Hadoop迁移MaxCompute神器之DataX-On-Hadoop使用指南
DataX-On-Hadoop即使用hadoop的任务调度器,将DataX task(Reader->Channel->Writer)调度到hadoop执行集群上执行。这样用户的hadoop数据可以通过MR任务批量上传到MaxCompute、RDS等,不需要用户提前安装和部署DataX软件包,也不需要另外为DataX准备执行集群。但是可以享受到DataX已有的插件逻辑、流控限速、鲁棒重试等等。
1. DataX-On-Hadoop 运行方式
1.1 什么是DataX-On-Hadoop
DataX https://github.com/alibaba/DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、MaxCompute 等各种异构数据源之间高效的数据同步功能。 DataX同步引擎内部实现了任务的切分、调度执行能力,DataX的执行不依赖Hadoop环境。
DataX-On-Hadoop是DataX针对Hadoop调度环境实现的版本,使用hadoop的任务调度器,将DataX task(Reader->Channel->Writer)调度到hadoop执行集群上执行。这样用户的hadoop数据可以通过MR任务批量上传到MaxCompute等,不需要用户提前安装和部署DataX软件包,也不需要另外为DataX准备执行集群。但是可以享受到DataX已有的插件逻辑、流控限速、鲁棒重试等等。
目前DataX-On-Hadoop支持将Hdfs中的数据上传到公共云MaxCompute当中。
1.2 如何运行DataX-On-Hadoop
运行DataX-On-Hadoop步骤如下:
- 提阿里云工单申请DataX-On-Hadoop软件包,此软件包本质上也是一个Hadoop MR Jar;
- 通过hadoop客户端提交一个MR任务,您只需要关系作业的配置文件内容(这里是./bvt_case/speed.json,配置文件和普通的DataX配置文件完全一致),提交命令是:
./bin/hadoop jar datax-jar-with-dependencies.jar com.alibaba.datax.hdfs.odps.mr.HdfsToOdpsMRJob ./bvt_case/speed.json
- 任务执行完成后,可以看到类似如下日志:
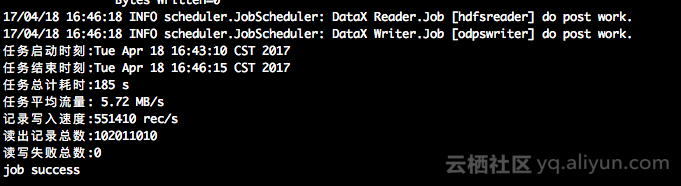
本例子的Hdfs Reader 和Odps Writer配置信息如下:
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": "-1",
"record": "-1"
}
}
}
},
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/tmp/test_datax/big_data*",
"defaultFS": "hdfs://localhost:9000",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "odpswriter",
"parameter": {
"project": "",
"table": "",
"partition": "pt=1,dt=2",
"column": [
"id",
"name"
],
"accessId": "",
"accessKey": "",
"truncate": true,
"odpsServer": "http://service.odps.aliyun.com/api",
"tunnelServer": "http://dt.odps.aliyun.com",
"accountType": "aliyun"
}
}
}
]
}
}1.3 DataX-On-Hadoop 任务高级配置参数
针对上面的例子,介绍几个性能、脏数据的参数:
- core.transport.channel.speed.byte 同步任务切分多多个mapper并发执行,每个mapper的同步速度比特Byte上限,默认为-1,负数表示不限速;如果是1048576表示单个mapper最大速度是1MB/s。
- core.transport.channel.speed.record 同步任务切分多多个mapper并发执行,每个mapper的同步速度记录上限,默认为-1,负数表示不限速;如果是10000表示单个mapper最大记录速度每秒1万行。
- job.setting.speed.byte 同步任务整体的最大速度,依赖hadoop 2.7.0以后的版本,主要是通过mapreduce.job.running.map.limit参数控制同一时间点mapper的并行度。
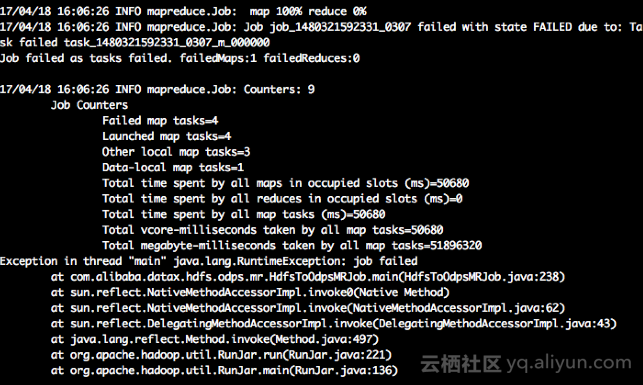
- job.setting.errorLimit.record 脏数据记录现在,默认不配置表示不进行脏数据检查(有脏数据任务不会失败);0表示允许脏数据条数最大为0条,如果任务执行时脏数据超过限制,任务会失败;1表示允许脏数据条数最大为1条,含义不言自明。一个由于脏数据原因失败的任务:
作业级别的性能参数配置位置示例:
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": "-1",
"record": "-1"
}
}
}
},
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {},
"writer": {}
}
]
}
}另外,介绍几个变量替换、作业命名参数:
- 支持变量参数,比如作业配置文件json中有如下:
-
"path": "/tmp/test_datax/dt=${dt}/abc.txt"
任务执行时可以配置如下传参,使得一份配置代码可以多次使用:
./bin/hadoop jar datax-jar-with-dependencies.jar com.alibaba.datax.hdfs.odps.mr.HdfsToOdpsMRJob
datax.json -p "-Ddt=20170427 -Dbizdate=123" -t hdfs_2_odps_mr- 支持给作业命名,任务执行时的-t参数是作业的traceId,即作业的名字方便根据作业名字即知晓其意图,比如上面的
-t hdfs_2_odps_mr
读写插件详细配置介绍,请见后续第2、3部分。
2. Hdfs 读取
2.1 快速介绍
Hdfs Reader提供了读取分布式文件系统数据存储的能力。在底层实现上,Hdfs Reader获取分布式文件系统上文件的数据,并转换为DataX传输协议传递给Writer。
Hdfs Reader实现了从Hadoop分布式文件系统Hdfs中读取文件数据并转为DataX协议的功能。textfile是Hive建表时默认使用的存储格式,数据不做压缩,本质上textfile就是以文本的形式将数据存放在hdfs中,对于DataX而言,Hdfs Reader实现上类比TxtFileReader,有诸多相似之处。orcfile,它的全名是Optimized Row Columnar file,是对RCFile做了优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。Hdfs Reader利用Hive提供的OrcSerde类,读取解析orcfile文件的数据。目前Hdfs Reader支持的功能如下:
-
支持textfile、orcfile、rcfile、sequence file、csv和parquet格式的文件,且要求文件内容存放的是一张逻辑意义上的二维表。
-
支持多种类型数据读取(使用String表示),支持列裁剪,支持列常量。
-
支持递归读取、支持正则表达式("*"和"?")。
-
支持orcfile数据压缩,目前支持SNAPPY,ZLIB两种压缩方式。
-
支持sequence file数据压缩,目前支持lzo压缩方式。
-
多个File可以支持并发读取。
-
csv类型支持压缩格式有:gzip、bz2、zip、lzo、lzo_deflate、snappy。
我们暂时不能做到:
- 单个File支持多线程并发读取,这里涉及到单个File内部切分算法。后续可以做到支持。
2.2 功能说明
2.2.1 配置样例
{
"core": {
"transport": {
"channel": {
"speed": {
"byte": "-1048576",
"record": "-1"
}
}
}
},
"job": {
"setting": {
"speed": {
"byte": 1048576
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/tmp/test_datax/*",
"defaultFS": "hdfs://localhost:9000",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {}
}
]
}
}2.2.2 参数说明
-
path
-
描述:要读取的文件路径,如果要读取多个文件,可以使用正则表达式"*",注意这里可以支持填写多个路径。
当指定通配符,HdfsReader尝试遍历出多个文件信息。例如: 指定/*代表读取/目录下所有的文件,指定/yixiao/*代表读取yixiao目录下所有的文件。HdfsReader目前只支持"*"和"?"作为文件通配符。
特别需要注意的是,DataX会将一个作业下同步的所有的文件视作同一张数据表。用户必须自己保证所有的File能够适配同一套schema信息。并且提供给DataX权限可读。
-
必选:是
-
默认值:无
-
-
defaultFS
- 描述:Hadoop hdfs文件系统namenode节点地址。
- 必选:是
- 默认值:无
-
fileType
-
描述:文件的类型,目前只支持用户配置为"text"、"orc"、"rc"、"seq"、"csv"。
text表示textfile文件格式
orc表示orcfile文件格式
rc表示rcfile文件格式
seq表示sequence file文件格式
csv表示普通hdfs文件格式(逻辑二维表)
特别需要注意的是,HdfsReader能够自动识别文件是orcfile、rcfile、sequence file还是textfile或csv类型的文件,该项是必填项,HdfsReader在做数据同步之前,会检查用户配置的路径下所有需要同步的文件格式是否和fileType一致,如果不一致则会抛出异常
另外需要注意的是,由于textfile和orcfile是两种完全不同的文件格式,所以HdfsReader对这两种文件的解析方式也存在差异,这种差异导致hive支持的复杂复合类型(比如map,array,struct,union)在转换为DataX支持的String类型时,转换的结果格式略有差异,比如以map类型为例:
orcfile map类型经hdfsreader解析转换成datax支持的string类型后,结果为"{job=80, team=60, person=70}"
textfile map类型经hdfsreader解析转换成datax支持的string类型后,结果为"job:80,team:60,person:70"
从上面的转换结果可以看出,数据本身没有变化,但是表示的格式略有差异,所以如果用户配置的文件路径中要同步的字段在Hive中是复合类型的话,建议配置统一的文件格式。
如果需要统一复合类型解析出来的格式,我们建议用户在hive客户端将textfile格式的表导成orcfile格式的表
-
-
column
-
描述:读取字段列表,type指定源数据的类型,index指定当前列来自于文本第几列(以0开始),value指定当前类型为常量,不从源头文件读取数据,而是根据value值自动生成对应的列。
默认情况下,用户可以全部按照string类型读取数据,配置如下:
用户可以指定column字段信息,配置如下:
对于用户指定column信息,type必须填写,index/value必须选择其一。
-
"column": ["*"]
-
{ "type": "long", "index": 0 //从本地文件文本第一列获取int字段 }, { "type": "string", "value": "alibaba" //HdfsReader内部生成alibaba的字符串字段作为当前字段 }
-
必选:是
-
默认值:全部按照string类型读取
-
-
fieldDelimiter
- 描述:读取的字段分隔符
另外需要注意的是,HdfsReader在读取textfile数据时,需要指定字段分割符,如果不指定默认为',',HdfsReader在读取orcfile时,用户无需指定字段分割符,hive本身的默认分隔符为 "\u0001";若你想将每一行作为目的端的一列,分隔符请使用行内容不存在的字符,比如不可见字符"\u0001" ,分隔符不能使用\n
- 必选:否
- 默认值:,
-
encoding
- 描述:读取文件的编码配置。
- 必选:否
- 默认值:utf-8
-
nullFormat
-
描述:文本文件中无法使用标准字符串定义null(空指针),DataX提供nullFormat定义哪些字符串可以表示为null。
例如如果用户配置: nullFormat:"\N",那么如果源头数据是"\N",DataX视作null字段。
-
必选:否
-
默认值:无
-
-
compress
- 描述:当fileType(文件类型)为csv下的文件压缩方式,目前仅支持 gzip、bz2、zip、lzo、lzo_deflate、hadoop-snappy、framing-snappy压缩;值得注意的是,lzo存在两种压缩格式:lzo和lzo_deflate,用户在配置的时候需要留心,不要配错了;另外,由于snappy目前没有统一的stream format,datax目前只支持最主流的两种:hadoop-snappy(hadoop上的snappy stream format)和framing-snappy(google建议的snappy stream format);orc文件类型下无需填写。
- 必选:否
- 默认值:无
-
csvReaderConfig
- 描述:读取CSV类型文件参数配置,Map类型。读取CSV类型文件使用的CsvReader进行读取,会有很多配置,不配置则使用默认值。
- 必选:否
-
默认值:无
常见配置:
"csvReaderConfig":{ "safetySwitch": false, "skipEmptyRecords": false, "useTextQualifier": false }
所有配置项及默认值,配置时 csvReaderConfig 的map中请严格按照以下字段名字进行配置:
-
hadoopConfig
-
描述:hadoopConfig里可以配置与Hadoop相关的一些高级参数,比如HA的配置。
"hadoopConfig":{ "dfs.nameservices": "testDfs", "dfs.ha.namenodes.testDfs": "namenode1,namenode2", "dfs.namenode.rpc-address.youkuDfs.namenode1": "", "dfs.namenode.rpc-address.youkuDfs.namenode2": "", "dfs.client.failover.proxy.provider.testDfs": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider" }
-
必选:否
-
默认值:无
-
-
minInputSplitSize
- 描述:Hadoop hdfs部分文件类型支持文件内部切分,这样一个文件可以被切分到多个mapper里面并发执行,每个mapper读取这个文件的一部分。这边测试环境验证确实可以做到速度的 线性 扩展。注意:由于切分的粒度更细了,启动mapper数量多可能占用的机器资源也多一些。目前支持文件内部切分的文件类型有: rc、text、csv、parquet
- 必选:否
- 默认值:无限大
2.3 类型转换
2.3.1 RCFile
如果用户同步的hdfs文件是rcfile,由于rcfile底层存储的时候不同的数据类型存储方式不一样,而HdfsReader不支持对Hive元数据数据库进行访问查询,因此需要用户在column type里指定该column在hive表中的数据类型,比如该column是bigint型。那么type就写为bigint,如果是double型,则填写double,如果是float型,则填写float。注意:如果是varchar或者char类型,则需要填写字节数,比如varchar(255),char(30)等,跟hive表中该字段的类型保持一致,或者也可以填写string类型。
如果column配置的是*,会读取所有column,那么datax会默认以string类型读取所有column,此时要求column中的类型只能为String,CHAR,VARCHAR中的一种。
RCFile中的类型默认会转成DataX支持的内部类型,对照表如下:
| RCFile在Hive表中的数据类型 | DataX 内部类型 |
|---|---|
| TINYINT,SMALLINT,INT,BIGINT | Long |
| FLOAT,DOUBLE,DECIMAL | Double |
| String,CHAR,VARCHAR | String |
| BOOLEAN | Boolean |
| Date,TIMESTAMP | Date |
| Binary | Binary |
2.3.2 ParquetFile
如果column配置的是*, 会读取所有列; 此时Datax会默认以String类型读取所有列. 如果列中出现Double等类型的话, 全部将转换为String类型。如果column配置读取特定的列的话, DataX中的类型和Parquet文件类型的对应关系如下:
| Parquet格式文件的数据类型 | DataX 内部类型 |
|---|---|
| int32, int64, int96 | Long |
| float, double | Double |
| binary | Binary |
| boolean | Boolean |
| fixed_len_byte_array | String |
textfile,orcfile,sequencefile:
由于textfile和orcfile文件表的元数据信息由Hive维护并存放在Hive自己维护的数据库(如mysql)中,目前HdfsReader不支持对Hive元数据数据库进行访问查询,因此用户在进行类型转换的时候,必须指定数据类型,如果用户配置的column为"*",则所有column默认转换为string类型。HdfsReader提供了类型转换的建议表如下:
| DataX 内部类型 | Hive表 数据类型 |
|---|---|
| Long | TINYINT,SMALLINT,INT,BIGINT |
| Double | FLOAT,DOUBLE |
| String | String,CHAR,VARCHAR,STRUCT,MAP,ARRAY,UNION,BINARY |
| Boolean | BOOLEAN |
| Date | Date,TIMESTAMP |
其中:
- Long是指Hdfs文件文本中使用整形的字符串表示形式,例如"123456789"。
- Double是指Hdfs文件文本中使用Double的字符串表示形式,例如"3.1415"。
- Boolean是指Hdfs文件文本中使用Boolean的字符串表示形式,例如"true"、"false"。不区分大小写。
- Date是指Hdfs文件文本中使用Date的字符串表示形式,例如"2014-12-31"。
特别提醒:
- Hive支持的数据类型TIMESTAMP可以精确到纳秒级别,所以textfile、orcfile中TIMESTAMP存放的数据类似于"2015-08-21 22:40:47.397898389",如果转换的类型配置为DataX的Date,转换之后会导致纳秒部分丢失,所以如果需要保留纳秒部分的数据,请配置转换类型为DataX的String类型。
2.4 按分区读取
Hive在建表的时候,可以指定分区partition,例如创建分区partition(day="20150820",hour="09"),对应的hdfs文件系统中,相应的表的目录下则会多出/20150820和/09两个目录,且/20150820是/09的父目录。了解了分区都会列成相应的目录结构,在按照某个分区读取某个表所有数据时,则只需配置好json中path的值即可。
比如需要读取表名叫mytable01下分区day为20150820这一天的所有数据,则配置如下:
"path": "/user/hive/warehouse/mytable01/20150820/*"3. MaxCompute写入
3.1 快速介绍
ODPSWriter插件用于实现往ODPS(即MaxCompute)插入或者更新数据,主要提供给etl开发同学将业务数据导入MaxCompute,适合于TB,GB数量级的数据传输。在底层实现上,根据你配置的 项目 / 表 / 分区 / 表字段 等信息,通过 Tunnel写入 MaxCompute 中。支持MaxCompute中以下数据类型:BIGINT、DOUBLE、STRING、DATATIME、BOOLEAN。下面列出ODPSWriter针对MaxCompute类型转换列表:
| DataX 内部类型 | MaxCompute 数据类型 |
|---|---|
| Long | bigint |
| Double | double |
| String | string |
| Date | datetime |
| Boolean | bool |
3.2 实现原理
在底层实现上,ODPSWriter是通过MaxCompute Tunnel写入MaxCompute系统的,有关MaxCompute的更多技术细节请参看 MaxCompute主站: https://www.aliyun.com/product/odps
3.3 功能说明
3.3.1 配置样例
- 这里使用一份从内存产生到MaxCompute导入的数据。
{ "core": { "transport": { "channel": { "speed": { "byte": "-1048576", "record": "-1" } } } }, "job": { "setting": { "speed": { "byte": 1048576 }, "errorLimit": { "record": 0 } }, "content": [ { "reader": {}, "writer": { "name": "odpswriter", "parameter": { "project": "", "table": "", "partition": "pt=1,dt=2", "column": [ "col1", "col2" ], "accessId": "", "accessKey": "", "truncate": true, "odpsServer": "http://service.odps.aliyun.com/api", "tunnelServer": "http://dt.odps.aliyun.com", "accountType": "aliyun" } } } ] } }
3.3.2 参数说明
-
accessId
- 描述:MaxCompute系统登录ID
- 必选:是
- 默认值:无
- 描述:MaxCompute系统登录ID
-
accessKey
- 描述:MaxCompute系统登录Key
- 必选:是
- 默认值:无
- 描述:MaxCompute系统登录Key
-
project
- 描述:MaxCompute表所属的project,注意:Project只能是字母+数字组合,请填写英文名称。在云端等用户看到的MaxCompute项目中文名只是显示名,请务必填写底层真实地Project英文标识名。
- 必选:是
- 默认值:无
- 描述:MaxCompute表所属的project,注意:Project只能是字母+数字组合,请填写英文名称。在云端等用户看到的MaxCompute项目中文名只是显示名,请务必填写底层真实地Project英文标识名。
-
table
- 描述:写入数据的表名,不能填写多张表,因为DataX不支持同时导入多张表。
- 必选:是
- 默认值:无
- 描述:写入数据的表名,不能填写多张表,因为DataX不支持同时导入多张表。
-
partition
- 描述:需要写入数据表的分区信息,必须指定到最后一级分区。把数据写入一个三级分区表,必须配置到最后一级分区,例如pt=20150101/type=1/biz=2。
- 必选:如果是分区表,该选项必填,如果非分区表,该选项不可填写。
- 默认值:空
-
column
- 描述:需要导入的字段列表,当导入全部字段时,可以配置为"column": ["*"], 当需要插入部分MaxCompute列填写部分列,例如"column": ["id", "name"]。ODPSWriter支持列筛选、列换序,例如表有a,b,c三个字段,用户只同步c,b两个字段。可以配置成["c","b"], 在导入过程中,字段a自动补空,设置为null。
- 必选:否
- 默认值:无
- 描述:需要导入的字段列表,当导入全部字段时,可以配置为"column": ["*"], 当需要插入部分MaxCompute列填写部分列,例如"column": ["id", "name"]。ODPSWriter支持列筛选、列换序,例如表有a,b,c三个字段,用户只同步c,b两个字段。可以配置成["c","b"], 在导入过程中,字段a自动补空,设置为null。
-
truncate
-
描述:ODPSWriter通过配置"truncate": true,保证写入的幂等性,即当出现写入失败再次运行时,ODPSWriter将清理前述数据,并导入新数据,这样可以保证每次重跑之后的数据都保持一致。
truncate选项不是原子操作!MaxCompute SQL无法做到原子性。因此当多个任务同时向一个Table/Partition清理分区时候,可能出现并发时序问题,请务必注意!针对这类问题,我们建议尽量不要多个作业DDL同时操作同一份分区,或者在多个并发作业启动前,提前创建分区。
-
必选:是
-
默认值:无
-
-
odpsServer
- 描述:MaxCompute的server,详细可以参考文档https://help.aliyun.com/document_detail/34951.html
线上公网地址为 http://service.cn.maxcompute.aliyun.com/api
- 必选:是
- 默认值:无
-
tunnelServer
- 描述:MaxCompute的tunnelserver,详细可以参考文档https://help.aliyun.com/document_detail/34951.html
线上公网地址为 http://dt.cn-beijing.maxcompute.aliyun-inc.com
- 必选:是
- 默认值:无
-
blockSizeInMB
- 描述:为了提高数据写出MaxCompute的效率ODPSWriter会攒数据buffer,待数据达到一定大小后会进行一次数据提交。blockSizeInMB即为攒数据buffer的大小,默认是64MB。
- 必选:否
- 默认值:64