2019独角兽企业重金招聘Python工程师标准>>> 
本文重点关注mapWithState,假设spark shell启动没问题,明白Receiver和RDD生成的过程,不明白的建议从此文开始学习,或关注YY课堂:每天20:00免费现场授课频道68917580。
案例:累计单词出现的次数,持续性的更新计数。
因为是持续性的计数,因此比较高效的算法是计算完一批数据之后将每个单词的计数保存起来,在下一批数据来之后,再做增量更新。
先在终端运行:
root@master:~# nc -lk 9999启动spark-shell,输入如下代码:
// 累计单词出现的次数,持续性的更新计数
import org.apache.spark.streaming.{Durations, State, StateSpec, StreamingContext}
import org.apache.spark.{SparkContext, SparkConf}
sc.setCheckpointDir(".")
val ssc = new StreamingContext(sc, Durations.seconds(5L))
ssc.socketTextStream("localhost", 9999).
flatMap(_.split(" ")).
map((_, 1)).
reduceByKey(_ + _).
mapWithState(
StateSpec.function(
(word: String, countOfThisBatch: Option[Int], state: State[Int]) => {
val newState = countOfThisBatch.getOrElse(0) + state.getOption().getOrElse(0)
state.update(newState)
(word, newState)
}
)
).
print
ssc.start输入:
输出: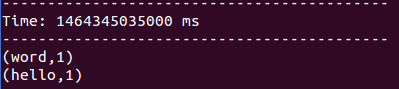


和updateStateByKey的结果略有差别,mapWithState只对增量的数据做操作,并且只返回增量的数据。
而updateStateByKey是返回全量的数据,而且在前文的源码解析中发现,需要cogroup一次。
按照案例解析源码:
看下MapWithStateDStreamImpl的实例化过程。
- 实例化一个InternalMapWithStateDStream,
- 将上一个DStream作为parent创建此InternalMapWithStateDStream,同时将创建的DStream当作当前的DStream的parent。
// MapWithStateDStream.scala line 57
private val internalStream =
new InternalMapWithStateDStream[KeyType, ValueType, StateType, MappedType](dataStream, spec)
// MapWithStateDStream.scala line 62
override def dependencies: List[DStream[_]] = List(internalStream)再看下InternalMapWithStateDStream的实例化,
StorageLevel设置为MEMORY_ONLY,而DStream默认的是MEMORY_ONLY_SER
// InternalMapWithStateDStream.scala line 109
persist(StorageLevel.MEMORY_ONLY)
// DStream.scala line 165
// DStream默认的storage level
/** Persist RDDs of this DStream with the default storage level (MEMORY_ONLY_SER) */
def persist(): DStream[T] = persist(StorageLevel.MEMORY_ONLY_SER)checkpoint的设置为true
// MapWithStateDStream.scala line 120
/** Enable automatic checkpointing */
override val mustCheckpoint = truecheckpointDuration的设置,若未设置checkpointDuration,则使用滑动窗口*默认倍数(10)。也就是每10个滑动窗口时长做一次checkpoint。
// MapWithStateDStream.scala line 123
/** Override the default checkpoint duration */
override def initialize(time: Time): Unit = {
if (checkpointDuration == null) {
checkpointDuration = slideDuration * DEFAULT_CHECKPOINT_DURATION_MULTIPLIER
}
super.initialize(time)
}
// InternalMapWithStateDStream.scala line 168
private[streaming] object InternalMapWithStateDStream {
private val DEFAULT_CHECKPOINT_DURATION_MULTIPLIER = 10
}至此,DStream的lineage如下:
SocketInputDStream -> FlatMappedDStream -> MappedDStream -> ShuffledDStream -> InternalMapWithStateDStream -> MapWithStateDStream?-> ForEachDStream
静态的DAG已经分析完,接下来从运行时回溯:
首先回溯到的是MapWithStateDStreamImpl.compute,依赖父DStream,InternalMapWithStateDStream.compute。
在InternalMapWithStateDStream中,也是先取上一批次产生的RDD,为什么用也呢?因为updateStateByKey也是这么做的。具体做法如下:
- getOrCompute(validTime - slideDuration):取上一批次生产的RDD,
- None:创建空RDD
- Some(rdd):上一批次的有RDD
- rdd.partitioner != Some(partitioner):若分区器不相同,使用新分区器重新生成RDD
- rdd:直接返回已经存在的RDD
// MapWithStateDStream.scala line 134
val prevStateRDD = getOrCompute(validTime - slideDuration) match {
case Some(rdd) =>
if (rdd.partitioner != Some(partitioner)) {
// If the RDD is not partitioned the right way, let us repartition it using the
// partition index as the key. This is to ensure that state RDD is always partitioned
// before creating another state RDD using it
MapWithStateRDD.createFromRDD[K, V, S, E](
rdd.flatMap { _.stateMap.getAll() }, partitioner, validTime)
} else {
rdd
}
case None =>
MapWithStateRDD.createFromPairRDD[K, V, S, E](
spec.getInitialStateRDD().getOrElse(new EmptyRDD[(K, S)](ssc.sparkContext)),
partitioner,
validTime
)
}上述是取到上一批次的状态信息。是从时间维度来切入的。
从另一方面,是从RDD的lineage维度来看,取本批次的依赖的父RDD。
// MapWithStateDStream.scala line 156
// 取本批次的父RDD
val dataRDD = parent.getOrCompute(validTime).getOrElse {
context.sparkContext.emptyRDD[(K, V)]
}
最后将历史状态RDD与本批次的RDD创建新的RDD:MapWithStateRDD
// MapWithStateDStream.scala line 163
Some(new MapWithStateRDD(
prevStateRDD, partitionedDataRDD, mappingFunction, validTime, timeoutThresholdTime))接下来再从运行时开始推导:
首次运行的时候,getOrCompute(validTime - slideDuration) --> None:
// MapWithStateDStream.scala line 145
case None =>
MapWithStateRDD.createFromPairRDD[K, V, S, E](
spec.getInitialStateRDD().getOrElse(new EmptyRDD[(K, S)](ssc.sparkContext)),
partitioner,
validTime
)先取到spec,此时的spec就是mapWithState接受的参数,是StateSpec类型的,而StateSpec是抽象类,显然传入的是StateSpec的子类StateSpecImpl的实例。
// PairDStreamFunctions.scala line 375
def mapWithState[StateType: ClassTag, MappedType: ClassTag](
spec: StateSpec[K, V, StateType, MappedType]
): MapWithStateDStream[K, V, StateType, MappedType] = {
new MapWithStateDStreamImpl[K, V, StateType, MappedType](
self,
spec.asInstanceOf[StateSpecImpl[K, V, StateType, MappedType]]
)
}
// StateSpec.scala line 73
sealed abstract class StateSpec[KeyType, ValueType, StateType, MappedType] extends Serializable
也就是说,案例中的如下代码,实际上返回的是一个StateSpecImpl类的实例。
StateSpec.function(
(word: String, countOfThisBatch: Option[Int], state: State[Int]) => {
val newState = countOfThisBatch.getOrElse(0) + state.getOption().getOrElse(0)
state.update(newState)
(word, newState)
}
)源码中来验证下,的确是new 了stateSpecImpl返回了。
传入的函数的签名是(KeyType,Option[ValueType],State[StateType])=>MappedType。
在方法内,将函数签名适配成(Time,KeyType,Option[ValueType],State[StateType])=>MappedType。相当于新增了时间维度。
将适配好的函数 作为参数 传入StateSpecImpl的构造。
// StateSpec.scala line 174
def function[KeyType, ValueType, StateType, MappedType](
mappingFunction: (KeyType, Option[ValueType], State[StateType]) => MappedType
): StateSpec[KeyType, ValueType, StateType, MappedType] = {
ClosureCleaner.clean(mappingFunction, checkSerializable = true)
val wrappedFunction =
(time: Time, key: KeyType, value: Option[ValueType], state: State[StateType]) => {
Some(mappingFunction(key, value, state))
}
new StateSpecImpl(wrappedFunction)
}
// StateSpec.scala line 230
private[streaming]
case class StateSpecImpl[K, V, S, T](
function: (Time, K, Option[V], State[S]) => Option[T]) extends StateSpec[K, V, S, T]看下StateSpecImpl类的继承结构。

父类MapWithStateDStream类的定义,只定义了一个方法,stateSnapshots()。
// MapWithStateDStream.scala line 43
sealed abstract class MapWithStateDStream[KeyType, ValueType, StateType, MappedType: ClassTag](
ssc: StreamingContext) extends DStream[MappedType](ssc) {
/** Return a pair DStream where each RDD is the snapshot of the state of all the keys. */
def stateSnapshots(): DStream[(KeyType, StateType)]
}再看MapWithStateDStream.scala line 145的分支。
最初都是null,则返回空RDD。
// MapWithStateDStream.scala line 147
spec.getInitialStateRDD().getOrElse(new EmptyRDD[(K, S)](ssc.sparkContext))
// StateSpec.scala line 269
private[streaming] def getInitialStateRDD(): Option[RDD[(K, S)]] = Option(initialStateRDD)
// StateSpec.scala line 237
@volatile private var initialStateRDD: RDD[(K, S)] = null没有历史状态时,使用PairRDD创建MapWithStateRDD
// MapWithStateDStream.scala line 146
MapWithStateRDD.createFromPairRDD[K, V, S, E](
spec.getInitialStateRDD().getOrElse(new EmptyRDD[(K, S)](ssc.sparkContext)),
partitioner,
validTime
)- 按照分区器分区,这个很重要。上面有提到,如果分区器不一致,需要重新算的步骤。
- 每一个分区一个MapWithStateRDDRecord,将KV保存成对应的StateMap中,并且分区器是延续的。
- 创建新的MapWithStateRDD并返回。
// MapWithStateRDD.scala line 183
def createFromPairRDD[K: ClassTag, V: ClassTag, S: ClassTag, E: ClassTag](
pairRDD: RDD[(K, S)],
partitioner: Partitioner,
updateTime: Time): MapWithStateRDD[K, V, S, E] = {
// 使用分区器创建StateMap,每个分区一个MapWithStateRDDRecord
val stateRDD = pairRDD.partitionBy(partitioner).mapPartitions ({ iterator =>
val stateMap = StateMap.create[K, S](SparkEnv.get.conf)
iterator.foreach { case (key, state) => stateMap.put(key, state, updateTime.milliseconds) }
Iterator(MapWithStateRDDRecord(stateMap, Seq.empty[E]))
}, preservesPartitioning = true)
// 使用相同的分区器创建空RDD
val emptyDataRDD = pairRDD.sparkContext.emptyRDD[(K, V)].partitionBy(partitioner)
// 适配方法签名
val noOpFunc = (time: Time, key: K, value: Option[V], state: State[S]) => None
new MapWithStateRDD[K, V, S, E](
stateRDD, emptyDataRDD, noOpFunc, updateTime, None)
}StateMap的创建
// MapWithStateRDD.scala line 189
val stateMap = StateMap.create[K, S](SparkEnv.get.conf)
// StateMap.scala line 59
def create[K: ClassTag, S: ClassTag](conf: SparkConf): StateMap[K, S] = {
val deltaChainThreshold = conf.getInt("spark.streaming.sessionByKey.deltaChainThreshold",
DELTA_CHAIN_LENGTH_THRESHOLD)
new OpenHashMapBasedStateMap[K, S](deltaChainThreshold)
}
// StateMap.scala line 28
/** Internal interface for defining the map that keeps track of sessions. */
private[streaming] abstract class StateMap[K: ClassTag, S: ClassTag] extends Serializable
构造OpenHashMapBasedStateMap,内部使用OpenHashMap数据结构。
// StateMap.scala line 79
/** Implementation of StateMap based on Spark's [[org.apache.spark.util.collection.OpenHashMap]] */
private[streaming] class OpenHashMapBasedStateMap[K: ClassTag, S: ClassTag](
@transient @volatile var parentStateMap: StateMap[K, S],
initialCapacity: Int = DEFAULT_INITIAL_CAPACITY,
deltaChainThreshold: Int = DELTA_CHAIN_LENGTH_THRESHOLD
) extends StateMap[K, S] { self =>
// ...
// line 99
@transient @volatile private var deltaMap = new OpenHashMap[K, StateInfo[S]](initialCapacity)
// ...
}看下OpenHashMap的介绍
- 快速的Map实现,比java.util.HashMap快5倍
- key可以为null
- 不能删除
- 内部是使用高速的HashSet实现:OpenHashSet作为keySet,也是非null,不能删除
// OpenHashMap.scala line 34
/**
* :: DeveloperApi ::
* A fast hash map implementation for nullable keys. This hash map supports insertions and updates,
* but not deletions. This map is about 5X faster than java.util.HashMap, while using much less
* space overhead.
*
* Under the hood, it uses our OpenHashSet implementation.
*/
@DeveloperApi
private[spark]
class OpenHashMap[K : ClassTag, @specialized(Long, Int, Double) V: ClassTag](
initialCapacity: Int)
extends Iterable[(K, V)]
with Serializable再回到 MapWithStateRDD.scala line 190
// MapWithStateRDD.scala line 190
iterator.foreach { case (key, state) => stateMap.put(key, state, updateTime.milliseconds) }若key不存在,则将state和time封装成StateInfo,作为map的value。
若key存在,则取出StateInfo,更新state和time,且将deleted设置为false。
// StateMap.scala line 142
/** Add or update state */
override def put(key: K, state: S, updateTime: Long): Unit = {
val stateInfo = deltaMap(key)
if (stateInfo != null) {
stateInfo.update(state, updateTime)
} else {
deltaMap.update(key, new StateInfo(state, updateTime))
}
}
// StateMap.scala line 320
/** Internal class to represent the state information */
case class StateInfo[S](
var data: S = null.asInstanceOf[S],
var updateTime: Long = -1,
var deleted: Boolean = false) {
def markDeleted(): Unit = {
deleted = true
}
def update(newData: S, newUpdateTime: Long): Unit = {
data = newData
updateTime = newUpdateTime
deleted = false
}
}从上述的deleted属性,也可以理解OpenHashapBasedStateMap对于需要删除的state的做法:是将对应的value,即StateInfo对象的deleted设置为null,而不是将key从map中删除来实现的。
封装成MapWithStateRDDRecord 类型的case class后,作为唯一的一个元素,加入迭代器。
最后返会 MapWithStateRDD实例,包含之前的状态RDD和本批次的分区后的数据RDD
- 之前的状态RDD:RDD[MapWithStateRDDRecord[K, S, E]
- 本批次的数据RDD:RDD[(K, V)]
在本案例中,K是String,S是Int,E是(String,Int),V是Int。
创建MapWithStateRDD实例,RDD依赖的RDD有两个,一个是之前的历史状态RDD,一个是当前批次的RDD。
// MapWithStateRDD.scala line 119
private[streaming] class MapWithStateRDD[K: ClassTag, V: ClassTag, S: ClassTag, E: ClassTag](
private var prevStateRDD: RDD[MapWithStateRDDRecord[K, S, E]],
private var partitionedDataRDD: RDD[(K, V)],
mappingFunction: (Time, K, Option[V], State[S]) => Option[E],
batchTime: Time,
timeoutThresholdTime: Option[Long]
) extends RDD[MapWithStateRDDRecord[K, S, E]](
partitionedDataRDD.sparkContext,
List(
new OneToOneDependency[MapWithStateRDDRecord[K, S, E]](prevStateRDD),
new OneToOneDependency(partitionedDataRDD))
)同样,当非首次时,见MapWithStateDStream.scala line 135
则会判断,若分区器有变化,则会重新创建RDD,因为分区器是要被后续沿用的。若分区器没修改,则直接返回。
此处的rdd是MapWithStateRDDRecord[K,S,V],
// MapWithStateDStream.scala line 140
MapWithStateRDD.createFromRDD[K, V, S, E](
rdd.flatMap { _.stateMap.getAll() }, partitioner, validTime)
MapWithStateRDD.createFromRDD[K, V, S, E](rdd.flatMap { _.stateMap.getAll() }, partitioner, validTime):
- _.stateMap.getAll():将历史的状态过滤掉本次有的key,在加上本次更新中非删除的数据,就是所有的状态了。
- rdd.flatMap:就是扁平化,很简单的RDD转换。输出为MapPartitionsRDD[(K, S, Long)],本案例中,K:String,S:Int。Long代表的是updateTime。
- MapWithStateRDD.createFromRDD:
- val pairRDD = rdd.map { x => (x._1, (x._2, x._3)) }:转换成key:(state,updateTime)格式,类似StateInfo case class
- 按照分区器分区后,将rdd中的数据装入新的StateMap中。
- 剩余做法和 createFromPairRDD做法一致。
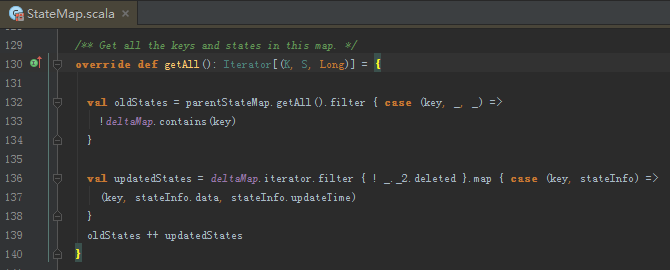
// MapWithStateRDD.scala line 202
def createFromRDD[K: ClassTag, V: ClassTag, S: ClassTag, E: ClassTag](
rdd: RDD[(K, S, Long)],
partitioner: Partitioner,
updateTime: Time): MapWithStateRDD[K, V, S, E] = {
val pairRDD = rdd.map { x => (x._1, (x._2, x._3)) }
val stateRDD = pairRDD.partitionBy(partitioner).mapPartitions({ iterator =>
val stateMap = StateMap.create[K, S](SparkEnv.get.conf)
iterator.foreach { case (key, (state, updateTime)) =>
stateMap.put(key, state, updateTime)
}
Iterator(MapWithStateRDDRecord(stateMap, Seq.empty[E]))
}, preservesPartitioning = true)
val emptyDataRDD = pairRDD.sparkContext.emptyRDD[(K, V)].partitionBy(partitioner)
val noOpFunc = (time: Time, key: K, value: Option[V], state: State[S]) => None
new MapWithStateRDD[K, V, S, E](
stateRDD, emptyDataRDD, noOpFunc, updateTime, None)
}那么在RDD计算时,MapWithStateRDD.scala line 144 ,调用 MapWithStateRDDRecord.updateRecordWithData方法,得到MapWithStateRDDRecord,并封装成迭代器。
看下MapWithStateRDDRecord.updateRecordWithData:
- prevRecord.map { _.stateMap.copy() }. getOrElse { new EmptyStateMap[K, S]() }:先取出历史状态的RDD
- 对本批数据中的key,依次遍历。
- wrappedState.wrap(newStateMap.get(key)):只是用历史状态做初始化。设置defined flags:

- val returned = mappingFunction(batchTime, key, Some(value), wrappedState):执行自定义的函数;也就是案例中的代码段:
- 本案例中逻辑是次数相加:将历史状态和当前数据做聚合
- 再将状态更新。

- 返回MappedType,即(单词,计数):(String,Int)。
(word: String, countOfThisBatch: Option[Int], state: State[Int]) => { val newState = countOfThisBatch.getOrElse(0) + state.getOption().getOrElse(0) state.update(newState) (word, newState) } - 封装成迭代器返回
- wrappedState.wrap(newStateMap.get(key)):只是用历史状态做初始化。设置defined flags:
- 移除超时数据(按配置可选)
- 封装成MapWithStateRDDRecord后返回。
那么至此,InternalMapWithStateDStream的内部已经分析完,下面进入到依赖InternalMapWithStateDStream的MapWithStateDStream。

此时_.flagMap[MappedType]中,_=MapWithStateRDD
{_.mappedData}中_=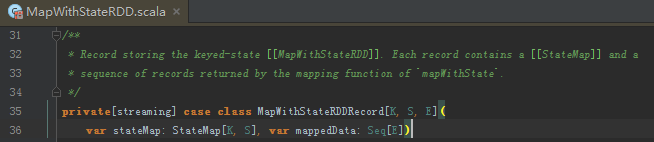 ,此处的mappedData为每次匹配的key调用自定义函数后的返回,本案例中为 (word, newState)。也就是说,状态更新和函数返回是两码事。考虑下:为什么mappedData是一个Seq类型,是因为,在本批次中,同一个单词可能会出现多次,则每次都会调用下自定义的函数。
,此处的mappedData为每次匹配的key调用自定义函数后的返回,本案例中为 (word, newState)。也就是说,状态更新和函数返回是两码事。考虑下:为什么mappedData是一个Seq类型,是因为,在本批次中,同一个单词可能会出现多次,则每次都会调用下自定义的函数。
将本章的案例的reduceByKey注释,并在同一批输入中重复一个单词,就可以很好的解释。
updateStateByKey和MapWithState的异同:
相同点:都是使用历史状态和增量数据合并的逻辑来实现的。
差异:
- 在保存历史状态的实现中
- updateStateByKey是复用自身RDD,通过RDD来实现历史状态的保存的。
- mapWithState是通过内部的RDD来实现的。是保存于MapWithStateRDDRecord
- 在性能方便
- updateStateByKey是对全量历史数据与增量数据进行cogroup,性能肯定低。
- mapWithState只是更新增量数据部分。性能相对较高。
- 返回数据范围
- updateStateByKey返回的是全量数据
- mapWithState只返回更新的数据部分。
其他差异请读者留言,一起补充完整。
databricks官方demo