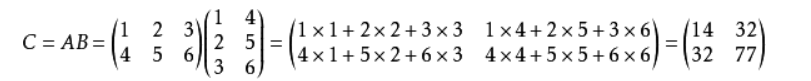CUDA编程(三) —— 编程实践
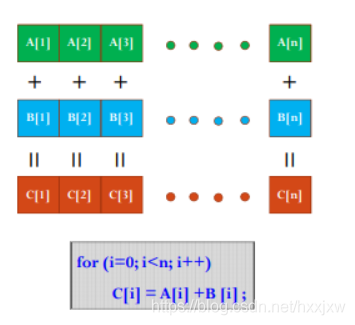
1. 将两个元素数目为1024×1024的float数组相加
首先我们思考一下如果只用CPU我们怎么串行完成这个任务
#include <iostream> #include <stdlib.h> #include <sys/time.h> #include <math.h> using namespace std; int main() { struct timeval start, end; gettimeofday( &start, NULL ); float*A, *B, *C; int n = 1024 * 1024; int size = n * sizeof(float); A = (float*)malloc(size); B = (float*)malloc(size); C = (float*)malloc(size); for(int i=0;i<n;i++) { A[i] = 90.0; B[i] = 10.0; } for(int i=0;i<n;i++) { C[i] = A[i] + B[i]; } float max_error = 0.0; for(int i=0;i<n;i++) { max_error += fabs(100.0-C[i]); } cout << "max_error is " << max_error << endl; gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; cout << "total time is " << timeuse/1000 << "ms" <<endl; return 0; }输出结果
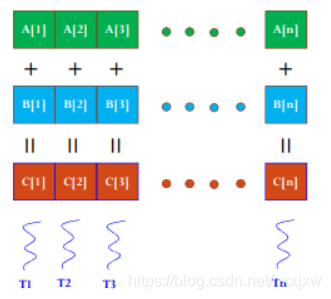
如果我们使用GPU来做并行计算
编程要点:
- 每个Block中的Thread数最大不超过512;
- 为了充分利用SM,Block数尽可能多,>100
#include "cuda_runtime.h" #include <stdlib.h> #include <iostream> #include <sys/time.h> using namespace std; __global__ void Plus(float A[], float B[], float C[], int n) { int i = blockDim.x * blockIdx.x + threadIdx.x; C[i] = A[i] + B[i]; } int main() { struct timeval start, end; gettimeofday( &start, NULL ); float*A, *Ad, *B, *Bd, *C, *Cd; int n = 1024 * 1024; int size = n * sizeof(float); // CPU端分配内存 A = (float*)malloc(size); B = (float*)malloc(size); C = (float*)malloc(size); // 初始化数组 for(int i=0;i<n;i++) { A[i] = 90.0; B[i] = 10.0; } // GPU端分配内存 cudaMalloc((void**)&Ad, size); cudaMalloc((void**)&Bd, size); cudaMalloc((void**)&Cd, size); // CPU的数据拷贝到GPU端 cudaMemcpy(Ad, A, size, cudaMemcpyHostToDevice); cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice); cudaMemcpy(Bd, B, size, cudaMemcpyHostToDevice); // 定义kernel执行配置,(1024*1024/512)个block,每个block里面有512个线程 dim3 dimBlock(512); dim3 dimGrid(n/512); // 执行kernel Plus<<<dimGrid, dimBlock>>>(Ad, Bd, Cd, n); // 将在GPU端计算好的结果拷贝回CPU端 cudaMemcpy(C, Cd, size, cudaMemcpyDeviceToHost); // 校验误差 float max_error = 0.0; for(int i=0;i<n;i++) { max_error += fabs(100.0 - C[i]); } cout << "max error is " << max_error << endl; // 释放CPU端、GPU端的内存 free(A); free(B); free(C); cudaFree(Ad); cudaFree(Bd); cudaFree(Cd); gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; cout << "total time is " << timeuse/1000 << "ms" <<endl; return 0; }输出结果
由上面的例子看出,使用CUDA编程时我们看不到for循环了,因为CPU编程的循环已经被分散到各个thread上做了,所以我们也就看到不到for一类的语句。从结果上看,CPU的循环计算的速度比GPU计算快多了,原因就在于CUDA中有大量的内存拷贝操作(数据传输花费了大量时间,而计算时间却非常少),如果计算量比较小的话,CPU计算会更合适一些。
2. 矩阵加法
CPU方式
#include <stdlib.h> #include <iostream> #include <sys/time.h> #include <math.h> #define ROWS 1024 #define COLS 1024 using namespace std; int main() { struct timeval start, end; gettimeofday( &start, NULL ); int *A, **A_ptr, *B, **B_ptr, *C, **C_ptr; int total_size = ROWS*COLS*sizeof(int); A = (int*)malloc(total_size); B = (int*)malloc(total_size); C = (int*)malloc(total_size); A_ptr = (int**)malloc(ROWS*sizeof(int*)); B_ptr = (int**)malloc(ROWS*sizeof(int*)); C_ptr = (int**)malloc(ROWS*sizeof(int*)); //CPU一维数组初始化 for(int i=0;i<ROWS*COLS;i++) { A[i] = 80; B[i] = 20; } for(int i=0;i<ROWS;i++) { A_ptr[i] = A + COLS*i; B_ptr[i] = B + COLS*i; C_ptr[i] = C + COLS*i; } for(int i=0;i<ROWS;i++) for(int j=0;j<COLS;j++) { C_ptr[i][j] = A_ptr[i][j] + B_ptr[i][j]; } //检查结果 int max_error = 0; for(int i=0;i<ROWS*COLS;i++) { //cout << C[i] << endl; max_error += abs(100-C[i]); } cout << "max_error is " << max_error <<endl; gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; cout << "total time is " << timeuse/1000 << "ms" <<endl; return 0; }
GPU写法
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <sys/time.h> #include <stdio.h> #include <math.h> #define Row 1024 #define Col 1024 __global__ void addKernel(int **C, int **A, int ** B) { int idx = threadIdx.x + blockDim.x * blockIdx.x; int idy = threadIdx.y + blockDim.y * blockIdx.y; if (idx < Col && idy < Row) { C[idy][idx] = A[idy][idx] + B[idy][idx]; } } int main() { struct timeval start, end; gettimeofday( &start, NULL ); int **A = (int **)malloc(sizeof(int*) * Row); int **B = (int **)malloc(sizeof(int*) * Row); int **C = (int **)malloc(sizeof(int*) * Row); int *dataA = (int *)malloc(sizeof(int) * Row * Col); int *dataB = (int *)malloc(sizeof(int) * Row * Col); int *dataC = (int *)malloc(sizeof(int) * Row * Col); int **d_A; int **d_B; int **d_C; int *d_dataA; int *d_dataB; int *d_dataC; //malloc device memory cudaMalloc((void**)&d_A, sizeof(int **) * Row); cudaMalloc((void**)&d_B, sizeof(int **) * Row); cudaMalloc((void**)&d_C, sizeof(int **) * Row); cudaMalloc((void**)&d_dataA, sizeof(int) *Row*Col); cudaMalloc((void**)&d_dataB, sizeof(int) *Row*Col); cudaMalloc((void**)&d_dataC, sizeof(int) *Row*Col); //set value for (int i = 0; i < Row*Col; i++) { dataA[i] = 90; dataB[i] = 10; } //将主机指针A指向设备数据位置,目的是让设备二级指针能够指向设备数据一级指针 //A 和 dataA 都传到了设备上,但是二者还没有建立对应关系 for (int i = 0; i < Row; i++) { A[i] = d_dataA + Col * i; B[i] = d_dataB + Col * i; C[i] = d_dataC + Col * i; } cudaMemcpy(d_A, A, sizeof(int*) * Row, cudaMemcpyHostToDevice); cudaMemcpy(d_B, B, sizeof(int*) * Row, cudaMemcpyHostToDevice); cudaMemcpy(d_C, C, sizeof(int*) * Row, cudaMemcpyHostToDevice); cudaMemcpy(d_dataA, dataA, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); cudaMemcpy(d_dataB, dataB, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); dim3 threadPerBlock(16, 16); dim3 blockNumber( (Col + threadPerBlock.x - 1)/ threadPerBlock.x, (Row + threadPerBlock.y - 1) / threadPerBlock.y ); printf("Block(%d,%d) Grid(%d,%d).\n", threadPerBlock.x, threadPerBlock.y, blockNumber.x, blockNumber.y); addKernel << <blockNumber, threadPerBlock >> > (d_C, d_A, d_B); //拷贝计算数据-一级数据指针 cudaMemcpy(dataC, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost); int max_error = 0; for(int i=0;i<Row*Col;i++) { //printf("%d\n", dataC[i]); max_error += abs(100-dataC[i]); } //释放内存 free(A); free(B); free(C); free(dataA); free(dataB); free(dataC); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); cudaFree(d_dataA); cudaFree(d_dataB); cudaFree(d_dataC); printf("max_error is %d\n", max_error); gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; printf("total time is %d ms\n", timeuse/1000); return 0; }输出
从结果看出,CPU计算时间还是比GPU的计算时间短。这里需要指出的是,这种二维数组的程序写法的效率并不高(虽然比较符合我们的思维方式),因为我们做了两次访存操作。所以一般而言,做高性能计算一般不会采取这种编程方式。
3. 矩阵乘法
两矩阵相乘,左矩阵第一行乘以右矩阵第一列(分别相乘,第一个数乘第一个数),乘完之后相加,即为结果的第一行第一列的数,依次往下算,直到计算完所有矩阵元素。
CPU写法
#include <iostream> #include <stdlib.h> #include <sys/time.h> #define ROWS 1024 #define COLS 1024 using namespace std; void matrix_mul_cpu(float* M, float* N, float* P, int width) { for(int i=0;i<width;i++) for(int j=0;j<width;j++) { float sum = 0.0; for(int k=0;k<width;k++) { float a = M[i*width+k]; float b = N[k*width+j]; sum += a*b; } P[i*width+j] = sum; } } int main() { struct timeval start, end; gettimeofday( &start, NULL ); float *A, *B, *C; int total_size = ROWS*COLS*sizeof(float); A = (float*)malloc(total_size); B = (float*)malloc(total_size); C = (float*)malloc(total_size); //CPU一维数组初始化 for(int i=0;i<ROWS*COLS;i++) { A[i] = 80.0; B[i] = 20.0; } matrix_mul_cpu(A, B, C, COLS); gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; cout << "total time is " << timeuse/1000 << "ms" <<endl; return 0; }输出
GPU写法
梳理一下CUDA求解矩阵乘法的思路:因为C=A×B,我们利用每个线程求解C矩阵每个(x, y)的元素,每个线程载入A的一行和B的一列,遍历各自行列元素,对A、B对应的元素做一次乘法和一次加法
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <sys/time.h> #include <stdio.h> #include <math.h> #define Row 1024 #define Col 1024 __global__ void matrix_mul_gpu(int *M, int* N, int* P, int width) { int i = threadIdx.x + blockDim.x * blockIdx.x; int j = threadIdx.y + blockDim.y * blockIdx.y; int sum = 0; for(int k=0;k<width;k++) { int a = M[j*width+k]; int b = N[k*width+i]; sum += a*b; } P[j*width+i] = sum; } int main() { struct timeval start, end; gettimeofday( &start, NULL ); int *A = (int *)malloc(sizeof(int) * Row * Col); int *B = (int *)malloc(sizeof(int) * Row * Col); int *C = (int *)malloc(sizeof(int) * Row * Col); //malloc device memory int *d_dataA, *d_dataB, *d_dataC; cudaMalloc((void**)&d_dataA, sizeof(int) *Row*Col); cudaMalloc((void**)&d_dataB, sizeof(int) *Row*Col); cudaMalloc((void**)&d_dataC, sizeof(int) *Row*Col); //set value for (int i = 0; i < Row*Col; i++) { A[i] = 90; B[i] = 10; } cudaMemcpy(d_dataA, A, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); cudaMemcpy(d_dataB, B, sizeof(int) * Row * Col, cudaMemcpyHostToDevice); dim3 threadPerBlock(16, 16); dim3 blockNumber((Col+threadPerBlock.x-1)/ threadPerBlock.x, (Row+threadPerBlock.y-1)/ threadPerBlock.y ); printf("Block(%d,%d) Grid(%d,%d).\n", threadPerBlock.x, threadPerBlock.y, blockNumber.x, blockNumber.y); matrix_mul_gpu << <blockNumber, threadPerBlock >> > (d_dataA, d_dataB, d_dataC, Col); //拷贝计算数据-一级数据指针 cudaMemcpy(C, d_dataC, sizeof(int) * Row * Col, cudaMemcpyDeviceToHost); //释放内存 free(A); free(B); free(C); cudaFree(d_dataA); cudaFree(d_dataB); cudaFree(d_dataC); gettimeofday( &end, NULL ); int timeuse = 1000000 * ( end.tv_sec - start.tv_sec ) + end.tv_usec - start.tv_usec; printf("total time is %d ms\n", timeuse/1000); return 0; }输出
从这个矩阵乘法任务可以看出,我们通过GPU进行并行计算的方式仅花费了0.5秒,但是CPU串行计算方式却花费了7.6秒,计算速度提升了十多倍,可见并行计算的威力!