html项目案例_Python爬虫项目案例: 豆瓣top250电影榜单爬取2020年8月最新(附源代码,数据)...

网站首页:
https://movie.douban.com/top250?start=0&filter=爬取步骤:
共250部电影,分10页,每页25部,点击每部图片可进入详情页,我们爬取详情页的信息
1.分别爬取10页html
2.分别从10页html中,找到共250个详情页的url
3.分别从250个详情页url,爬取详情页html
4.分别从250个详情页html从解析目标信息,并存储在列表中,形成由每部电影一个列表,含有250个列表的 列表列表
6.存储为excel文件(注意修改路径!!!)
代码如下:(想要源代码或爬取数据评论或私信就行)
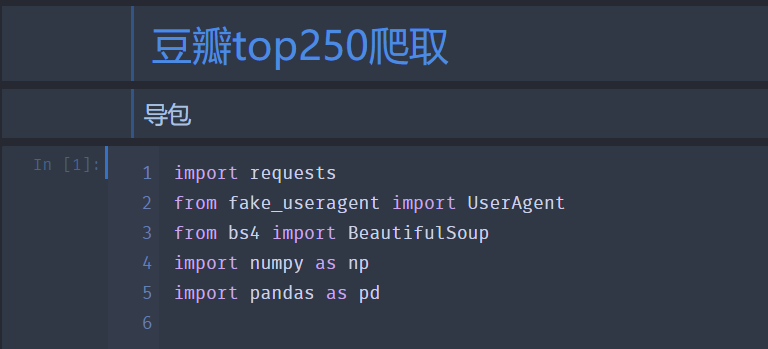

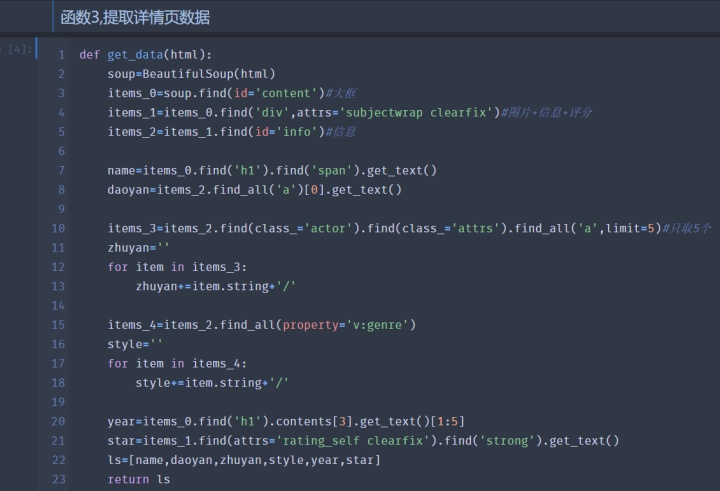
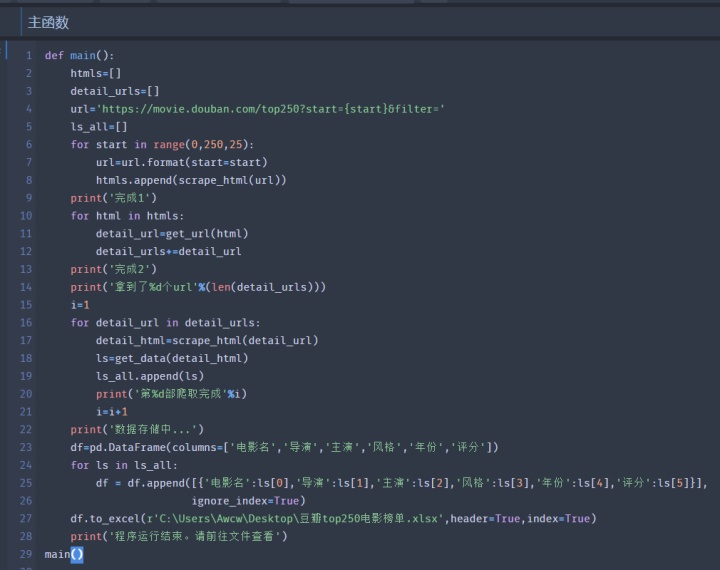
结果如下

下一次将会对这次爬取的电影榜单进行数据分析,探寻经典电影中蕴含的规律与价值,欢迎关注!
最后,想要源数据和代码的可以,评论或私信我,手头还有很多的数据分析和爬虫的项目案例希望和大家一起交流和分享,求大家点个赞吧!