Java基础-正则表达式(Regular Expression)语法规则简介
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.正则表达式的概念
正则表达式(Regular Expression,在代码中常简写为regex)是一个字符串,使用单个字符串来描述,用来定义匹配规则,匹配一系列符合某个句法规则的字符串。在开发中,正则表达式通常被用来检索,替换那些符合某个规则的文本。
二.正则表达式常用的匹配规则
再看Java的API帮助文档,在pattern类中有正则表达式的规则定义,正则表达式中明确区分大小写字母。接下来我们就来说一些Java常用的字符吧。
1>.字符"x"
含义:代表的是字符‘x’。
例如:匹配规则为“a”,那么匹配的字符传内容就是"a"。
2>.字符“\\”
含义:代表的反斜线字符‘\’(前面的"\"是转义的作用,被转的是“\”,后面的"\"被转义为了普通的斜线,失去了转义的作用)。
例如:匹配规则为“\\",那么需要匹配的字符串内容就是“\”。
3>.字符"\t"
含义:制表符(前面的“\”是转义的作用)。
例如:匹配规则为“\t”,那么对应的效果就是产生一个制表符的空间。
4>.字符“\n”
含义:换行符.
例如:匹配规则为“\n”,那么对应的效果就是换行,光标在原有位置的下一行。
5>.字符“\r”
含义:回车符。
例如:匹配规则为“\r”,那么对应的效果就是回车后的效果,光标来到下一行行首。
6>.字符类"[abc]"
含义:代表的是字符'a','b','c'。
例如:匹配规则为“[abc]”,那么需要匹配的内容就是字符a,或者字符b,或字符c的其中一个。
7>.字符类"[^abc]"
含义:代表的是除了a,b或c以外的任何字符。
例如:匹配规则为“[^abc]”,那么需要匹配的内容就是不是字符‘a’,或者不是字符'b',或不是字符‘c’的任意一个字符。
8>.字符类"[a-zA-Z]"
含义:带包的是a到z或A到Z,两头的字母包括再内。
例如:匹配规则为“[a-zA-Z]”,那么需要匹配的是一个大写或者小写字母。
9>.字符类"[0-9]"
含义:代表的是0到9数字,两个的数字包括在内。
例如:匹配规则为“[0-9]”,那么需要匹配的是一个数字。
10>.字符类"[a-zA-Z_0-9]"
含义:代表的字母或者数字或者下划线(即单词字符)。
例如:匹配规则为"[a-zA-Z_0-9]",那么需要匹配的是一个字母或者是一个数字或者一个下划线。
11>.预定义字符类“.”
含义:代表的是任何字符。
例如:匹配规则为“.”,那么需要匹配的是一个任意字符。如果就想使用“.”的话,使用匹配规则"\\."来实现。
12>.预定义字符类“\d”
含义:代表的是的是0到9数字,两头的数字包括在内,相当于[0-9]。
例如:匹配规则为“\d”,那么需要匹配的是一个数字。
13>.预定义字符类“\w”
含义:代表的字母或者数字或者下划线(即单词字符),相当于[a-zA-Z_0-9]。
例如:匹配规则为“\w”,那么需要匹配的是一个字母或者是一个数字或者一个下滑线。
14>.边界匹配器“^”
含义:代表的是行的开头。
例如:匹配规则为“^[abc][0-9]$”,那么需要匹配的内容从[abc]这个位置开始,相当于左双引号。
15>.边界匹配器"$"
含义:代表的是行的结尾。
例如:匹配规则为“\b[abc]\b”,那么代表的是字母a或b或c的左右两边需要的是非单词字符([a-zA-z_0-9])。
16>.数量词"x?"
含义:代表的是x出现一次或一次的也没有。
例如:匹配规则为“a?”,那么需要匹配的内容是多个字符‘a’,或者一个'a'都没有。
17>.数量词“x*”
含义:代表的是x出现零次或多次。
例如:匹配规则为“a*”,那么需要匹配的内容是多个字符'a',或者一个'a'。
18>.数量词“x+”
含义:代表的是x出现一次或多次
例如:匹配规则为“a+”,那么需要匹配的内容是多个字符'a',或者一个‘a’。
19>.数量词“X{n}”
含义:代表的是x出现恰好n次。
例如:匹配规则为“a{5}”,那么需要匹配的内容是5个字符‘a’。
20>.数量词“X{n,}”
含义:代表的是X出现至少n次。
例如:匹配规则为“a{5,8}”,那么需要匹配的内容是有5个字符‘a’到8个字符‘a’之间。


1 构造 匹配 2 3 字符 4 x 字符 x 5 \\ 反斜线字符 6 \0n 带有八进制值 0 的字符 n (0 <= n <= 7) 7 \0nn 带有八进制值 0 的字符 nn (0 <= n <= 7) 8 \0mnn 带有八进制值 0 的字符 mnn(0 <= m <= 3、0 <= n <= 7) 9 \xhh 带有十六进制值 0x 的字符 hh 10 \uhhhh 带有十六进制值 0x 的字符 hhhh 11 \t 制表符 ('\u0009') 12 \n 新行(换行)符 ('\u000A') 13 \r 回车符 ('\u000D') 14 \f 换页符 ('\u000C') 15 \a 报警 (bell) 符 ('\u0007') 16 \e 转义符 ('\u001B') 17 \cx 对应于 x 的控制符 18 19 字符类 20 [abc] a、b 或 c(简单类) 21 [^abc] 任何字符,除了 a、b 或 c(否定) 22 [a-zA-Z] a 到 z 或 A 到 Z,两头的字母包括在内(范围) 23 [a-d[m-p]] a 到 d 或 m 到 p:[a-dm-p](并集) 24 [a-z&&[def]] d、e 或 f(交集) 25 [a-z&&[^bc]] a 到 z,除了 b 和 c:[ad-z](减去) 26 [a-z&&[^m-p]] a 到 z,而非 m 到 p:[a-lq-z](减去) 27 28 预定义字符类 29 . 任何字符(与行结束符可能匹配也可能不匹配) 30 \d 数字:[0-9] 31 \D 非数字: [^0-9] 32 \s 空白字符:[ \t\n\x0B\f\r] 33 \S 非空白字符:[^\s] 34 \w 单词字符:[a-zA-Z_0-9] 35 \W 非单词字符:[^\w] 36 37 POSIX 字符类(仅 US-ASCII) 38 \p{Lower} 小写字母字符:[a-z] 39 \p{Upper} 大写字母字符:[A-Z] 40 \p{ASCII} 所有 ASCII:[\x00-\x7F] 41 \p{Alpha} 字母字符:[\p{Lower}\p{Upper}] 42 \p{Digit} 十进制数字:[0-9] 43 \p{Alnum} 字母数字字符:[\p{Alpha}\p{Digit}] 44 \p{Punct} 标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ 45 \p{Graph} 可见字符:[\p{Alnum}\p{Punct}] 46 \p{Print} 可打印字符:[\p{Graph}\x20] 47 \p{Blank} 空格或制表符:[ \t] 48 \p{Cntrl} 控制字符:[\x00-\x1F\x7F] 49 \p{XDigit} 十六进制数字:[0-9a-fA-F] 50 \p{Space} 空白字符:[ \t\n\x0B\f\r] 51 52 java.lang.Character 类(简单的 java 字符类型) 53 \p{javaLowerCase} 等效于 java.lang.Character.isLowerCase() 54 \p{javaUpperCase} 等效于 java.lang.Character.isUpperCase() 55 \p{javaWhitespace} 等效于 java.lang.Character.isWhitespace() 56 \p{javaMirrored} 等效于 java.lang.Character.isMirrored() 57 58 Unicode 块和类别的类 59 \p{InGreek} Greek 块(简单块)中的字符 60 \p{Lu} 大写字母(简单类别) 61 \p{Sc} 货币符号 62 \P{InGreek} 所有字符,Greek 块中的除外(否定) 63 [\p{L}&&[^\p{Lu}]] 所有字母,大写字母除外(减去) 64 65 边界匹配器 66 ^ 行的开头 67 $ 行的结尾 68 \b 单词边界 69 \B 非单词边界 70 \A 输入的开头 71 \G 上一个匹配的结尾 72 \Z 输入的结尾,仅用于最后的结束符(如果有的话) 73 \z 输入的结尾 74 75 Greedy 数量词 76 X? X,一次或一次也没有 77 X* X,零次或多次 78 X+ X,一次或多次 79 X{n} X,恰好 n 次 80 X{n,} X,至少 n 次 81 X{n,m} X,至少 n 次,但是不超过 m 次 82 83 Reluctant 数量词 84 X?? X,一次或一次也没有 85 X*? X,零次或多次 86 X+? X,一次或多次 87 X{n}? X,恰好 n 次 88 X{n,}? X,至少 n 次 89 X{n,m}? X,至少 n 次,但是不超过 m 次 90 91 Possessive 数量词 92 X?+ X,一次或一次也没有 93 X*+ X,零次或多次 94 X++ X,一次或多次 95 X{n}+ X,恰好 n 次 96 X{n,}+ X,至少 n 次 97 X{n,m}+ X,至少 n 次,但是不超过 m 次 98 99 Logical 运算符 100 XY X 后跟 Y 101 X|Y X 或 Y 102 (X) X,作为捕获组 103 104 Back 引用 105 \n 任何匹配的 nth 捕获组 106 107 引用 108 \ Nothing,但是引用以下字符 109 \Q Nothing,但是引用所有字符,直到 \E 110 \E Nothing,但是结束从 \Q 开始的引用 111 112 特殊构造(非捕获) 113 (?:X) X,作为非捕获组 114 (?idmsux-idmsux) Nothing,但是将匹配标志i d m s u x on - off 115 (?idmsux-idmsux:X) X,作为带有给定标志 i d m s u x on - off 116 的非捕获组 (?=X) X,通过零宽度的正 lookahead 117 (?!X) X,通过零宽度的负 lookahead 118 (?<=X) X,通过零宽度的正 lookbehind 119 (?<!X) X,通过零宽度的负 lookbehind 120 (?>X) X,作为独立的非捕获组
三.字符串类中设计正则表达式的常用方法
1>.matches(String regex)方法
作用:告知此字符串是否匹配给定的正则表达式。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.Demo; 8 9 public class RegexDemo { 10 11 public static void main(String[] args) { 12 String QQ = "1053419035"; 13 String phone = "13021055038"; 14 System.out.println(checkQQ(QQ)); 15 System.out.println(checkTellphone(phone)); 16 17 } 18 19 //定义检测QQ的方法。 20 public static boolean checkQQ(String QQ) { 21 String pattern = "[1-9][\\d]{4,9}"; 22 boolean res = QQ.matches(pattern); 23 return res; 24 } 25 26 // 27 public static boolean checkTellphone(String phone) { 28 String pattern = "1[34857][\\d]{9}"; 29 boolean res = phone.matches(pattern); 30 return res; 31 } 32 } 33 34 35 /* 36 以上代码执行结果如下: 37 true 38 true 39 */
2>.split(String regex)方法
作用:根据给定正则表达式的匹配拆分此字符串。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.Demo; 8 9 public class RegexDemo { 10 11 public static void main(String[] args) { 12 String src = "2018-04-17"; 13 String pattern = "-"; 14 System.out.println(getSplit(src,pattern)); 15 16 } 17 18 public static StringBuffer getSplit(String src,String pattern) { 19 String[] arr = src.split(pattern); 20 StringBuffer buffer = new StringBuffer(); 21 buffer.append("["); 22 for (int i = 0; i < arr.length; i++) { 23 if(i==arr.length-1) { 24 buffer.append(arr[i]+"]"); 25 }else { 26 buffer.append(arr[i]+","); 27 } 28 } 29 return buffer; 30 } 31 } 32 33 34 /* 35 以上代码执行结果如下: 36 [2018,04,17] 37 */
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.Demo; 8 9 public class RegexDemo { 10 11 public static void main(String[] args) { 12 String src = "10 20 30 40 50 60 70"; 13 String pattern = " +"; //匹配多个空格。 14 System.out.println(getSplit(src,pattern)); 15 16 } 17 18 public static StringBuffer getSplit(String src,String pattern) { 19 String[] arr = src.split(pattern); 20 StringBuffer buffer = new StringBuffer(); 21 buffer.append("["); 22 for (int i = 0; i < arr.length; i++) { 23 if(i==arr.length-1) { 24 buffer.append(arr[i]+"]"); 25 }else { 26 buffer.append(arr[i]+","); 27 } 28 } 29 return buffer; 30 } 31 } 32 33 34 /* 35 以上代码执行结果如下: 36 [10,20,30,40,50,60,70] 37 */
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.Demo; 8 9 public class RegexDemo { 10 11 public static void main(String[] args) { 12 String ipconfig = "192.168.0.254"; 13 String pattern = "\\."; //我们需要对"."进行转义。 14 System.out.println(getSplit(ipconfig,pattern)); 15 16 } 17 18 public static StringBuffer getSplit(String src,String pattern) { 19 String[] arr = src.split(pattern); 20 StringBuffer buffer = new StringBuffer(); 21 buffer.append("["); 22 for (int i = 0; i < arr.length; i++) { 23 if(i==arr.length-1) { 24 buffer.append(arr[i]+"]"); 25 }else { 26 buffer.append(arr[i]+","); 27 } 28 } 29 return buffer; 30 } 31 } 32 33 34 /* 35 以上代码执行结果如下: 36 [10,20,30,40,50,60,70] 37 */
3>.replaceAll(String regex,String replacenent)方法
作用:使用给定的replacement替换此字符串所有匹配给定的正则表达式的子字符串。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.Demo; 8 9 public class RegexDemo { 10 11 public static void main(String[] args) { 12 String src = "2018yinzhengjie@0417"; 13 System.out.println("切割之前:>>>"+src); 14 String re = "$"; 15 re = java.util.regex.Matcher.quoteReplacement(re); //一个是JDK提供的方法,对特殊字符进行处理. 16 src = src.replaceAll("[\\d]+", re); 17 System.out.println("切割之后:>>>"+src); 18 } 19 } 20 21 22 /* 23 以上代码执行结果如下: 24 切割之前:>>>2018yinzhengjie@0417 25 切割之后:>>>$yinzhengjie@$ 26 */
4>.匹配正确的数字
1 匹配规则:
2 1>.匹配正整数:"\\d+";
3 2>.匹配正小数:"\\d+\\.\\d+" ;
4 3>.匹配负整数:"-\\d+";
5 4>.匹配负小数:"-\\d+.\\d+"
6 5>.匹配保留两位小数的整数:"\\d+\\.\\d{2}"
7 6>.匹配保留1-3位小数的整数:“\\d+\\.\\d{1,3}”
四.小试牛刀
1>.邮箱地址匹配
下面的一个案例是对用户输入的邮箱进行合法性判断,当然实际生产环境中比这个要复杂的多,我们这里只是判断用户输入的邮箱地址是否合法。
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.Demo; 8 9 import java.util.Scanner; 10 11 public class RegexDemo { 12 13 public static void main(String[] args) { 14 Scanner s = new Scanner(System.in); 15 s.useDelimiter("\n"); 16 while(true) { 17 System.out.print("请输入您想要注册的邮箱(输入'exit'退出程序):>>>"); 18 String Email = s.nextLine(); 19 if(Email.equals("exit")) { 20 System.exit(0); 21 } 22 if(checkMail(Email) == true) { 23 System.out.println("您输入的邮箱格式正确!"); 24 }else { 25 System.out.println("您输入的邮箱格式错误!"); 26 } 27 } 28 29 } 30 31 //定义邮箱的匹配规则 32 public static boolean checkMail(String Email) { 33 String pattern = "[a-zA-Z0-9_]+@[0-9a-z]+(\\.[a-z]+)+"; 34 boolean res = Email.matches(pattern); 35 return res; 36 } 37 }
下图是我测试的结果:
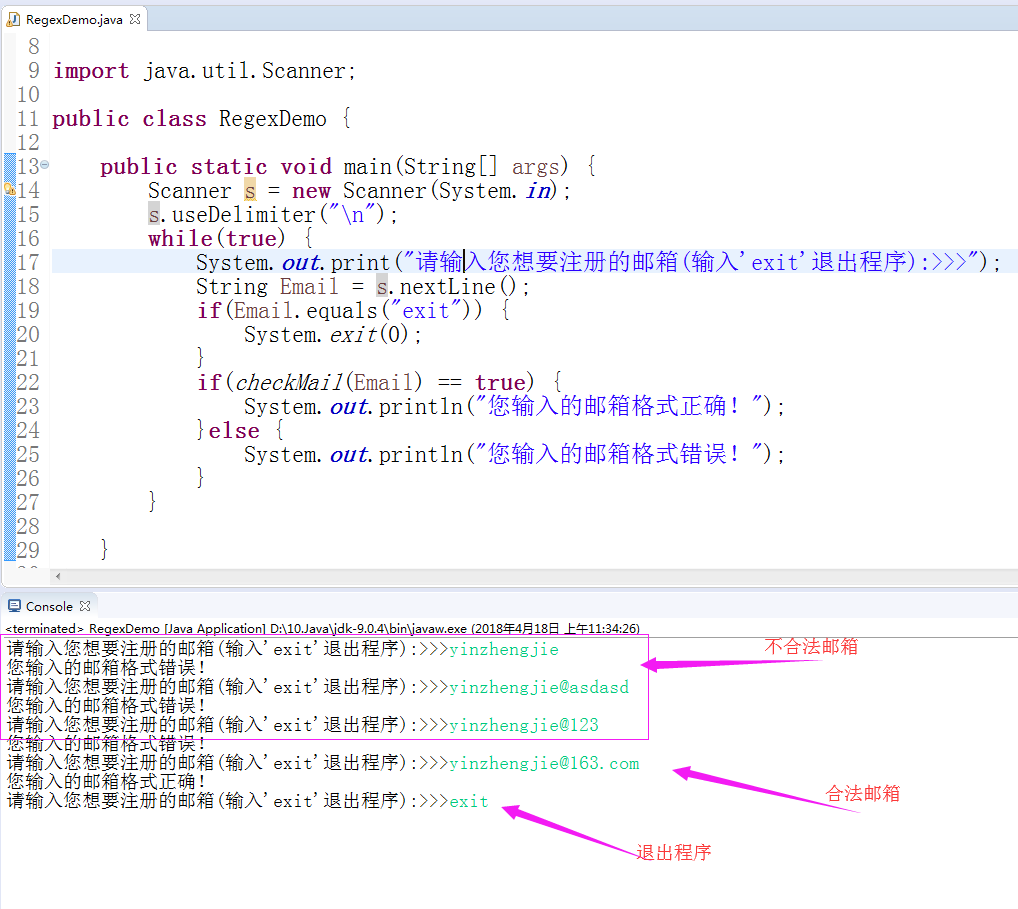
2>.统计单词出现的次数
我们可以手动输入一些字符串,然后让程序自动统计出来单词出现的次数,实现代码如下:
1 /* 2 @author :yinzhengjie 3 Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/ 4 EMAIL:y1053419035@qq.com 5 */ 6 7 package cn.org.yinzhengjie.demo; 8 9 import java.util.HashMap; 10 import java.util.Scanner; 11 import java.util.Set; 12 import java.util.regex.Matcher; 13 import java.util.regex.Pattern; 14 15 16 public class WordCountDemo { 17 18 public static void main(String[] args) { 19 Scanner sc = new Scanner(System.in); 20 System.out.print("input a string:"); 21 String s = sc.nextLine(); 22 23 HashMap<String, Integer> hm = new HashMap<>(); 24 25 Pattern p = Pattern.compile("\\b\\w+\\b"); 26 Matcher m = p.matcher(s); 27 while(m.find()){ 28 String word = m.group(); 29 if(!hm.containsKey(word)){ 30 hm.put(word, 1); 31 }else{ 32 hm.put(word, hm.get(word) + 1); 33 } 34 } 35 36 Set<String> keys = hm.keySet(); 37 for (String word : keys) { 38 System.out.println("单词是: " + word +"\t次数是: "+ hm.get(word)); 39 } 40 } 41 }
测试结果如下:
