为什么80%的码农都做不了架构师?>>> 
一、构建spark项目
maven构建scala项目
1.参考之前构建scala项目的步骤,先构建一个scala项目。
2.然后再加入spark版本的依赖。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.5.0</version>
</dependency>注意spark版本要和集群上spark版本对应。spark-core_2.10不能写成spark-core_2.11,后面的2.10是和你的scala版本对应上的。如果spark的版本是从scala2.11编译的,则要写2.11。
3.把jdk和scala版本改成spark依赖的版本
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.10.4</scala.version>
<scala.compat.version>2.10</scala.compat.version>
</properties>注意scala.version和scala.compat.version版本要改成相同的,否则maven编译会报错,编译不过去。
4.spark程序代码如下:
object SparkMain {
def main(args : Array[String]) {
var sparkConf = new SparkConf();
sparkConf.setAppName("sparkTest").setMaster("spark://bigdata1:7077,bigdata2:7077");
val sc = new SparkContext(sparkConf);
sc.addJar("D:\\programs\\scala-SDK-4.1.1-vfinal-2.11-win32.win32.x86_64\\workspace\\SparkTest\\target\\SparkTest-0.0.1-SNAPSHOT.jar");
val hdfsRdd = sc.textFile("hdfs://bigdata1:9000/data/stbcontent/0");
val mapRdd = hdfsRdd.flatMap(mySplit);
var result = hdfsRdd.flatMap(mySplit).count();
mapRdd.saveAsTextFile("hdfs://bigdata1:9000/data/stbformat1");
println(result);
sc.stop();
}
}注意此处的drivering program就是安装eclipse的这台机器了,所以路径都是针对eclipse。如果打包到集群上跑,那么路径就变成了linux那台机器了。所以我们查看4044端口的时候,就是window这台机器的ip了。
如果直接跑在本地windows下,需要添加hadoop的环境,添加完了之后,你就可以在windows上直接跑spark程序了,则spark代码如下:
object SeeSource {
def main(args: Array[String]): Unit = {
var sparkConf = new SparkConf();
sparkConf.setAppName("seeSource").setMaster("local[2]");
val sc = new SparkContext(sparkConf);
println("aa");
sc.stop();
}
}参考:在Eclipse上运行Spark(Standalone,Yarn-Client)
二、问题汇总
1.java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@d919109 rejected from java.util.concurrent.ThreadPoolExecutor@7b42ce0a
将sparkConf.setMaster里面master ip改成hostName,这样就不会出现这个错误了,如下:
sparkConf.setMaster("spark://bigdata1:7077,bigdata2:7077");
参考: java远程调用 spark服务出错
2.java.lang.NoClassDefFoundError: scala/collection/GenTraversableOnce$class
scala ide编译spark程序使用的scala版本和spark集群上的scala版本不一致。解决方法就是更改scala ide所使用的scala 版本
首先新增符合要求的scala版本,如下:
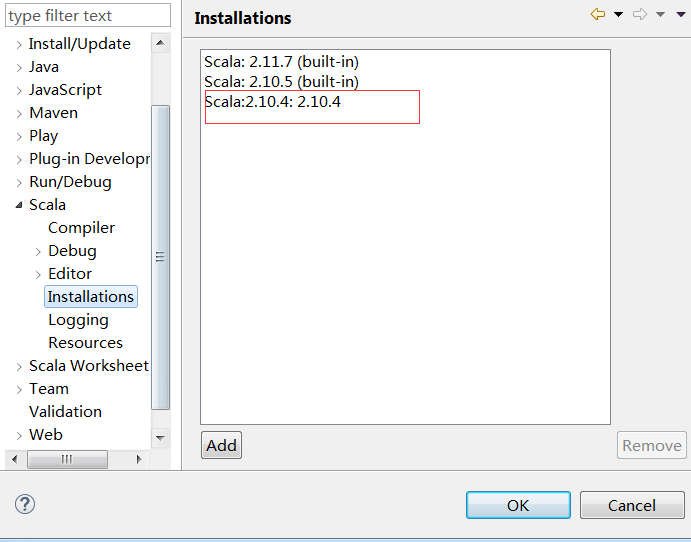
然后项目右键,选择scala compiler,选择刚刚新增的scala版本
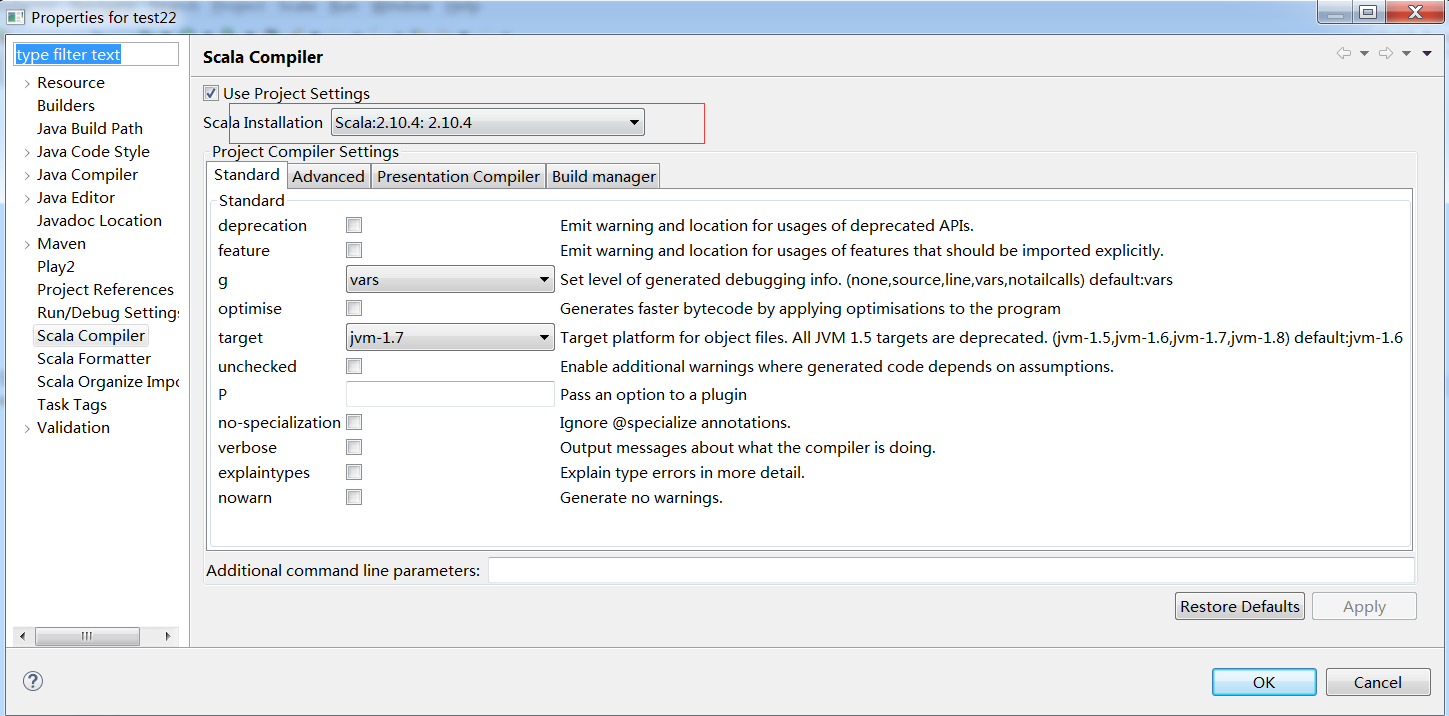
参考:运行第一个SparkStreaming程序(及过程中问题解决)
3.java.lang.ClassNotFoundException: com.bigdata.test22.SparkTest$$anonfun$1
出现这个错误是spark standalone集群中,我们运行的类在worker节点没有,所以worker节点就会报找不到类这个错误,需要将我们的spark程序打包放到集群的每个节点上,然后在sparkConf加上如下代码:
sparkConf.addJar("D:\\programs\\scala-SDK-4.1.1-vfinal-2.11-win32.win32.x86_64\\workspace\\SparkTest\\target\\SparkTest-0.0.1-SNAPSHOT.jar");
注意,一般我们使用ide来测试spark的话,如果是在linux编程,ide和spark在同一个节点上,那么使用sparkConf.setMaster("local[2]"),只在一台机器上跑,就不存在找不到类的问题了。
spark java api通过run as java application运行的方法