2019独角兽企业重金招聘Python工程师标准>>> 
1: Hypothesis Testing
In this mission, we'll learn about hypothesis testing(假设检测) and statistical significance(统计有效性/统计显著性). A hypothesis is a pattern or rule about a process in the world that can be tested. We use hypothesis testing to determine if a change we made had a meaningful impact or not.
You can use hypothesis testing to help you determine:
- if a new banner ad on a website caused a meaningful drop in the user engagement,
- if raising the price of a product caused a meaningful drop in sales,
- if a new weight loss pill helped people lose more weight.
Observing a decrease in user engagement or sales after instituting a change doesn't automatically imply that the change was the cause. Hypothesis testing allows us to calculate the probability that random chance was actually responsible for the difference in outcome. Every process has some inherent amount of randomness that we can't measure and understanding the role of chance helps us reach a conclusion that's more likely to be correct.
We first set up a null hypothesis that describes the status quo. We then state an alternative hypothesis, which we used to compare with the null hypothesis to decide which describes the data better. In the end, we either need to:
- reject the null hypothesis and accept the alternative hypothesis or
- accept the null hypothesis and reject the alternative hypothesis.
We can frame each of the studies above as these rival pairs of hypotheses:
-
if a new banner ad on a website caused a meaningful drop in the user engagement:
- null hypothesis: users who were exposed to the banner ad spent the same amount of time on the website than those who weren't.
- alternative hypothesis: users who were exposed to the banner ad spent less time on the website than those who weren't.
-
if raising the price of a product caused a meaningful drop in sales:
- null hypothesis: the number of purchases of the product was the same at the lower price than it was at the higher price.
- alternative hypothesis: the number of purchases of the product was lower at the higher price than it was at the lower price.
-
if a new weight loss pill helped people lose more weight:
- null hypothesis: patients who went on the weight loss pill lost no more weight than those who didn't.
- alternative hypothesis: patients who went on the weight loss pill lost more weight than those who didn't.
In the rest of this mission, we'll focus on the third scenario and use data to determine if a weight loss pill helped people lose weight.
2: Research Design
To help us determine if the weight loss pill was effective, we conducted a study where we invited 100 volunteers and split them into 2 even groups randomly:
- Group A was given a placebo, or fake, pill and instructed to consumer it on a daily basis.
- Group B was given the actual weight loss pill and instructed to consume it on a daily basis.
Both groups were instructed to change nothing else about their diets. Group A is referred to as the control group while group B is referred to as the treatment group. This type of study is called a blind experiment since the participants didn't know which pill they were receiving. This helps us reduce the potential bias that is introduced when participants know which pill they were given. For example, participants who are aware they were given the weight loss pill may try to add healthier foods to their diet to help them lose more weight. Both groups were weighed before the study began and a month later, after the study ended.
Understanding the research design for a study is an important first step that informs the rest of your analysis. It helps us uncover potential flaws in the study that we need to keep in mind as we dive deeper. The weight loss pill study we conducted is known as an experimental study. Experimental studies usually involve bringing in participants, instructing them to perform some tasks, and observing them. A key part of running an experimental study is random assignment, which involves assigning participants in the study to random groups without revealing which group each participant is in. Before exploring and analyzing a dataset, it's important to understand how the study was conducted. Flaws in how the study was run can lead you to reach the wrong conclusions.
3: Statistical Significance
Statistics helps us determine if the difference in the weight lost between the 2 groups is because of random chance or because of an actual difference in the outcomes. If there is a meaningful difference, we say that the results are statistically significant. We'll dive into what this means exactly over the course of this mission.
Now that we're familiar with the study, let's state our null and alternative hypotheses more precisely. Our null hypothesis should describe the default position of skepticism, which is that there's no statistically significant difference between the outcomes of the 2 groups. Put another way, it should state that any difference is due to random chance. Our alternative hypothesis should state that there is in fact a statistically significant difference between the outcomes of the 2 groups.
- Null hypothesis: participants who consumed the weight loss pills lost the same amount of weight as those who didn't take the pill.
- Alternative hypothesis: participants who consumed the weight loss pills lost more weight than those who didn't take the pill.
The lists weight_lost_a and weight_lost_b contain the amount of weight (in pounds) that the participants in each group lost. Let's now explore the data to become more familiar with it.
Instructions
-
Use the NumPy function
mean()to calculate:- The mean of the weight lost by participants in group A. Assign to
mean_group_aand display it using theprint()function. - The mean of the weight lost by participants in group B. Assign to
mean_group_band display it using theprint()function.
- The mean of the weight lost by participants in group A. Assign to
-
Use the Matplotlib function
hist()to plot histograms for bothweight_lost_aandweight_lost_b
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
mean_group_a=np.mean(weight_lost_a)
print(mean_group_a)
mean_group_b=np.mean(weight_lost_b)
print(mean_group_b)
plt.hist(weight_lost_a)
plt.show()
plt.hist(weight_lost_b)


4: Test Statistic
To decide which hypothesis more accurately describes the data, we need to frame the hypotheses more quantitatively. The first step is to decide on a test statistic, which is a numerical value that summarizes the data and we can use in statistical formulas. We use this test statistic to run a statistical test that will determine how likely the difference between the groups were due to random chance.
Since we want to know if the amount of weight lost between the groups is meaningfully different, we will use the difference in the means, also known as the mean difference, of the amount of weight lost for each group as the test statistic.
The following symbol is used to represent the sample mean in statistics:
x¯![]()
We'll use:
x¯a![]()
to denote the mean of group A and
x¯bx¯b![]()
to denote the mean of group B. For the mean difference, we'll subtract the mean of group B from group A:
x¯b−x¯ax¯b−x¯a![]()
Now that we have decided on a test statistic, we can rewrite our hypotheses to be more precise:
Null hypothesis: x¯b−x¯a=0x¯b−x¯a=0![]()
Alternative hypothesis: x¯b−x¯a>0x¯b−x¯a>0![]()
Note that while we've stated our hypotheses as equations, we're not simply calculating the difference and matching the result to hypothesis. We're instead using a statistical test to determine which of these statements better describes the data.
Instructions
- Calculate the observed test statistic by subtracting
mean_group_afrommean_group_band assign tomean_difference. - Display
mean_differenceusing theprint()function
mean_difference=mean_group_b-mean_group_a
print(mean_difference)
置换检验
5: Permutation Test
Now that we have a test statistic, we need to decide on a statistical test. The purpose of a statistical test is to work out the likelihood(可能性) that the result we achieved was due to random chance(随机概率,随机因素).
The permutation test is a statistical test that involves simulating rerunning(随机运行) the study many times and recalculating(重新计算) the test statistic for each iteration. The goal is to calculate a distribution of the test statistics over these many iterations. This distribution is called thesampling distribution and it approximates the full range of(全范围) possible test statistics (测试统计)under the null hypothesis. We can then benchmark(参照) the test statistic we observed in the data (a mean difference of 2.52) to determine how likely it is to observe this mean difference under the null hypothesis. If the null hypothesis is true, that the weight loss pill doesn't help people lose more weight, than the observed mean difference of 2.52 should be quite common in the sampling distribution. If it's instead extremely rare(极少), then we accept the alternative hypothesis instead.
To simulate rerunning(模拟运行) the study, we randomly reassign(随机再分配) each data point (weight lost) to either group A or group B. We keep track of the recalculated test statistics as a separate list. By re-randomizing the groups(再随机分组) that the weight loss values belong to, we're simulating what randomly generated groupings of these weight loss values would look like. We then use these randomly generated groupings to understand how rare the groupings in our actual data were.
Ideally, the number of times we re-randomize the groups that each data point belongs to matches the total number of possible permutations(排列). Usually, the number of total permutations is too high for even powerful supercomputers to calculate within a reasonable time frame(合理的时间框架). While we'll use 1000 iterations for now since we'll get the results back quickly, in later missions we'll learn how to quantify the tradeoff(交易) we make between accuracy(精确性) and speed to determine the optimal(最佳的) number of iterations.
Since we'll be randomizing the groups each value belongs to, we created a list named all_values that contains just the weight loss values.
Instructions
- Create an empty list named
mean_differences. - Inside a
forloop that repeats1000times:- Assign empty lists to the variables
group_aandgroup_b. - Inside a
forloop that iterates overall_values:- Use the
numpy.random.rand()function to generate a value between0and1. - If the random value is larger than or equal to
0.5, assign that weight loss value to group A by using theappend()method to append it togroup_a. - If the random value is less than
0.5, assign that weight loss value to group B by using theappend()method to append it togroup_b.
- Use the
- Outside the
forloop that iterates overall_values:- Use the
numpy.mean()function to calculate the means ofgroup_aandgroup_b. - Subtract the mean of group A from group B and assign the result to
iteration_mean_difference. - Append
iteration_mean_differencetomean_differencesusing theappend()method.
- Use the
- Assign empty lists to the variables
- Use
plt.hist()to generate a histogram ofmean_differences.
mean_difference = 2.52
print(all_values)
mean_differences = []
for i in range(1000):
group_a = []
group_b = []
for value in all_values:
assignment_chance = np.random.rand()
if assignment_chance >= 0.5:
group_a.append(value)
else:
group_b.append(value)
iteration_mean_difference = np.mean(group_b) - np.mean(group_a)
mean_differences.append(iteration_mean_difference)
plt.hist(mean_differences)
plt.show()
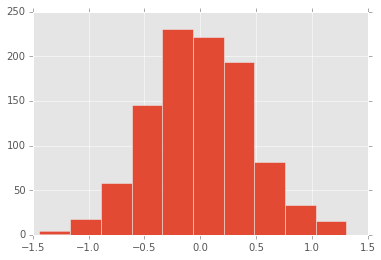
6: Sampling Distribution
By randomly assigning participants to group A or group B, we account for the effect of random chance. Someone in group B who just happened to lose more weight (but not because of the pills) makes the results look better than they were. By creating many permutations, we're able to see all possible configurations of this error. Creating a histogram enables us to see how likely different values of our test statistic are if we repeated our experiment many times.
The histogram we generated in the previous step using Matplotlib is a visual representation of the sampling distribution. Let's now create adictionary that contains the values in the sampling distribution so we can benchmark our observed test statistic against it.
The keys in the dictionary should be the test statistic and the values should be their frequency:
{
0.34943639291465356: 3,
-0.55702280912364888: 2,
-0.14942528735632177: 1
....
}
We need to first count up how frequently each value in the list, mean_differences, occurs. As we loop over mean_differences, we need a way to check if the test statistic is already in our dictionary:
- If it is, we look up the value at that key, add
1to it, and assign the new value to the key. - If it isn't, we add the key to the dictinoary and assign the value
1to it.
We'll dive more into how to accomplish this in the next step.
7: Dictionary Representation Of A Distribution
To check if a key exists in a dictionary, we need to use the get() method to:
- return the value at the specified key if it exists in the dictionary or
- return another value we specify instead.
Here are the parameters the method takes in:
- the required parameter is the key we want to look up,
- the optional parameter is the default value we want returned if the key is not found.
In the following code block, we use the get method and set the default value to False:
empty = {}
# Since "a" isn't a key in empty, the value False is returned.
key_a = empty.get("a", False):
empty["b"] = "boat"
# key_b is the value for the key "b" in empty.
key_b = empty.get("b", False):
# "boat" is assigned to key_b.
We can use the value returned from the get() method in an if statement to express our logic:
empty = {"c": 1}
if empty.get("c", False):
# If in the dictionary, grab the value, increment by 1, reassign.
val = empty.get("c")
inc = val + 1
empty["c"] = inc
else:
# If not in the dictionary, assign `1` as the value to that key.
empty["c"] = 1
Instructions
- Create an empty dictionary called
sampling_distributionwhose keys will be the test statistics and whose values are the frequencies of the test statistics.- Inside a
forloop that iterates overmean_differences, check if each value exists as a key insampling_distribution:- Use the dictionary method
get()with a default condition ofFalseto check if the current iteration's value is already insampling_distribution.- If it is, increment the existing value in
sampling_distributionfor that key by1. - If it isn't, add it to
sampling_distributionas a key and assign1as the value.
- If it is, increment the existing value in
- Use the dictionary method
- Inside a
sampling_distribution={}
for i in mean_differences:
if sampling_distribution.get(i,False):
sampling_distribution[i]=sampling_distribution[i]+1
else:
sampling_distribution[i]=1
8: P Value
In the sampling distribution we generated, most of the values are closely centered around the mean difference of 0. This means that if it were purely up to chance, both groups would have lost the same amount of weight (the null hypothesis). But since the observed test statistic is not near 0, it could mean that the weight loss pills could be responsible for the mean difference in the study.
We can now use the sampling distribution to determine the number of times a value of 2.52 or higher appeared in our simulations. If we then divide that frequency by 1000, we'll have the probability of observing a mean difference of 2.52 or higher purely due to random chance.
This probability is called the p value. If this value is high, it means that the difference in the amount of weight both groups lost could haveeasily happened randomly and the weight loss pills probably didn't play a role. On the other hand, a low p value implies that there's an incredibly small probability that the mean difference we observed was because of random chance.
In general, it's good practice to set the p value threshold before conducting the study:
-
if the p value is less than the threshold, we:
- reject the null hypothesis that there's no difference in mean amount of weight lost by participants in both groups,
- accept the alternative hypothesis that the people who consumed the weight loss pill lost more weight,
- conclude that the weight loss pill does affect the amount of weight people lost.
-
if the p value is greater than the threshold, we:
- accept the null hypothesis that there's no difference in the mean amount of weight lost by participants in both groups,
- reject the alternative hypothesis that the people who consumed the weight loss pill lost more weight,
- conclude that the weight loss pill doesn't seem to be effective in helping people lose more weight.
The most common p value threshold is 0.05 or 5%, which is what we'll use in this mission. Although .05 is an arbitrary threshold, it means that there's only a 5% chance that the results are due to random chance, which most researchers are comfortable with.
Instructions
- Create an empty list named
frequencies. - Inside a
forloop that iterates over the keys insampling_distribution:- If the key is
2.52or larger, add itss value tofrequencies(and do nothing if it isn't).
- If the key is
- Outside the
forloop, use theNumPy functionsum()to calculate the sum of the values infrequencies. - Divide the sum by
1000and assign top_value.
import numpy
frequencies=[]
for i in sampling_distribution:
if i >2.52:
frequencies.append(i)
p_value=(numpy.sum(frequencies))/1000
9: Caveats(警告)
Since the p value of 0 is less than the threshold we set of 0.05, we conclude that the difference in weight lost can't be attributed to random chance alone. We therefore reject the null hypothesis and accept the alternative hypothesis. A few caveats:
- Research design is incredibly important and can bias your results. For example, if the participants in group A realized they were given placebo sugar pills, they may modify their behavior and affect the outcome.
- The p value threshold you set can also affect the conclusion you reach.
- If you set too high of a p value threshold, you may accept the alternative hypothesis incorrectly and reject the null hypothesis. This is known as a type I error.
- If you set too low of a p value threshold, you may reject the alternative hypothesis incorrectly in favor of accepting the null hypothesis. This is known as a type II error.
10: Next Steps
In this mission, we explored hypothesis testing and the basics of statistical significance using a study that closely represents real world studies. In the next mission, we'll learn about the chi squared distribution and the chi squared test.