让具身智能更快更强!华东师大上大提出TinyVLA:高效视觉-语言-动作模型,遥遥领先

论文链接:https://arxiv.org/pdf/2409.12514
项目链接:https://tiny-vla.github.io/
具身智能近期发展迅速,拥有了大模型"大脑"的机械臂在动作上更加高效和精确,但现有的一个难点是:模型受到算力和数据的制约。如何使用更少的训练数据,以更快的推理速度,实现媲美OpenVLA的性能?今天给大家分享的TinyVLA,就是来解决这个难题的,还有多种规模的模型可供选择!
总结速览
解决的问题:现有的视觉-语言-动作(VLA)模型在推理速度慢和需要大量机器人数据进行预训练方面面临挑战,限制了实际应用。
提出的方案:引入一种新型紧凑型视觉-语言-动作模型TinyVLA,提供更快的推理速度和更高的数据效率,消除预训练阶段的需求。
应用的技术:TinyVLA框架包括两个关键组件:1) 使用高效的多模态模型初始化策略骨干;2) 在微调过程中集成扩散策略解码器,以实现精确的机器人动作。
达到的效果:TinyVLA在仿真和实际机器人上进行了广泛评估,显著优于现有的VLA模型OpenVLA,在速度和数据效率上表现更佳,同时在语言指令、未知物体、位置变化等方面展现出强大的泛化能力。
方法
1. 训练轻量级VLM模型。 现有的VLM大多在30亿参数以上,推理速度较慢,训练周期长,因此我们训练了一系列更加紧凑的VLM模型,我们使用pythia作为我们的LLM部分,参照LLaVA的框架我们训练了3个不同大小的VLM,参数量从4亿到14亿。以此作为我们VLA的主干网络。
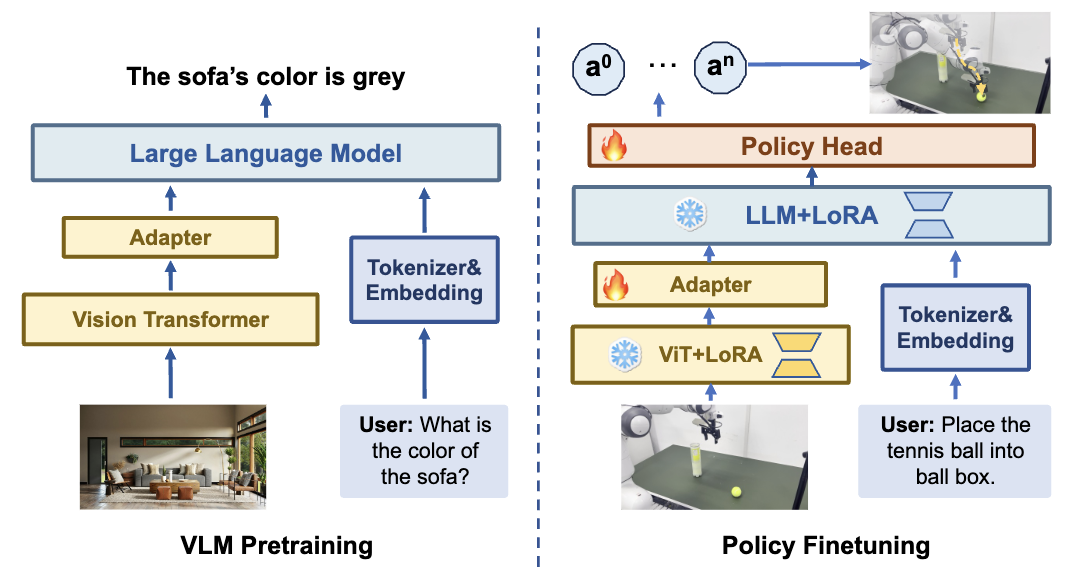
2. 机器人数据微调VLA模型。 我们用训练好的VLM权重来初始化我们的VLA模型,但是VLM只能生成语言,无法直接生成动作;OpenVLA和RT-2采用将动作离散化的方式,将动作预测任务转变成next token prediction任务,但这种方式会使得模型的训练难度大大增加;因此我们采取用policy head 网络替换原有的llm head,从而在不破坏动作连续性的同时,使得模型训练更加简单。我们采取Diffusion policy网络来预测动作。为了增加动作的一致性以及提升动作预测效率,TinyVLA一次性会预测未来16步的动作。为了进一步减少资源消耗,我们使用LoRA微调VLM部分,使得需要训练的参数只占总参数的5%。
实验
仿真实验结果
如图所示,TinyVLA-H在metaworld的50个任务上都超越baseline,特别是较难的任务中,更是大幅领先。

多任务真机实验结果
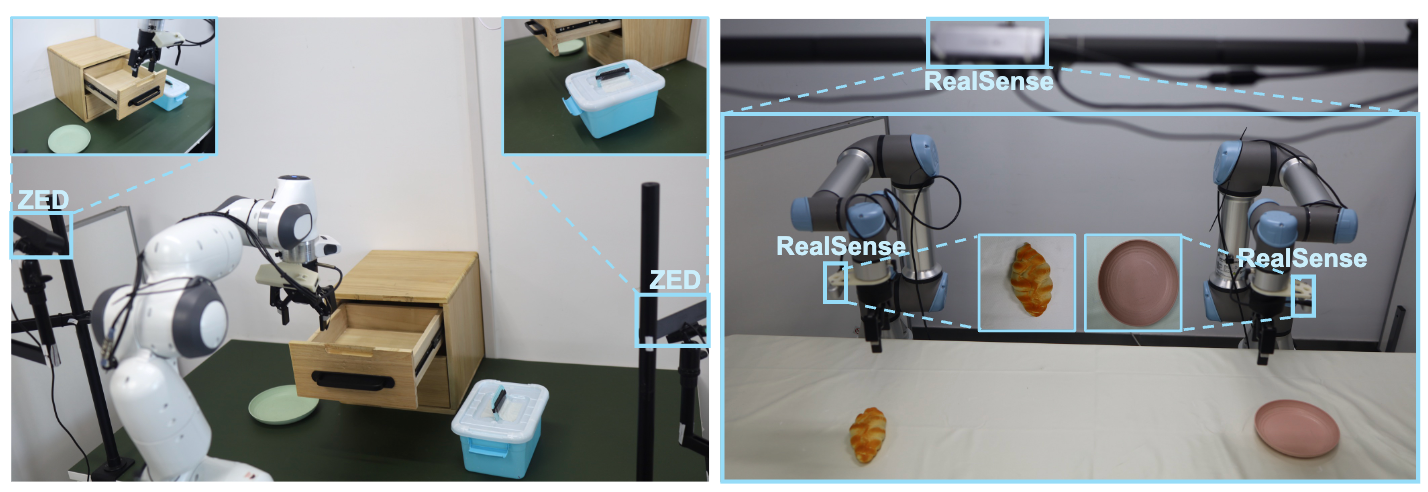
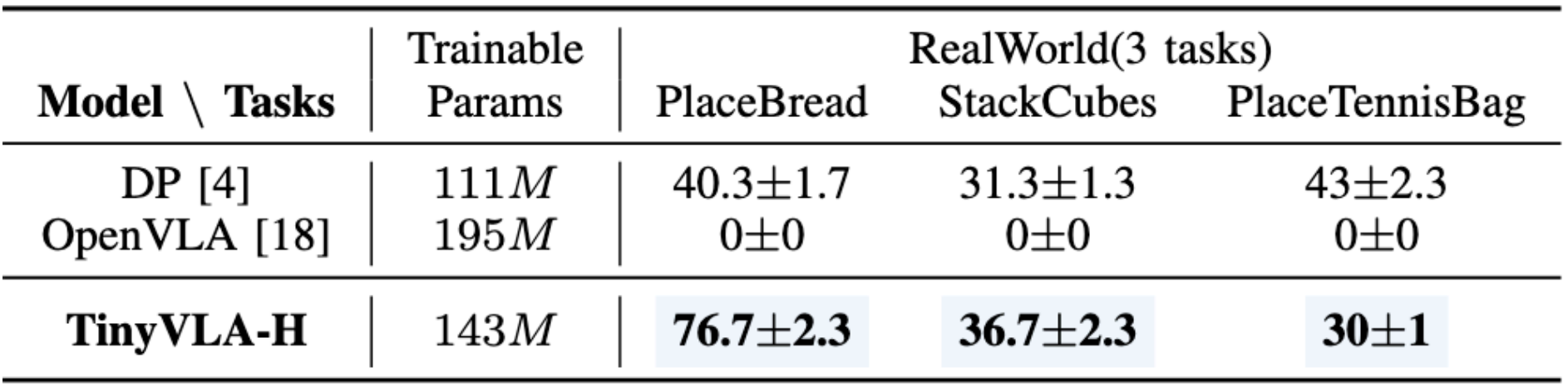
1. 单臂多任务实验。 如图所示,在5个真实环境下的任务分别测试20次,使用不同的权重测试3轮并且统计成功率均值和方差。TinyVLA-H实现了最好的效果,在翻马克杯任务、叠方块任务以及关抽屉任务上都达到了96%以上的成功率,平均成功率达到94%,比OpenVLA提升了25.7%。并且,从TinyVLA-S到TinyVLA-H,随着模型增加,成功率也在增加,证明TinyVLA符合Scaling Law。

2. 双臂任务实验。 双臂环境和单臂完全不同,因为对应的动作维度不同,而OpenVLA是自回归形式生成动作,切换到双臂环境导致动作长度不一致,使得OpenVLA没法正常生成动作,并且Open-x Embodiedment数据集也只包含单臂任务,这进一步导致OpenVLA无法正常生成双臂动作。而TinyVLA无需修改模型结构,只需要更改动作维度,即可直接迁移到双臂环境。如图所示,在3个真实环境下的任务分别测试10次,使用不同的权重测试3轮并且统计成功率均值和方差。TinyVLA-H 仍然大幅领先Baseline。
泛化实验结果
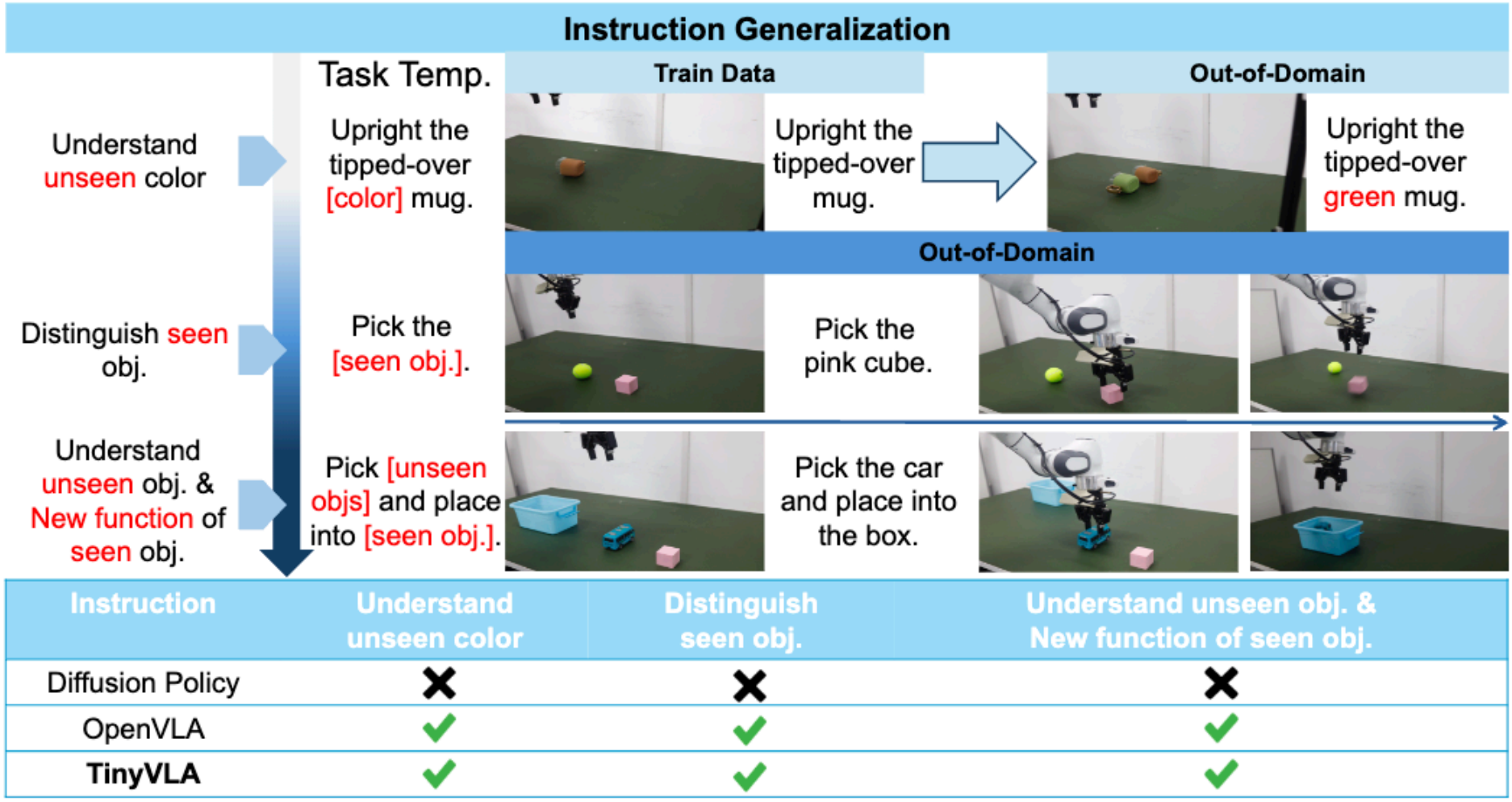
1. 指令泛化。 由于TinyVLA的主干网络是一个在大规模图片文本数据集上预训练的VLM模型,尽管没在相应的机器人指令数据集上预训练,但TinyVLA-H体现出了一些类似于RT-2的指令理解能力。为了更好的区分难度,划分了3个难度等级(越大越难),第1级,理解未在机器人数据中出现的颜色;第2级,区分不同物体;第3级,辨别新的物体并且实现已知物体的新用途。对于第1级,TinyVLA能准确区分不同颜色的同一物体,且该颜色并没有在机器人数据集中出现。第2级,TinyVLA能区分不同物体,这些物体虽然都出现在机器人数据中但并没有同时出现过,也没有在相应的区分任务中训练过。第3级,指令是全新的,要求TinyVLA抓起一个没有在机器人任务中见过的小车并放到盒子里,注意盒子只在开盖子的任务中出现过。
2. 视角泛化。 视角泛化是机器人领域的一大难题,轻微晃动视角都可能会导致任务完成失败。TinyVLA在一定范围内展现出了视角泛化能力。如图所示,我们测试了4个视角度数,范围从-30度到+30度,左右视角分别测试。对于关抽屉任务,TinyVLA展现出较好的能力,但是精度要求更高的叠方块任务则较难完成任务。

3. 位置泛化。 位置泛化要求模型不仅要能在图片中识别出目标物体的位置,还要求模型能泛化到不同的动作空间。而TinyVLA在这项测试中大部分位置能够完成任务,少部分极端位置则逊色于OpenVLA。这可能是由于OpenVLA在大规模的机器人数据集上预训练,且该数据集主要是pick place的任务类型。
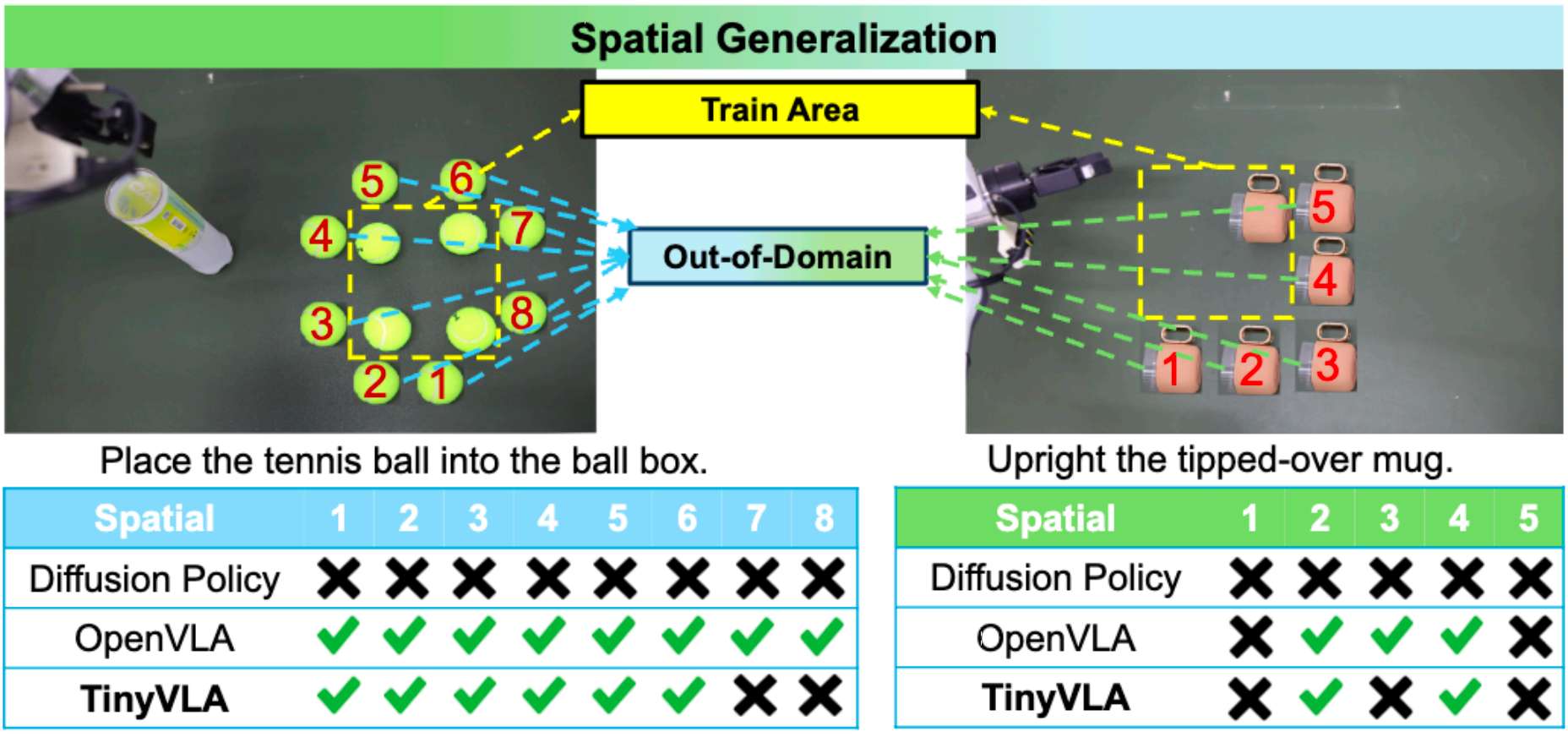
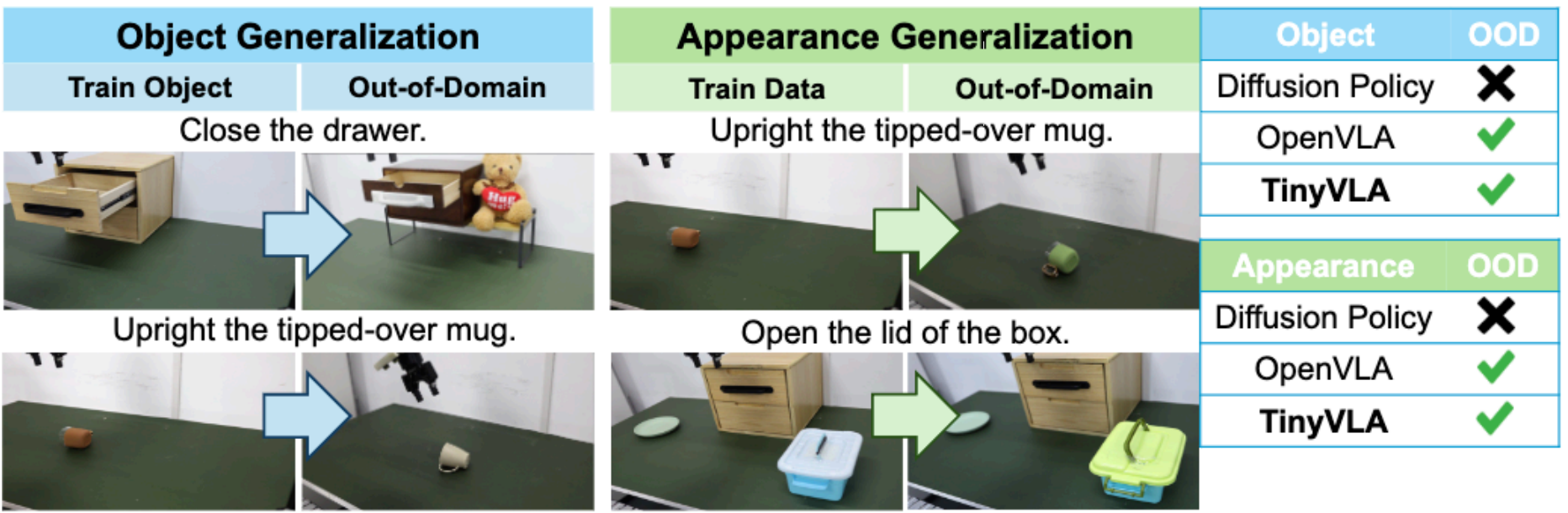
4. 物体以及外观泛化。 更换不同的物体或者相同的物体变换颜色,TinyVLA能实现媲美OpenVLA的性能,而只需要OpenVLA约1/5的参数量,且推理速度更快。
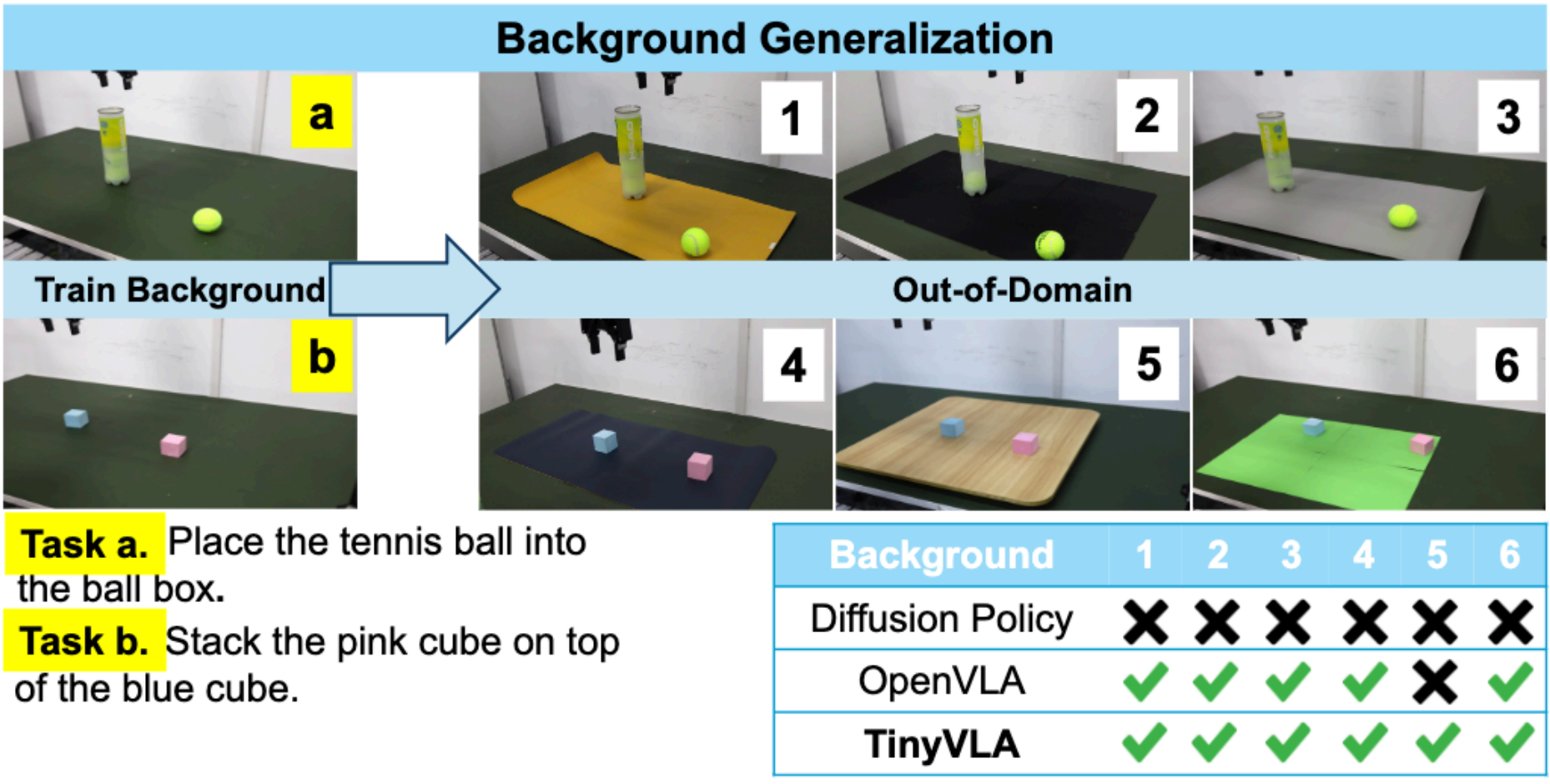
5. 背景泛化。 背景变化同样会导致任务失败,因为背景通常会导致大面积的干扰,从而影响任务的完成。我们测试了6种背景下模型是否还能正常完成任务,且我们选择的叠方块和抓网球都是位置敏感性任务,更容易收到干扰。测his结果如图,TinyVLA与OpenVLA展现出了相近的能力。
6. 光照泛化。

结论
在机器人领域,VLA模型展现出了强大的泛化能力,包括但不限于物体、干扰物、指令泛化等。但VLA模型同时也面临着两个严峻的问题,一方面现有的VLA如RT-2、OpenVLA有着70亿参数甚至550亿参数,庞大的参数量到导致模型的推理速度十分缓慢,OpenVLA在H100上推理也只能达到约6Hz的运行频率。另一方面,现有VLA都是在庞大的机器人数据上预训练过的,比如OpenVLA在Open-x Embodiedment dataset上预训练大约970K轨迹,而真实环境很难收集到如此大规模的数据,因此如何高效地利用少量数据也是机器人领域难点之一。为了缓解这两个问题,本文推出了TinyVLA,以实现更快的推理速度以及不使用大量的预训练数据,并且实现媲美OpenVLA的性能。
TinyVLA将现有的VLM模型和Diffusion policy网络相结合,将VLM的泛化能力迁移到机器人领域的同时,还能利用Diffusion policy网络从而缓解自回归生成导致的推理速度缓慢。我们根据LLaVA的框架首先预训练了一系列不同大小的VLM,然后将VLM的权重直接迁移到我们的VLA模型,再用下游机器人数据进行LoRA微调。根据VLM的参数量变化,我们的TinyVLA也有三种规模,总参数量从4亿到13亿参数。
在下游任务上,我们最大的TinyVLA-H推理延迟比OpenVLA快20倍且单臂环境平均任务成功率高出25.7%,如下图所示。同时我们的TinyVLA还能够直接迁移到双臂环境,无需修改网络结构等,只需要修改预测的动作维度即可;但受限于OpenVLA的自回归结构以及预训练数据均为单臂,导致其很难在双臂环境下正常运行。此外我们的TinyVLA在多个泛化指标上能达到与OpenVLA相媲美的性能,比如物体泛化、位置泛化、干扰物、背景泛化;而在视角变化泛化上,TinyVLA更是遥遥领先,在-30度到30度的超大范围测试中,部分情况仍能准确完成任务。
参考文献
[1]TinyVLA: Towards Fast, Data-Efficient Vision-Language-Action Models for Robotic Manipulation
更多精彩内容,请关注公众号:AI生成未来
