Google提出 Speculative RAG:通过草稿机制增强检索增强生成
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

近年来,大型语言模型(LLMs)逐渐被用于为用户提供问答服务。然而,尽管应用广泛,LLMs在面对知识密集型问题时,常常会出现事实性错误,甚至生成虚构内容(即无法验证的描述)。特别是当问题需要最新信息或涉及较为冷门的事实时,LLMs的表现尤为不理想。例如,当用户询问“最新款谷歌Pixel手机的功能有哪些?”时,LLMs可能会给出过时或不准确的信息。
为了应对这些问题,检索增强生成(RAG)应运而生,成为一种有望改善这一现状的解决方案。RAG通过利用外部知识库检索相关文档,并将检索到的信息融入生成的内容中,从而有效减少了知识密集型任务中的事实错误。然而,处理较长文档时,复杂的推理任务可能导致显著的延迟。尽管一些研究已探索延长LLMs上下文长度的路径,但如何在延长的上下文中实现扎实的推理仍是一个尚未解决的挑战。因此,在RAG系统中,如何在效率与效果之间找到平衡已成为一个核心研究焦点。
在《Speculative RAG: 通过草稿机制增强检索增强生成》一文中 (https://arxiv.org/pdf/2407.08223),研究者提出了一种新框架,通过引入一个更小的专用RAG起草模块,来分担主要模型的计算负担。该模块经过针对RAG任务的微调,旨在作为现有通用模型的高效且稳健的RAG组件。
Speculative RAG采用了草稿生成的方法,与推测解码类似。推测解码通过使用较小的模型同时快速生成多个候选内容,再与基础模型并行验证,从而加速了自回归模型的推理过程。研究表明,Speculative RAG在多个基准测试中均表现出了显著的精度提升和延迟减少。
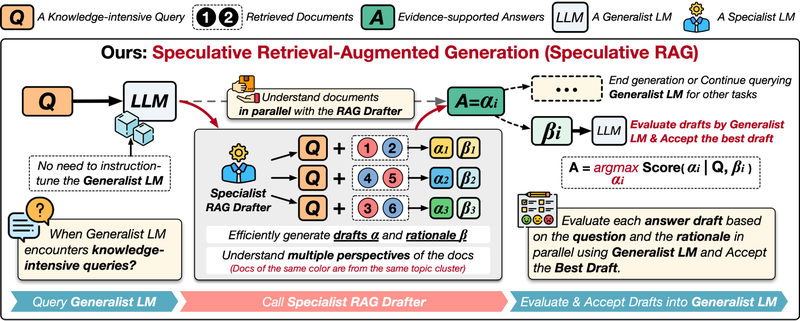
Speculative RAG的工作原理
Speculative RAG包含两个核心部分:(1)专用的RAG起草器,(2)通用的RAG验证器。首先,基础模型的检索模块从知识库中检索相关文档。然后,Speculative RAG将计算负担分配给专用的RAG起草器,这是一种专门用于处理检索文档的小型模型,主要负责基于文档快速生成回答和推理内容。这样,通用验证器只需关注验证这些草稿答案的准确性,而无需逐一深入审查冗余的文档。
例如,在回答“谁在1980年电影《九到五》中饰演Doralee Rhodes?”时,检索模块会从知识库中获取多个相关文档。接着,Speculative RAG起草器会根据不同的文档子集并行生成多个草稿答案。由于检索的文档可能包含关于1980年电影和2010年音乐剧《九到五》的信息,通用RAG验证器会计算每个草稿的生成概率,并根据准确性赋予其信心分数。最终,验证器选出与1980年电影相关的草稿作为最终答案。
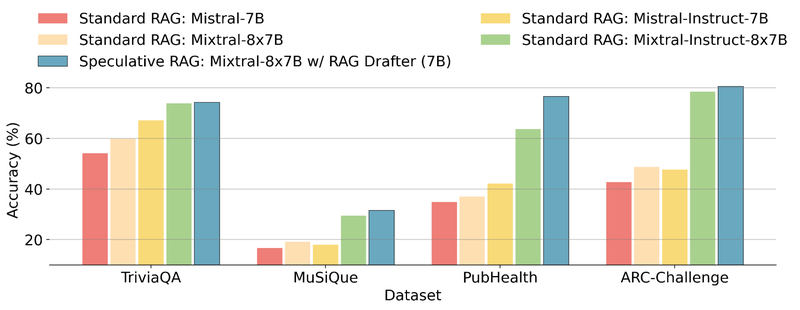
实验结果
Speculative RAG在多个公共RAG基准测试中展现了其高效性和准确性。研究人员使用Mistral-7B模型作为专用起草器,并通过Open Instruct数据集和Contriever-MS MARCO等文档对其进行微调。此外,Mixtral-8x7B模型作为通用验证器,不需要进一步训练。在TriviaQA、MuSiQue、PubHealth和ARC-Challenge数据集上,Speculative RAG的表现均优于标准RAG系统。在PubHealth数据集上,Speculative RAG的准确率比最佳基线系统Mixtral-Instruct-8x7B高出12.97%。
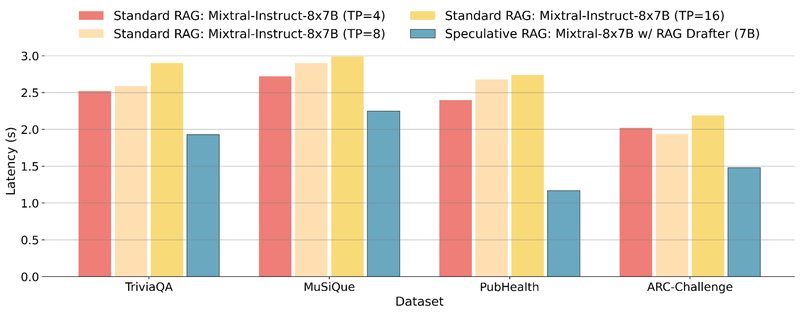
延迟的显著改善
由于RAG系统需要处理大量检索文档,延迟是一个关键挑战。在实验中,Speculative RAG通过并行草稿生成,大幅减少了延迟时间。例如,在PubHealth数据集上,Speculative RAG的延迟比标准RAG系统减少了51%。
总结
Speculative RAG通过将RAG任务分解为起草和验证两步,显著提升了生成内容的质量和速度。它利用专用起草器生成多个候选答案,再由通用模型进行验证,最终实现了精度提升高达12.97%,并将延迟减少了51%。Speculative RAG为通过任务分解提高RAG性能提供了新的思路。