管理主机每天任务: 查询登录档、追踪流量、监控用户使用主机状态、主机各项硬设备状态、 主机软件更新查询、其他使用者要求;
因此shell script 就必须要学啊,虽然可以说绝大部分shell能做的事情python或者perl都能做,但是系统很多服务都是用shell script写的啊,所以shell script还是必须要学;
编写shell script注意事项:
1. 指令的执行是从上而下、从左而右的分析与执行;
2. 指令、选项与参数间的多个空白都会被忽略掉;
3. 空白行也将被忽略掉,并且 [tab] 按键所推开的空白同样视为空格键;
4. 如果读取到一个 Enter 符号 (CR) ,就尝试开始执行该行 (或该串) 命令;
5. 至于如果一行的内容太多,则可以使用『\[Enter] 』来延伸至下一行;
6. 『# 』可做为批注任何加在 # 后面的资料将全部被规为批注文字而忽略
养成良好的 script 撰写习惯,在每个 script 的文件头处记录好:
script 的功能;
script 的功能;
script 的版本信息;
script 的作者与联系方式;
script 的版权宣告方式;
script 的 History (历史纪录);
script 内较特殊的指令,使用『绝对路径』的方式来下达;
script 运作时需要的环境变量预先宣告与设定。
shell中数值计算:
var=$((运算内容))
注意是两个括号;
zhenxiang@ubuntu:~$ var=$((3+4)) zhenxiang@ubuntu:~$ echo $var 7
直接下达指令或者是用bash或sh来下达指令时, 该 script 都会使用一个新的 bash 环境来执行脚本内的指令!也就是说,使用者种执行方式时, 其实 script 是在子程序的 bash 内执行的;我们知道子进程可以继承父进程的环境变量等,而父进程却没有办法得到子进程的变量;来看一个例子:
[root@www scripts]# echo $firstname $lastname <==确认了,这两个发量并不存在喔! [root@www scripts]# sh sh02.sh <==传两个变量到脚本中 Please input your first name: VB <==这个名字是自己输 Please input your last name: Tsai Your full name is: VB Tsai <==在 script 运作中,这两个发数有生效 [root@www scripts]# echo $firstname $lastname <==事实上,这两个变量在父程序的 bash 中还是不存在的
但是用source 则脚本就会在父进程中执行噢
source
利用 source 来执行脚本:在父进程中执行;
shell特殊变量:
| 变量 | 含义 |
|---|---|
| $0 | 当前脚本的文件名 |
| $n | 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是$1,第二个参数是$2。 |
| $# | 传递给脚本或函数的参数个数。 |
| $* | 传递给脚本或函数的所有参数。 |
| $@ | 传递给脚本或函数的所有参数。被双引号(" ")包含时,与 $* 稍有不同,下面将会讲到。 |
| $? | 上个命令的退出状态,或函数的返回值。 |
| $$ | 当前Shell进程ID。对于 Shell 脚本,就是这些脚本所在的进程ID。 |
#!/bin/bash echo "File Name: $0" echo "First Parameter : $1" echo "First Parameter : $2" echo "Quoted Values: $@" echo "Quoted Values: $*" echo "PID: $$" echo "Total Number of Parameters : $#"
运行结果:
$./test.sh Zara Ali File Name : ./test.sh First Parameter : Zara Second Parameter : Ali Quoted Values: Zara Ali Quoted Values: Zara Ali PID:2760 Total Number of Parameters : 2
$* 和 $@ 的区别
$* 和 $@ 都表示传递给函数或脚本的所有参数,不被双引号(" ")包含时,都以"$1" "$2" … "$n" 的形式输出所有参数。
但是当它们被双引号(" ")包含时,"$*" 会将所有的参数作为一个整体,以"$1 $2 … $n"的形式输出所有参数;"$@" 会将各个参数分开,以"$1" "$2" … "$n" 的形式输出所有参数。
test 指令的测试功能
[root@www ~]# test -e /dmtsai && echo "exist" || echo "Not exist" Not exist <==结果显示不存在啊!
文件存在与否测试
-e 该『档名』是否存在?
-f 该『档名』是否存在且为档案(file)?
-d 该『文件名』是否存在且为目录(directory)?
当然除了常用的测试文件档案存在与否,test还可以测试档案的权限,两档案间比较,两整数间判定,字符串数据的判定,多重条件判定,详细使用可以man test;
判断符号:[ ]
例子: $HOME 是否为空 [root@www ~]# [ -z "$HOME" ] ; echo $? 1
注意:bash的语法中,中括号作为shell的判断式, 必须要注意中括号的两端需要有空格符来分隔;
假设我空格键使用『□』符号来表示,那么,在这些地方你都需要有空格键:
[ "$HOME" == "$MAIL" ]
[□"$HOME"□==□"$MAIL"□]
注意点:
在中括号 [] 内的每个组件都需要有空格键来分隔;
在中括号内的变数,最好都以双引号括号起来;
在中括号内的常数,最好都以单或双引号括号起来。
为什么要这么麻烦啊?直接举例来说,假如我设定了 name="VBird Tsai" ,然后这样判定:
[root@www ~]# name="VBird Tsai" [root@www ~]# [ $name == "VBird" ] bash: [: too many arguments
其实$name 应该代替 VBird Tsai,原判断式则变成 [VBird Tsai == "VBird"] 当然会出错咯,所以变量加引号是很重要的,很好的习惯;
read
常用:
输入在终端显示
read -p "Input passwd:" -s Passwd
echo $Passwd
echo $Passwd
限时输入,否则退出
#延迟五秒,没有输入将自动退出
read -p "Input a number:" -t 5 Number
read -p "Input a number:" -t 5 Number
读取限定字符
#从输入中取5个字符
read -p "Input a word:" -n 5 Word
read -p "Input a word:" -n 5 Word
等待输出m退出
#输入,直到输入m ,将自动退出
read -d m -p "Input some words end with q:" word
-p 是终端提示字符显示;
当然如果有两个限制如:1.当输出m时退出 2.当输入5个字符之后退出 两者满足一个就退出
shift:造成参数变量号码偏移
[root@www scripts]# vi sh08.sh
#!/bin/bash
# Program:
# Program shows the effect of shift function.
# History:
# 2009/02/17 VBird First release
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
export PATH
echo "Total parameter number is ==> $#"
echo "Your whole parameter is ==> '$@'"
shift # 进行第一次『一个变量的 shift 』
echo "Total parameter number is ==> $#"
#!/bin/bash
# Program:
# Program shows the effect of shift function.
# History:
# 2009/02/17 VBird First release
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
export PATH
echo "Total parameter number is ==> $#"
echo "Your whole parameter is ==> '$@'"
shift # 进行第一次『一个变量的 shift 』
echo "Total parameter number is ==> $#"
echo "Your whole parameter is ==> '$@'"
shift 3 # 进行第二次『三个变量的 shift 』
echo "Total parameter number is ==> $#"
echo "Your whole parameter is ==> '$@'"
这玩意的执行成果如下:
[root@www scripts]# sh sh08.sh one two three four five six <==给予六个参数
Total parameter number is ==> 6 <==最原始的参数变量情况
Your whole parameter is ==> 'one two three four five six'
Total parameter number is ==> 5 <==第一次偏移,看底下发现第一个 one不见了
Your whole parameter is ==> 'two three four five six'
Total parameter number is ==> 2 <==第二次偏移掉三个,two three four不见了
Your whole parameter is ==> 'five six'
shift 后面可以接数字,代表拿掉最前面的几个参数的意思。 上面的执行结果中,第一次进行 shift 后他的显示情况是『
one two three four fivesix』,所以就剩下五个啦!第二次直接拿掉三个,就发成『
two three four five six 』
单重条件判断式:
if [ 条件判断断式 ]; then
当条件判断式成立时,可以进行的指令工作内容;
else
当条件判断式不成立时,可以进行的指令工作内容;
fi
多重条件判断式
if [ 条件判断式一 ]; then
当条件判断式一成立时,可以进行的指令工作内容;
elif [ 条件判断式二 ]; then
当条件判断式二成立时,可以进行的指令工作内容;
else
当条件判断式一与二均不成立时,可以进行的指令工作内容;
fi
注意:if elif 后面 均要加 ;then ,而 else并没有;
case语句
case $变量名称 in <==关键词为 case ,还有变量前有钱字号
"第一个变量内容") <==每个变量内容建议用双引号括起来,关键词则为小括号 )
程序段
;; <==每个类别结尾使用两个连续的分号来处理!
"第二个发量内容")
程序段
;;
*) <==最后一个变量内容都会用 * 来代表所有其他值
不包括第一个变量内容与第二个变量内容的其他程序执行段
exit 1
;;
esac <==以case 反写作为结束
function功能
注意点:function中特殊字符与shell中的特殊字符是相互独立的;
如例子:tt.sh #!/bin/bash function printit() { echo "this is printit \$1:$1" } printit 2 echo "this is shell \$1:$1" [root@www scripts]# ./tt.sh 4 this is printit $1:2 this is shell $1:4 <==两者是不一样的噢;
循环:
当condition成立时才做do;
while [ condition ] <==中括号内的状态就是判断式
do <==do 是循环的开始!
程序段落
done <==done 是循环的结束
当condition不成立时做do;
until [ condition ]
do
do
程序段落
done
相对于 while, until 的循环方式是必须要符合某个条件的状态, for 这种语法,已经知道要进行几次循环
for var in con1 con2 con3
do
程序段
done
另一种写法的for循环;
for (( 初始值; 限制值; 执行步阶 ))
do
程序段
done
shell script 的追踪与 debug
[root@www ~]# sh [-nvx] scripts.sh 选项与参数: -n :不要执行 script,仅查询语法的问题; -v :再执行 sccript 前,先将 scripts 的内容输出到屏幕上; -x :将使用到的 script 内容显示到屏幕上,这是很有用的参数!
正则: Regular Expression
正则表达式与通配符是完全不一样的东西:
通配符: 代表的是bash操作接口的一个功能,
正则表达式:一种字符串处理的表达方式
特殊字符意义:
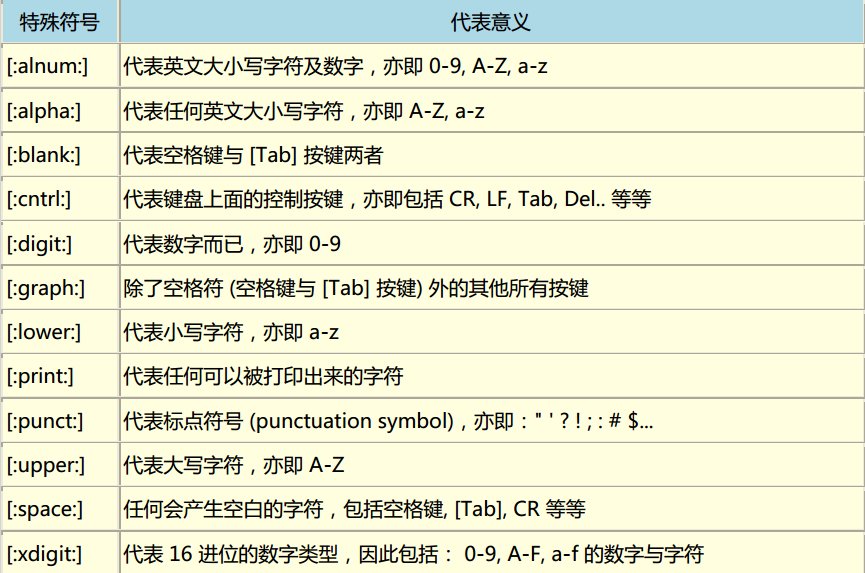
尤其上表中的[:alnum:], [:alpha:], [:upper:], [:lower:], [:digit:] 这几个一定要知道代表什么意思,因为他要比 a-z 或 A-Z 的用途要确定的很好了!
grep 进阶
[root@www ~]# grep [-A] [-B] [--color=auto] '搜寻字符串' filename
选项与参数:
-A :后面可加数字,为 after 的意思,除了列出该行外,后续的 n 行也列出来;
-B :后面可加数字,为 befer 的意思,除了列出该行外,前面的 n 行也列出来;
--color=auto 可将正确的那个攫取数据列出颜色
-n : 加上行号来显示
-v : 反向选择,即单行中没有该字符的;
-i : 忽略大小写
行首与行尾字符 ^ $
[root@www ~]# grep -n '^the' regular_express.txt 12:the symbol '*' is represented as start. #行首是the开头的,注意与通配符[^]区别很大噢,根本不是一个东西 #这个$自然就是攫取行尾咯
找出行尾是小数点” .“的
[root@www ~]# grep -n '\.$' regular_express.txt #小数点有其他意思则需要 转意字符去,而$是放在行尾的啦;
找出空白行:
[root@www ~]# grep -n '^$' regular_express.txt #只有行首和行尾当然就是空白行了
任意一个字符 . 与重复字符 *
. (小数点):代表『一定有一个任意字符』的意思;
* (星星号):代表『0个或无穷个前一个字符』的意思,为组合形态
#既然是组合形态当然是和前一个字符进行组合,就是说前一个字符不是单独存在的,是和这个*号来组合的,也就是说也可能没有前一个字符,也可能有无穷多个字符;
注:通配符*代表任意字符,与正则的小数点一样;
例子:找出g??d的字符串 [root@www ~]# grep -n 'g..d' regular_express.txt
例子:找出g开头与g结尾的字符串当中可有可无 是g*g吗?当然不是;g* 代表0个g或者一个以上的g 这个要重点理解一下; [root@www ~]# grep -n 'g.*g' regular_express.txt # .* 就代表零个或多个任意字符
再来一例:找出任意数字的一行
[root@www ~]# grep -n '[0-9][0-9]*' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1. #虽然可以使用 grep -n '[0-9]' regular_express.txt 但,使用上面可以更好的理解#的作用
限定连续 RE 字符范围 {}
我想要找出两个到五个 o 的连续字符串,该如何作?这候就得要使用到限定范围的字符 {} 了。
因为 { 与 } 的符号在 shell 是有特殊意义的,因此, 我们必须要使用跳脱字符 \ 来让他失去特殊意义才行;
例子:找到两个O的字符串
[root@www ~]# grep -n 'o\{2\}' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 19:goooooogle yes!
例子:找到两到五个O的字符串 [root@www ~]# grep -n 'go\{2,5\}g' regular_express.txt 18:google is the best tools for search keyword. 例子:找到两个以上O的字符串 [root@www ~]# grep -n 'go\{2,\}g' regular_express.txt
sed 工具(主要对行来操作)
sed是一个管线命令,可以分析standard input;还可以将数据进行取代、删除、新增、攫取等;
[root@www ~]# sed [-nefr] [动作]
选项与参数:
选项与参数:
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN
的数据一般都会被列出到屏幕上。但如果加上 -n 参数后,则只有经过
sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在指令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename内的sed动作;
-r :sed 的动作支持的是延伸型正则表示法的语法。(预设是基础正则表示法语法)
-i :直接修改读取的档案内容,而不是由屏输出
动作说明: n1,n2 function
n1, n2 :不见得会存在,一般代表『选择进行动作的行数』,举例来说,如果我的动作
是需要在 10 到 20 行之间进行的,则『10,20[动作行为] 』
function 有底下这些咚咚:
a :新增, a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)
c :取代, c 的后面可以接字符串,这些字符串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运作~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配
正则表示法!例如 1,20s/old/new/g 就是啦!
范例一:将 /etc/passwd 的内容列出并且打印行号,同时,请将第 2~5 行删除!
[root@www ~]# nl /etc/passwd | sed '2,5d' 1 root:x:0:0:root:/root:/bin/bash 6 sync:x:5:0:sync:/sbin:/bin/sync 7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
如果是删除3行以后的呢? nl /etc/passwd | sed '3,$d'
注意:$代表的是最后一行噢!
那么在第二行后第三行加上 “drink tea”
[root@www ~]# nl /etc/passwd | sed '2a drink tea' 1 root:x:0:0:root:/root:/bin/bash 2 bin:x:1:1:bin:/bin:/sbin/nologin drink tea 3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 如果要在第二行前增加 则将 参数a改成参数i
以行为单位的取代与显示:
范例四:我想将第 2-5 行的内容取代成为『 No 2-5 number』呢?
[root@www ~]# nl /etc/passwd | sed '2,5c No 2-5 number' 1 root:x:0:0:root:/root:/bin/bash No 2-5 number 6 sync:x:5:0:sync:/sbin:/bin/sync
部分数据的搜寻并取代的功能
sed 's/要被取代的字符串/新的字符串/g'
当要删除时:sed 's/要删除的字符串//g' 即用空格替换将要取代的字符串,其实没有真的删除
那么要删除空白行呢?
sed '/^$/d' 其实就是选择空白字符串将其删除;
如果要删除以MANPATH_开头的字符串
sed '/MANPATH_.*$/d'
总结:以部分数据为目的惊醒 搜寻取代与删除时,用 /正则选择的字符串 / 来表示;
直接修改档案内容:-i (危险动作)
范例七:利用 sed 直接在 regular_express.txt 最后一行加入『 # This is a test』
[root@www ~]# sed -i '$a # This is a test' regular_express.txt # 由于$代表的是最后一行,而 a 的动作是新增,因此该档案最后新增啰
延伸正则表示法
举个例子:我们要去除空白行和行首为#的
grep -v ‘^$’regular.txt | grep -v '^#' 需要使用到两次管道命令来搜寻;那么如果使用延伸型只需要一次: egrep -v '^$|^#' regular.txt
格式化打印: printf
[root@www ~]# printf '打印格式' 实际内容
选项与参数:
关于格式方面的几个特殊样式:
\a 警告声音输出
\b 退格键(backspace)
\f 清除屏幕 (form feed)
\b 退格键(backspace)
\f 清除屏幕 (form feed)
\n 输出新的一行
\r 亦即 Enter 按键
\t 水平的 [tab] 按键
\v 垂直的[tab] 按键
\xNN NN 为两位数的数字,可以转换数字成为字符。
关于 C 程序语言内,常见的变数格式
%ns 那个 n 是数字, s 代表 string ,亦卲多少个字符;
%ni 那个 n 是数字, i 代表 integer ,亦卲多少整数字数;
%ni 那个 n 是数字, i 代表 integer ,亦卲多少整数字数;
%N.nf 那个 n 与 N 都是数字, f 代表 floating (浮点),如果有小数字数,
假设我共要十个位数,但小数点有两位,即为%10.2f
awk:好用的数据处理工具
相较于sed常常用作整行的处理,awk则比较倾向于分成数个字段来处理;
通常的运作模式:
[root@www ~]# awk '条件类型 1{动作 1} 条件类型 2{动作 2} ...' filename
awk 截断每个字段,而$1代表第一个字段,$4代表第四个字段;字段的默认分隔符为空格或者tab键
例子:
[root@www ~]# last -n 5 <==仅列出前五行 root pts/1 192.168.1.100 Tue Feb 10 11:21 still logged in root pts/1 192.168.1.100 Tue Feb 10 00:46 - 02:28 (01:41) root pts/1 192.168.1.100 Mon Feb 9 11:41 - 18:30 (06:48) dmtsai pts/1 192.168.1.100 Mon Feb 9 11:41 - 11:41 (00:00) 只想要第一和第三字段 [root@www ~]# last -n 5 | awk '{print $1 "\t" $3}' root 192.168.1.100 root 192.168.1.100 root 192.168.1.100 dmtsai 192.168.1.100
awk 是以行为一次处理的单位,而以字段为最小的处理单位
awk内建变量:
变量名称 代表意义
NF 每一行拥有的字段总数
NR 目前awk所处理的是第几行数据
FS 目前的分隔字符,默认是空格符
awk 的格式内容如果想要以 print 打印时,记得
非变量的文字
部分,
都需要使用双引号来定义出来喔!因为单引号已经是 awk 的指令固定用法了;
例子:
[root@www ~]# last -n 5| awk '{print $1 "\t lines: " NR "\t columes: " NF}' root lines: 1 columes: 10 root lines: 2 columes: 10 root lines: 3 columes: 10 dmtsai lines: 4 columes: 10 root lines: 5 columes: 9
awk 的逻辑运算字符
运算单元 代表意义
> 大于
< 小于
>= 大于或等于
<= 小于或等于
== 等于
!= 不等于
例子:
在 /etc/passwd 当中是以冒号 ":" 来作为字段的分隔 查阅第三栏小于 10 以下的数据,并且仅列出账号与第三栏 [root@www ~]# cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t " $3}' root:x:0:0:root:/root:/bin/bash bin 1 daemon 2 ....(以下省略)....
怎么第一行没有正确的显示出来呢?这是因为我们读入第一行的时候,那些变数 $1,$2... 默认还是以空格键为分隔的,所以虽然我们定义了 FS=":" 了, 但是即仅能在第二行后才开始生效。那么怎么办呢?我们可以预先设定 awk 的变量啊! 利用 BEGIN 这个关键词喔!
[root@www ~]# cat /etc/passwd| awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
root 0
bin 1
daemon 2
bin 1
daemon 2
......(以下省略)......
用BEGIN这个关键词,从设置从开始就生效噢;
NR, NF 等变量要用大写,且不需要有钱字号 $ 啦!
有几个重要事项说明:
awk 的指令间隔:所有 awk 的动作,即在 {} 内的动作,如果有需要多个指令辅助时,可利用分号『 ;』间隔, 或者直接以 [Enter] 按键来隔开每个指令;
逻辑运算当中,如果是『等于』的情况,则务必使用两个等号『 ==』!
格式化输出时,在 printf 的格式设定当中,务必加上 \n ,才能进行分行!
与bash shell 的变量不同,在 awk 当中,变量可以直接使用,不需要加上$符号
档案对比工具
diff
diff 就是用在比对两个档案之间的差异的,并且是以行为单位来比对的
举例:
假如我们要将 /etc/passwd 处理成为一个新的版本,处理方式为: 将第四行删除,第六行则取代成为『 no six line』,新的档案放置到 /tmp/test 里面,那么应该怎么做?
[root@www ~]# mkdir -p /tmp/test <==先建立测试用的目录
[root@www ~]# cd /tmp/test
[root@www test]# cp /etc/passwd passwd.old
[root@www test]# cat /etc/passwd | \
[root@www test]# cp /etc/passwd passwd.old
[root@www test]# cat /etc/passwd | \
> sed -e '4d' -e '6c no six line' > passwd.new
# 注意一下, sed 后面如果要接超过两个以上的动作时,每个动作前面得加 -e才行!
# 透过这个动作,在 /tmp/test 里面便有新旧的 passwd 档案存在了!
diff [-bBi] from-file to-file
选项与参数:
from-file :一个档名,作为原始比对档案的档名;
to-file :一个档名,作为目的比对档案的档名;
注意,from-file 或 to-file 可以 - 取代,那个 - 代表Standard input 之意。
-b :忽略一行当中,仅有多个空白的差异(例如 "about me" 与 "about me"视为相同
-B :忽略空白行的差异。
-i : 忽略大小写的不同。
总结
- 管理主机每天任务
- 查询登录档
- 追踪流量
- 监控用户使用主机状态
- 主机各项硬件设备状态
- 主机软件更新查询
- 其他使用者要求
- 脚本规范
- script 的功能
- script 的版本信息
- script 的作者与联系方式
- shell特殊变量
- $0:脚本的文件名
- $n:传递给脚本的参数。n是一个数字,表示第一个参数。
- $#:参数的个数
- $*:参数列表
- $@:参数列表;被双引号包含时,与$*不同
- $?:上一个命令的退出状态
- $$:当前脚本的进程ID
- $* 和 $@ 的区别
- $* 和 $@ 都表示传递参数列表
- 不被双引号(" ")包含时,都以"$1" "$2" … "$n" 的形式输出所有参数。
- 当它们被双引号(" ")包含时,
- "$*" 会将所有的参数作为一个整体,以"$1 $2 … $n"的形式输出所有参数;
- "$@" 会将各个参数分开,以"$1" "$2" … "$n" 的形式输出所有参数。
- 文件测试
- -e 该『档名』是否存在
- -f 该『档名』是否存在且为档案(file)
- -d 该『文件名』是否存在且为目录(directory)
- 中括号测试注意点
- 在中括号 [] 内的每个组件都需要有空格键来分隔;
- 在中括号内的变数,最好都以双引号括号起来;
- 在中括号内的常数,最好都以单或双引号括号起来。
- read
- 限时输入
- read -p "Input a number:" -t 5 Number
- 从输入中取5个字符
- read -p "Input a word:" -n 5 Word
- 等待输出q退出
- read -d q -p "Input some words end with q:" word
- 限时输入
- shift
- 变量剔除替换
- 变量1用完之后,将变量1剔除,原先的变量2,变成变量1;
- 默认步长是1,shift 2,则步长是2;踢掉两个;
- 条件判断式语法,for的两种写法,case语法,while的两种写法
- function
- function中特殊字符与shell中的特殊字符是相互独立的。
- shell script 的debug
- bash -nx scripts.sh
- n,不执行,仅检测语法问题
- x,将使用的script内容显示屏幕
- bash -nx scripts.sh
- 正则表达式
- 常用特殊字符
- [:alnum:],代表0-9;A-Z;a-z
- [:alpha:],代表A-Z;a-z
- [:upper:],代表A-Z
- [:lower:],代表a-z
- [:digit:], 代表0-9
- 行首与行尾
- ^ $
- 找空白行
- grep -n '^$' regular_express.text
- 任意一个字符 .
- 重复次数
-
- * ,0次或无限次
- +,1次或无限次
- ?, 0次或1次
- 连续RE字符范围{}
- 连续两个O
- grep -n 'o\{2\}' regular_express.txt
- 连续2到5个
- grep -n 'go\{2,5\}g' regular_express.txt
- 2个以上
- grep -n 'go\{2,\}g' regular_express.txt
- 连续两个O
- 常用特殊字符
- grep 进阶
- -A,-B,-C n ;除匹配行之外,前,后再显示n行
- A,after;B,before;C,是前后都显示
- -n,带上行号显示
- -v,反向选择
- -i, 忽略大小写
- -A,-B,-C n ;除匹配行之外,前,后再显示n行
- sed
- 将数据读入模式空间中,和模式条件做匹配;符合模式条件,则在模式空间中使用后面的编辑命令对其完成编辑,并且将编辑结果输出到屏幕;并且在结束后,默认将模式空间的内容,打印出来。
- 默认不编辑源文件,仅对模式空间上的数据做处理;
- 逐行处理
- awk
- 将数据分成几个字段来处理
- 以行为一次处理的单位,而以字段为最小的处理单位
- diff
- 档案对比工具
- 用在比对两个档案之间的差异,以行为单位来对比