一、作用域说明(一)
#加载顺序:内置 -- 全局 -- 局部
#名字查找顺序:局部 -- 全局 -- 内置
#作用域关系:在函数定义时已经固定,与调用位置无关 x=1 def f1(): def f2(): print(x) return f2 func=f1() x=999 func() #fun 找的是f1,f1找的是f2,f2打印x,x在局部没有,就找全局的,也就是x=1 #调用阶段,全局的x已经被修改为999,所以打印的是999
二、作用域说明(二)
x=1 def f1(): def f2(): print(x) return f2 def foo(func): x=888 func() foo(f1()) #foo执行,参数是func,也就是f1,f1找f2,f2找x的值,也就是1,x是全局的,已经固定好了 #foo的时候,局部的x=888的值,不会修改全局的x,所以结果是1
三、闭包函数
#闭包函数 #1.定义在函数内部的函数 #2.包含对外部作用域名字的引用,而不是对全局作用域名字的引用 x=1 def f1(): x=893 def f2(): print(x) return f2 func=f1() func() #f2定义在函数内部;对外部作用域x=893引用,而没有引用全局的x,所以f2就是闭包函数
闭包函数进一步说明
#通过闭包思想,给函数传参,如下例子: #想给函数wrapper传入参数,可以封装到另外一个函数里,此时,wrapper就是闭包函数,无论如何都有一个参数x=629 x=730 def deco(): x=629 def wrapper(): print(x) return wrapper func=deco() func() #调用的时候,就没必要每次传入参数
四、装饰器前言
#需求:如下函数,计算函数执行时间,但不修改源代码 #第一步: import time def index(): time.sleep(3) print("Welcome to the first page") def wrapper(func): start=time.time() func() stop=time.time() print("execute time is %s" %(stop-start)) wrapper(index) #这样可以得到结果,但是修改了调用方式,调用方式应该是index() #第二步 #不想给wrapper传参,就需要用闭包思想,将参数放入外部作用域,如下 import time def index(): time.sleep(3) print("Welcome to the first page") def timmer(): func=index def wrapper(): start=time.time() func() stop=time.time() print("execute time is %s" %(stop-start)) return wrapper index=timmer() #获取wrapper index() #调用wrapper #刚才的需求已经实现 #第三步骤,如果再来一个函数 import time def index(): time.sleep(3) print("Welcome to the first page") def home(): time.sleep(3) print("Welcome to the home page") def timmer(): func=index def wrapper(): start=time.time() func() stop=time.time() print("execute time is %s" %(stop-start)) return wrapper #这样,如何实现,对home也可以? import time def index(): time.sleep(3) print("Welcome to the first page") def home(): time.sleep(3) print("Welcome to the home page") #对timmer函数传参 def timmer(func): #func=index #将此处定义的参数传入 def wrapper(): start=time.time() func() stop=time.time() print("execute time is %s" %(stop-start)) return wrapper index=timmer(index) home=timmer(home) index() home()
五、装饰器
#对于上面的实现,装饰器的写法如下: import time def timmer(func): def wrapper(): start=time.time() func() stop=time.time() print("execute time is %s" %(stop-start)) return wrapper @timmer #index=timmer(index) def index(): time.sleep(3) print("Welcome to the first page") @timmer #home=timmer(home) def home(): time.sleep(3) print("Welcome to the home page") index() home()
返回结果:
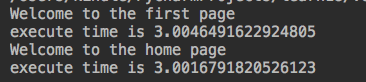
六.装饰器后续(一)
如果home有一个参数的条件?先注释掉index
import time def timmer(func): def wrapper(): start=time.time() func() stop=time.time() print("execute time is %s" %(stop-start)) return wrapper # @timmer #index=timmer(index) # def index(): # time.sleep(3) # print("Welcome to the first page") @timmer #home=timmer(home) def home(name): #如果home有一个参数呢 time.sleep(3) print("Welcome to the home page %s" %name) # index() home()
报错:

分析:
给home加了参数,home其实就是timmer的的参数,timmer运行,调用的wrapper,wrapper调用的是func,给func传参,也就是wrapper传参
import time def timmer(func): def wrapper(name): #此处传参 start=time.time() func(name) #这里传参 stop=time.time() print("execute time is %s" %(stop-start)) return wrapper # @timmer #index=timmer(index) # def index(): # time.sleep(3) # print("Welcome to the first page") @timmer #home=timmer(home) def home(name): #如果home有一个参数呢 time.sleep(3) print("Welcome to the home page %s" %name) # index() home('ckl')
这样调用成功:

问题来了,如果调用index呢?
import time def timmer(func): def wrapper(name): #此处传参 start=time.time() func(name) #这里传参 stop=time.time() print("execute time is %s" %(stop-start)) return wrapper @timmer #index=timmer(index) def index(): time.sleep(3) print("Welcome to the first page") @timmer #home=timmer(home) def home(name): #如果home有一个参数呢 time.sleep(3) print("Welcome to the home page %s" %name) index() home('ckl')
报错:

解决思路,有没有用方法,既可以传参,也可以不传参,可以用*args**kwargs
import time def timmer(func): def wrapper(*args,**kwargs): #此处传参 start=time.time() func(*args,**kwargs) #这里传参 stop=time.time() print("execute time is %s" %(stop-start)) return wrapper @timmer #index=timmer(index) def index(): time.sleep(3) print("Welcome to the first page") @timmer #home=timmer(home) def home(name): #如果home有一个参数呢 time.sleep(3) print("Welcome to the home page %s" %name) index() home('ckl')
解决:
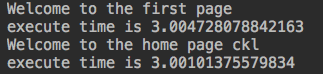
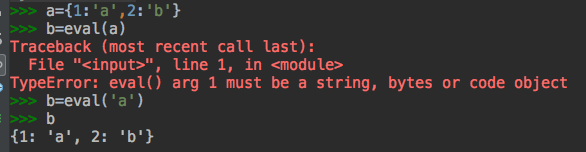
eval 用法:
七、无参数装饰器用户认证示例
用户文件db.txt
{'ckl':'123456','zld':'67890'}
认证程序:
#无参装饰器 current_user={'user':None} def auth(func): def wrapper(*args,**kwargs): if current_user['user']: return func(*args,**kwargs) name = input('name: ').strip() password = input('password: ').strip() with open('db.txt',encoding='utf-8') as f: user_dic = eval(f.read()) if name in user_dic and password == user_dic[name]: res = func(*args,**kwargs) current_user['user']=name return res else: print('user or password error') return wrapper @auth def index(): print('from index') @auth def home(name): print('welcome to home %s' %name) index() home('ckl')
运行结果:
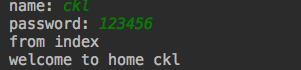
八、带参数装饰器
问题:接上,这样用户认证不是文件,是其它来源呢?如下:
current_user={'user':None}
def auth(func):
def wrapper(*args,**kwargs):
if auth_type == 'file':
if current_user['user']:
return func(*args,**kwargs)
name = input('name: ').strip()
password = input('password: ').strip()
with open('db.txt',encoding='utf-8') as f:
user_dic = eval(f.read())
if name in user_dic and password == user_dic[name]:
res = func(*args,**kwargs)
current_user['user']=name
return res
else:
print('user or password error')
elif auth_type == 'mysql':
print("from mysql")
elif auth_type == 'oracle':
print("from mysql")
else:
print("not found your type")
return wrapper
@auth
def index():
print('from index')
@auth
def home(name):
print('welcome to home %s' %name)
index()
home('ckl')
分析
#那么,auth_type参数传到哪里?
#如果加到这里
def wrapper(*args,**kwargs,auth_type):
#这样就违反了wrapper的定义作用,这里不能加参数
#加到这里呢
def auth(func,auth_type):
#这样就违反了auth的认证,无法加参数
#那么,可以吧参数加到auth上面即可
auth_type='mysql'
def auth(func):
#这是解决方法,但是必须再包一层,把参数带入,并通过返回,打破层级限制
带参装饰器 current_user={'user':None} def auth(auth_type='file'): def deco(func): def wrapper(*args, **kwargs): if auth_type == 'file': if current_user['user']: return func(*args, **kwargs) name = input('name: ').strip() password = input('password: ').strip() with open('db.txt', encoding='utf-8') as f: user_dic = eval(f.read()) if name in user_dic and password == user_dic[name]: res = func(*args, **kwargs) current_user['user'] = name return res else: print('user or password error') elif auth_type == 'mysql': print("from mysql") elif auth_type == 'oracle': print("from mysql") else: print("not found your type") return wrapper return deco @auth(auth_type='mysql') def index(): print('from index') @auth() def home(name): print('welcome to home %s' %name) index() home('ckl')
九、迭代器
可迭代对象iterable:凡是对象下有__iter__方法;对象.__iter__,该对象就是可迭代对象
字典示例说明
dic = {'ckl':123,'zld':'456'}
i=dic.__iter__() #dic有__iter__方法,dic就是可迭代对象
#i 就是迭代器iterator
#i.__next__() == next(i)
print(next(i))
print(next(i))
print(next(i)) #StopIteration
结果:

列表示例说明
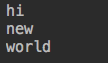
s_list = ['hi','new','world'] s = s_list.__iter__() #s_list就是可迭代对象,s是迭代器 print(next(s)) print(next(s)) print(next(s)) print(next(s))
结果:

十、使用迭代器与不使用迭代器对比
列表示例说明
未使用迭代器取值操作,依赖索引
s_list = ['hi','new','world'] count=0 while count < len(s_list): print(s_list[count]) count+=1
结果:

使用迭代器取值操作
s_list = ['hi','new','world'] s_i = s_list.__iter__() #得到list的迭代器 while True: try: print(next(s_i)) #从迭代器里取值 except StopIteration: break
结果:
字典示例说明
未使用迭代器之前
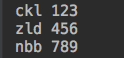
dic = {'ckl':123,'zld':'456','nbb':789}
for i in dic:
print(i,dic[i])
运行结果
使用迭代器:
dic = {'ckl':123,'zld':'456','nbb':789}
i_dic = iter(dic) # dic.__inter__()
while True:
try:
s=next(i_dic)
print(s,dic[s])
except StopIteration:
break
结果:

十一、迭代器优缺点
迭代器对象:
1.有__iter__,执行仍然是迭代本身
2.有__nex__
迭代器优点
1.提供了一种统一的(不依赖索引的)迭代方式
2.迭代器本身,比起其它数据类型更节省内存
文件示例说明
文件内容:
222 333 333 333 你好啊,世界你好啊,世界 333 zhende 你好啊,世界 .....
文件打开读取的操作:
with open('access.log','r') as f: #f.__iter__() #f就是一个迭代器,拥有__inter__和__next__ print(next(f)) print(next(f)) print(next(f)) print(next(f))
结果:

这样操作,更节省内存,不需要一下将所有内容加载到内存,需要一条取一条
迭代器缺点
1.一次性,只能往后走,不能回退,不如索引取值灵活
2.无法预知什么时候取值结束,即无法预知长度
for 循环原理
#for循环打开的都是可迭代对象 s_list = ['hi','new','world','like'] for item in s_list: print(item)
补充:判断可迭代对象与迭代器对象
可迭代对象判断:
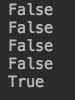
from collections import Iterable,Iterator s_list = ['hi','new','world','like'] dic = {'ckl':123,'zld':'456','nbb':789} s = 'hello' t = ('a','b','c','d') set1 = {4,5,6,7,8} f1=open('db.txt') print(isinstance(s_list,Iterable)) print(isinstance(s,Iterable)) print(isinstance(t,Iterable)) print(isinstance(set1,Iterable)) print(isinstance(f1,Iterable))
结果:

迭代器判断:
from collections import Iterable,Iterator s_list = ['hi','new','world','like'] dic = {'ckl':123,'zld':'456','nbb':789} s = 'hello' t = ('a','b','c','d') set1 = {4,5,6,7,8} f1=open('db.txt') print(isinstance(s_list,Iterator)) print(isinstance(s,Iterator)) print(isinstance(t,Iterator)) print(isinstance(set1,Iterator)) print(isinstance(f1,Iterator))
#只有文件是迭代器
结果:
十二、生成器
生成器:在函数内部包含yield关键字,那个该函数执行的结果是生成器
生成器就是一个迭代器
yield的功能:
1.把函数的结果做成迭代器(以一种优雅的方式封装好__iter__,__next__,方法)。
2.yield暂停函数,保存状态
def func(): print("Welcome") yield 1 #暂停函数运行,并且有返回值 print("The") yield 2 print("New") yield 3 print("World") g=func() #g.__iter__() g.__next__() g有这两个方法,g就是一个迭代器对象 next(g) next(g) next(g) next(g) #StopIteration for i in g: #循环迭代器,打印结果 print(i)
python3的range函数就是用yield,所以无论存多少值,内存都不会爆。因为只有在调用的时候才存值,且存一个。
模拟range
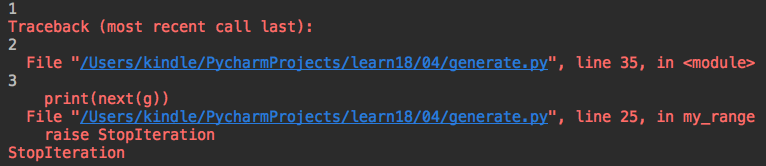
def my_range(x,y): while True: if x == y: #如果起始值等于结束值,就抛出异常 raise StopIteration yield x #暂停并return 起始值 x+=1 g=my_range(1,4) print(next(g)) print(next(g)) print(next(g)) print(next(g)) #超出范围
结果:
完整如下:
def my_range(x,y): while True: if x == y: #如果起始值等于结束值,就抛出异常 raise StopIteration yield x #暂停并return 起始值 x+=1 g=my_range(1,4) # print(next(g)) # print(next(g)) # print(next(g)) # print(next(g)) #超出范围 for i in g: print(i)
结果:

yield和return区别
相同:都有返回值
不同:return只能返回一次值程序就结束;yield可以返回多次值,暂停函数的运行
模拟tail
实现tail方法,之前实现:
import time def tailf(f_name): with open(f_name,'r') as fb: fb.seek(0,2) #光标跳到文件末尾 while True: #一直循环 content=fb.readline() if content: #如果有内容,打印结果 print(content) else: time.sleep(0.5) #没有等待0.5秒,再循环 tailf('access.log')
文件内容:
222 333 333 333 你好啊,世界你好啊,世界 333 zhende ....
追加内容脚本:
with open('access.log','a') as fa: fa.writelines("hi girl")
运行tail程序:
运行追加程序
查看结果:
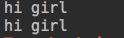
思考:如果我想实现过滤呢,如tailf ckl.txt | grep 'error' 这样的功能呢?
需要将tail的结果传递给grep程序
修改tail方法,增加grep
import time def tailf(f_name): with open(f_name,'r') as fb: fb.seek(0,2) while True: content=fb.readline() if content: yield content #将结果返回,并且暂停 else: time.sleep(0.5) def grep(pattern,lines): for line in lines: if pattern in line: print(line) # tailf('access.log') grep('error',tailf('access.log')) #将tailf的结果追加到grep里
运行结果:
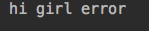
没有任何,打印,因为输出没有过滤条件有error,而结果没有
输出错误字段:
十三、生成器进一步说明
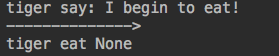
def eater(name): print("%s say: I begin to eat!" %name) while True: food = yield print('%s eat %s' %(name,food)) tiger_g=eater('tiger') next(tiger_g) print('-------------->') next(tiger_g)
运行结果:
运行分析
- 加载定义的函数eater()
- 加载tiger_g生成器
tiger_g=eater('tiger') - 调用next方法
next(tiger_g)
- 运行eater(name),参数为tiger
- 运行
print("%s say: I begin to eat!" %name) #打印 tiger say: I begin to eat! - 进入循环
- 运行如下
food = yield #给food赋值为None,返回None,暂停函数执行
- 运行:
print('-------------->') - 继续运行next方法
- 进入循环,food的值为None
- 运行:
print('%s eat %s' %(name,food)) #tiger eat None - 再次进入循环
- food赋值为None,返回值为None,yield结束循环
通过send方法传值:
def eater(name): print("%s say: I begin to eat!" %name) while True: food = yield print('%s eat %s' %(name,food)) tiger_g=eater('tiger') tiger_g.send('rabbit') print('*'*20) tiger_g.send('bird') print('*'*20)
运行报错:

因为send运行前,迭代对象必须有一个初始值,修改如下:
def eater(name): print("%s say: I begin to eat!" %name) while True: food = yield print('%s eat %s' %(name,food)) tiger_g=eater('tiger') #第一阶段:初始化 next(tiger_g) #tiger_g.send(None) print('*'*20) #通过send给yield传值 print(tiger_g.send('rabbit')) #给food传值为rabbit,并且返回值为None print('*'*20) print(tiger_g.send('bird')) #给food传值为bird,并且返回值为None print('*'*20)
结果:

现在返回值为空,我可以传入返回值,如下:
def eater(name): print("%s say: I begin to eat!" %name) while True: food = yield 888 #传入返回值 print('%s eat %s' %(name,food)) tiger_g=eater('tiger') #第一阶段:初始化 next(tiger_g) #tiger_g.send(None) print('*'*20) #通过send给yield传值 print(tiger_g.send('rabbit')) #给food传值为rabbit,并且返回值为None print('*'*20) print(tiger_g.send('bird')) #给food传值为bird,并且返回值为None print('*'*20)
运行结果:

这样,每次的返回值都是888。进一步思考,可否将每次赋值的内容存入到一个列表呢?
修改如下:
def eater(name): food_list = [] print("%s say: I begin to eat!" %name) while True: food = yield food_list.append(food) print('%s eat %s' %(name,food)) print(food_list) tiger_g=eater('tiger') #第一阶段:初始化 next(tiger_g) #tiger_g.send(None) print('*'*20) #通过send给yield传值 print(tiger_g.send('rabbit')) #给food传值为rabbit,并且返回值为None print('*'*20) print(tiger_g.send('bird')) #给food传值为bird,并且返回值为None print('*'*20)
运行结果:

这样,每次传值都追加都列表里,列表的内容就是每次传值的内容,可以将列表的内容返回,如下:
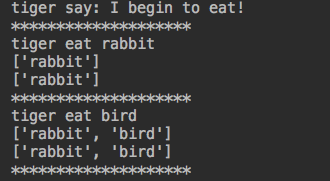
def eater(name): food_list = [] print("%s say: I begin to eat!" %name) while True: food = yield food_list food_list.append(food) print('%s eat %s' %(name,food)) print(food_list) tiger_g=eater('tiger') #第一阶段:初始化 next(tiger_g) #tiger_g.send(None) print('*'*20) #通过send给yield传值 print(tiger_g.send('rabbit')) #给food传值为rabbit,并且返回值为None print('*'*20) print(tiger_g.send('bird')) #给food传值为bird,并且返回值为None print('*'*20)
运行结果:
进一步思考
可以将函数的执行结果返回到另外一个函数里,而不结束运行,函数交互运行
def eater(name): food_list = [] print("%s say: I begin to eat!" %name) while True: food = yield food_list food_list.append(food) print('%s eat %s' %(name,food)) def feeding(): tiger_g = eater('tiger') # 初始化 next(tiger_g) # 给yield传值 while True: food = input(">> ").strip() if not food: continue tiger_g.send(food) #传入输入的值 feeding()
运行结果:

每次执行都需要初始化,为初始化添加装饰器
def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init def eater(name): food_list = [] print("%s say: I begin to eat!" %name) while True: food = yield food_list food_list.append(food) print('%s eat %s' %(name,food)) tiger_g=eater('tiger') tiger_g.send('jimihua')
执行结果,不需要next:

yile 文件内容过滤示例
需求如下:过滤当前架构下所有文件里面包含error字段的文件,并打印出文件名
目录结构如下:
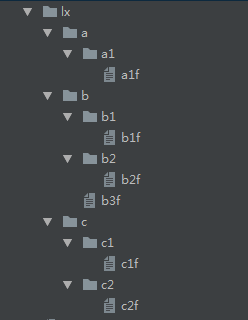
包含error字段的文件为:a1f b2f b3f c2f
实现如下:
#1.获取文件的详细路径 import os def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper #1.获得文件路径及文件 @init def getpath(target): while True: #获取目录路径 filepath = yield x=os.walk(filepath) #循环所有列表,如果列表最后一个字段为文件则执行 for abspath,_,fname in x: if fname: fname=''.join(fname) #将文件文件路径及文件名合并为文件的绝对路径 total_file = "%s\%s" %(abspath,fname) #返回文件路径,也就是名的绝对路径 fpath=total_file #此处的target就是getfile(),发送文件及文件名 target.send((total_file,fpath)) #2.打开文件 @init def getfile(target): while True: #接收文件名和文件路径 filename,abspath = yield #打开文件,以读的方式 with open(filename,'r') as f_read: #此处的target就是op_file(), 发送打开文件管道及文件路径 target.send((f_read,abspath)) # #3.读取文件内容 @init def op_file(target): while True: #接收文打开管道及文件路径 f,abspath = yield for i in f: #此处的target就是grep(),发送文件行及文件路径 target.send((i,abspath)) # #4.过滤错误内容 @init def grep(e_arg): while True: #接收行及文件路径 lines,abspath = yield #如果行包含错误字段,就打印此文件路径 if e_arg in lines: print(abspath) g=getpath(getfile(op_file(grep('error')))) g.send(r'D:\py_pro\005\lx')
查看结果:

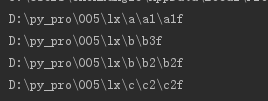
问题:b2f文件出现了两次?分析发现,这个文件里面有两次error的行,解决办法:如果遇到一个error的,后续内容就不再读取
改良如下:
#1.获取文件的详细路径 import os def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper #1.获得文件路径及文件 @init def getpath(target): while True: #获取目录路径 filepath = yield x=os.walk(filepath) #循环所有列表,如果列表最后一个字段为文件则执行 for abspath,_,fname in x: if fname: fname=''.join(fname) #将文件文件路径及文件名合并为文件的绝对路径 total_file = "%s\%s" %(abspath,fname) #返回文件路径,也就是名的绝对路径 fpath=total_file #此处的target就是getfile(),发送文件及文件名 target.send((total_file,fpath)) #2.打开文件 @init def getfile(target): while True: #接收文件名和文件路径 filename,abspath = yield #打开文件,以读的方式 with open(filename,'r') as f_read: #此处的target就是op_file(), 发送打开文件管道及文件路径 target.send((f_read,abspath)) # #3.读取文件内容 @init def op_file(target): while True: #接收文打开管道及文件路径 f,abspath = yield for i in f: #此处的target就是grep(),发送文件行及文件路径 res=target.send((i,abspath)) #------------> 获取到grep()返回的结果 if res: #----------------> 如果res为ture就结束循环,不再循环后面的内容 break # #4.过滤错误内容 @init def grep(e_arg): tag = False #---------> 起始值为False while True: #接收行及文件路径 lines,abspath = yield tag #------------> 返回tag #如果行包含错误字段,就修改tag为True并打印此文件路径,否则修改为False if e_arg in lines: tag = True print(abspath) else: tag = False g=getpath(getfile(op_file(grep('error')))) g.send(r'D:\py_pro\005\lx')
执行结果:
十四、递归
递归调用:在调用一个函数的过程中,直接或间接调用了函数本身
def count_age(n): if n == 1: return 20 return count_age(n-1)+3 print(count_age(5))
结果为:30
分析:
count_age(5) --> count_age(4)+3 --> count_age(3)+3 --> count_age(2)+3 --> count_age(1)+3 #递推
32 <----- 29 + 3 <---------- 26 + 3 <------------ 23 +3 <----------- 20 + 3 #回溯
递归的两个节点:递推,回溯
递归特点:
1.有一个明确的结束条件
2.每次递归规模比上次递归都减小
3.递归效率不高
递归使用的条件:循环的次数无法确定
递归举例:
打印列表的所有元素:
l = [1,2,[3,[4,5,6,[7,8,[9,10,[11,12,13,[14,15,[16,17,18,19,[20,21,22,[23]]]]]]]]]] def func(x): for i in x: if type(i) is not list: #这就是结束条件 print(i) else: func(i) func(l)
十五、二分法查找
自己实现的最简单的二分法查找
l = [1,3,4,7,9,12,19,21,26,31,32,39,42,51,58,69,78,93,109] def binary_search(l,num): if len(l) > 1: mid_index = len(l) // 2 print(l) if num == l[mid_index]: print("find it") return elif num > l[mid_index]: l=l[mid_index:] elif num < l[mid_index]: l=l[:mid_index] binary_search(l,num) else: print("not found") binary_search(l,41)
斐波那契数列
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 4 def Fobinaq(arg1,arg2,stop): 5 if arg1 == 0: 6 print(arg1,arg2) 7 arg3 = arg1 + arg2 8 print(arg3) 9 if arg3 < stop: 10 Fobinaq(arg2,arg3,stop) 11 12 Fobinaq(0,1,50)
列表旋转90度脚本
[1][2][3][4]
[1][2][3][4]
[1][2][3][4]
[1][2][3][4]
脚本:
1 #!/usr/bin/env python 2 #-*- coding:utf-8 -*- 3 """ 4 列表旋转90度 5 """ 6 7 """ 8 data = [[i for i in range(4)] for m in range(4)] 9 10 for r_index,row in enumerate(data): 11 for c_index in range(r_index,len(row)): 12 tmp = data[c_index][r_index] 13 data[c_index][r_index] = row[c_index] 14 data[r_index][c_index] = tmp 15 16 print('-'*10) 17 for r in data: 18 print(r) 19 """ 20 21 data = [[col for col in range(4)] for row in range(4)] 22 23 for i in range(len(data)): 24 a = [data[i][i] for row in range(4)] 25 print(a)