为了使用好Apache Flink,Yelp实现了一个连接算法
摘要
在Yelp,我们生成了大量高吞吐量的数据流,包括日志、业务数据和应用程序数据。我们需要对这些数据流进行连接、过滤、聚合,有时候甚至需要进行快速转换。为了实现这一过程,工程团队投入了大量时间来分析多个流式处理框架,最终确定Apache Flink是最佳选择。我们现在使用Flink实现了一个连接算法,我们称之为“Joinery”。它可以针对两个或两个以上基于键的数据流执行非时间窗口的一对一、一对多和多对多内部连接。
那么它的工作原理是什么?简单地说,就是开发人员提供用于描述所需连接的配置文件,Joinery服务负责执行并输出连接过的基于键的结果流。
背景:我们要解决什么问题?
自从流式管道出现以来,流和表之间的差距已经大大缩小。流式管道允许对高吞吐量数据流执行计算密集型的数据操作,如连接、过滤和聚合。虽然大多数流式管道支持基于时间窗口的连接,但在很多情况下也需要进行非时间窗口的连接。
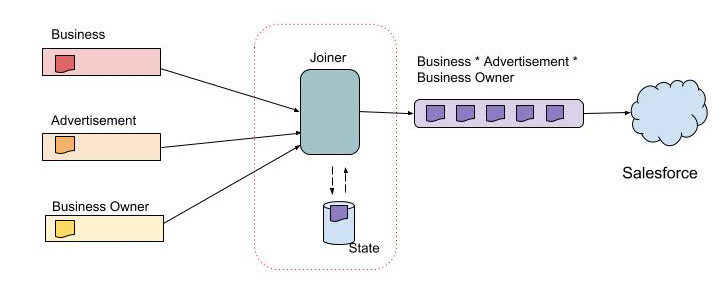
Salesforce就有这样的需求。Salesforce是我们在Yelp使用的一个下游数据存储,为销售团队提供支持。它包含了平台的业务数据,例如购买的广告包和业务所有者的资料。数据被存储在关系数据库中,但这些数据是非规范化的,以便在销售人员需要即时访问数据时(例如在向客户推销时)可以避免耗时的实时联接操作。
为了支持这个用例,我们实现了一个实时流连接器,用于连接多个数据流,并将关系数据库中的规范化表呈现为流,存入Salesforce的非规范化表中。在下图中,每个入站流表示关系数据库中的一张表。流连接器消费这些入站流中的消息,并基于消息键创建完全连接的消息,再将结果写到出站流中。例如,在下面的流连接器中,用于连接消息的消息键是business-id,它是业务和广告表的主键以及业务所有者表的外键。
之前的方法
从历史上看,Yelp工程团队已经构建了Paastorm来解决类似的问题。但是,当数据集增长到数十GB时,Paastorm带来了更高的维护成本。另一个问题是它们不是为有状态应用程序而设计的,因此使用Paastorm作为有状态解决方案意味着必须从头开始实施状态管理。例如,一个将结果上传到Salesforce的spolt保存了数千万条消息,一旦发生崩溃,需要花费几个小时来恢复!这将导致整个管道出现严重的延迟,并需要人工干预,最终导致工程生产力下降。
这种场景要求任何用于连接无界流的方法都必须具备可扩展性和容错能力。
一个连接算法?
基于我们过去在构建数据管道和聚合方面的经验,我们开发出了以下的连接算法:
算法:
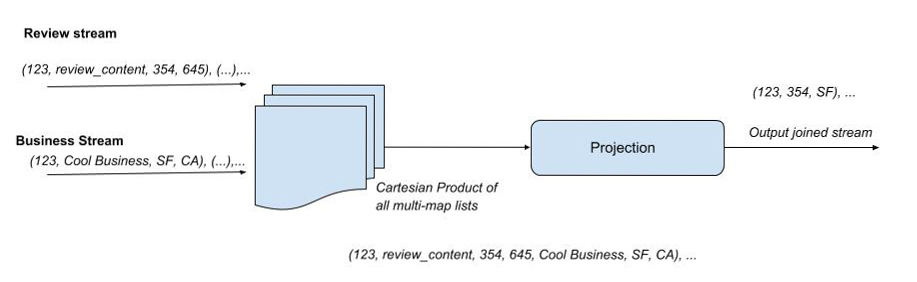
- 根据消息键将消息打散或排列到等值连接(equi-join)分区中。
- 将消息插入到相应的multi-map哈希表中。
- 通过获取所有multi-map的笛卡尔积来构造输出。
- 过滤、投射并输出结果。
上述算法可归纳为三个关键部分:
- 更新阶段;
- 连接阶段;
- 投射(Projection)阶段。
让我们更详细地介绍这些阶段。
更新阶段
对于每个输入,算法会创建一个哈希表,然后将消息与键映射起来。对于每个新传入的消息,我们会检查消息类型(类似于MySQL LogType——log、create、update、delete),并将create/update/delete消息分别加入到对应的哈希表中。
连接阶段
接下来,我们会探测上述的哈希表,以便生成所有消息的连接结果。这将生成所有可能的排列。然后,经过连接的消息被发布到目标流中。请注意,只有当入站消息具有相同的键时,连接的消息才会被发布到目标流中。这个算法的连接阶段执行的是内连接。
投射阶段
在创建输出消息期间,可以使用别名来投射输出流中的字段,以防止命名冲突。如果下游消费者不需要字段,也可以完全将字段删除。
这个算法仅适用于基于键的压缩日志型数据流。使用日志压缩型数据流可防止出现无限制的增长,并确保消费者应用程序至少可以保留Kafka分区中每个消息的最后一个已知值。这些约束意味着这个算法适用于数据变更日志流,而不是常规日志流。
在下图中,左侧表示输入流,消息来自不同的输入源。这张图描绘了输入流的笛卡尔积。在连接阶段,我们执行流聚合,当检测到输入源中具有相同键(在此示例中为id)的记录时,聚合操作会生成一个元组。换句话说,算法会检查输入流中的键是否在所有哈希表(流)中具有映射,如果有,就进入到投射阶段。
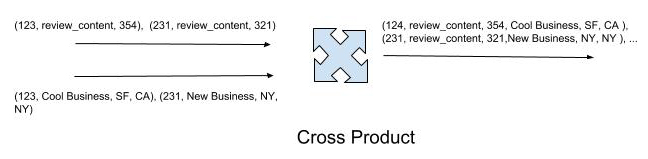
下图说明了算法是如何生成记录的:
这很酷,但内存占用是怎样的?
由于Joinery执行的是无界流的连接,因此其内部状态可能会变得非常大。维护巨大的内存状态是很昂贵的,而且无法进行快速的恢复。为了缓解这种情况,Joinery为数据流中的数据分配了键,这样有助于跨节点分配内存,但仍然无法阻止状态大小超出节点的总可用堆内存(这可能会导致OOM错误)。因此,我们需要一种方法将数据写到磁盘上,同时保持相对较低的内存占用。
通过利用Flink的增量检查点,我们可以将应用程序状态保存到外部存储。这样可以减少内存占用量,并且可以在几分钟内实现更快的恢复(与我们的spolt相比)。
一个端到端的例子
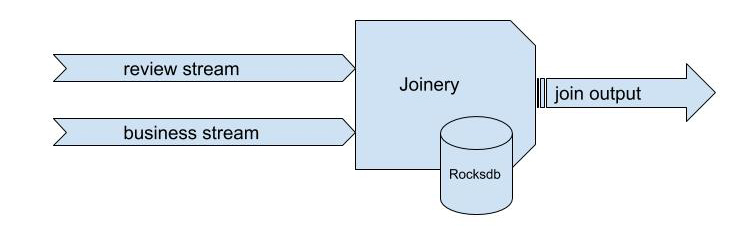
我们通过一个假设的场景来演示Joinery是如何连接两个流的:用户评论(user review)和业务(business)。
user review: - biz_id - content - review_id - user_id用户评论流
business: - business_id - name - address - state业务流
我们想要根据业务ID连接上述两个流,并生成一个输出流。Joinery配置如下:
join: - schema_id: 12345 join_keys: [biz_id] exclude_fields: [content, review_id] - schema_id: 23143 join_keys: [business_id] aliases: - from: business_id to: biz_id exclude_fields: [address, name] output: namespace: joinery_example source: business_review_join Doc: Join of business table and review table pkey: - business_idJoinery配置
上面的配置要求Joinery根据biz_id键来连接两个流。这里需要注意的是,即使两个流中都没有相同的键,我们也可以使用别名来映射键(类似于传统的SQL别名)。

未来的工作
我们现在面临的并希望在未来解决的主要挑战之一是在升级和状态迁移期间保持数据的完整性。部署在生产环境中的流式应用程序应该具备强壮的弹性,并且能够快速进行状态恢复。
对Joinery这样的应用程序进行黑盒测试和审计是很难的。Yelp已经开发了像pqctl(自定义docker compose环境)这样的工具,可以帮助基础设施团队进行可重复的简单单元测试。借助这个工具和大量的验收测试套件,我们希望能够测试到更多的端到端连接场景。其中一些正在进行中,但仍有很多工作要做,以确保我们可以在应用程序重启后验证状态,特别是在升级Joinery版本时。
附件:MJoin算法(http://www.vldb.org/conf/2003/papers/S10P01.pdf)
英文原文:https://engineeringblog.yelp.com/2018/12/joinery-a-tale-of-unwindowed-joins.html