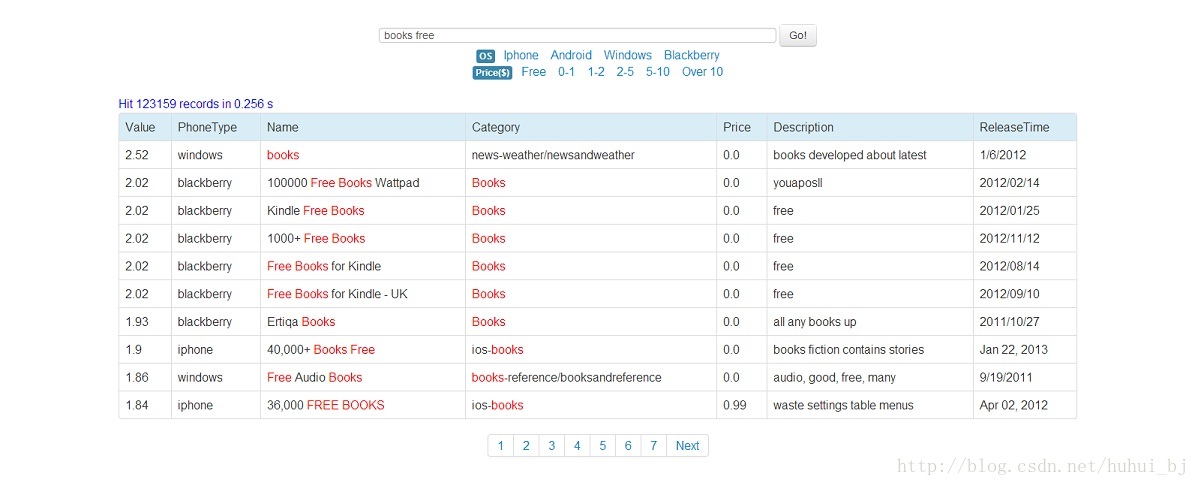
1.针对多个域的一次性查询
1.1.三种方案
使用lucene构造搜索引擎的时候,如果要针对多个域进行一次性查询,一般来说有三种方法:
第一种实现方法是创建多值的全包含域的文本进行索引,这个方案最简单。但是这个防范有个缺点:你不能直接对每个域的加权进行控制。
第二种方法是使用MultiFieldQueryParser,它是QueryParser的子类,它会在后台程序中实例化一个QueryParser对象,用来针对每个域进行查询表达式的解析,然后使用BooleanQuery将查询结果合并起来。当程序向BooleanQuery添加查询子句时,默认操作符OR被用于最简单的解析方法中。为了实现更好的控制,布尔操作符可以使用BooleanClause的常量指定给每个域。如果需要指定的话可以使用BooleanClause.Occur.MUST,如果禁止指定可以使用BooleanClause.Occur.MUST_NOT,或者普通情况为BooleanClause.Occur.SHOULD。下面的程序展示的是如何创建MultiFieldQueryParser类的方法:
// 在这四个域中检索
String[] fields = { "phoneType", "name", "category", "price" };
Query query = new MultiFieldQueryParser(Version.LUCENE_36, fields, analyzer).parse(keyword);1.2.方案选择
以上三种方案中,并不是第三种方案最好,也不是第一种方案就最差。哪种实现方式更适合你的应用程序呢?答案是“看情况”,因为这里存在一些取舍。全包含域是一个简单的解决方案——但这个方案只能对搜索结果进行简单的排序并且可能浪费磁盘空间(程序可能对同样的文本索引两次),但这个方案可能会获得最好的搜索性能。
MultiFieldQueryParser生成的BooleanQuery会计算所有查询所匹配的文档评分的总和(DisjunctionMaxQuery则只选取最大评分),然后它能够实现针对每个域的加权。你必须对以上3中解决方案都进行测试,同时需要一起考虑搜索性能和搜索相关性,然后再找出最佳方案。
2.在结果中查询
2.1.两种方案
在检索结果中再次进行检索,是一个很常见的需求,一般有两种方案可以选择:
①使用QueryFilter把第一个查询当作一个过滤器处理;
②用BooleanQuery把前后两个查询结合起来,并且使用BooleanClause.Occur.MUST。
针对第一种方法,我需要解释一下。QueryFilter在Lucene的2.x版本中是存在的,但是在3.x中,lucene的API中这个类已经被废弃了,无法再找到。如果你的项目使用的是lucene是3.x,但是你又一定要使用QueryFilter,那么你必须自己创建一个QueryFilter类,然后将2.x中QueryFilter的源代码复制过来。你可能会说,直接在工程中同时使用lucene2.x和3.x的核心jar文件不就行了吗。但遗憾的是,一个工程下,是不能同时使用不同版本的lucene的。
2.2.QueryFilter方案
上文已经说了,如果一定要使用QueryFilter,由于lucene2.x中没有QueryFilter的API,所以自己要写一个QueryFilter,QueryFilter的源代码在lucene2.x中是这样的:
import org.apache.lucene.search.CachingWrapperFilter;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.QueryWrapperFilter;
public class QueryFilter extends CachingWrapperFilter {
/**
* Constructs a filter which only matches documents matching
* <code>query</code>.
*/
public QueryFilter(Query query) {
super(new QueryWrapperFilter(query));
}
public boolean equals(Object o) {
return super.equals((QueryFilter) o);
}
public int hashCode() {
return super.hashCode() ^ 0x923F64B9;
}
}
第一种方案的例子程序如下:
//简单实现对keyword的搜索
public static void search(String keyword) throws IOException, ParseException {
QueryParser queryParser = new QueryParser("content",new SimpleAnalyzer());
Query query = queryParser.parse(keyword.trim());
QueryFilter filter = new QueryFilter(query);
//检索
search(query, filter);
}
//在搜索oldKeyword的结果集中搜索newKeyword
public static void searchInResult(String newKeyword, String oldKeyword) throws ParseException, IOException {
QueryParser queryParser = new QueryParser("content",new SimpleAnalyzer());
Query query = queryParser.parse(newKeyword.trim());
Query oldQuery = queryParser.parse(oldKeyword.trim());
QueryFilter oldFilter = new QueryFilter(oldQuery);
CachingWrapperFilter filter = new CachingWrapperFilter(oldFilter);
//检索
search(query, filter);
}
private static void search(Query query, Filter filter) throws IOException, ParseException {
IndexSearcher ins = new IndexSearcher("d:/tesindex");
Hits hits = ins.search(query, filter);
for (int i = 0; i < hits.length(); i++) {
Document doc = hits.doc(i);
System.out.println(doc.get("content"));
}
}2.3.BooleanQuery方案
使用BooleanQuery来实现在结果中检索的过程是这样的,首先通过关键字keyword1正常检索,当用户需要在检索结果中再通过关键字keyword2检索的时候,通过构建BooleanQuery,来实现对在结果中检索的效果。这里要注意,这两个关键字都要使用BooleanClause.Occur.MUST。
//创建BooleanQuery
BooleanQuery booleanQuery = new BooleanQuery();
//多域检索,在这四个域中检索
String[] fields = { "phoneType", "name", "category","free" };
Query multiFieldQuery = new MultiFieldQueryParser(Version.LUCENE_36, fields, analyzer).parse(keyword);
//将multiFieldQuery添加到BooleanQuery中
booleanQuery.add(multiFieldQuery, BooleanClause.Occur.MUST);
//如果osKeyword不为空
if(osKeyword != null && !osKeyword.equals("") && !osKeyword.equals("null")){
TermQuery osQuery = new TermQuery(new Term("phoneType",osKeyword));
//将osQuery添加到BooleanQuery中
booleanQuery.add(osQuery, BooleanClause.Occur.MUST);
}3.检索结果分页
3.1.两种方案
通过关键字的检索,当lucene返回多条记录的时候,往往一个页面是无法容纳所有检索结果的,这自然而然就该分页了。我这里给出两种方案,这两种方法我都是用过。
第一种方法,就是讲检索结果全部封装在一个Collection中,例如List中,将这个结果传到前台,如jsp页面。然后在这个list中进行分页显示;
第二种方法,是使用lucene自带的分页工具public TopDocs topDocs(int start,int howMany)。
我认为,第一种方法不涉及二次查询,这样的话就避免了在查询上的浪费。但是当检索的结果数据量很大,这样一次性传输这么多数据到客户端,而用户检索后得到的结果往往只会查看第一页的内容,很少去查看第二页、第三页以及后面的内容,所以一次性将全部结果传到前台,这样的浪费是很大的。
第二种方法,虽然每次翻页都意味着一次查询,表面上浪费了资源,但是由于lucene的高效,这样的浪费对整个系统的影响是微乎其微的,但是这个方法避免了方法一中的缺陷。
3.2.分页实现
/**
* 对搜索返回的前n条结果进行分页显示
* @param keyWord 查询关键词
* @param pageSize 每页显示记录数
* @param currentPage 当前页
*/
public void paginationQuery(String keyWord,int pageSize,int currentPage) throws ParseException, CorruptIndexException, IOException {
String[] fields = {"title","content"};
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_36,fields,analyzer);
Query query = queryParser.parse(keyWord);
IndexReader indexReader = IndexReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//TopDocs 搜索返回的结果
TopDocs topDocs = indexSearcher.search(query, 100);//只返回前100条记录
int totalCount = topDocs.totalHits; // 搜索结果总数量
ScoreDoc[] scoreDocs = topDocs.scoreDocs; // 搜索返回的结果集合
//查询起始记录位置
int begin = pageSize * (currentPage - 1) ;
//查询终止记录位置
int end = Math.min(begin + pageSize, scoreDocs.length);
//进行分页查询
for(int i=begin;i<end;i++) {
int docID = scoreDocs[i].doc;
Document doc = indexSearcher.doc(docID);
int id = NumericUtils.prefixCodedToInt(doc.get("id"));
String title = doc.get("title");
System.out.println("id is : "+id);
System.out.println("title is : "+title);
}
}4.高亮检索结果
针对检索结果的高亮实现方法,在lucene中提供了响应的工具,这里使用lucene-highlighter-3.6.2.jar来实现对检索结果的高亮显示。
public void search(String fieldName, String keyword)throws CorruptIndexException, IOException, ParseException {
searcher = new IndexSearcher(indexPath);
QueryParser queryParse = new QueryParser(fieldName, analyzer); // 构造QueryParser,解析用户输入的检索关键字
Query query = queryParse.parse(keyword);
Hits hits = searcher.search(query);
for (int i = 0; i < hits.length(); i++) {
Document doc = hits.doc(i);
String text = doc.get(fieldName);
SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<font color='red'>", "</font>");
Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));
highlighter.setTextFragmenter(new SimpleFragmenter(text.length()));
if (text != null) {
TokenStream tokenStream = analyzer.tokenStream(fieldName,new StringReader(text));
String highLightText = highlighter.getBestFragment(tokenStream,text);
System.out.println("高亮显示第 " + (i + 1) + " 条检索结果如下所示:");
System.out.println(highLightText);
}
}
searcher.close();
}5.检索结果的评分
lucene的评分是有一套自己的机制的,输入某一个关键字,lucene会对命中的记录进行评分,默认情况下,分数越高的结果会排在结果的越前面。如果在创建索引的时候,没有对某个域进行加权,那么默认分数的上限是5分,如果有对域做加权,检索结果的评分可能会出现大于5分的情况。
我们可以使用explain()来看看lucene对检索结果的评分情况:
//评分
Explanation explanation = indexSearcher.explain(query, docID);
System.out.println(explanation.toString()); 2.4342022 = (MATCH) weight(name:books in 71491), product of:
0.2964393 = queryWeight(name:books), product of:
8.21147 = idf(docFreq=109, maxDocs=149037)
0.036100637 = queryNorm