基于Oracle的SQL优化--学习(十三)
Oracle里的应用类型
Session Cursor的生命周期
Session Cursor是有生命周期的,每个 Session Cursor 在使用的过程中都至少会经历一次 Open、 Parse 、 Bind 、 Execute 、 Fetch 和 Close 中的 一个或多个阶段。
Session Cursor的生命周期中各个阶段的先后顺序和关联关系可以用下图 来说明。
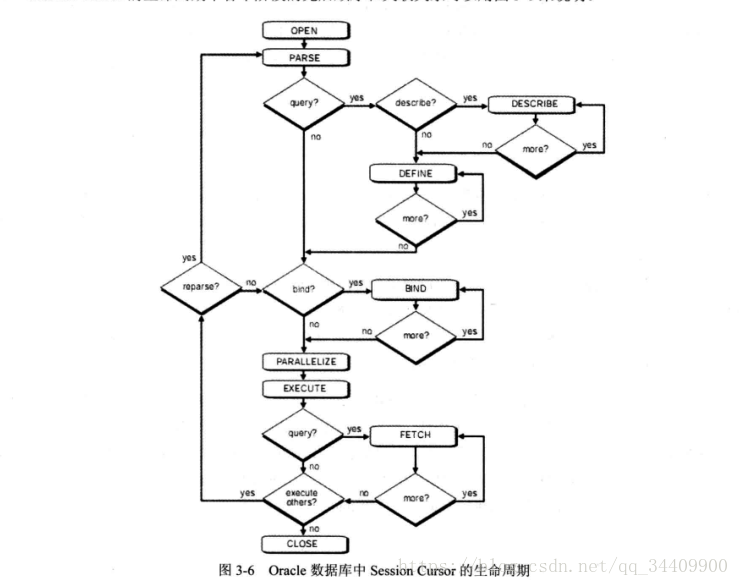
作为Oracle数据库中当前Session解析和执行的SQL的载体,Session Cursor的整改生命周期大致可以分为以下9个阶段:
阶段 1 : Open
阶段2 : Parse
阶段 3 : Describe (仅适用于查询语句)
阶段 4 : Define (仅适用于查询语句)
阶段 5 : Bind (仅适用于使用了绑定变量的目标 SQL )
阶段 6 : Parallelize (仅适用于开启了并行的情形)
阶段 7 : Execute
阶段 8 : Fetch (仅适用于查询语句)
阶段 9 : Close
对于査询语句而言,其对应的SessionCursor可能会经历上述所有的9个阶段。当然,如果该査询语句没有使用绑定变量则其对应的SessionCursor就不需要经历阶段5:如果该査询语句没有使用并行査询,则其对应的SessionCursor就不需要经历阶段6。对于DML语句而言,其对应的SessionCursor可能会经历阶段1、2、5、6、7和9。和查询语句一样,如果该DML语句没有使用绑定变量,则其对应的SessionCursor就不需要经历阶段5;如果该DML语句没有使用并行(ParallelDML),则其对应的SessionCursor就不需要经历阶段6。和查询语句以及DML语句不同,DDL语句的SessionCursor只会经历阶段1和2,也就是说,DDL语句实际上在解析(Parse)完后就已经执行完毕了。
SessionCursor的Parse阶段大致会做如下事情。
(1)执行对目标SQL的校验。在这个校验过程中,Oracle会执行对目标SQL的语法、语义和权限的检查。
(2)执行对目标SQL的查询转换
(3)执行对目标SQL的查询优化(QueryOptimization)。在这个过程中,Oracle会根据不同的优化器类型,按照不同的判断原则,从执行完查询转换这一步后得到的目标SQL诸多可能的执行路径中选择一条来作为其执行计划。
SessionCursor的Describe阶段仅适用于查询语句,它用于明确目标SQL所涉及的具体查询列的名称、类型和长度,比如要执行的SQL是“se丨ect*fromemp”,当经过Describe阶段后,Oracle就会知道要执行的SQL实际上是要查询表EMP的所有列(表EMP共有8列,分别为EMPNO、ENAME、JOB、MGR、HIREDATE、SAL、COMM和DEPTNO),以及这些列的名称、类型和长度。
(1)执行对目标SQL的校验。在这个校验过程中,Oracle会执行对目标SQL的语法、语义和权限的检查。
(2)执行对目标SQL的查询转换
(3)执行对目标SQL的查询优化(QueryOptimization)。在这个过程中,Oracle会根据不同的优化器类型,按照不同的判断原则,从执行完查询转换这一步后得到的目标SQL诸多可能的执行路径中选择一条来作为其执行计划。
SessionCursor的Describe阶段仅适用于查询语句,它用于明确目标SQL所涉及的具体查询列的名称、类型和长度,比如要执行的SQL是“se丨ect*fromemp”,当经过Describe阶段后,Oracle就会知道要执行的SQL实际上是要查询表EMP的所有列(表EMP共有8列,分别为EMPNO、ENAME、JOB、MGR、HIREDATE、SAL、COMM和DEPTNO),以及这些列的名称、类型和长度。
SessionCursor的Define阶段也只适用于査询语句,它发生在Describe阶段之后,用于决定一组变量在PGA中的位置、大小和数据类型,这组变量用于存储目标SQL的各个具体査询列所对应的查询结果。SessionCursor的Bind阶段只适用于那些在SQL文本中使用了绑定变量的目标SQL,Oracle在执行含绑定变量的目标SQL时,对目标SQL中的每一个绑定变量都要用其实际的值来替换(即所谓的“绑定变量值替换”),所以Bind阶段要做的事情就是为这些绑定变量在PGA中预留内存空间(预留的空间必须要能够容纳这些绑定变量实际的值),并创建指向这些预留内存空间的指针(这些指针会用于后续的绑定变量值替换)。
SessionCursor的Execute阶段就是目标SQL的实际执行阶段,这个阶段的执行结果就是目标SQL的执行结果。对于那些在SQL文本中使用了绑定变量的目标SQL而言,Oracle在实际执行该SQL之前会做绑定变量值替换,即对该SQL中的每一个绑定变量都用其实际的值来替换。
基于Oracle数据库的应用分为如下四种类型:
应用类型一:不使用绑定变量。
应用类型二:每次Open、Parse、Bind、Execute、Fetch、Close。
应用类型三:一次Open+每次Parse、Bind、Execute、Fetch+—次Close。
应用类型四:一次Open、Parse、Bind+每次Execute、Fetch+—次Close。
应用类型一的特点是SQL语句没有使用绑定变量,这意味着硬解析的比率会非常高,正因为如此,我们通常把该种类型的应用系统的特点概括为“硬解析”。这里不使用绑定变量的原因通常是因为开发人员并未意识到硬解析的危害,即开发人员并未意识到硬解析会严重阻碍OLTP类型应用系统在数据库端的性能和可扩展性。
应用类型二:每次Open、Parse、Bind、Execute、Fetch、Close。
应用类型三:一次Open+每次Parse、Bind、Execute、Fetch+—次Close。
应用类型四:一次Open、Parse、Bind+每次Execute、Fetch+—次Close。
应用类型一的特点是SQL语句没有使用绑定变量,这意味着硬解析的比率会非常高,正因为如此,我们通常把该种类型的应用系统的特点概括为“硬解析”。这里不使用绑定变量的原因通常是因为开发人员并未意识到硬解析的危害,即开发人员并未意识到硬解析会严重阻碍OLTP类型应用系统在数据库端的性能和可扩展性。
应用类型二的特点是SQL语句使用了绑定变量,同时数据库端参数SESSION_CACHED_CURSORS的值为0,这意味着硬解析的比率与应用类型一相比会少很多,正因为如此,我们通常会把该种类型的应用系统的特点概括为“软解析”。应用类型二由于参数SESSION_CACHED_CURSORS的值为0,所以SessionCursor不能以SoftClosed状态缓存在PGA中,这意味着Oracle在执行该类型应用系统中的每一条SQL语句时,其对应的SessionCursor都需要经历Open、Parse、Bind、Execute、Fetch和Close这些阶段。
应用类型三的特点是SQL语句使用了绑定变量,而且数据库端参数SESSION_CACHED_CURSORS的值大于0,这意味着这种类型的应用系统中的每一条SQL语句所对应的SessionCursor在经历Execute阶段后,当满足一定的额外条件时(在OraclellgR2中,这个额外条件是该SessionCursor所对应的SQL解析和执行的次数要超过3次),Oracle就不会对上述SessionCursor执行Close操作,而是将其标记为SoftClosed,并将其缓存在当前Session的PGA中。这样做的好处是,当目标SQL再次被执行时,Oracle就不需要为其再生成一个SessionCursor了,只需要从当前Session的PGA中将之前已经被标记为SoftClosed的匹配SessionCursor直接拿过来用就可以了(当然,剩下的Parse、Bind、Execute、Fetch还是需要做的)。所以应用类型三和应用
类型二比起来,可以省掉Open—个新的SessionCursor及Close—个现有SessionCursor所耗费的资源和时间。Oracle可以通过己缓存的SessionCursor中存储的目标SQL对应的ParentCursor的库缓存对象句柄地址,来建立目标SQL的SessionCursor与其ParentCursor之间的联系,这意味着Oracle可以直接通过己缓存的SessionCursor来定位其对应的ParentCursor,而不再需要先持有库缓存相关Latch,然后再去库缓存的相应HashBucket中的库缓存对象句柄链表中査找匹配的ParentCursor。所以在Oracle 11g之前,应用类型三在对库缓存相关Latch的争用方面会比应用类型二要好
应用类型三的特点是SQL语句使用了绑定变量,而且数据库端参数SESSION_CACHED_CURSORS的值大于0,这意味着这种类型的应用系统中的每一条SQL语句所对应的SessionCursor在经历Execute阶段后,当满足一定的额外条件时(在OraclellgR2中,这个额外条件是该SessionCursor所对应的SQL解析和执行的次数要超过3次),Oracle就不会对上述SessionCursor执行Close操作,而是将其标记为SoftClosed,并将其缓存在当前Session的PGA中。这样做的好处是,当目标SQL再次被执行时,Oracle就不需要为其再生成一个SessionCursor了,只需要从当前Session的PGA中将之前已经被标记为SoftClosed的匹配SessionCursor直接拿过来用就可以了(当然,剩下的Parse、Bind、Execute、Fetch还是需要做的)。所以应用类型三和应用
类型二比起来,可以省掉Open—个新的SessionCursor及Close—个现有SessionCursor所耗费的资源和时间。Oracle可以通过己缓存的SessionCursor中存储的目标SQL对应的ParentCursor的库缓存对象句柄地址,来建立目标SQL的SessionCursor与其ParentCursor之间的联系,这意味着Oracle可以直接通过己缓存的SessionCursor来定位其对应的ParentCursor,而不再需要先持有库缓存相关Latch,然后再去库缓存的相应HashBucket中的库缓存对象句柄链表中査找匹配的ParentCursor。所以在Oracle 11g之前,应用类型三在对库缓存相关Latch的争用方面会比应用类型二要好
应用类型四的特点为如下所示:
(1)SQL语句使用了绑定变量。
(2)数据库端参数SESSION_CACHED_CURSORS的值大于0。
(3)该类型应用系统通过一些手段(例如在Pro*C/C++代码里通过设置HOLD_CURSOR=YES和RELEASE_CURSOR=NO,或者在PL/SQL代码的循环内部执行目标SQL),使得每一条SQLi吾句所对应的SessionCursor会反复经历Execute和Fetch,但Open、Parse、Bind和Close只用经历一次。
总结:使用绑定变量(最好是用批量绑定)来有效的降低系统硬解析的数量,并且将应用系统设计成“一次解析,多次执行”的方式。
(1)SQL语句使用了绑定变量。
(2)数据库端参数SESSION_CACHED_CURSORS的值大于0。
(3)该类型应用系统通过一些手段(例如在Pro*C/C++代码里通过设置HOLD_CURSOR=YES和RELEASE_CURSOR=NO,或者在PL/SQL代码的循环内部执行目标SQL),使得每一条SQLi吾句所对应的SessionCursor会反复经历Execute和Fetch,但Open、Parse、Bind和Close只用经历一次。
总结:使用绑定变量(最好是用批量绑定)来有效的降低系统硬解析的数量,并且将应用系统设计成“一次解析,多次执行”的方式。
Oracle里查询转换的作用
oracle 里的查询转换,又称为查询改写,它是 oracle 在解析目标 SQL 的过程中的重要一步,其含义是指oracle 在解析目标 SQL 时可能会对其做等价改写,目的是为了能更高效地执行目标 SQL ,即oracle 可能会将目标 SQL 改写成语义上完全等价但执行效率却更高的形式。
oracle 数据库里 SQL 语句的执行过程可以用下图 来表示。

当用户提交待执行的目标 SQL 后, Oracle一首先会执行对目标 SQL 的解析过程。在这个过程中, Oracle
会先执行对目标 SQL 的语法、语义和权限的检查。如果目标 SQL 能通过上述检查,接下来 oracle 就会去
Library Cache 中查找匹配的 shared cursor 。如果找到匹配的 Shared Cursor , oracle 就会把存储于该 Shared
Curso :中的解析树和执行计划直接拿过来重用,这相当于跳过了后续的“查询转换”和“查询优化”两个步骤,
直接进入到“实际执行”阶段。
如果找不到匹配的 Shared Cursor,就意味着此时没有可以被共享的解析树和执行计划,接下来整个执行过程
就进入到查询转换这一步。在这一步里, Oracle 会根据一些规则来决定是否对目标 SQL 执行查询转换,
在 Oracle不同的版本里这些规则不尽相同.比如在 Oracle 9i中, Oracle 会内置一些查询转换规则,只要 目标
SQL 满足了这些规则的要求, Oracle 就会对其执行查询转换,即在 Oracle 9i中,查询转换是独立于优化器的,
它与优化器的类型无关(不管是 CBO 还是 RBO ) ,因为 Oracle 此时会认为经过杏询转换后的等价改写 SQL 的
执行效率一定比原目标 SQL 的执行效率高。但这种情况在 Oracle 10g 里发生了变化,在 Oracle 10g 及其以后的
版本中, Oracle 会对某些类型的查询转换(比如子查询展开、复杂视图合并等)计算成本,即 Oracle 会分别计算
经过查询转换后的等价改写 SQL 的成本和原始 SQL 的成本,只有当等价改写 SQL 的成本值小于未经过查询转换的
原始 SQL 的成本值时, Oracle 才会对目标 SQL 执行这些查询转换,这也意味着在 Oracle 10g及其以后的版本中
,查询转换不再独立于优化器,它己经和 CBO 密切相关了,这可能是因为 Oracle 意识到并不是所有经过查询转
换后的等价改写 SQL 的执行效率就 ·一定会比原目标 SQL 的执行效率要高的缘故。执行完查询转换这一步后,原目
标 SQL 可能就己经被 Oracle 改写了,在执行下一步查询优化( Query Ontimization )时,优化器所面对的 SQL
就己变成了等价改写形式。当然,如果 Orade 发现并不能对原口标 SQL 做查询转换,那么即使执行完查询转换这
一步,原目标 SQL 也不会发生任何改动,即此时执行下一步查询优化时优化器所面对的 SQL 就还是原目标 SQL 。
接下来,就正式进入了查询优化这个步骤。在这个步骤里,根据不同的优化器类型, Orade 会采用不同的判断原
则,从执行完查询转换后得到的目标 SQL 的诸多可能的执行路径中选择一条来作为其执行计划,即杏询优化的输入
就是执行完查询转换后得到的等价改写 SQL ,其输出就是该 SQL 的执行计划。