑,我们可以知道,通过配置可排除慢盘的数量,来控制block写入时是否避免写入慢盘。例如某个磁盘一旦被识别为慢盘,并且在磁盘选择逻辑时被排除了, 那么在下个慢盘检测时间点之前,该磁盘上都不会有新的IO操作,如此一下, 到下个检测时间点计算慢盘时,该盘不会被识别为慢盘,这样就又可以继续写入了。
但是,如果在下个慢盘检测点之前,其他磁盘都写满了,按照原生逻辑,即便慢盘上还有足够的空间,数据仍旧是不会被写入的。在不需要考虑性能的时候,这种有空间但无法写入带来的失败可能是业务侧无法接受的。
4)读取没有优化
虽然datanode识别出慢盘后,也将慢盘的信息通过心跳汇报给了namenode,但是namenode也仅仅是通过jmx进行呈现,并没有做额外的处理。
但是,我们在实际使用过程中,却遇到过这么一个问题,spark任务在计算过程中,对存储在hdfs中的表数据进行读取,其耗时比正常情况下多了2-3倍,最后发现虽然待读取的数据都是3副本,但从namenode获取block所在DN列表时,排在列表中首位的DN恰好分别位于几个慢盘上的DN。也就是说,绝大部分的block都是从位于慢盘的DN节点中读取的。
因此,原生的逻辑仅考虑了尽量避免写入慢盘的场景,而没有考虑block读取时优先选择非慢盘的节点。
总结
小结一下,本文主要讲解了hdfs中慢盘检测识别的原理,以及识别后的处理,同时结合实际过程中的经验,指出了原生逻辑的不足
针对这些不足,我们在引入第三方patch的同时,也针对性的进行了相应代码修改。例如过滤SSD介质的磁盘,仅对HDD的磁盘进行慢盘检测;例如参考慢盘检测中,IO操作的取样率;数据在写入时,也按照一定的概率写入慢盘,而不是完全过滤掉慢盘,尤其是仅有慢盘可写时;同样,DN将慢盘信息上报到NN后,客户端向NN获取block所在的DN节点列表时,对DN列表进行排序,如果存在慢盘,则放到列表的末端,实现尽量不从慢盘来读取数据。
好了,这就是本文的全部内容,如果觉得本文对您有帮助,请点赞+转发,如果觉得有不正确的地方,欢迎留言交流~
参考:
[1] https://issues.apache.org/jira/browse/HDFS-15744
[2] HDFS慢节点监控及处理 https://mp.weixin.qq.com/s/wP8MlQr6Q-Z542YzpBCZEA