HFile结构
截止hbase 1.0.2版本,hfile已经有3个版本,要深入了解hfile的话,还是要从第一个版本开始看起。
hfile v1

Data Block:保存表中的数据,这部分可以被压缩
Meta Block:(可选)保存用户自定义的kv对,可以被压缩。
File Info :Hfile的meta元信息,不被压缩,定长。
Data Block Index :Data Block的索引。每个Data块的起始点。
Meta Block Index:(可选的)Meta Block的索引,Meta块的起始点。
Trailer: 定长。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer有指针指向其他数据块的起始点,保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储。Data Block是HBase I/O的基本单元,为了提高效率,HRegionServer中有基于LRU的Block Cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定,大号的Block有利于顺序Scan,小号Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成, Magic内容就是一些随机数字,目的是防止数据损坏。
注意,block是hfile的最小压缩和编码数据块,默认128KB
第一版的block index是非常简单的,注意只有两个block index,一个是data block index,一个是meta block index,block index包括了以下几点:
1. offset
2. Uncompressed size
3. Key (a serialized byte array written using Bytes.writeByteArray)
3.1 Key length as a variable-length integer (VInt)
3.2 Key bytes
block index的数量会存放在trailer,这样才能读取到block index数据。
这个版本的block index有1个缺点
1. 无法知道block压缩后的数据大小,这在之后的解压过程是必要的
所以在版本2,解决了这个问题,在block index中增加了实际存储block大小的数据
hfile v2
在接口层面做了兼容,在读hfile的时候,支持v1和v2,在写hfile的时候,只会写v2版本的hfile。
hfile升级的原因:
1. v1 的设计导致了region server启动时间很长,需要加载很大的数据量,比如大量的bloom filter,大量的block index
为了解决这个问题,v2使得hfile增加了新特性,把bloom filter和block index打散,写到多个block中去,这样就减少了hfile 写入时候的内存offset。并且这些打散的block index会有预定的长度。
另一方面,v2还用到了 load-on-open 这个概念,意思是说,在打开hfile的时候,加载那些必要的信息,包括trailer,trailer里记录了hfile的必要信息。而其他数据就可以再用到的时候,通过trailer再解析出来
下图为hfile v2版本的结构
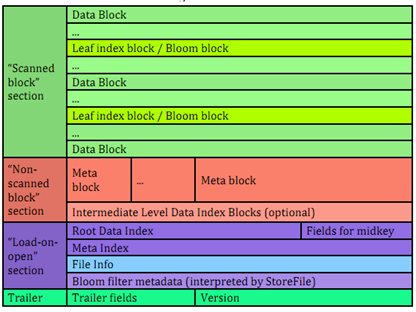
与V1版本的相比,它的区别在于
1)文件分为三部分:Scanned block section,Non-scanned block section,以及load-on-open
2) multi block index,为DataBlockIndex建立多层索引。DataBlockIndex分为Leaf Index Block、Root Data Index(或者multi Root Data index(紫色的Meta Index区域)),Leaf index block具体存储了DataBlock的offset、length、以及firstkey的信息。RootDataIndex 存储的是每个Leaf index block的offset、length、Leaf index Block记录的第一个key,以及截至到该Leaf Index Block记录的DataBlock的个数。假定DataBlock的个数足够多,HFile文件又足够大的情况下,默认的128KB的长度的ROOTDataIndex仍然存在超过chunk大小的情况时,会分成更多的层次。这样最终的可能是ROOT INDEX –> IntermediateLevel ROOT INDEX(可以是多层) -> Leaf index block,由此形成多级索引,在提高hfile的初始化加载速度的同时不影响对数据的查找性能,另外在ROOT INDEX中会记录Mid Key所对应的信息,帮助在做File Split或者折半查询时快速定位中间Row的信息。
简单来说,多级索引的目的是为了解决hfile过大导致block index过大。所以将block index分为root block index和non-root block index,分开存储。
关于midkey
hfile在存midkey的时候采用了shortKey的思路,比如上个block最后一个rowkey为"the quick brown fox", 当前block第一个rowkey为"the who", 那么我们可以用"the r"来作为midkey,和hbase rowkey的scan规则保持一致
存储短一点的虚拟midkey有两个好处:
1. 减少index部分的存储空间,因为自定义的rowkey可以会出现几KB这样极端的长度,精简过后,只需要几个字节
2. 采用与上一个block的最后一个rowkey更接近的虚拟key作为midkey,可以避免潜在的io浪费。如果midkey采用当前block的第一个rowkey,那么当查询的rowkey比midkey小但是比上一个block的最后一个rowkey大时,会去遍历上一个block,这就出现了无用功。而midkey更接近上一个block的最后一个rowkey时,可以在很大程度上避免这个问题,即直接返回该rowkey不在此hfile中。
// 很详细的中文翻译及解析
http://wangneng-168.iteye.com/blog/2164299
// 官方对hfile的介绍
https://hbase.apache.org/book.html#_hfile_format_2
hfile v3
增加安全方面特性,为cell级别增加ACL
hifle v3不和hfilev1和v2兼容,因为在存储keyvalue的时候,会额外的存储tags,用于控制ACL
总结
hbase的三个版本的hfile在文件结构层面逐渐完善,每个hfile文件都有自己独立的索引。理解这些结构对实际应用业务优化也是很有好处的。例如有很多场景需要多hbase的resion进行遍历而内存资源又有限的情况,假设计算引擎用的是spark,那么每个分区遍历一个region是不可能的,因为数据量太多,资源吃不下,而根据timestamp过滤分批遍历的话,性能有影响,相当于每个region都要被重复遍历。这种场景下,可以对region按照rowkey分割,每个spark分区只遍历一个region的部分rowkey,这样就可以无限拆分下去,再不也不用担心资源的问题。不过这就又出现了一个问题,如果用rowkey切割region,首先,rowkey如果设计的好的话,不同rowkey段的数据很均匀,那么可以直接根据业务切分。而如果无法评估出不同rowkey段和数据的对应关系,那么这个时候,可以利用到hfile。通过查看region下hfile文件中每个datablock的第一个rowkey,(由于datablock的index都是被保存在hfile的,所以datablock可被直接定位),用该rowkey切割region,并且可以以最小block的粒度来控制每批遍历region的数据量,这个粒度相信资源是完全够用的。